 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion-Robust Deep Reconstruction for Free-Breathing Cardiac Cine MRI
May 20, 2026Conventional cardiac cine MRI relies on breath-hold Cartesian acquisitions, which are vulnerable to motion artifacts and can be uncomfortable or infeasible, particularly for pediatric and other noncompliant patients who cannot reliably hold their breath. Free-breathing radial acquisitions can alleviate these limitations, but robust reconstruction at high acceleration remains challenging due to prominent streak artifacts. To address these limitations, we propose Cine-DL, a clinically oriented framework that couples targeted k-space preprocessing with fast, model-based deep reconstruction. In this pipeline, raw free-breathing radial data undergo retrospective cardiac binning and respiratory gating to resolve cardiac phases and discard motion-corrupted spokes. We then introduce Streak Optimized Coil Compression (SOC), which explicitly preserves cardiac signals while suppressing peripheral interference that typically drives the streak artifacts. The resulting 2D+t cine series is reconstructed with an unrolled network that alternates a ResNet proximal operator with physics-based data consistency updates solved via conjugate gradient. We further employ a memory-efficient training strategy that reduces peak memory usage. We evaluate Cine-DL on free-breathing volunteer data against established baselines (k-t SENSE and iGRASP) and demonstrate clinical translation via hospital deployment on newly acquired patient data. Our experiments show that Cine-DL consistently improves quantitative metrics and visual fidelity, supporting a practical route toward routine, time-sensitive clinical adoption of free-breathing cine MRI.
Principled Design of Diffusion-based Optimizers for Inverse Problems
May 12, 2026Score-based diffusion models achieve state-of-the-art performance for inverse problems, but their practical deployment is hindered by long inference times and cumbersome hyperparameter tuning. While pretrained diffusion models can be reused across tasks without retraining, inference-time hyperparameters such as the noise schedule and posterior sampling weights typically require ad-hoc adjustment for each problem setup. We propose principled reparameterizations that induce invariances, allowing the same hyperparameters to be reused across multiple problems without re-tuning. In addition, building on the RED-diff framework, which reformulates posterior sampling as an optimization problem, we further develop the OptDiff pipeline. OptDiff provides a simplified tuning framework that facilitates the integration of convex optimization tools to accelerate inference. Experiments on image reconstruction, deblurring, and super-resolution show substantial speedups and improved image quality.
LTDA-Drive: LLMs-guided Generative Models based Long-tail Data Augmentation for Autonomous Driving
May 21, 2025



3D perception plays an essential role for improving the safety and performance of autonomous driving. Yet, existing models trained on real-world datasets, which naturally exhibit long-tail distributions, tend to underperform on rare and safety-critical, vulnerable classes, such as pedestrians and cyclists. Existing studies on reweighting and resampling techniques struggle with the scarcity and limited diversity within tail classes. To address these limitations, we introduce LTDA-Drive, a novel LLM-guided data augmentation framework designed to synthesize diverse, high-quality long-tail samples. LTDA-Drive replaces head-class objects in driving scenes with tail-class objects through a three-stage process: (1) text-guided diffusion models remove head-class objects, (2) generative models insert instances of the tail classes, and (3) an LLM agent filters out low-quality synthesized images. Experiments conducted on the KITTI dataset show that LTDA-Drive significantly improves tail-class detection, achieving 34.75\% improvement for rare classes over counterpart methods. These results further highlight the effectiveness of LTDA-Drive in tackling long-tail challenges by generating high-quality and diverse data.
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.
RadAdapt: Radiology Report Summarization via Lightweight Domain Adaptation of Large Language Models
May 02, 2023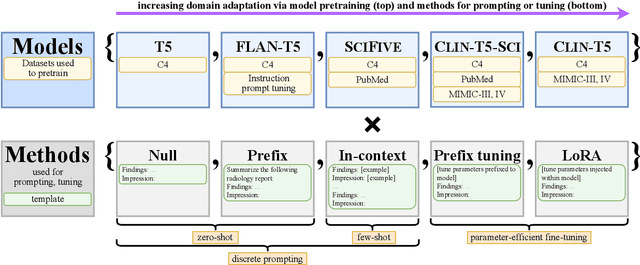
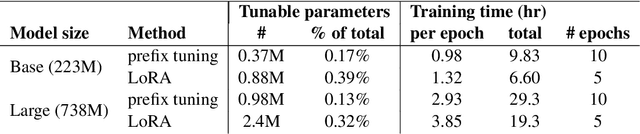

We systematically investigate lightweight strategies to adapt large language models (LLMs) for the task of radiology report summarization (RRS). Specifically, we focus on domain adaptation via pretraining (on natural language, biomedical text, and clinical text) and via prompting (zero-shot, in-context learning) or parameter-efficient fine-tuning (prefix tuning, LoRA). Our results on the MIMIC-III dataset consistently demonstrate best performance by maximally adapting to the task via pretraining on clinical text and parameter-efficient fine-tuning on RRS examples. Importantly, this method fine-tunes a mere 0.32% of parameters throughout the model, in contrast to end-to-end fine-tuning (100% of parameters). Additionally, we study the effect of in-context examples and out-of-distribution (OOD) training before concluding with a radiologist reader study and qualitative analysis. Our findings highlight the importance of domain adaptation in RRS and provide valuable insights toward developing effective natural language processing solutions for clinical tasks.
