 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Multimodal Geospatial Foundation Models: Techniques, Applications, and Challenges
Oct 27, 2025Foundation models have transformed natural language processing and computer vision, and their impact is now reshaping remote sensing image analysis. With powerful generalization and transfer learning capabilities, they align naturally with the multimodal, multi-resolution, and multi-temporal characteristics of remote sensing data. To address unique challenges in the field, multimodal geospatial foundation models (GFMs) have emerged as a dedicated research frontier. This survey delivers a comprehensive review of multimodal GFMs from a modality-driven perspective, covering five core visual and vision-language modalities. We examine how differences in imaging physics and data representation shape interaction design, and we analyze key techniques for alignment, integration, and knowledge transfer to tackle modality heterogeneity, distribution shifts, and semantic gaps. Advances in training paradigms, architectures, and task-specific adaptation strategies are systematically assessed alongside a wealth of emerging benchmarks. Representative multimodal visual and vision-language GFMs are evaluated across ten downstream tasks, with insights into their architectures, performance, and application scenarios. Real-world case studies, spanning land cover mapping, agricultural monitoring, disaster response, climate studies, and geospatial intelligence, demonstrate the practical potential of GFMs. Finally, we outline pressing challenges in domain generalization, interpretability, efficiency, and privacy, and chart promising avenues for future research.
Hyperspectral Imaging
Aug 11, 2025



Hyperspectral imaging (HSI) is an advanced sensing modality that simultaneously captures spatial and spectral information, enabling non-invasive, label-free analysis of material, chemical, and biological properties. This Primer presents a comprehensive overview of HSI, from the underlying physical principles and sensor architectures to key steps in data acquisition, calibration, and correction. We summarize common data structures and highlight classical and modern analysis methods, including dimensionality reduction, classification, spectral unmixing, and AI-driven techniques such as deep learning. Representative applications across Earth observation, precision agriculture, biomedicine, industrial inspection, cultural heritage, and security are also discussed, emphasizing HSI's ability to uncover sub-visual features for advanced monitoring, diagnostics, and decision-making. Persistent challenges, such as hardware trade-offs, acquisition variability, and the complexity of high-dimensional data, are examined alongside emerging solutions, including computational imaging, physics-informed modeling, cross-modal fusion, and self-supervised learning. Best practices for dataset sharing, reproducibility, and metadata documentation are further highlighted to support transparency and reuse. Looking ahead, we explore future directions toward scalable, real-time, and embedded HSI systems, driven by sensor miniaturization, self-supervised learning, and foundation models. As HSI evolves into a general-purpose, cross-disciplinary platform, it holds promise for transformative applications in science, technology, and society.
SAM-Based Building Change Detection with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping
Apr 17, 2025Building change detection remains challenging for urban development, disaster assessment, and military reconnaissance. While foundation models like Segment Anything Model (SAM) show strong segmentation capabilities, SAM is limited in the task of building change detection due to domain gap issues. Existing adapter-based fine-tuning approaches face challenges with imbalanced building distribution, resulting in poor detection of subtle changes and inaccurate edge extraction. Additionally, bi-temporal misalignment in change detection, typically addressed by optical flow, remains vulnerable to background noises. This affects the detection of building changes and compromises both detection accuracy and edge recognition. To tackle these challenges, we propose a new SAM-Based Network with Distribution-Aware Fourier Adaptation and Edge-Constrained Warping (FAEWNet) for building change detection. FAEWNet utilizes the SAM encoder to extract rich visual features from remote sensing images. To guide SAM in focusing on specific ground objects in remote sensing scenes, we propose a Distribution-Aware Fourier Aggregated Adapter to aggregate task-oriented changed information. This adapter not only effectively addresses the domain gap issue, but also pays attention to the distribution of changed buildings. Furthermore, to mitigate noise interference and misalignment in height offset estimation, we design a novel flow module that refines building edge extraction and enhances the perception of changed buildings. Our state-of-the-art results on the LEVIR-CD, S2Looking and WHU-CD datasets highlight the effectiveness of FAEWNet. The code is available at https://github.com/SUPERMAN123000/FAEWNet.
