 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuriosity in hindsight
Nov 18, 2022



Consider the exploration in sparse-reward or reward-free environments, such as Montezuma's Revenge. The curiosity-driven paradigm dictates an intuitive technique: At each step, the agent is rewarded for how much the realized outcome differs from their predicted outcome. However, using predictive error as intrinsic motivation is prone to fail in stochastic environments, as the agent may become hopelessly drawn to high-entropy areas of the state-action space, such as a noisy TV. Therefore it is important to distinguish between aspects of world dynamics that are inherently predictable and aspects that are inherently unpredictable: The former should constitute a source of intrinsic reward, whereas the latter should not. In this work, we study a natural solution derived from structural causal models of the world: Our key idea is to learn representations of the future that capture precisely the unpredictable aspects of each outcome -- not any more, not any less -- which we use as additional input for predictions, such that intrinsic rewards do vanish in the limit. First, we propose incorporating such hindsight representations into the agent's model to disentangle "noise" from "novelty", yielding Curiosity in Hindsight: a simple and scalable generalization of curiosity that is robust to all types of stochasticity. Second, we implement this framework as a drop-in modification of any prediction-based exploration bonus, and instantiate it for the recently introduced BYOL-Explore algorithm as a prime example, resulting in the noise-robust "BYOL-Hindsight". Third, we illustrate its behavior under various stochasticities in a grid world, and find improvements over BYOL-Explore in hard-exploration Atari games with sticky actions. Importantly, we show SOTA results in exploring Montezuma with sticky actions, while preserving performance in the non-sticky setting.
Self-conditioned Embedding Diffusion for Text Generation
Nov 08, 2022Can continuous diffusion models bring the same performance breakthrough on natural language they did for image generation? To circumvent the discrete nature of text data, we can simply project tokens in a continuous space of embeddings, as is standard in language modeling. We propose Self-conditioned Embedding Diffusion, a continuous diffusion mechanism that operates on token embeddings and allows to learn flexible and scalable diffusion models for both conditional and unconditional text generation. Through qualitative and quantitative evaluation, we show that our text diffusion models generate samples comparable with those produced by standard autoregressive language models - while being in theory more efficient on accelerator hardware at inference time. Our work paves the way for scaling up diffusion models for text, similarly to autoregressive models, and for improving performance with recent refinements to continuous diffusion.
Emergent Communication: Generalization and Overfitting in Lewis Games
Sep 30, 2022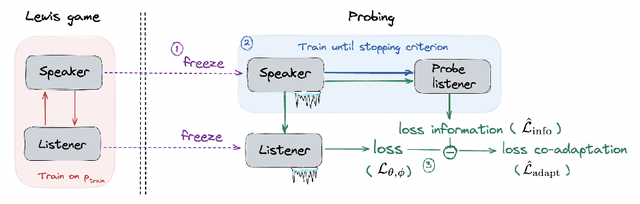

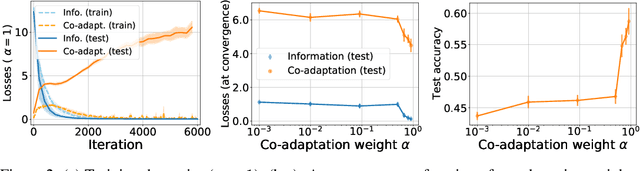

Lewis signaling games are a class of simple communication games for simulating the emergence of language. In these games, two agents must agree on a communication protocol in order to solve a cooperative task. Previous work has shown that agents trained to play this game with reinforcement learning tend to develop languages that display undesirable properties from a linguistic point of view (lack of generalization, lack of compositionality, etc). In this paper, we aim to provide better understanding of this phenomenon by analytically studying the learning problem in Lewis games. As a core contribution, we demonstrate that the standard objective in Lewis games can be decomposed in two components: a co-adaptation loss and an information loss. This decomposition enables us to surface two potential sources of overfitting, which we show may undermine the emergence of a structured communication protocol. In particular, when we control for overfitting on the co-adaptation loss, we recover desired properties in the emergent languages: they are more compositional and generalize better.
