 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multivariate Models with Parametric Conditionals
Feb 02, 2026We consider deep multivariate models for heterogeneous collections of random variables. In the context of computer vision, such collections may e.g. consist of images, segmentations, image attributes, and latent variables. When developing such models, most existing works start from an application task and design the model components and their dependencies to meet the needs of the chosen task. This has the disadvantage of limiting the applicability of the resulting model for other downstream tasks. Here, instead, we propose to represent the joint probability distribution by means of conditional probability distributions for each group of variables conditioned on the rest. Such models can then be used for practically any possible downstream task. Their learning can be approached as training a parametrised Markov chain kernel by maximising the data likelihood of its limiting distribution. This has the additional advantage of allowing a wide range of semi-supervised learning scenarios.
Symmetric Equilibrium Learning of VAEs
Jul 19, 2023We view variational autoencoders (VAE) as decoder-encoder pairs, which map distributions in the data space to distributions in the latent space and vice versa. The standard learning approach for VAEs, i.e. maximisation of the evidence lower bound (ELBO), has an obvious asymmetry in that respect. Moreover, it requires a closed form a-priori latent distribution. This limits the applicability of VAEs in more complex scenarios, such as general semi-supervised learning and employing complex generative models as priors. We propose a Nash equilibrium learning approach that relaxes these restrictions and allows learning VAEs in situations where both the data and the latent distributions are accessible only by sampling. The flexibility and simplicity of this approach allows its application to a wide range of learning scenarios and downstream tasks. We show experimentally that the models learned by this method are comparable to those obtained by ELBO learning and demonstrate its applicability for tasks that are not accessible by standard VAE learning.
Enhancing Fairness of Visual Attribute Predictors
Jul 14, 2022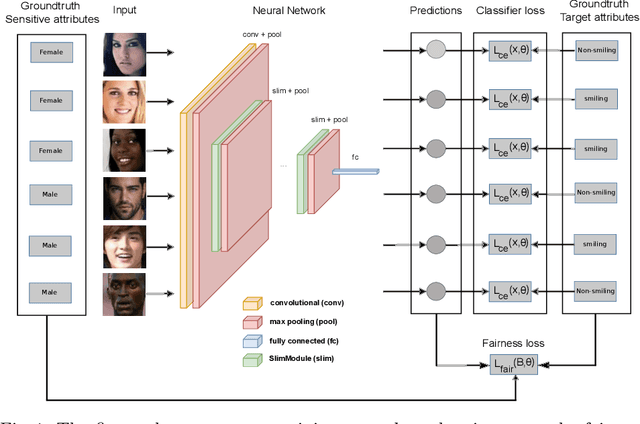
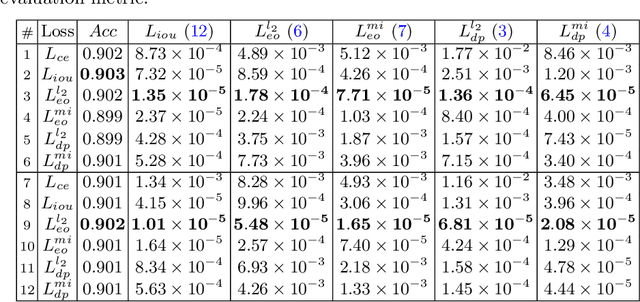
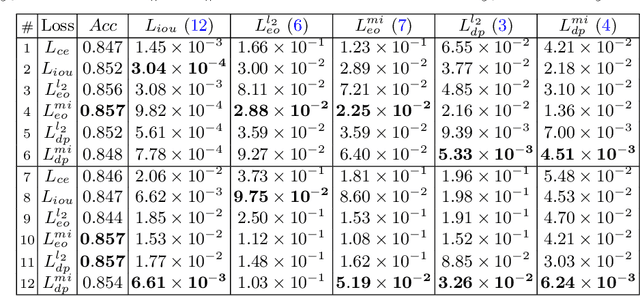
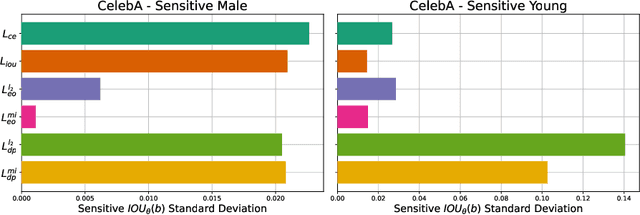
The performance of deep neural networks for image recognition tasks such as predicting a smiling face is known to degrade with under-represented classes of sensitive attributes. We address this problem by introducing fairness-aware regularization losses based on batch estimates of Demographic Parity, Equalized Odds, and a novel Intersection-over-Union measure. The experiments performed on facial and medical images from CelebA, UTKFace, and the SIIM-ISIC melanoma classification challenge show the effectiveness of our proposed fairness losses for bias mitigation as they improve model fairness while maintaining high classification performance. To the best of our knowledge, our work is the first attempt to incorporate these types of losses in an end-to-end training scheme for mitigating biases of visual attribute predictors. Our code is available at https://github.com/nish03/FVAP.
