 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Stable Self-Supervised Object Representations in Unconstrained Egocentric Video
Mar 14, 2026Humans develop visual intelligence through perceiving and interacting with their environment - a self-supervised learning process grounded in egocentric experience. Inspired by this, we ask how can artificial systems learn stable object representations from continuous, uncurated first-person videos without relying on manual annotations. This setting poses challenges of separating, recognizing, and persistently tracking objects amid clutter, occlusion, and ego-motion. We propose EgoViT, a unified vision Transformer framework designed to learn stable object representations from unlabeled egocentric video. EgoViT bootstraps this learning process by jointly discovering and stabilizing "proto-objects" through three synergistic mechanisms: (1) Proto-object Learning, which uses intra-frame distillation to form discriminative representations; (2) Depth Regularization, which grounds these representations in geometric structure; and (3) Teacher-Filtered Temporal Consistency, which enforces identity over time. This creates a virtuous cycle where initial object hypotheses are progressively refined into stable, persistent representations. The framework is trained end-to-end on unlabeled first-person videos and exhibits robustness to geometric priors of varied origin and quality. On standard benchmarks, EgoViT achieves +8.0% CorLoc improvement in unsupervised object discovery and +4.8% mIoU improvement in semantic segmentation, demonstrating its potential to lay a foundation for robust visual abstraction in embodied intelligence.
PsyMem: Fine-grained psychological alignment and Explicit Memory Control for Advanced Role-Playing LLMs
May 19, 2025



Existing LLM-based role-playing methods often rely on superficial textual descriptions or simplistic metrics, inadequately modeling both intrinsic and extrinsic character dimensions. Additionally, they typically simulate character memory with implicit model knowledge or basic retrieval augment generation without explicit memory alignment, compromising memory consistency. The two issues weaken reliability of role-playing LLMs in several applications, such as trustworthy social simulation. To address these limitations, we propose PsyMem, a novel framework integrating fine-grained psychological attributes and explicit memory control for role-playing. PsyMem supplements textual descriptions with 26 psychological indicators to detailed model character. Additionally, PsyMem implements memory alignment training, explicitly trains the model to align character's response with memory, thereby enabling dynamic memory-controlled responding during inference. By training Qwen2.5-7B-Instruct on our specially designed dataset (including 5,414 characters and 38,962 dialogues extracted from novels), the resulting model, termed as PsyMem-Qwen, outperforms baseline models in role-playing, achieving the best performance in human-likeness and character fidelity.
FTMixer: Frequency and Time Domain Representations Fusion for Time Series Modeling
May 24, 2024



Time series data can be represented in both the time and frequency domains, with the time domain emphasizing local dependencies and the frequency domain highlighting global dependencies. To harness the strengths of both domains in capturing local and global dependencies, we propose the Frequency and Time Domain Mixer (FTMixer). To exploit the global characteristics of the frequency domain, we introduce the Frequency Channel Convolution (FCC) module, designed to capture global inter-series dependencies. Inspired by the windowing concept in frequency domain transformations, we present the Windowing Frequency Convolution (WFC) module to capture local dependencies. The WFC module first applies frequency transformation within each window, followed by convolution across windows. Furthermore, to better capture these local dependencies, we employ channel-independent scheme to mix the time domain and frequency domain patches. Notably, FTMixer employs the Discrete Cosine Transformation (DCT) with real numbers instead of the complex-number-based Discrete Fourier Transformation (DFT), enabling direct utilization of modern deep learning operators in the frequency domain. Extensive experimental results across seven real-world long-term time series datasets demonstrate the superiority of FTMixer, in terms of both forecasting performance and computational efficiency.
