 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Consistency Regularization for Deep Face Anti-Spoofing
Nov 24, 2021
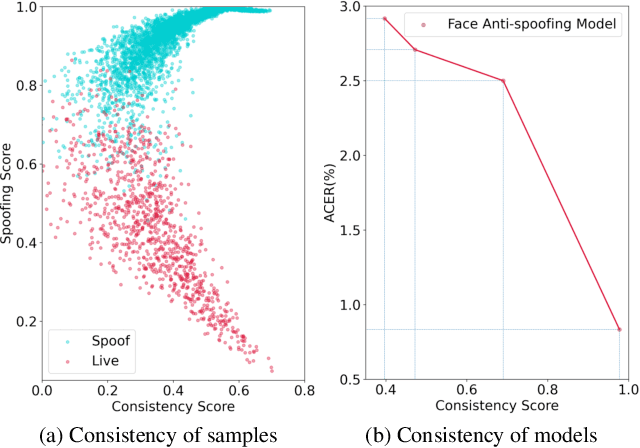

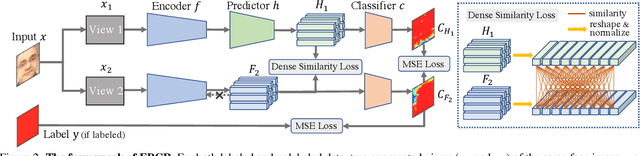

Face anti-spoofing (FAS) plays a crucial role in securing face recognition systems. Empirically, given an image, a model with more consistent output on different views of this image usually performs better, as shown in Fig.1. Motivated by this exciting observation, we conjecture that encouraging feature consistency of different views may be a promising way to boost FAS models. In this paper, we explore this way thoroughly by enhancing both Embedding-level and Prediction-level Consistency Regularization (EPCR) in FAS. Specifically, at the embedding-level, we design a dense similarity loss to maximize the similarities between all positions of two intermediate feature maps in a self-supervised fashion; while at the prediction-level, we optimize the mean square error between the predictions of two views. Notably, our EPCR is free of annotations and can directly integrate into semi-supervised learning schemes. Considering different application scenarios, we further design five diverse semi-supervised protocols to measure semi-supervised FAS techniques. We conduct extensive experiments to show that EPCR can significantly improve the performance of several supervised and semi-supervised tasks on benchmark datasets. The codes and protocols will be released soon.
A novel audio representation using space filling curves
Jan 08, 2022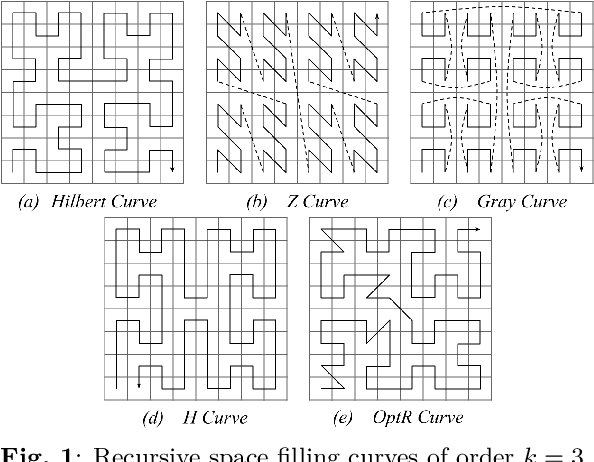
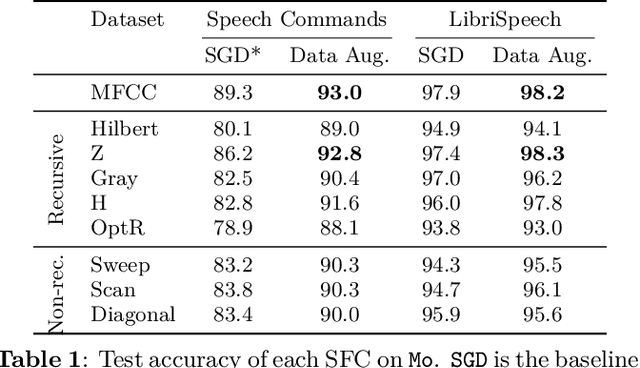
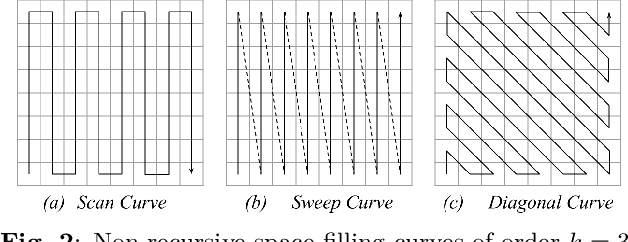
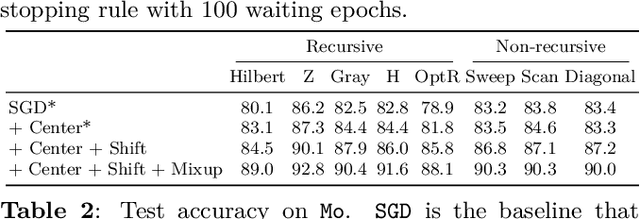
Since convolutional neural networks (CNNs) have revolutionized the image processing field, they have been widely applied in the audio context. A common approach is to convert the one-dimensional audio signal time series to two-dimensional images using a time-frequency decomposition method. Also it is common