IGroupSS-Mamba: Interval Group Spatial-Spectral Mamba for Hyperspectral Image Classification
Oct 07, 2024



Hyperspectral image (HSI) classification has garnered substantial attention in remote sensing fields. Recent Mamba architectures built upon the Selective State Space Models (S6) have demonstrated enormous potential in long-range sequence modeling. However, the high dimensionality of hyperspectral data and information redundancy pose challenges to the application of Mamba in HSI classification, suffering from suboptimal performance and computational efficiency. In light of this, this paper investigates a lightweight Interval Group Spatial-Spectral Mamba framework (IGroupSS-Mamba) for HSI classification, which allows for multi-directional and multi-scale global spatial-spectral information extraction in a grouping and hierarchical manner. Technically, an Interval Group S6 Mechanism (IGSM) is developed as the core component, which partitions high-dimensional features into multiple non-overlapping groups at intervals, and then integrates a unidirectional S6 for each group with a specific scanning direction to achieve non-redundant sequence modeling. Compared to conventional applying multi-directional scanning to all bands, this grouping strategy leverages the complementary strengths of different scanning directions while decreasing computational costs. To adequately capture the spatial-spectral contextual information, an Interval Group Spatial-Spectral Block (IGSSB) is introduced, in which two IGSM-based spatial and spectral operators are cascaded to characterize the global spatial-spectral relationship along the spatial and spectral dimensions, respectively. IGroupSS-Mamba is constructed as a hierarchical structure stacked by multiple IGSSB blocks, integrating a pixel aggregation-based downsampling strategy for multiscale spatial-spectral semantic learning from shallow to deep stages. Extensive experiments demonstrate that IGroupSS-Mamba outperforms the state-of-the-art methods.
Hyperspectral Pansharpening: Critical Review, Tools and Future Perspectives
Jul 01, 2024Hyperspectral pansharpening consists of fusing a high-resolution panchromatic band and a low-resolution hyperspectral image to obtain a new image with high resolution in both the spatial and spectral domains. These remote sensing products are valuable for a wide range of applications, driving ever growing research efforts. Nonetheless, results still do not meet application demands. In part, this comes from the technical complexity of the task: compared to multispectral pansharpening, many more bands are involved, in a spectral range only partially covered by the panchromatic component and with overwhelming noise. However, another major limiting factor is the absence of a comprehensive framework for the rapid development and accurate evaluation of new methods. This paper attempts to address this issue. We started by designing a dataset large and diverse enough to allow reliable training (for data-driven methods) and testing of new methods. Then, we selected a set of state-of-the-art methods, following different approaches, characterized by promising performance, and reimplemented them in a single PyTorch framework. Finally, we carried out a critical comparative analysis of all methods, using the most accredited quality indicators. The analysis highlights the main limitations of current solutions in terms of spectral/spatial quality and computational efficiency, and suggests promising research directions. To ensure full reproducibility of the results and support future research, the framework (including codes, evaluation procedures and links to the dataset) is shared on https://github.com/matciotola/hyperspectral_pansharpening_toolbox, as a single Python-based reference benchmark toolbox.
3DSS-Mamba: 3D-Spectral-Spatial Mamba for Hyperspectral Image Classification
May 21, 2024



Hyperspectral image (HSI) classification constitutes the fundamental research in remote sensing fields. Convolutional Neural Networks (CNNs) and Transformers have demonstrated impressive capability in capturing spectral-spatial contextual dependencies. However, these architectures suffer from limited receptive fields and quadratic computational complexity, respectively. Fortunately, recent Mamba architectures built upon the State Space Model integrate the advantages of long-range sequence modeling and linear computational efficiency, exhibiting substantial potential in low-dimensional scenarios. Motivated by this, we propose a novel 3D-Spectral-Spatial Mamba (3DSS-Mamba) framework for HSI classification, allowing for global spectral-spatial relationship modeling with greater computational efficiency. Technically, a spectral-spatial token generation (SSTG) module is designed to convert the HSI cube into a set of 3D spectral-spatial tokens. To overcome the limitations of traditional Mamba, which is confined to modeling causal sequences and inadaptable to high-dimensional scenarios, a 3D-Spectral-Spatial Selective Scanning (3DSS) mechanism is introduced, which performs pixel-wise selective scanning on 3D hyperspectral tokens along the spectral and spatial dimensions. Five scanning routes are constructed to investigate the impact of dimension prioritization. The 3DSS scanning mechanism combined with conventional mapping operations forms the 3D-spectral-spatial mamba block (3DMB), enabling the extraction of global spectral-spatial semantic representations. Experimental results and analysis demonstrate that the proposed method outperforms the state-of-the-art methods on HSI classification benchmarks.