BIFRNet: A Brain-Inspired Feature Restoration DNN for Partially Occluded Image Recognition
Mar 16, 2023



The partially occluded image recognition (POIR) problem has been a challenge for artificial intelligence for a long time. A common strategy to handle the POIR problem is using the non-occluded features for classification. Unfortunately, this strategy will lose effectiveness when the image is severely occluded, since the visible parts can only provide limited information. Several studies in neuroscience reveal that feature restoration which fills in the occluded information and is called amodal completion is essential for human brains to recognize partially occluded images. However, feature restoration is commonly ignored by CNNs, which may be the reason why CNNs are ineffective for the POIR problem. Inspired by this, we propose a novel brain-inspired feature restoration network (BIFRNet) to solve the POIR problem. It mimics a ventral visual pathway to extract image features and a dorsal visual pathway to distinguish occluded and visible image regions. In addition, it also uses a knowledge module to store object prior knowledge and uses a completion module to restore occluded features based on visible features and prior knowledge. Thorough experiments on synthetic and real-world occluded image datasets show that BIFRNet outperforms the existing methods in solving the POIR problem. Especially for severely occluded images, BIRFRNet surpasses other methods by a large margin and is close to the human brain performance. Furthermore, the brain-inspired design makes BIFRNet more interpretable.
Dual Complementary Dynamic Convolution for Image Recognition
Nov 11, 2022As a powerful engine, vanilla convolution has promoted huge breakthroughs in various computer tasks. However, it often suffers from sample and content agnostic problems, which limits the representation capacities of the convolutional neural networks (CNNs). In this paper, we for the first time model the scene features as a combination of the local spatial-adaptive parts owned by the individual and the global shift-invariant parts shared to all individuals, and then propose a novel two-branch dual complementary dynamic convolution (DCDC) operator to flexibly deal with these two types of features. The DCDC operator overcomes the limitations of vanilla convolution and most existing dynamic convolutions who capture only spatial-adaptive features, and thus markedly boosts the representation capacities of CNNs. Experiments show that the DCDC operator based ResNets (DCDC-ResNets) significantly outperform vanilla ResNets and most state-of-the-art dynamic convolutional networks on image classification, as well as downstream tasks including object detection, instance and panoptic segmentation tasks, while with lower FLOPs and parameters.
Consistency Regularization for Deep Face Anti-Spoofing
Nov 25, 2021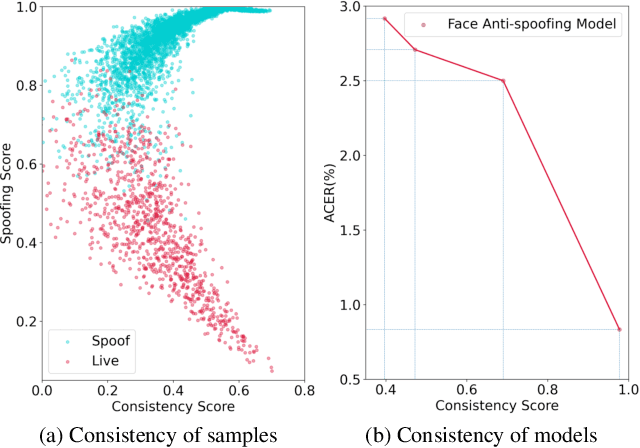

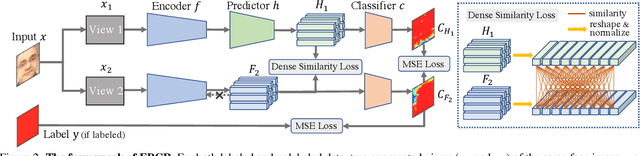

Face anti-spoofing (FAS) plays a crucial role in securing face recognition systems. Empirically, given an image, a model with more consistent output on different views of this image usually performs better, as shown in Fig.1. Motivated by this exciting observation, we conjecture that encouraging feature consistency of different views may be a promising way to boost FAS models. In this paper, we explore this way thoroughly by enhancing both Embedding-level and Prediction-level Consistency Regularization (EPCR) in FAS. Specifically, at the embedding-level, we design a dense similarity loss to maximize the similarities between all positions of two intermediate feature maps in a self-supervised fashion; while at the prediction-level, we optimize the mean square error between the predictions of two views. Notably, our EPCR is free of annotations and can directly integrate into semi-supervised learning schemes. Considering different application scenarios, we further design five diverse semi-supervised protocols to measure semi-supervised FAS techniques. We conduct extensive experiments to show that EPCR can significantly improve the performance of several supervised and semi-supervised tasks on benchmark datasets. The codes and protocols will be released at https://github.com/clks-wzz/EPCR.