to discard the phase information. In this paper, we propose to map one-dimensional audio waveforms to two-dimensional images using space filling curves (SFCs). These mappings do not compress the input signal, while preserving its local structure. Moreover, the mappings benefit from progress made in deep learning and the large collection of existing computer vision networks. We test eight SFCs on two keyword spotting problems. We show that the Z curve yields the best results due to its shift equivariance under convolution operations. Additionally, the Z curve produces comparable results to the widely used mel frequency cepstral coefficients across multiple CNNs.
Image Segmentation Using Deep Learning: A Survey
Jan 15, 2020
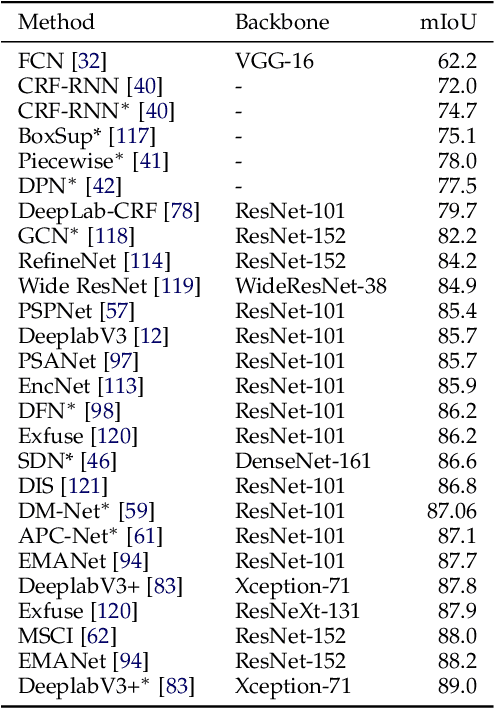
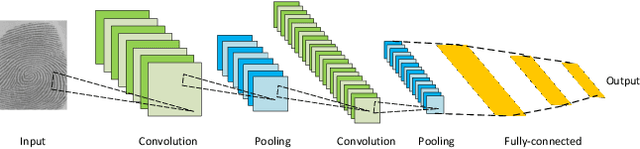
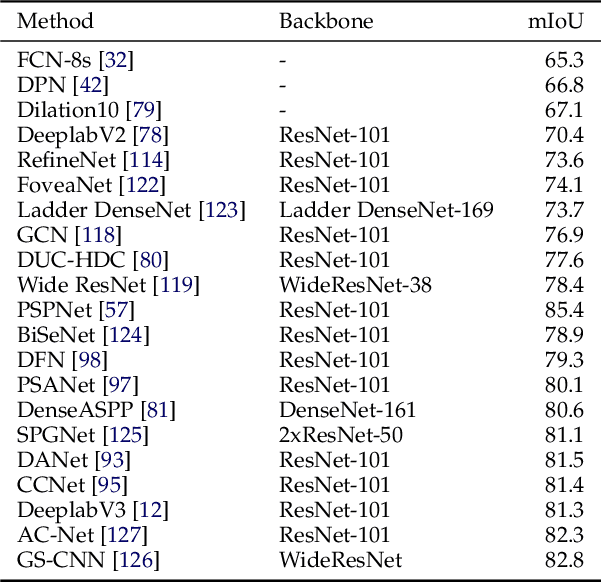
Image segmentation is a key topic in image processing and computer vision with applications such as scene understanding, medical image analysis, robotic perception, video surveillance, augmented reality, and image compression, among many others. Various algorithms for image segmentation have been developed in the literature. Recently, due to the success of deep learning models in a wide range of vision applications, there has been a substantial amount of works aimed at developing image segmentation approaches using deep learning models. In this survey, we provide a comprehensive review of the literature at the time of this writing, covering a broad spectrum of pioneering works for semantic and instance-level segmentation, including fully convolutional pixel-labeling networks, encoder-decoder architectures, multi-scale and pyramid based approaches, recurrent networks, visual attention models, and generative models in adversarial settings. We investigate the similarity, strengths and challenges of these deep learning models, examine the most widely used datasets, report performances, and discuss promising future research directions in this area.