Scale-Agnostic Super-Resolution in MRI using Feature-Based Coordinate Networks
Oct 18, 2022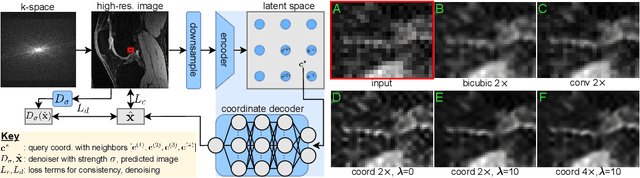
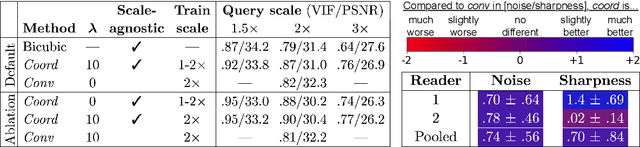
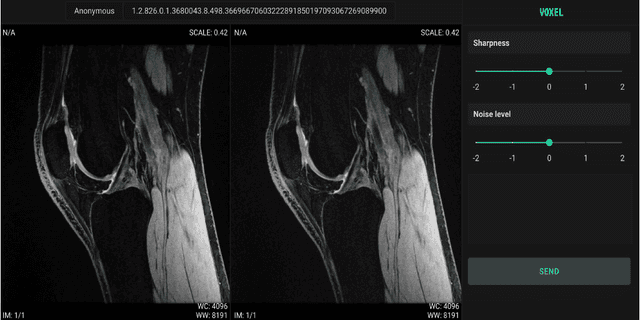
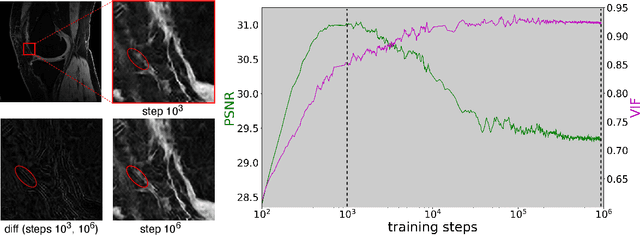
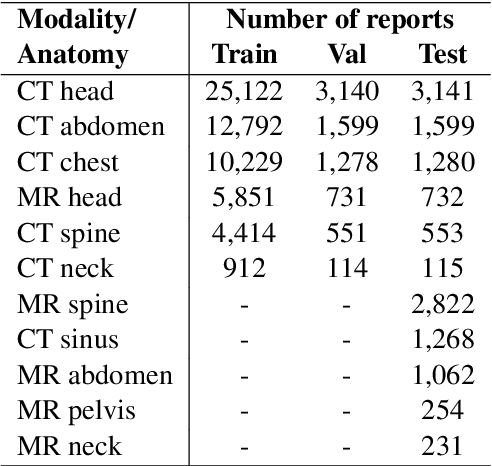
We propose using a coordinate network decoder for the task of super-resolution in MRI. The continuous signal representation of coordinate networks enables this approach to be scale-agnostic, i.e. one can train over a continuous range of scales and subsequently query at arbitrary resolutions. Due to the difficulty of performing super-resolution on inherently noisy data, we analyze network behavior under multiple denoising strategies. Lastly we compare this method to a standard convolutional decoder using both quantitative metrics and a radiologist study implemented in Voxel, our newly developed tool for web-based evaluation of medical images.
