 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers
Mar 07, 2022
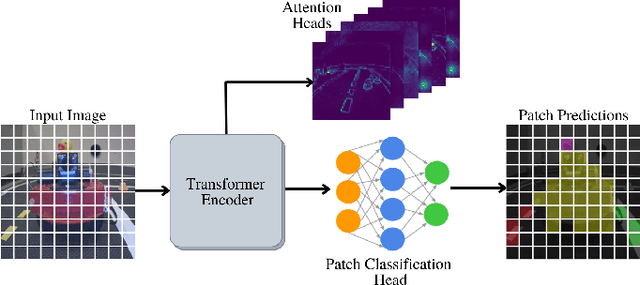

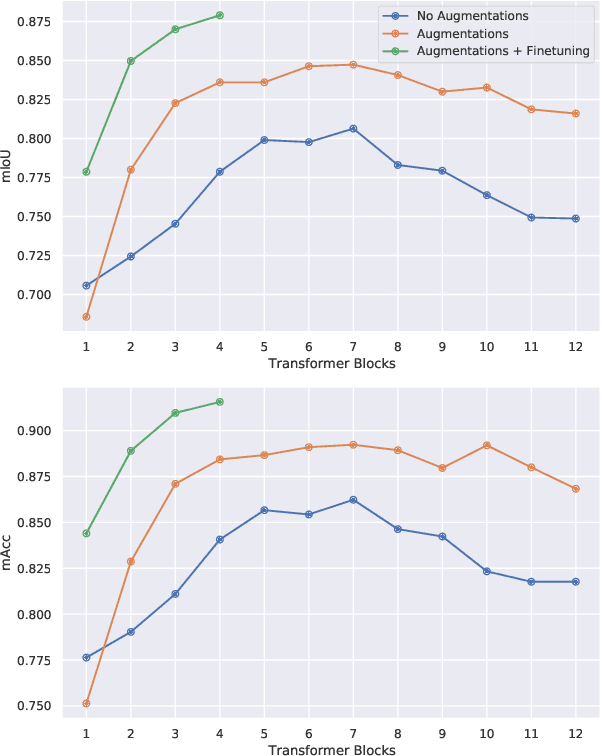

In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentations at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes
May 20, 2022

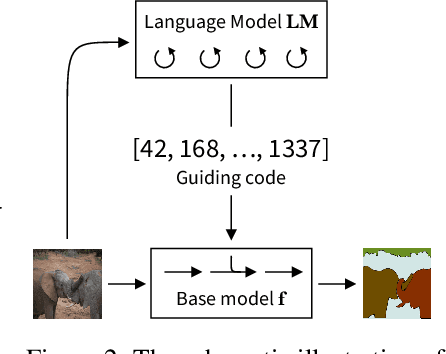

We introduce UViM, a unified approach capable of modeling a wide range of computer vision tasks. In contrast to previous models, UViM has the same functional form for all tasks; it requires no task-specific modifications which require extensive human expertise. The approach involves two components: (I) a base model (feed-forward) which is trained to directly predict raw vision outputs, guided by a learned discrete code and (II) a language model (autoregressive) that is trained to generate the guiding code. These components complement each other: the language model is well-suited to modeling structured interdependent data, while the base model is efficient at dealing with high-dimensional outputs. We demonstrate the effectiveness of UViM on three diverse and challenging vision tasks: panoptic segmentation, depth prediction and image colorization, where we achieve competitive and near state-of-the-art results. Our experimental results suggest that UViM is a promising candidate for a unified modeling approach in computer vision.