DenseTact: Optical Tactile Sensor for Dense Shape Reconstruction
Jan 04, 2022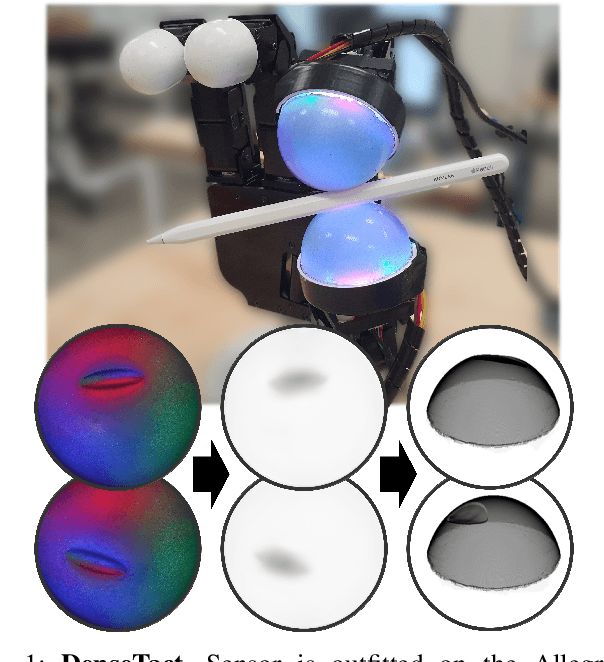
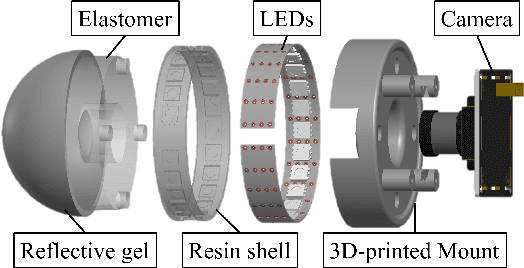
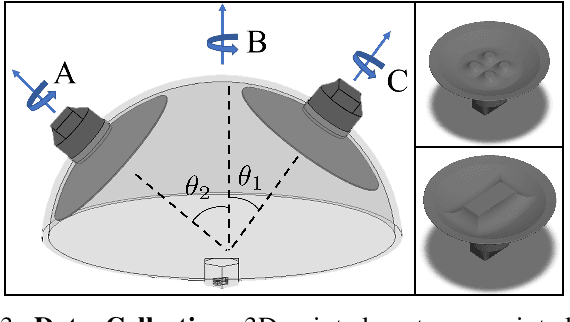
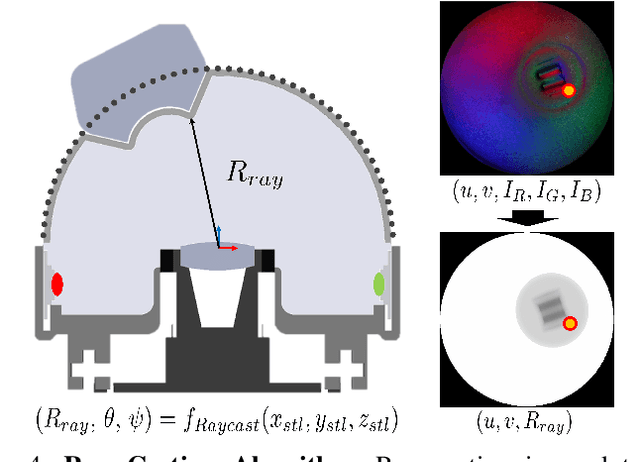
Increasing the performance of tactile sensing in robots enables versatile, in-hand manipulation. Vision-based tactile sensors have been widely used as rich tactile feedback has been shown to be correlated with increased performance in manipulation tasks. Existing tactile sensor solutions with high resolution have limitations that include low accuracy, expensive components, or lack of scalability. In this paper, an inexpensive, scalable, and compact tactile sensor with high-resolution surface deformation modeling for surface reconstruction of the 3D sensor surface is proposed. By measuring the image from the fisheye camera, it is shown that the sensor can successfully estimate the surface deformation in real-time (1.8ms) by using deep convolutional neural networks. This sensor in its design and sensing abilities represents a significant step toward better object in-hand localization, classification, and surface estimation all enabled by high-resolution shape reconstruction.