BYOL-Explore: Exploration by Bootstrapped Prediction
Jun 16, 2022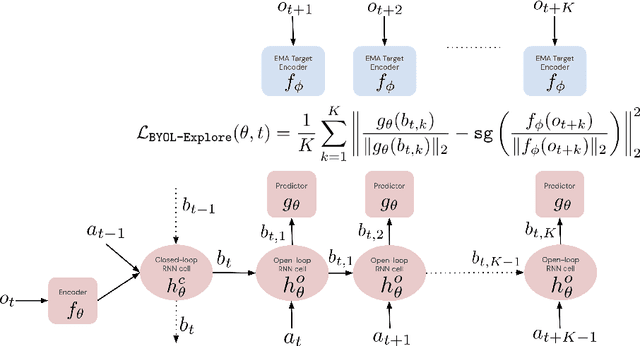
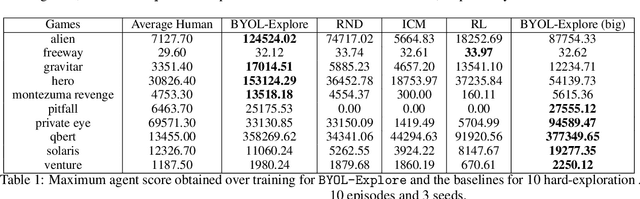

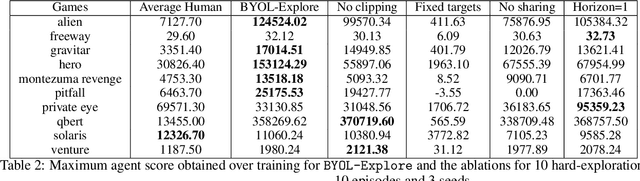
We present BYOL-Explore, a conceptually simple yet general approach for curiosity-driven exploration in visually-complex environments. BYOL-Explore learns a world representation, the world dynamics, and an exploration policy all-together by optimizing a single prediction loss in the latent space with no additional auxiliary objective. We show that BYOL-Explore is effective in DM-HARD-8, a challenging partially-observable continuous-action hard-exploration benchmark with visually-rich 3-D environments. On this benchmark, we solve the majority of the tasks purely through augmenting the extrinsic reward with BYOL-Explore s intrinsic reward, whereas prior work could only get off the ground with human demonstrations. As further evidence of the generality of BYOL-Explore, we show that it achieves superhuman performance on the ten hardest exploration games in Atari while having a much simpler design than other competitive agents.
Shaking the foundations: delusions in sequence models for interaction and control
Oct 20, 2021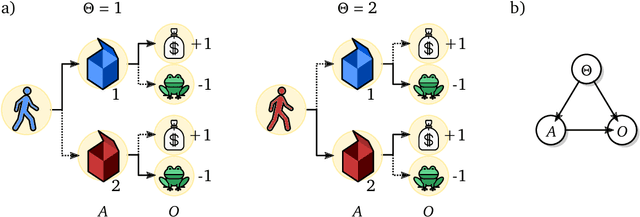
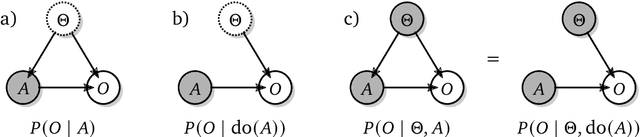
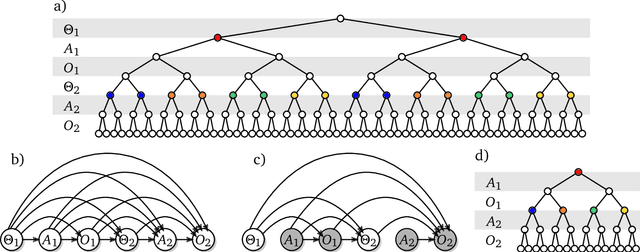
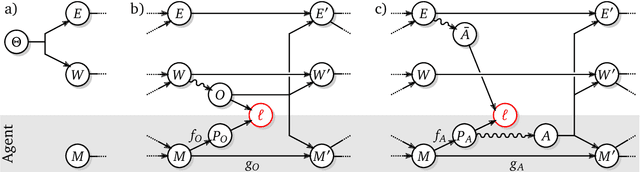
The recent phenomenal success of language models has reinvigorated machine learning research, and large sequence models such as transformers are being applied to a variety of domains. One important problem class that has remained relatively elusive however is purposeful adaptive behavior. Currently there is a common perception that sequence models "lack the understanding of the cause and effect of their actions" leading them to draw incorrect inferences due to auto-suggestive delusions. In this report we explain where this mismatch originates, and show that it can be resolved by treating actions as causal interventions. Finally, we show that in supervised learning, one can teach a system to condition or intervene on data by training with factual and counterfactual error signals respectively.