Lightweight Change Detection in Heterogeneous Remote Sensing Images with Online All-Integer Pruning Training
May 03, 2024Detection of changes in heterogeneous remote sensing images is vital, especially in response to emergencies like earthquakes and floods. Current homogenous transformation-based change detection (CD) methods often suffer from high computation and memory costs, which are not friendly to edge-computation devices like onboard CD devices at satellites. To address this issue, this paper proposes a new lightweight CD method for heterogeneous remote sensing images that employs the online all-integer pruning (OAIP) training strategy to efficiently fine-tune the CD network using the current test data. The proposed CD network consists of two visual geometry group (VGG) subnetworks as the backbone architecture. In the OAIP-based training process, all the weights, gradients, and intermediate data are quantized to integers to speed up training and reduce memory usage, where the per-layer block exponentiation scaling scheme is utilized to reduce the computation errors of network parameters caused by quantization. Second, an adaptive filter-level pruning method based on the L1-norm criterion is employed to further lighten the fine-tuning process of the CD network. Experimental results show that the proposed OAIP-based method attains similar detection performance (but with significantly reduced computation complexity and memory usage) in comparison with state-of-the-art CD methods.
SpectralGPT: Spectral Foundation Model
Nov 25, 2023



The foundation model has recently garnered significant attention due to its potential to revolutionize the field of visual representation learning in a self-supervised manner. While most foundation models are tailored to effectively process RGB images for various visual tasks, there is a noticeable gap in research focused on spectral data, which offers valuable information for scene understanding, especially in remote sensing (RS) applications. To fill this gap, we created for the first time a universal RS foundation model, named SpectralGPT, which is purpose-built to handle spectral RS images using a novel 3D generative pretrained transformer (GPT). Compared to existing foundation models, SpectralGPT 1) accommodates input images with varying sizes, resolutions, time series, and regions in a progressive training fashion, enabling full utilization of extensive RS big data; 2) leverages 3D token generation for spatial-spectral coupling; 3) captures spectrally sequential patterns via multi-target reconstruction; 4) trains on one million spectral RS images, yielding models with over 600 million parameters. Our evaluation highlights significant performance improvements with pretrained SpectralGPT models, signifying substantial potential in advancing spectral RS big data applications within the field of geoscience across four downstream tasks: single/multi-label scene classification, semantic segmentation, and change detection.
Hyperspectral Unmixing Based on Nonnegative Matrix Factorization: A Comprehensive Review
May 20, 2022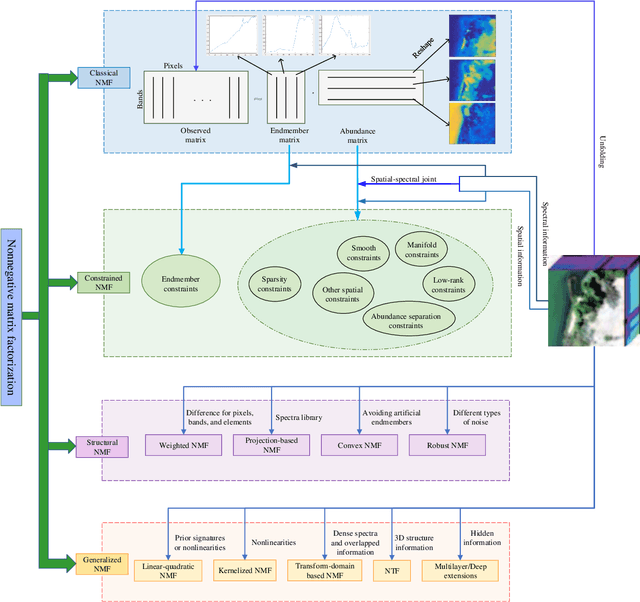
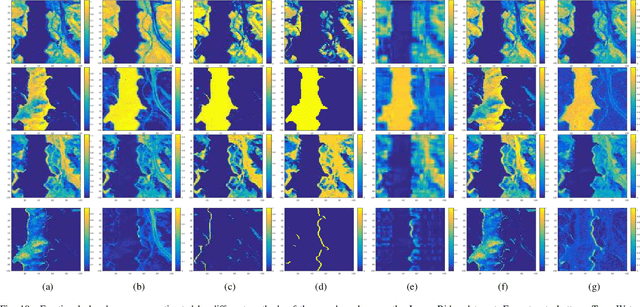
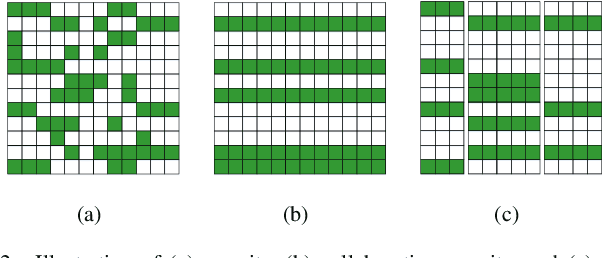
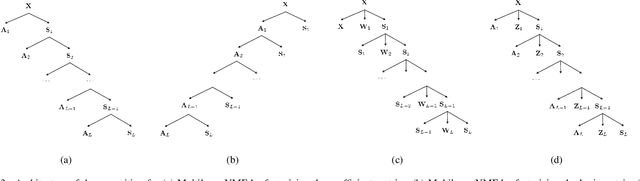
Hyperspectral unmixing has been an important technique that estimates a set of endmembers and their corresponding abundances from a hyperspectral image (HSI). Nonnegative matrix factorization (NMF) plays an increasingly significant role in solving this problem. In this article, we present a comprehensive survey of the NMF-based methods proposed for hyperspectral unmixing. Taking the NMF model as a baseline, we show how to improve NMF by utilizing the main properties of HSIs (e.g., spectral, spatial, and structural information). We categorize three important development directions including constrained NMF, structured NMF, and generalized NMF. Furthermore, several experiments are conducted to illustrate the effectiveness of associated algorithms. Finally, we conclude the article with possible future directions with the purposes of providing guidelines and inspiration to promote the development of hyperspectral unmixing.