Inferring Offensiveness In Images From Natural Language Supervision
Oct 08, 2021
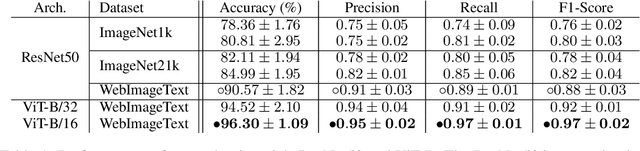
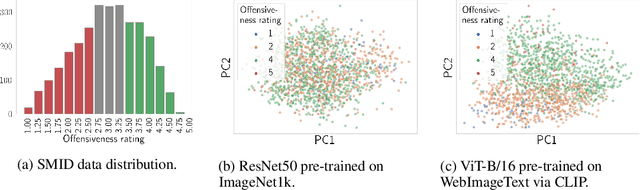
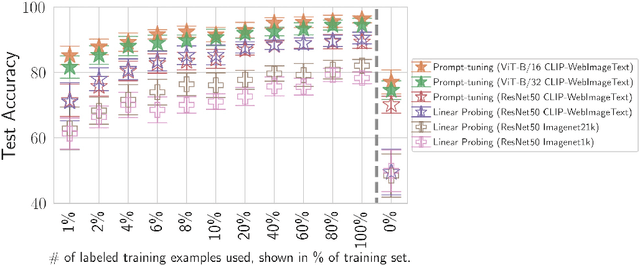
Probing or fine-tuning (large-scale) pre-trained models results in state-of-the-art performance for many NLP tasks and, more recently, even for computer vision tasks when combined with image data. Unfortunately, these approaches also entail severe risks. In particular, large image datasets automatically scraped from the web may contain derogatory terms as categories and offensive images, and may also underrepresent specific classes. Consequently, there is an urgent need to carefully document datasets and curate their content. Unfortunately, this process is tedious and error-prone. We show that pre-trained transformers themselves provide a methodology for the automated curation of large-scale vision datasets. Based on human-annotated examples and the implicit knowledge of a CLIP based model, we demonstrate that one can select relevant prompts for rating the offensiveness of an image. In addition to e.g. privacy violation and pornographic content previously identified in ImageNet, we demonstrate that our approach identifies further inappropriate and potentially offensive content.