VAE Approximation Error: ELBO and Conditional Independence
Feb 18, 2021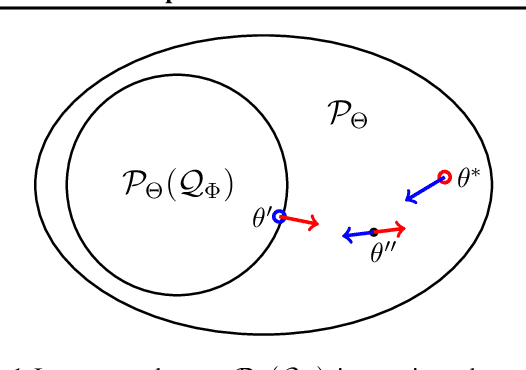
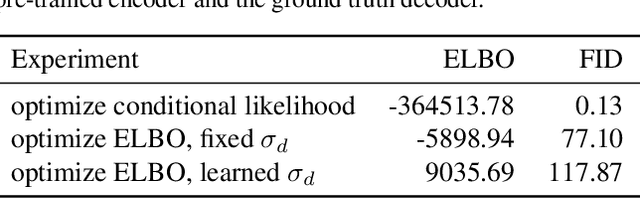
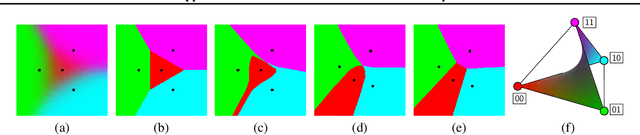
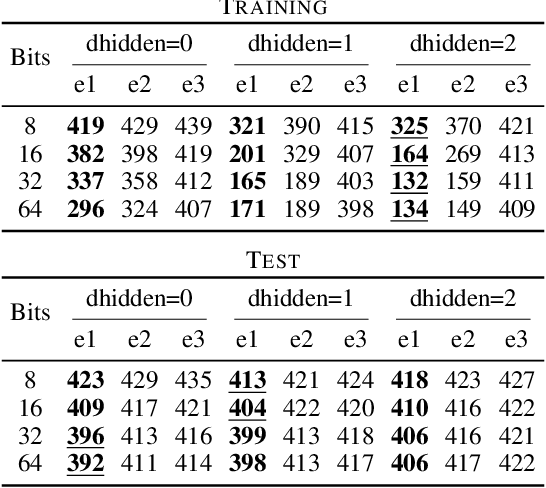
The importance of Variational Autoencoders reaches far beyond standalone generative models -- the approach is also used for learning latent representations and can be generalized to semi-supervised learning. This requires a thorough analysis of their commonly known shortcomings: posterior collapse and approximation errors. This paper analyzes VAE approximation errors caused by the combination of the ELBO objective with the choice of the encoder probability family, in particular under conditional independence assumptions. We identify the subclass of generative models consistent with the encoder family. We show that the ELBO optimizer is pulled from the likelihood optimizer towards this consistent subset. Furthermore, this subset can not be enlarged, and the respective error cannot be decreased, by only considering deeper encoder networks.