Broaden Your Views for Self-Supervised Video Learning
Mar 30, 2021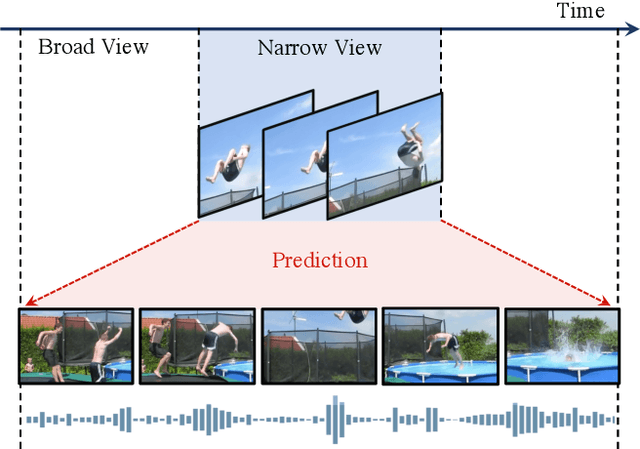
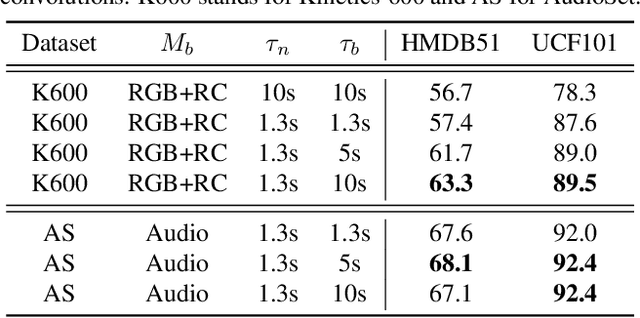
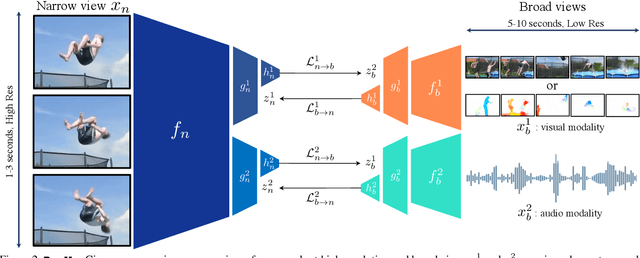
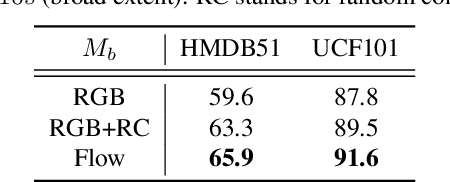
Most successful self-supervised learning methods are trained to align the representations of two independent views from the data. State-of-the-art methods in video are inspired by image techniques, where these two views are similarly extracted by cropping and augmenting the resulting crop. However, these methods miss a crucial element in the video domain: time. We introduce BraVe, a self-supervised learning framework for video. In BraVe, one of the views has access to a narrow temporal window of the video while the other view has a broad access to the video content. Our models learn to generalise from the narrow view to the general content of the video. Furthermore, BraVe processes the views with different backbones, enabling the use of alternative augmentations or modalities into the broad view such as optical flow, randomly convolved RGB frames, audio or their combinations. We demonstrate that BraVe achieves state-of-the-art results in self-supervised representation learning on standard video and audio classification benchmarks including UCF101, HMDB51, Kinetics, ESC-50 and AudioSet.