Improving Fractal Pre-training
Oct 06, 2021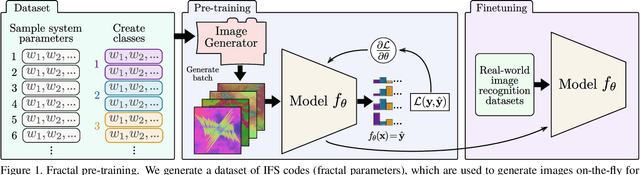

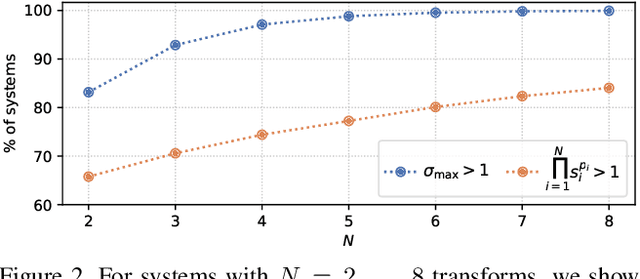

The deep neural networks used in modern computer vision systems require enormous image datasets to train them. These carefully-curated datasets typically have a million or more images, across a thousand or more distinct categories. The process of creating and curating such a dataset is a monumental undertaking, demanding extensive effort and labelling expense and necessitating careful navigation of technical and social issues such as label accuracy, copyright ownership, and content bias. What if we had a way to harness the power of large image datasets but with few or none of the major issues and concerns currently faced? This paper extends the recent work of Kataoka et. al. (2020), proposing an improved pre-training dataset based on dynamically-generated fractal images. Challenging issues with large-scale image datasets become points of elegance for fractal pre-training: perfect label accuracy at zero cost; no need to store/transmit large image archives; no privacy/demographic bias/concerns of inappropriate content, as no humans are pictured; limitless supply and diversity of images; and the images are free/open-source. Perhaps surprisingly, avoiding these difficulties imposes only a small penalty in performance. Leveraging a newly-proposed pre-training task -- multi-instance prediction -- our experiments demonstrate that fine-tuning a network pre-trained using fractals attains 92.7-98.1\% of the accuracy of an ImageNet pre-trained network.
On-Device Text Image Super Resolution
Nov 20, 2020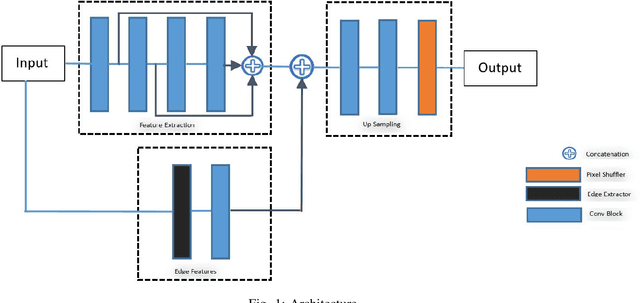

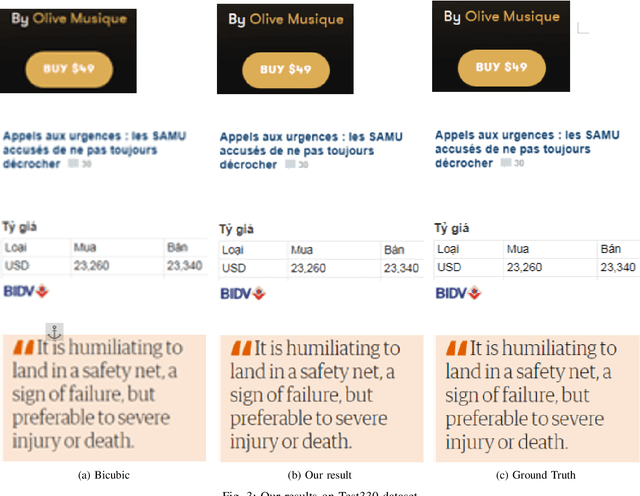

Recent research on super-resolution (SR) has witnessed major developments with the advancements of deep convolutional neural networks. There is a need for information extraction from scenic text images or even document images on device, most of which are low-resolution (LR) images. Therefore, SR becomes an essential pre-processing step as Bicubic Upsampling, which is conventionally present in smartphones, performs poorly on LR images. To give the user more control over his privacy, and to reduce the carbon footprint by reducing the overhead of cloud computing and hours of GPU usage, executing SR models on the edge is a necessity in the recent times. There are various challenges in running and optimizing a model on resource-constrained platforms like smartphones. In this paper, we present a novel deep neural network that reconstructs sharper character edges and thus boosts OCR confidence. The proposed architecture not only achieves significant improvement in PSNR over bicubic upsampling on various benchmark datasets but also runs with an average inference time of 11.7 ms per image. We have outperformed state-of-the-art on the Text330 dataset. We also achieve an OCR accuracy of 75.89% on the ICDAR 2015 TextSR dataset, where ground truth has an accuracy of 78.10%.