Meta-Teacher For Face Anti-Spoofing
Nov 12, 2021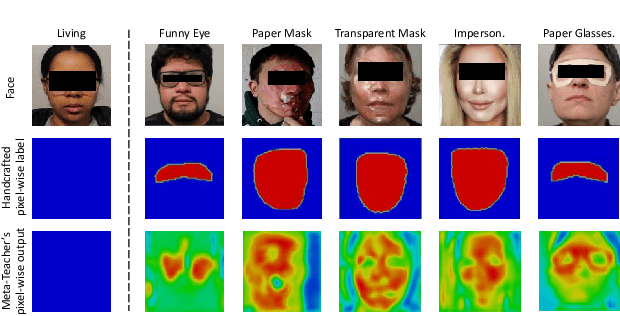
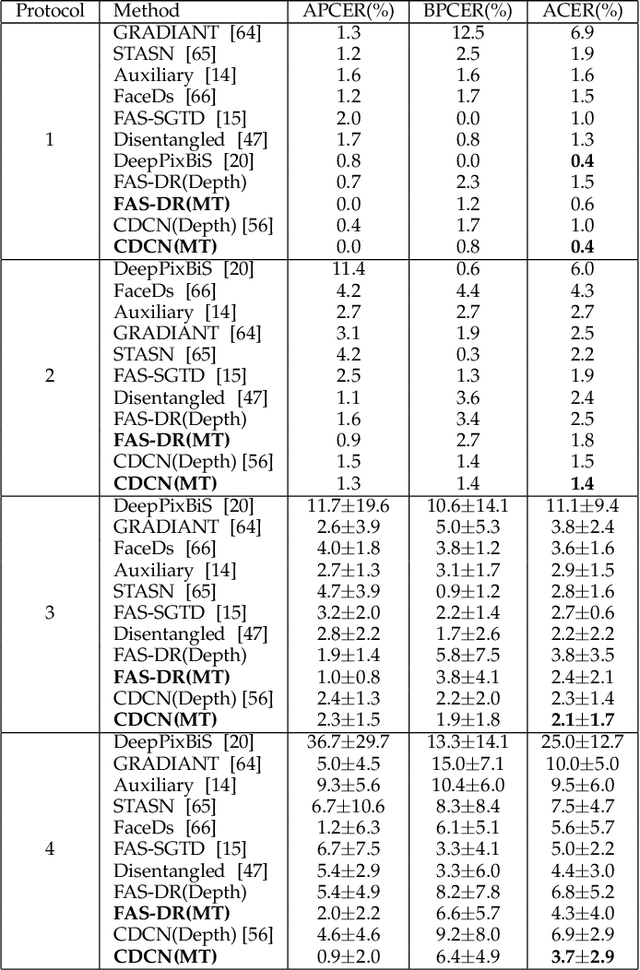
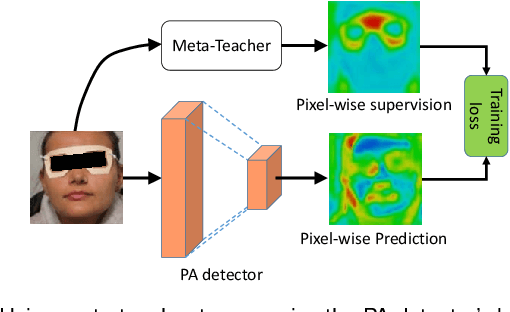
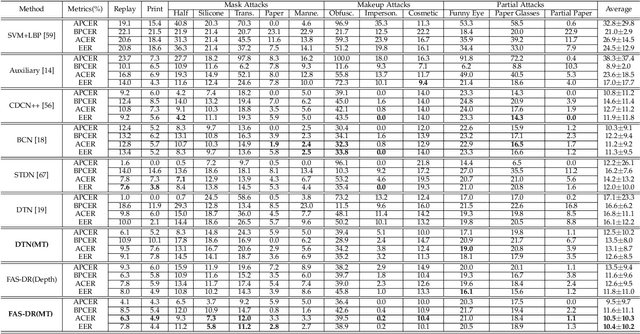
Face anti-spoofing (FAS) secures face recognition from presentation attacks (PAs). Existing FAS methods usually supervise PA detectors with handcrafted binary or pixel-wise labels. However, handcrafted labels may are not the most adequate way to supervise PA detectors learning sufficient and intrinsic spoofing cues. Instead of using the handcrafted labels, we propose a novel Meta-Teacher FAS (MT-FAS) method to train a meta-teacher for supervising PA detectors more effectively. The meta-teacher is trained in a bi-level optimization manner to learn the ability to supervise the PA detectors learning rich spoofing cues. The bi-level optimization contains two key components: 1) a lower-level training in which the meta-teacher supervises the detector's learning process on the training set; and 2) a higher-level training in which the meta-teacher's teaching performance is optimized by minimizing the detector's validation loss. Our meta-teacher differs significantly from existing teacher-student models because the meta-teacher is explicitly trained for better teaching the detector (student), whereas existing teachers are trained for outstanding accuracy neglecting teaching ability. Extensive experiments on five FAS benchmarks show that with the proposed MT-FAS, the trained meta-teacher 1) provides better-suited supervision than both handcrafted labels and existing teacher-student models; and 2) significantly improves the performances of PA detectors.