Unraveling Attention via Convex Duality: Analysis and Interpretations of Vision Transformers
May 20, 2022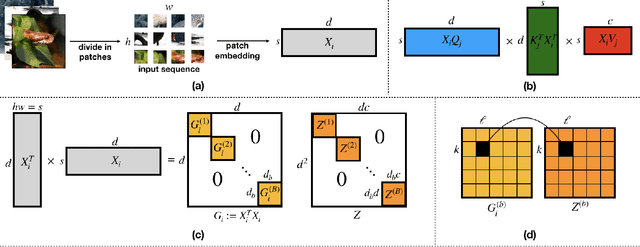
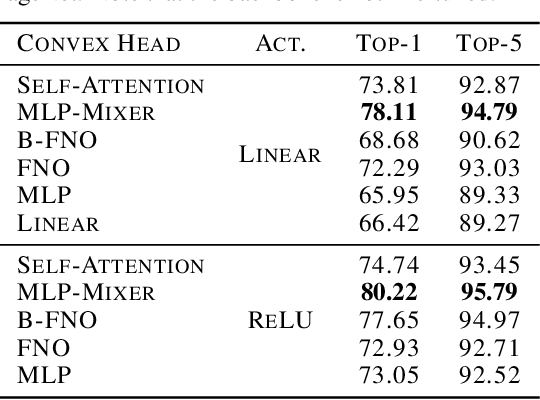
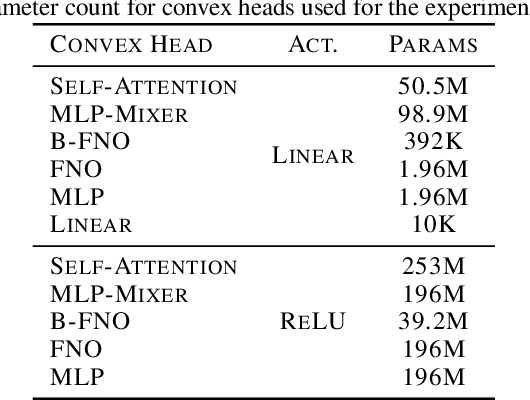
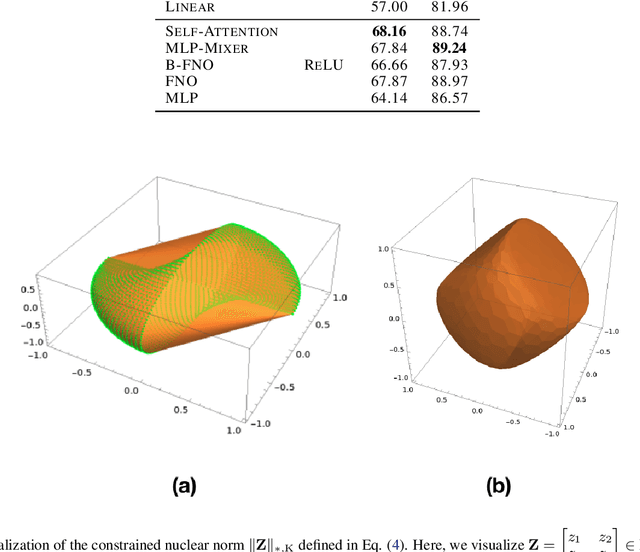
Vision transformers using self-attention or its proposed alternatives have demonstrated promising results in many image related tasks. However, the underpinning inductive bias of attention is not well understood. To address this issue, this paper analyzes attention through the lens of convex duality. For the non-linear dot-product self-attention, and alternative mechanisms such as MLP-mixer and Fourier Neural Operator (FNO), we derive equivalent finite-dimensional convex problems that are interpretable and solvable to global optimality. The convex programs lead to {\it block nuclear-norm regularization} that promotes low rank in the latent feature and token dimensions. In particular, we show how self-attention networks implicitly clusters the tokens, based on their latent similarity. We conduct experiments for transferring a pre-trained transformer backbone for CIFAR-100 classification by fine-tuning a variety of convex attention heads. The results indicate the merits of the bias induced by attention compared with the existing MLP or linear heads.