Bootstrapped Representation Learning on Graphs
Feb 12, 2021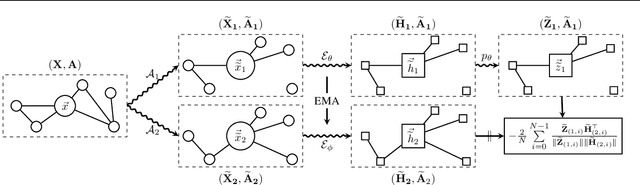
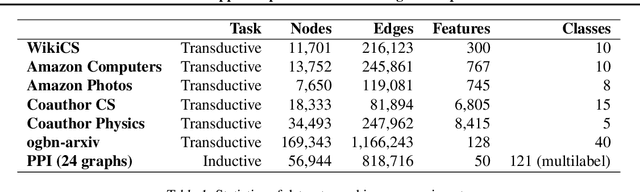
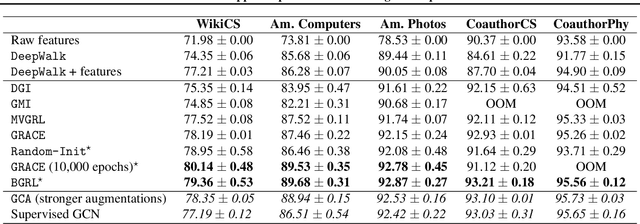
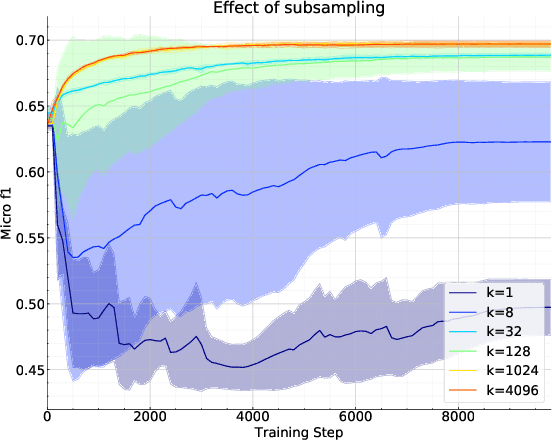
Current state-of-the-art self-supervised learning methods for graph neural networks (GNNs) are based on contrastive learning. As such, they heavily depend on the construction of augmentations and negative examples. For example, on the standard PPI benchmark, increasing the number of negative pairs improves performance, thereby requiring computation and memory cost quadratic in the number of nodes to achieve peak performance. Inspired by BYOL, a recently introduced method for self-supervised learning that does not require negative pairs, we present Bootstrapped Graph Latents, BGRL, a self-supervised graph representation method that gets rid of this potentially quadratic bottleneck. BGRL outperforms or matches the previous unsupervised state-of-the-art results on several established benchmark datasets. Moreover, it enables the effective usage of graph attentional (GAT) encoders, allowing us to further improve the state of the art. In particular on the PPI dataset, using GAT as an encoder we achieve state-of-the-art 70.49% Micro-F1, using the linear evaluation protocol. On all other datasets under consideration, our model is competitive with the equivalent supervised GNN results, often exceeding them.
Learning Successor States and Goal-Dependent Values: A Mathematical Viewpoint
Jan 18, 2021
In reinforcement learning, temporal difference-based algorithms can be sample-inefficient: for instance, with sparse rewards, no learning occurs until a reward is observed. This can be remedied by learning richer objects, such as a model of the environment, or successor states. Successor states model the expected future state occupancy from any given state for a given policy and are related to goal-dependent value functions, which learn how to reach arbitrary states. We formally derive the temporal difference algorithm for successor state and goal-dependent value function learning, either for discrete or for continuous environments with function approximation. Especially, we provide finite-variance estimators even in continuous environments, where the reward for exactly reaching a goal state becomes infinitely sparse. Successor states satisfy more than just the Bellman equation: a backward Bellman operator and a Bellman-Newton (BN) operator encode path compositionality in the environment. The BN operator is akin to second-order gradient descent methods and provides the true update of the value function when acquiring more observations, with explicit tabular bounds. In the tabular case and with infinitesimal learning rates, mixing the usual and backward Bellman operators provably improves eigenvalues for asymptotic convergence, and the asymptotic convergence of the BN operator is provably better than TD, with a rate independent from the environment. However, the BN method is more complex and less robust to sampling noise. Finally, a forward-backward (FB) finite-rank parameterization of successor states enjoys reduced variance and improved samplability, provides a direct model of the value function, has fully understood fixed points corresponding to long-range dependencies, approximates the BN method, and provides two canonical representations of states as a byproduct.