Image Transformation Network for Privacy-Preserving Deep Neural Networks and Its Security Evaluation
Aug 07, 2020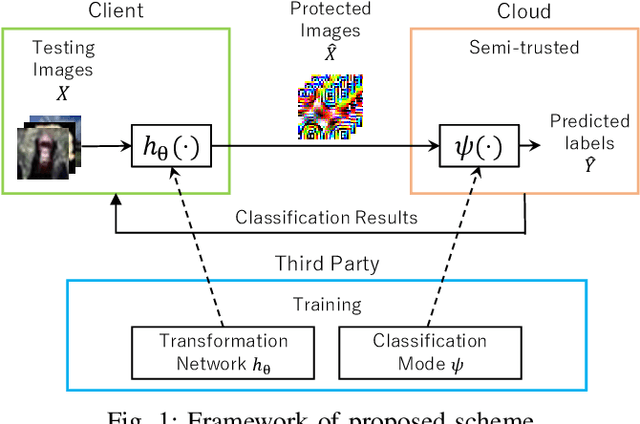
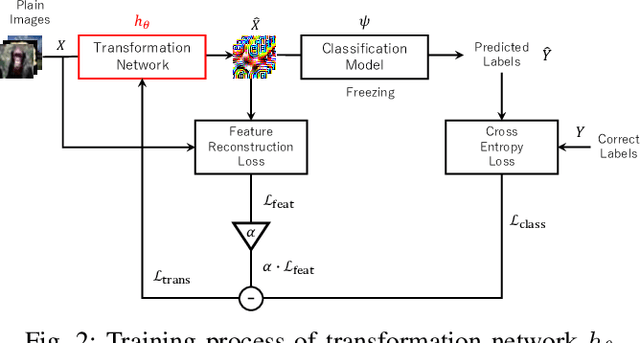

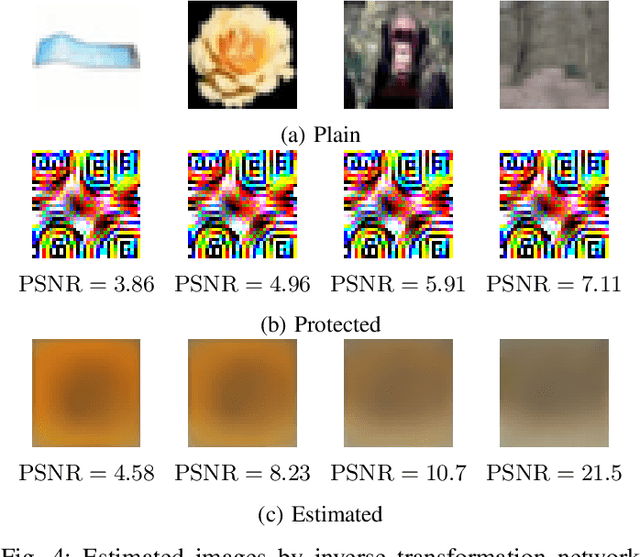
We propose a transformation network for generating visually-protected images for privacy-preserving DNNs. The proposed transformation network is trained by using a plain image dataset so that plain images are transformed into visually protected ones. Conventional perceptual encryption methods have a weak visual-protection performance and some accuracy degradation in image classification. In contrast, the proposed network enables us not only to strongly protect visual information but also to maintain the image classification accuracy that using plain images achieves. In an image classification experiment, the proposed network is demonstrated to strongly protect visual information on plain images without any performance degradation under the use of CIFAR datasets. In addition, it is shown that the visually protected images are robust against a DNN-based attack, called inverse transformation network attack (ITN-Attack) in an experiment.