A3CLNN: Spatial, Spectral and Multiscale Attention ConvLSTM Neural Network for Multisource Remote Sensing Data Classification
Apr 09, 2022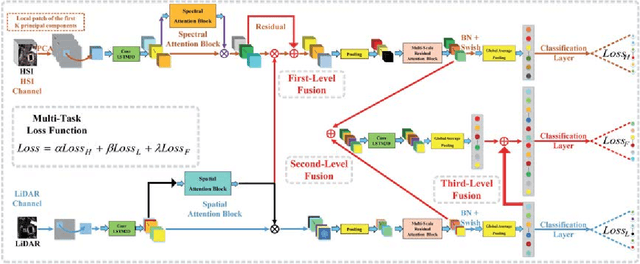
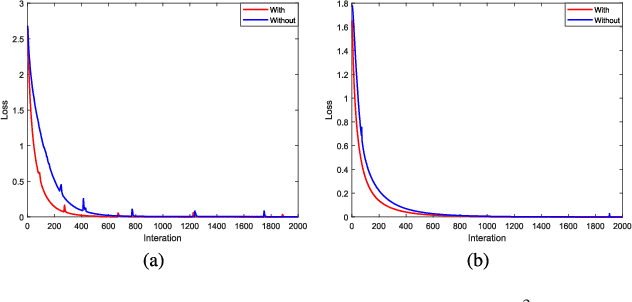
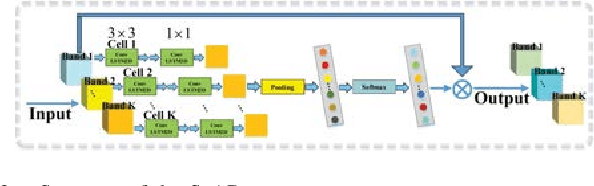
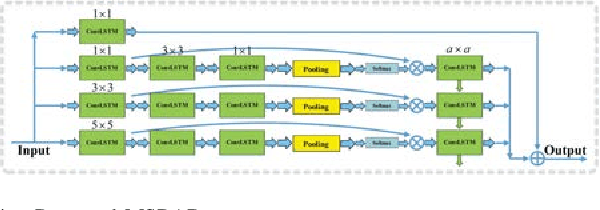
The problem of effectively exploiting the information multiple data sources has become a relevant but challenging research topic in remote sensing. In this paper, we propose a new approach to exploit the complementarity of two data sources: hyperspectral images (HSIs) and light detection and ranging (LiDAR) data. Specifically, we develop a new dual-channel spatial, spectral and multiscale attention convolutional long short-term memory neural network (called dual-channel A3CLNN) for feature extraction and classification of multisource remote sensing data. Spatial, spectral and multiscale attention mechanisms are first designed for HSI and LiDAR data in order to learn spectral- and spatial-enhanced feature representations, and to represent multiscale information for different classes. In the designed fusion network, a novel composite attention learning mechanism (combined with a three-level fusion strategy) is used to fully integrate the features in these two data sources. Finally, inspired by the idea of transfer learning, a novel stepwise training strategy is designed to yield a final classification result. Our experimental results, conducted on several multisource remote sensing data sets, demonstrate that the newly proposed dual-channel A3CLNN exhibits better feature representation ability (leading to more competitive classification performance) than other state-of-the-art methods.
* 16 pages, 10 figures