Adversarial Attack across Datasets
Oct 13, 2021
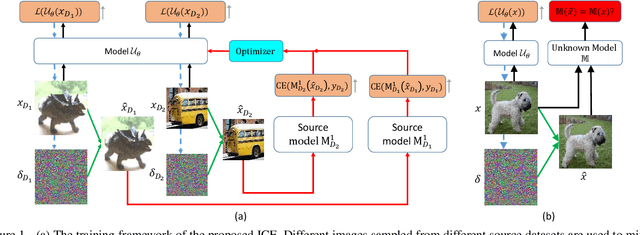
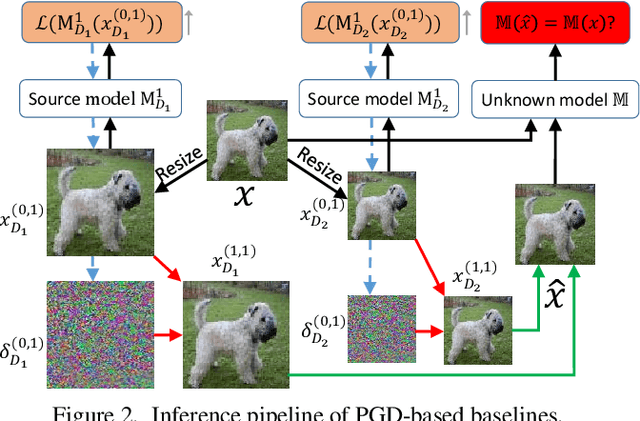
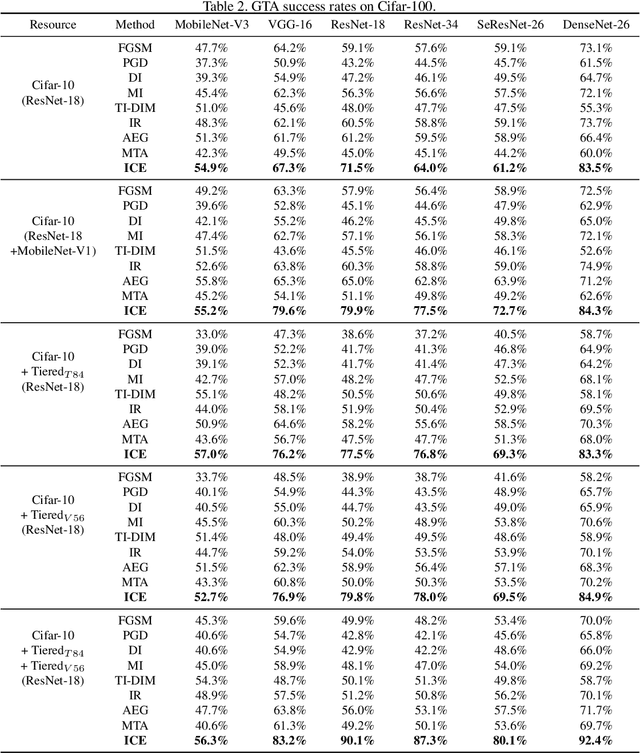
It has been observed that Deep Neural Networks (DNNs) are vulnerable to transfer attacks in the query-free black-box setting. However, all the previous studies on transfer attack assume that the white-box surrogate models possessed by the attacker and the black-box victim models are trained on the same dataset, which means the attacker implicitly knows the label set and the input size of the victim model. However, this assumption is usually unrealistic as the attacker may not know the dataset used by the victim model, and further, the attacker needs to attack any randomly encountered images that may not come from the same dataset. Therefore, in this paper we define a new Generalized Transferable Attack (GTA) problem where we assume the attacker has a set of surrogate models trained on different datasets (with different label sets and image sizes), and none of them is equal to the dataset used by the victim model. We then propose a novel method called Image Classification Eraser (ICE) to erase classification information for any encountered images from arbitrary dataset. Extensive experiments on Cifar-10, Cifar-100, and TieredImageNet demonstrate the effectiveness of the proposed ICE on the GTA problem. Furthermore, we show that existing transfer attack methods can be modified to tackle the GTA problem, but with significantly worse performance compared with ICE.