BYOL works even without batch statistics
Oct 20, 2020

Bootstrap Your Own Latent (BYOL) is a self-supervised learning approach for image representation. From an augmented view of an image, BYOL trains an online network to predict a target network representation of a different augmented view of the same image. Unlike contrastive methods, BYOL does not explicitly use a repulsion term built from negative pairs in its training objective. Yet, it avoids collapse to a trivial, constant representation. Thus, it has recently been hypothesized that batch normalization (BN) is critical to prevent collapse in BYOL. Indeed, BN flows gradients across batch elements, and could leak information about negative views in the batch, which could act as an implicit negative (contrastive) term. However, we experimentally show that replacing BN with a batch-independent normalization scheme (namely, a combination of group normalization and weight standardization) achieves performance comparable to vanilla BYOL ($73.9\%$ vs. $74.3\%$ top-1 accuracy under the linear evaluation protocol on ImageNet with ResNet-$50$). Our finding disproves the hypothesis that the use of batch statistics is a crucial ingredient for BYOL to learn useful representations.
Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
Jun 13, 2020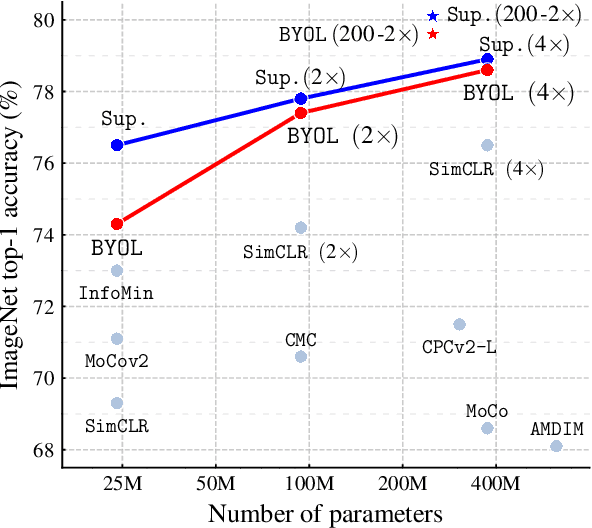

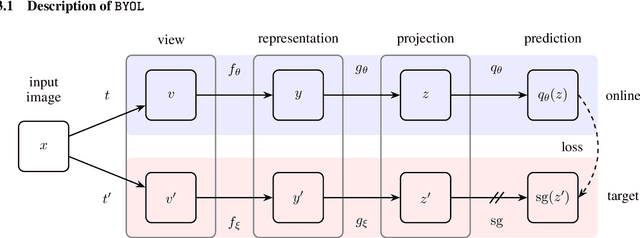
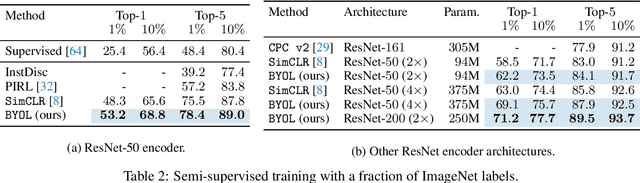
We introduce Bootstrap Your Own Latent (BYOL), a new approach to self-supervised image representation learning. BYOL relies on two neural networks, referred to as online and target networks, that interact and learn from each other. From an augmented view of an image, we train the online network to predict the target network representation of the same image under a different augmented view. At the same time, we update the target network with a slow-moving average of the online network. While state-of-the art methods intrinsically rely on negative pairs, BYOL achieves a new state of the art without them. BYOL reaches $74.3\%$ top-1 classification accuracy on ImageNet using the standard linear evaluation protocol with a ResNet-50 architecture and $79.6\%$ with a larger ResNet. We show that BYOL performs on par or better than the current state of the art on both transfer and semi-supervised benchmarks.