Unraveling Attention via Convex Duality: Analysis and Interpretations of Vision Transformers
May 20, 2022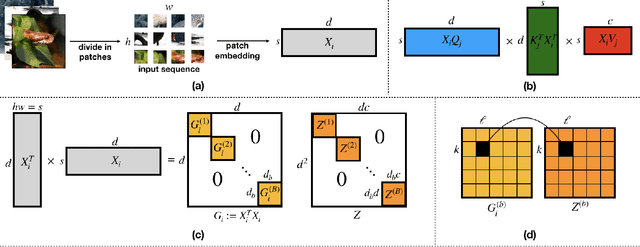
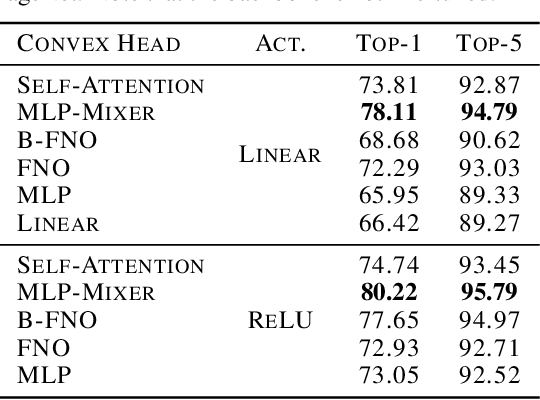
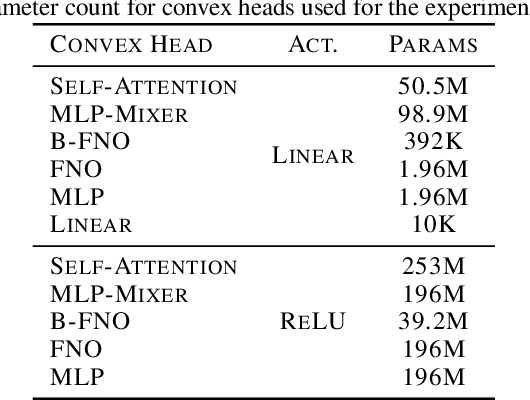
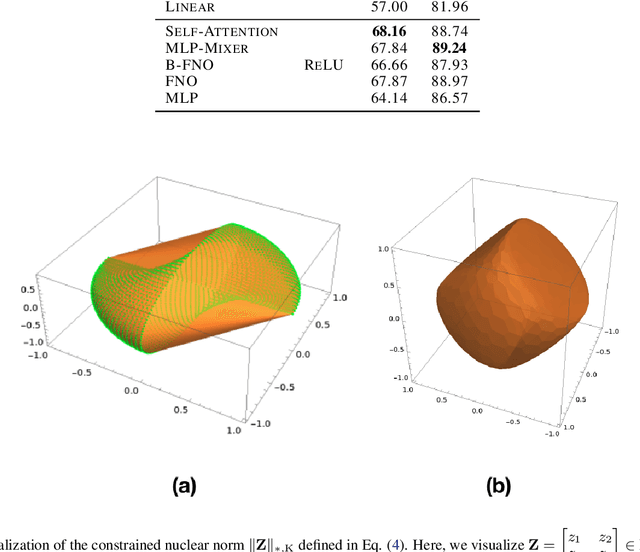
Vision transformers using self-attention or its proposed alternatives have demonstrated promising results in many image related tasks. However, the underpinning inductive bias of attention is not well understood. To address this issue, this paper analyzes attention through the lens of convex duality. For the non-linear dot-product self-attention, and alternative mechanisms such as MLP-mixer and Fourier Neural Operator (FNO), we derive equivalent finite-dimensional convex problems that are interpretable and solvable to global optimality. The convex programs lead to {\it block nuclear-norm regularization} that promotes low rank in the latent feature and token dimensions. In particular, we show how self-attention networks implicitly clusters the tokens, based on their latent similarity. We conduct experiments for transferring a pre-trained transformer backbone for CIFAR-100 classification by fine-tuning a variety of convex attention heads. The results indicate the merits of the bias induced by attention compared with the existing MLP or linear heads.
Why do CNNs Learn Consistent Representations in their First Layer Independent of Labels and Architecture?