Training Meta-Surrogate Model for Transferable Adversarial Attack
Sep 07, 2021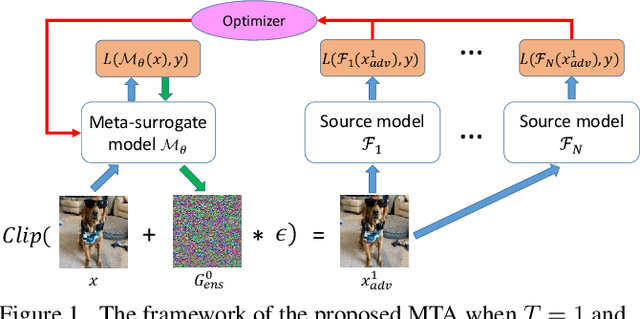
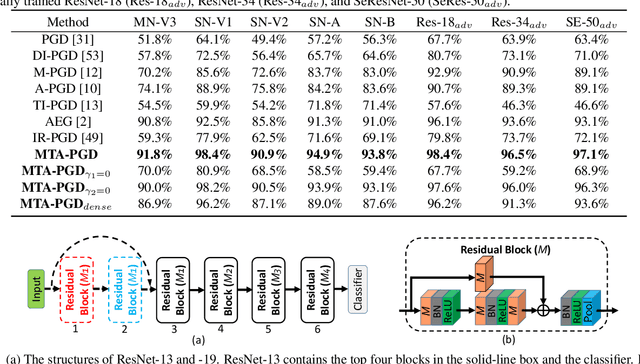
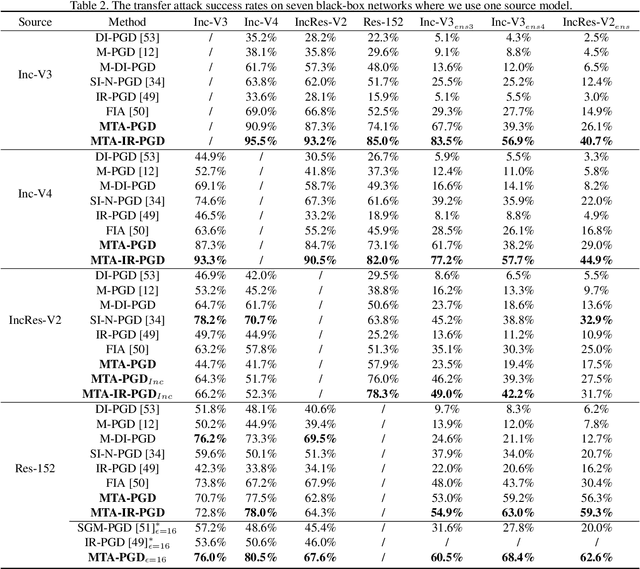
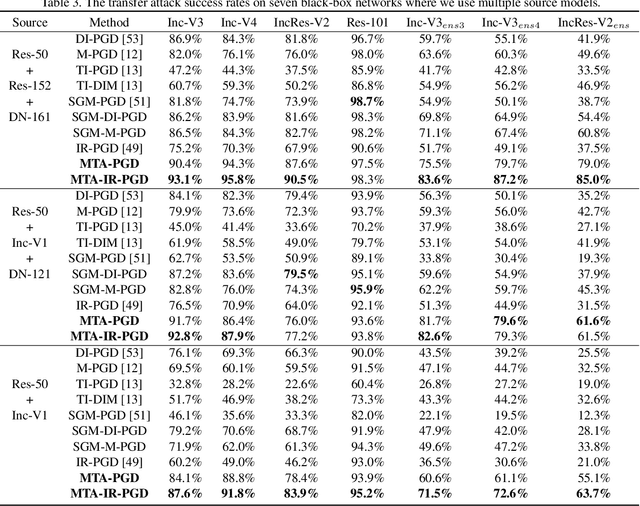
We consider adversarial attacks to a black-box model when no queries are allowed. In this setting, many methods directly attack surrogate models and transfer the obtained adversarial examples to fool the target model. Plenty of previous works investigated what kind of attacks to the surrogate model can generate more transferable adversarial examples, but their performances are still limited due to the mismatches between surrogate models and the target model. In this paper, we tackle this problem from a novel angle -- instead of using the original surrogate models, can we obtain a Meta-Surrogate Model (MSM) such that attacks to this model can be easier transferred to other models? We show that this goal can be mathematically formulated as a well-posed (bi-level-like) optimization problem and design a differentiable attacker to make training feasible. Given one or a set of surrogate models, our method can thus obtain an MSM such that adversarial examples generated on MSM enjoy eximious transferability. Comprehensive experiments on Cifar-10 and ImageNet demonstrate that by attacking the MSM, we can obtain stronger transferable adversarial examples to fool