A Connection between Feed-Forward Neural Networks and Probabilistic Graphical Models
Oct 30, 2017
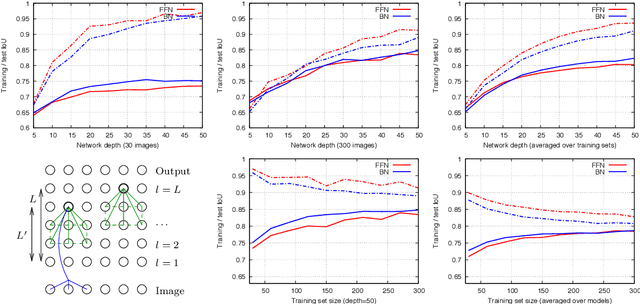

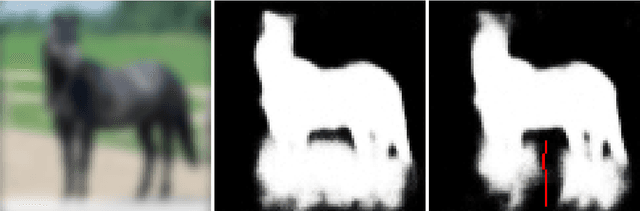
Two of the most popular modelling paradigms in computer vision are feed-forward neural networks (FFNs) and probabilistic graphical models (GMs). Various connections between the two have been studied in recent works, such as e.g. expressing mean-field based inference in a GM as an FFN. This paper establishes a new connection between FFNs and GMs. Our key observation is that any FFN implements a certain approximation of a corresponding Bayesian network (BN). We characterize various benefits of having this connection. In particular, it results in a new learning algorithm for BNs. We validate the proposed methods for a classification problem on CIFAR-10 dataset and for binary image segmentation on Weizmann Horse dataset. We show that statistically learned BNs improve performance, having at the same time essentially better generalization capability, than their FFN counterparts.
Crowd Sourcing Image Segmentation with iaSTAPLE
Feb 21, 2017
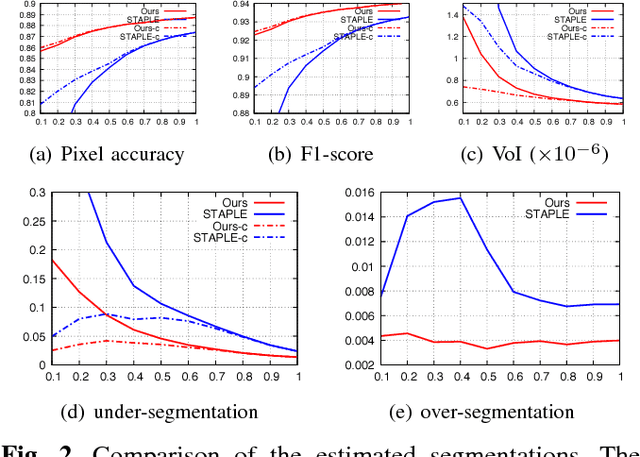

We propose a novel label fusion technique as well as a crowdsourcing protocol to efficiently obtain accurate epithelial cell segmentations from non-expert crowd workers. Our label fusion technique simultaneously estimates the true segmentation, the performance levels of individual crowd workers, and an image segmentation model in the form of a pairwise Markov random field. We term our approach image-aware STAPLE (iaSTAPLE) since our image segmentation model seamlessly integrates into the well-known and widely used STAPLE approach. In an evaluation on a light microscopy dataset containing more than 5000 membrane labeled epithelial cells of a fly wing, we show that iaSTAPLE outperforms STAPLE in terms of segmentation accuracy as well as in terms of the accuracy of estimated crowd worker performance levels, and is able to correctly segment 99% of all cells when compared to expert segmentations. These results show that iaSTAPLE is a highly useful tool for crowd sourcing image segmentation.