Jun 06, 2022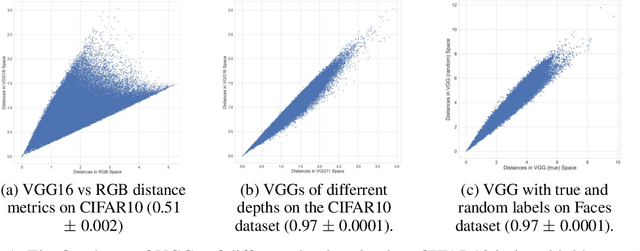
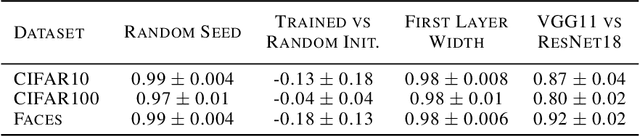
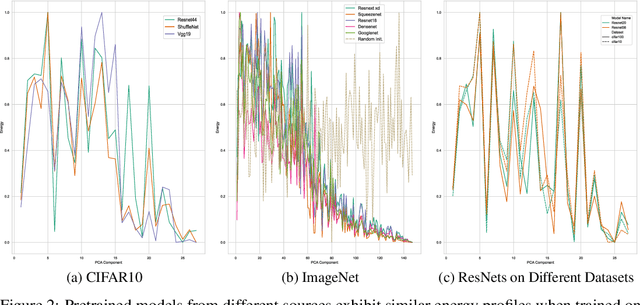

It has previously been observed that the filters learned in the first layer of a CNN are qualitatively similar for different networks and tasks. We extend this finding and show a high quantitative similarity between filters learned by different networks. We consider the CNN filters as a filter bank and measure the sensitivity of the filter bank to different frequencies. We show that the sensitivity profile of different networks is almost identical, yet far from initialization. Remarkably, we show that it remains the same even when the network is trained with random labels. To understand this effect, we derive an analytic formula for the sensitivity of the filters in the first layer of a linear CNN. We prove that when the average patch in images of the two classes is identical, the sensitivity profile of the filters in the first layer will be identical in expectation when using the true labels or random labels and will only depend on the second-order statistics of image patches. We empirically demonstrate that the average patch assumption holds for realistic datasets. Finally we show that the energy profile of filters in nonlinear CNNs is highly correlated with the energy profile of linear CNNs and that our analysis of linear networks allows us to predict when representations learned by state-of-the-art networks trained on benchmark classification tasks will depend on the labels.
Convolutional Neural Network to Restore Low-Dose Digital Breast Tomosynthesis Projections in a Variance Stabilization Domain
Mar 22, 2022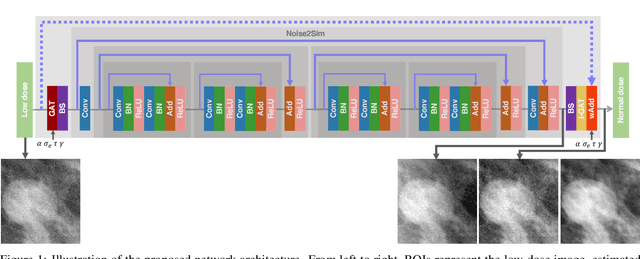
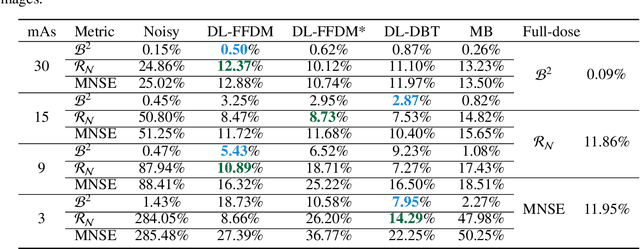

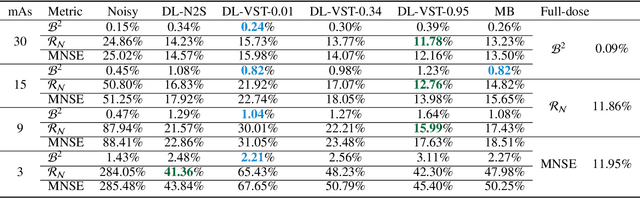
Digital breast tomosynthesis (DBT) exams should utilize the lowest possible radiation dose while maintaining sufficiently good image quality for accurate medical diagnosis. In this work, we propose a convolution neural network (CNN) to restore low-dose (LD) DBT projections to achieve an image quality equivalent to a standard full-dose (FD) acquisition. The proposed network architecture benefits from priors in terms of layers that were inspired by traditional model-based (MB) restoration methods, considering a model-based deep learning approach, where the network