black-box models including adversarially trained ones, with much higher success rates than existing methods. The proposed method reveals significant security challenges of deep models and is promising to be served as a state-of-the-art benchmark for evaluating the robustness of deep models in the black-box setting.
PoseFace: Pose-Invariant Features and Pose-Adaptive Loss for Face Recognition
Jul 25, 2021
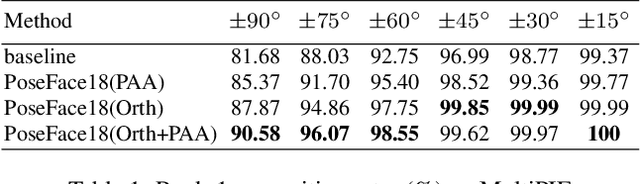
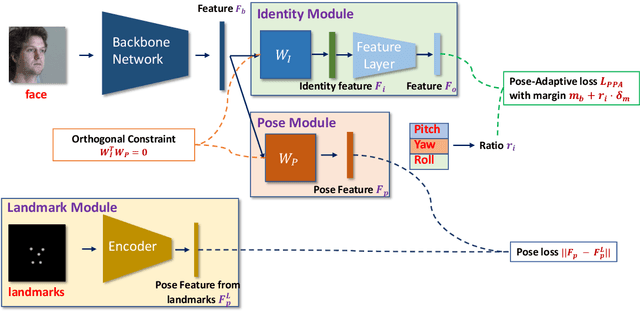
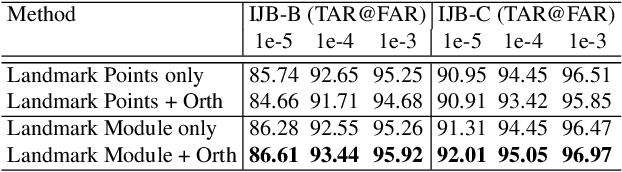
Despite the great success achieved by deep learning methods in face recognition, severe performance drops are observed for large pose variations in unconstrained environments (e.g., in cases of surveillance and photo-tagging). To address it, current methods either deploy pose-specific models or frontalize faces by additional modules. Still, they ignore the fact that identity information should be consistent across poses and are not realizing the data imbalance between frontal and profile face images during training. In this paper, we propose an efficient PoseFace framework which utilizes the facial landmarks to disentangle the pose-invariant features and exploits a pose-adaptive loss to handle the imbalance issue adaptively. Extensive experimental results on the benchmarks of Multi-PIE, CFP, CPLFW and IJB have demonstrated the superiority of our method over the state-of-the-arts.