Implicit Modeling -- A Generalization of Discriminative and Generative Approaches
Dec 05, 2016
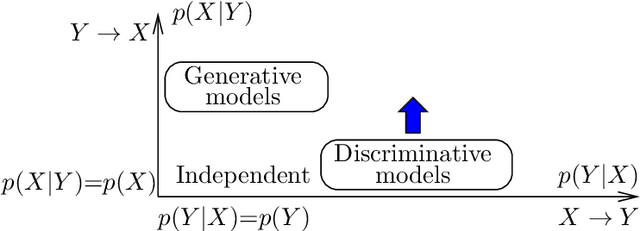
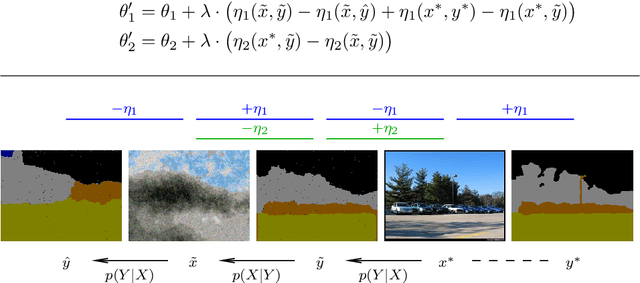
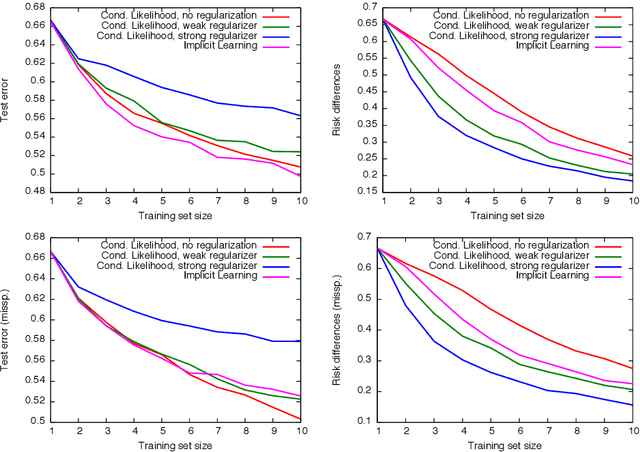
We propose a new modeling approach that is a generalization of generative and discriminative models. The core idea is to use an implicit parameterization of a joint probability distribution by specifying only the conditional distributions. The proposed scheme combines the advantages of both worlds -- it can use powerful complex discriminative models as its parts, having at the same time better generalization capabilities. We thoroughly evaluate the proposed method for a simple classification task with artificial data and illustrate its advantages for real-word scenarios on a semantic image segmentation problem.