is trained to operate in the variance stabilization transformation (VST) domain. To accurately control the network operation point, in terms of noise and blur of the restored image, we propose a loss function that minimizes the bias and matches residual noise between the input and the output. The training dataset was composed of clinical data acquired at the standard FD and low-dose pairs obtained by the injection of quantum noise. The network was tested using real DBT projections acquired with a physical anthropomorphic breast phantom. The proposed network achieved superior results in terms of the mean normalized squared error (MNSE), training time and noise spatial correlation compared with networks trained with traditional data-driven methods. The proposed approach can be extended for other medical imaging application that requires LD acquisitions.
Instance-level Image Retrieval using Reranking Transformers
Mar 22, 2021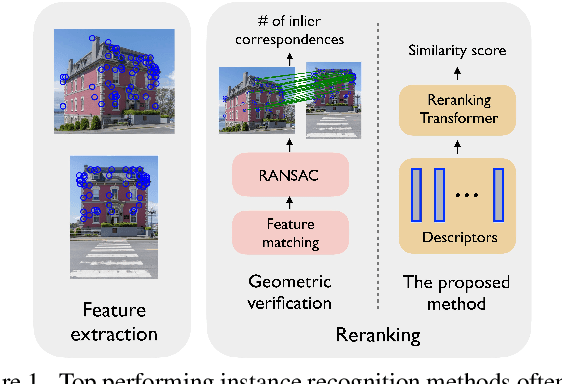
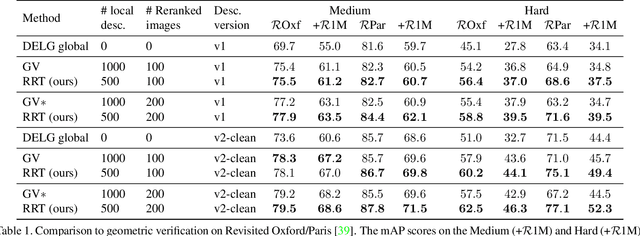
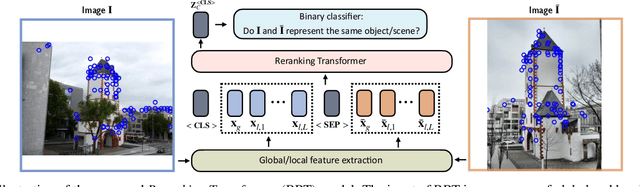
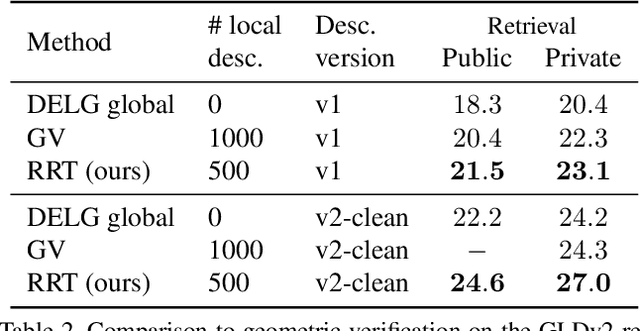
Instance-level image retrieval is the task of searching in a large database for images that match an object in a query image. To address this task, systems usually rely on a retrieval step that uses global image descriptors, and a subsequent step that performs domain-specific refinements or reranking by leveraging operations such as geometric verification based on local features. In this work, we propose Reranking Transformers (RRTs) as a general model to incorporate both local and global features to rerank the matching images in a supervised fashion and thus replace the relatively expensive process of geometric verification. RRTs are lightweight and can be easily parallelized so that reranking a set of top matching results can be performed in a single forward-pass. We perform extensive experiments on the Revisited Oxford and Paris datasets, and the Google Landmark v2 dataset, showing that RRTs outperform previous reranking approaches while using much fewer local descriptors. Moreover, we demonstrate that, unlike existing approaches, RRTs can be optimized jointly with the feature extractor, which can lead to feature representations tailored to downstream tasks and further accuracy improvements. Training code and pretrained models will be made public.
