 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs the Modality Gap a Bug or a Feature? A Robustness Perspective
Mar 30, 2026Many modern multi-modal models (e.g. CLIP) seek an embedding space in which the two modalities are aligned. Somewhat surprisingly, almost all existing models show a strong modality gap: the distribution of images is well-separated from the distribution of texts in the shared embedding space. Despite a series of recent papers on this topic, it is still not clear why this gap exists nor whether closing the gap in post-processing will lead to better performance on downstream tasks. In this paper we show that under certain conditions, minimizing the contrastive loss yields a representation in which the two modalities are separated by a global gap vector that is orthogonal to their embeddings. We also show that under these conditions the modality gap is monotonically related to robustness: decreasing the gap does not change the clean accuracy of the models but makes it less likely that a model will change its output when the embeddings are perturbed. Our experiments show that for many real-world VLMs we can significantly increase robustness by a simple post-processing step that moves one modality towards the mean of the other modality, without any loss of clean accuracy.
Control+Shift: Generating Controllable Distribution Shifts
Sep 12, 2024We propose a new method for generating realistic datasets with distribution shifts using any decoder-based generative model. Our approach systematically creates datasets with varying intensities of distribution shifts, facilitating a comprehensive analysis of model performance degradation. We then use these generated datasets to evaluate the performance of various commonly used networks and observe a consistent decline in performance with increasing shift intensity, even when the effect is almost perceptually unnoticeable to the human eye. We see this degradation even when using data augmentations. We also find that enlarging the training dataset beyond a certain point has no effect on the robustness and that stronger inductive biases increase robustness.
Why do CNNs Learn Consistent Representations in their First Layer Independent of Labels and Architecture?
Jun 06, 2022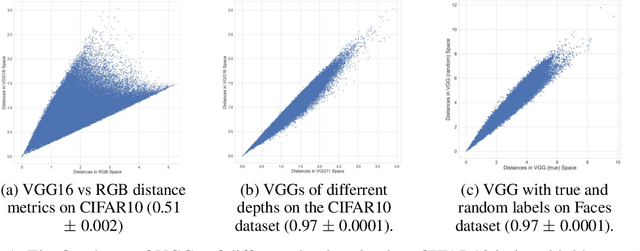
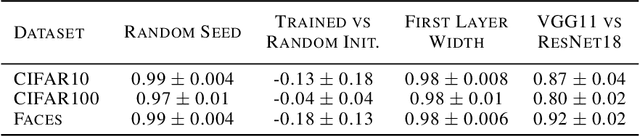
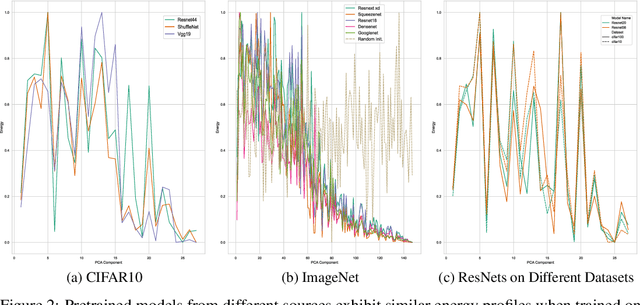

It has previously been observed that the filters learned in the first layer of a CNN are qualitatively similar for different networks and tasks. We extend this finding and show a high quantitative similarity between filters learned by different networks. We consider the CNN filters as a filter bank and measure the sensitivity of the filter bank to different frequencies. We show that the sensitivity profile of different networks is almost identical, yet far from initialization. Remarkably, we show that it remains the same even when the network is trained with random labels. To understand this effect, we derive an analytic formula for the sensitivity of the filters in the first layer of a linear CNN. We prove that when the average patch in images of the two classes is identical, the sensitivity profile of the filters in the first layer will be identical in expectation when using the true labels or random labels and will only depend on the second-order statistics of image patches. We empirically demonstrate that the average patch assumption holds for realistic datasets. Finally we show that the energy profile of filters in nonlinear CNNs is highly correlated with the energy profile of linear CNNs and that our analysis of linear networks allows us to predict when representations learned by state-of-the-art networks trained on benchmark classification tasks will depend on the labels.