Joint Training of Generic CNN-CRF Models with Stochastic Optimization
Sep 14, 2016
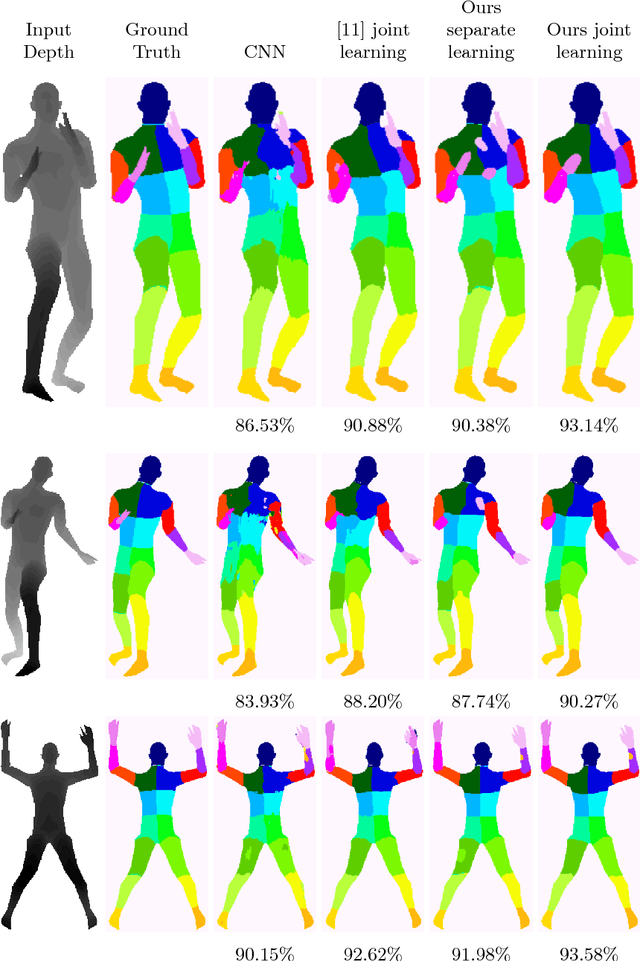
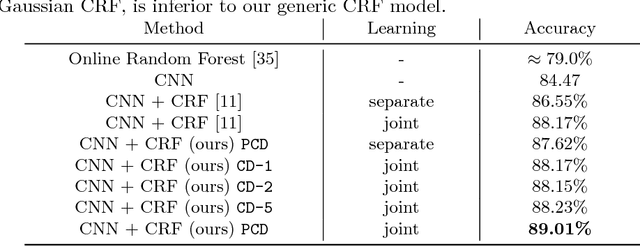
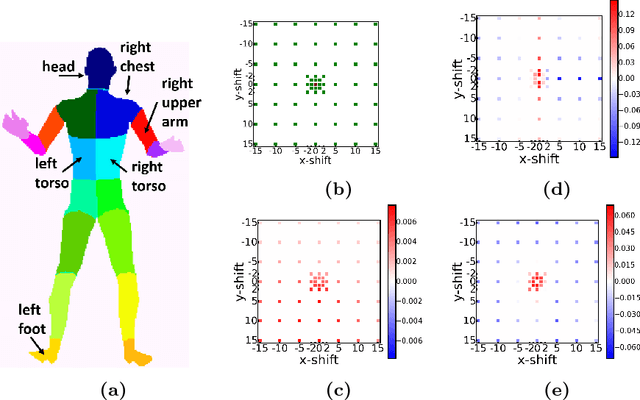
We propose a new CNN-CRF end-to-end learning framework, which is based on joint stochastic optimization with respect to both Convolutional Neural Network (CNN) and Conditional Random Field (CRF) parameters. While stochastic gradient descent is a standard technique for CNN training, it was not used for joint models so far. We show that our learning method is (i) general, i.e. it applies to arbitrary CNN and CRF architectures and potential functions; (ii) scalable, i.e. it has a low memory footprint and straightforwardly parallelizes on GPUs; (iii) easy in implementation. Additionally, the unified CNN-CRF optimization approach simplifies a potential hardware implementation. We empirically evaluate our method on the task of semantic labeling of body parts in depth images and show that it compares favorably to competing techniques.
Modelling Distributed Shape Priors by Gibbs Random Fields of Second Order
Jul 14, 2011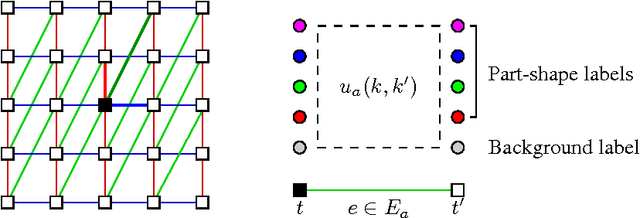



We analyse the potential of Gibbs Random Fields for shape prior modelling. We show that the expressive power of second order GRFs is already sufficient to express simple shapes and spatial relations between them simultaneously. This allows to model and recognise complex shapes as spatial compositions of simpler parts.
* 17 pages, 8 figures