Visually-Augmented Language Modeling
May 20, 2022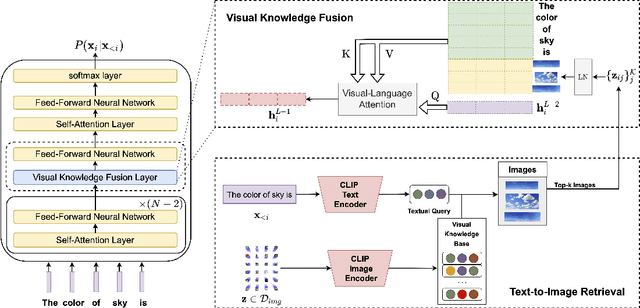

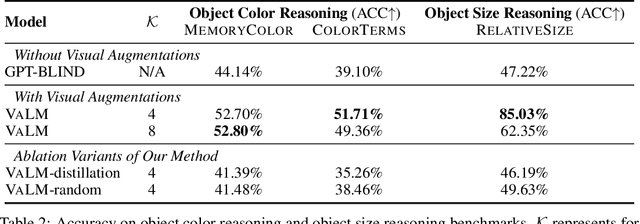
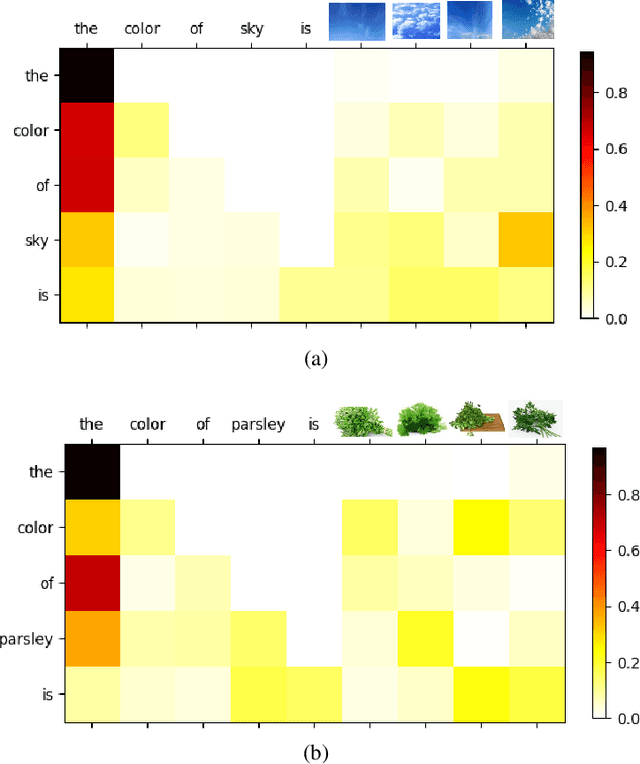
Human language is grounded on multimodal knowledge including visual knowledge like colors, sizes, and shapes. However, current large-scale pre-trained language models rely on the text-only self-supervised training with massive text data, which precludes them from utilizing relevant visual information when necessary. To address this, we propose a novel pre-training framework, named VaLM, to Visually-augment text tokens with retrieved relevant images for Language Modeling. Specifically, VaLM builds on a novel text-vision alignment method via an image retrieval module to fetch corresponding images given a textual context. With the visually-augmented context, VaLM uses a visual knowledge fusion layer to enable multimodal grounded language modeling by attending on both text context and visual knowledge in images. We evaluate the proposed model on various multimodal commonsense reasoning tasks, which require visual information to excel. VaLM outperforms the text-only baseline with substantial gains of +8.66% and +37.81% accuracy on object color and size reasoning, respectively.