VRT: A Video Restoration Transformer
Jan 28, 2022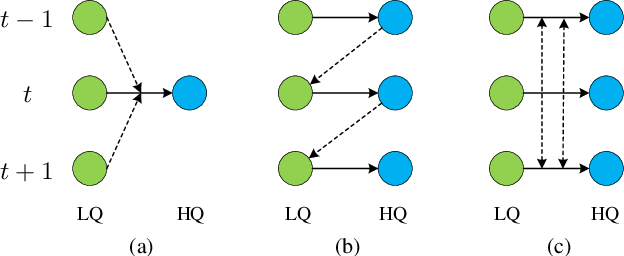
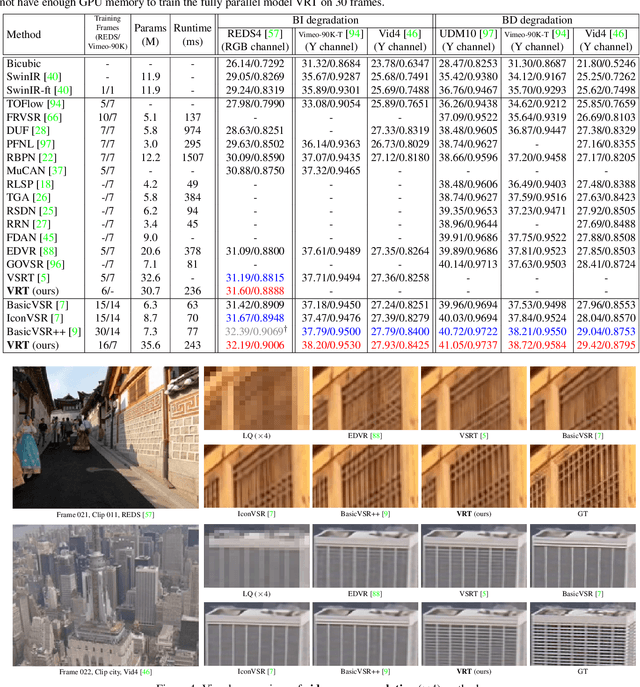
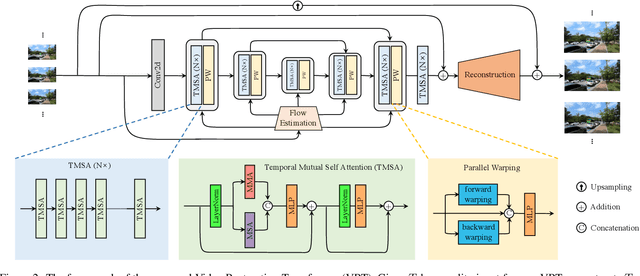
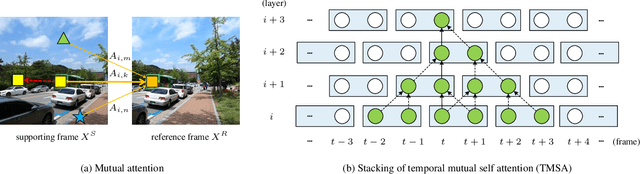
Video restoration (e.g., video super-resolution) aims to restore high-quality frames from low-quality frames. Different from single image restoration, video restoration generally requires to utilize temporal information from multiple adjacent but usually misaligned video frames. Existing deep methods generally tackle with this by exploiting a sliding window strategy or a recurrent architecture, which either is restricted by frame-by-frame restoration or lacks long-range modelling ability. In this paper, we propose a Video Restoration Transformer (VRT) with parallel frame prediction and long-range temporal dependency modelling abilities. More specifically, VRT is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (TMSA) and parallel warping. TMSA divides the video into small clips, on which mutual attention is applied for joint motion estimation, feature alignment and feature fusion, while self attention is used for feature extraction. To enable cross-clip interactions, the video sequence is shifted for every other layer. Besides, parallel warping is used to further fuse information from neighboring frames by parallel feature warping. Experimental results on three tasks, including video super-resolution, video deblurring and video denoising, demonstrate that VRT outperforms the state-of-the-art methods by large margins ($\textbf{up to 2.16dB}$) on nine benchmark datasets.
Achieving Human Parity on Visual Question Answering
Nov 18, 2021
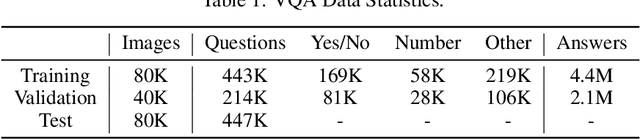
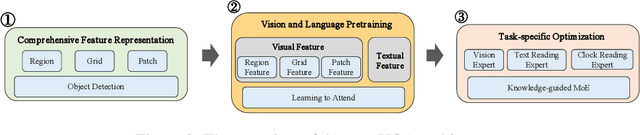
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.