Where is the disease? Semi-supervised pseudo-normality synthesis from an abnormal image
Jun 24, 2021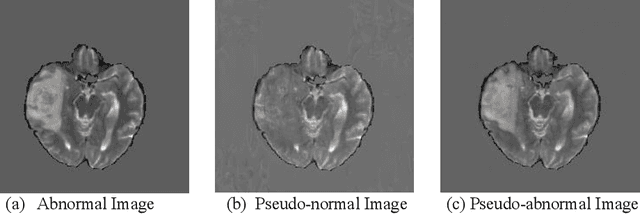

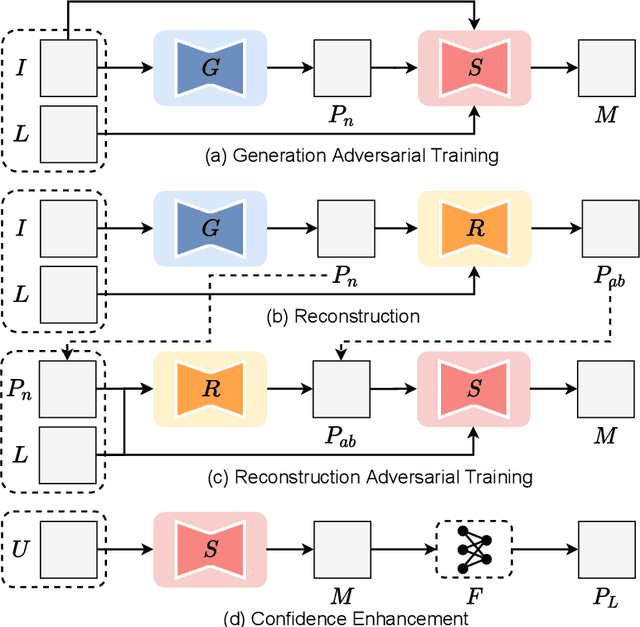
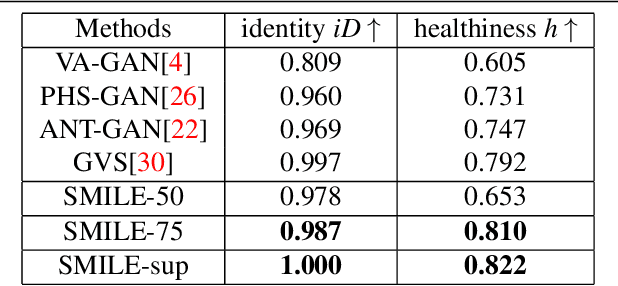
Pseudo-normality synthesis, which computationally generates a pseudo-normal image from an abnormal one (e.g., with lesions), is critical in many perspectives, from lesion detection, data augmentation to clinical surgery suggestion. However, it is challenging to generate high-quality pseudo-normal images in the absence of the lesion information. Thus, expensive lesion segmentation data have been introduced to provide lesion information for the generative models and improve the quality of the synthetic images. In this paper, we aim to alleviate the need of a large amount of lesion segmentation data when generating pseudo-normal images. We propose a Semi-supervised Medical Image generative LEarning network (SMILE) which not only utilizes limited medical images with segmentation masks, but also leverages massive medical images without segmentation masks to generate realistic pseudo-normal images. Extensive experiments show that our model outperforms the best state-of-the-art model by up to 6% for data augmentation task and 3% in generating high-quality images. Moreover, the proposed semi-supervised learning achieves comparable medical image synthesis quality with supervised learning model, using only 50 of segmentation data.
Glance to Count: Learning to Rank with Anchors for Weakly-supervised Crowd Counting
May 29, 2022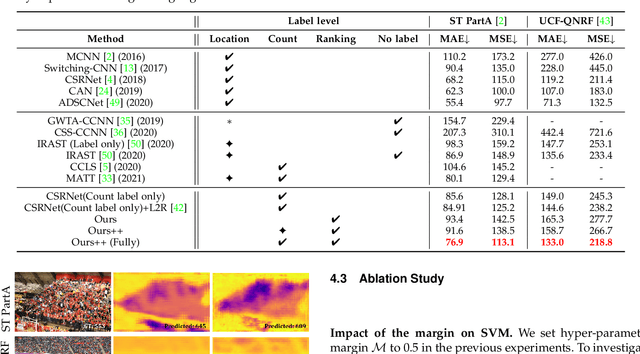
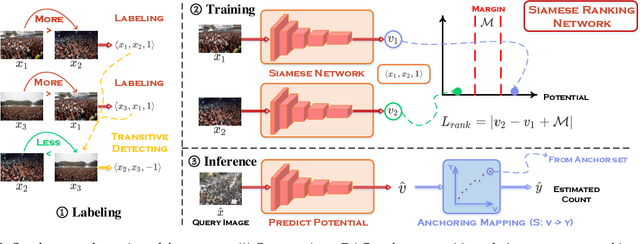
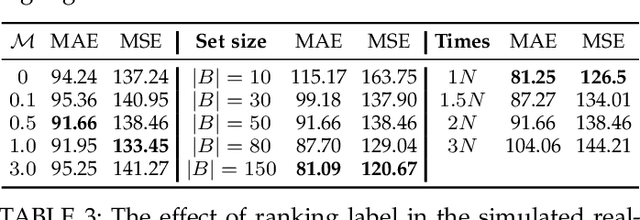

Crowd image is arguably one of the most laborious data to annotate. In this paper, we devote to reduce the massive demand of densely labeled crowd data, and propose a novel weakly-supervised setting, in which we leverage the binary ranking of two images with high-contrast crowd counts as training guidance. To enable training under this new setting, we convert the crowd count regression problem to a ranking potential prediction problem. In particular, we tailor a Siamese Ranking Network that predicts the potential scores of two images indicating the ordering of the counts. Hence, the ultimate goal is to assign appropriate potentials for all the crowd images to ensure their orderings obey the ranking labels. On the other hand, potentials reveal the relative crowd sizes but cannot yield an exact crowd count. We resolve this problem by introducing "anchors" during the inference stage. Concretely, anchors are a few images with count labels used for referencing the corresponding counts from potential scores by a simple linear mapping function. We conduct extensive experiments to study various combinations of supervision, and we show that the proposed method outperforms existing weakly-supervised methods without additional labeling effort by a large margin.
Improving Monocular Visual Odometry Using Learned Depth
Apr 04, 2022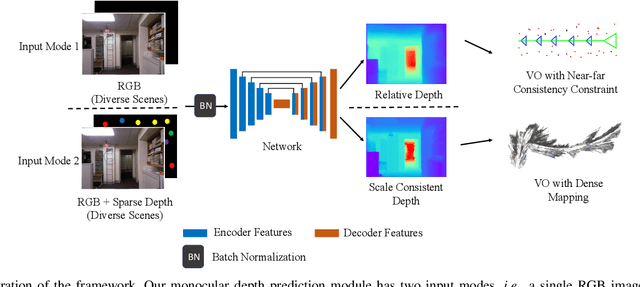
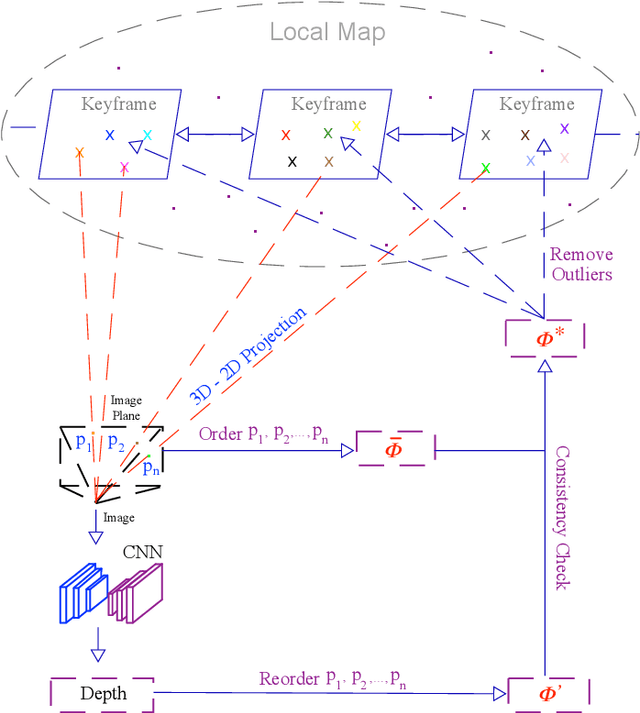
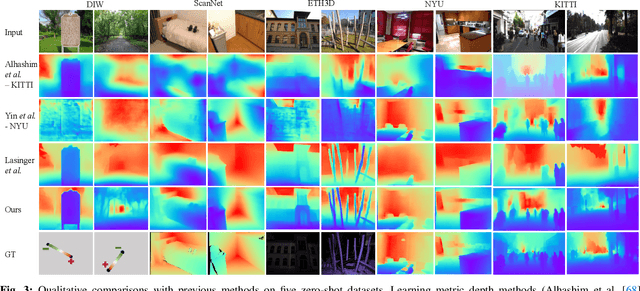
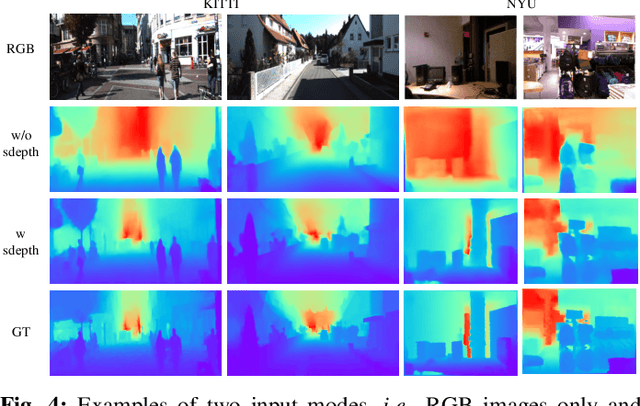
Monocular visual odometry (VO) is an important task in robotics and computer vision. Thus far, how to build accurate and robust monocular VO systems that can work well in diverse scenarios remains largely unsolved. In this paper, we propose a framework to exploit monocular depth estimation for improving VO. The core of our framework is a monocular depth estimation module with a strong generalization capability for diverse scenes. It consists of two separate working modes to assist the localization and mapping. With a single monocular image input, the depth estimation module predicts a relative depth to help the localization module on improving the accuracy. With a sparse depth map and an RGB image input, the depth estimation module can generate accurate scale-consistent depth for dense mapping. Compared with current learning-based VO methods, our method demonstrates a stronger generalization ability to diverse scenes. More significantly, our framework is able to boost the performances of existing geometry-based VO methods by a large margin.