Scale-Equivariant Unrolled Neural Networks for Data-Efficient Accelerated MRI Reconstruction
Apr 21, 2022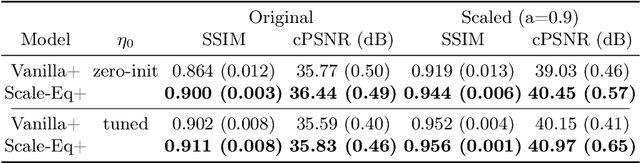
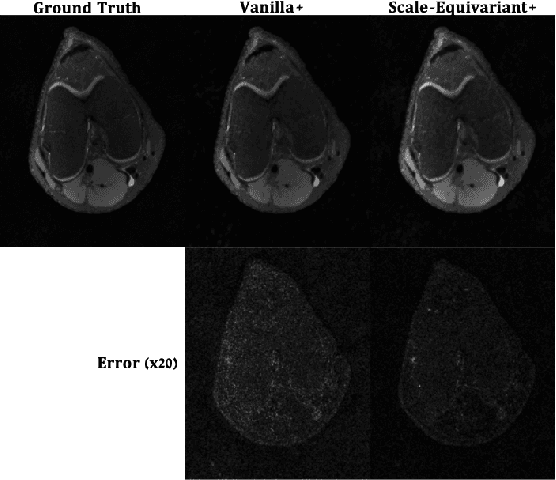
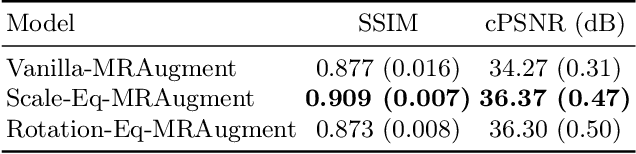
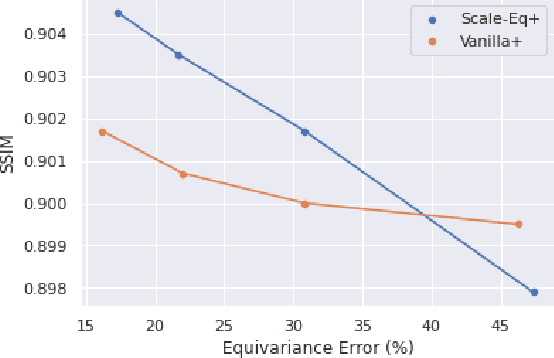
Unrolled neural networks have enabled state-of-the-art reconstruction performance and fast inference times for the accelerated magnetic resonance imaging (MRI) reconstruction task. However, these approaches depend on fully-sampled scans as ground truth data which is either costly or not possible to acquire in many clinical medical imaging applications; hence, reducing dependence on data is desirable. In this work, we propose modeling the proximal operators of unrolled neural networks with scale-equivariant convolutional neural networks in order to improve the data-efficiency and robustness to drifts in scale of the images that might stem from the variability of patient anatomies or change in field-of-view across different MRI scanners. Our approach demonstrates strong improvements over the state-of-the-art unrolled neural networks under the same memory constraints both with and without data augmentations on both in-distribution and out-of-distribution scaled images without significantly increasing the train or inference time.
NeRP: Implicit Neural Representation Learning with Prior Embedding for Sparsely Sampled Image Reconstruction
Aug 24, 2021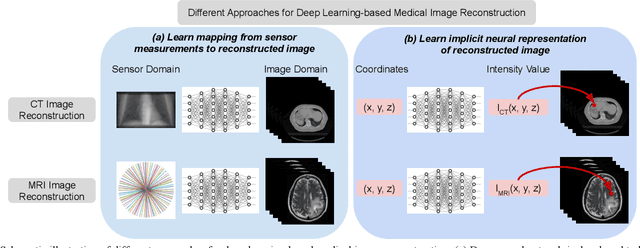
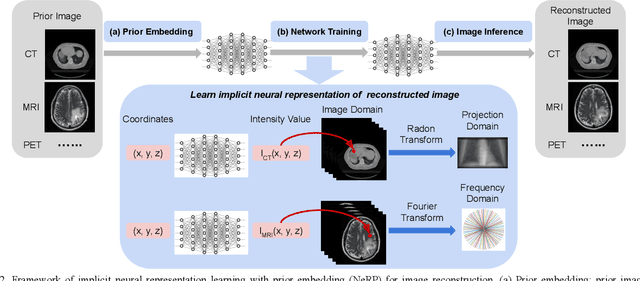
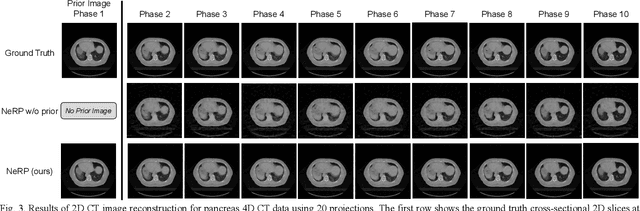
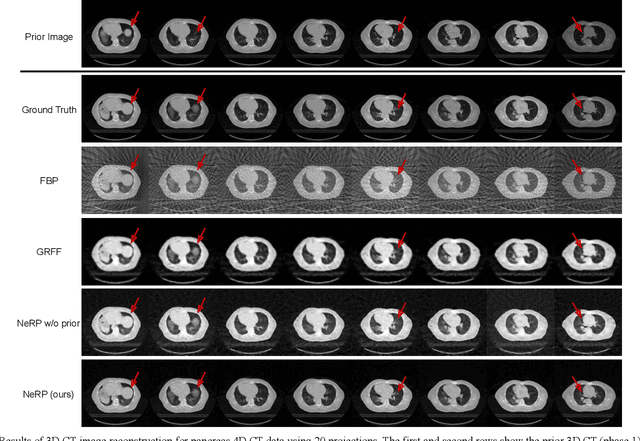
Image reconstruction is an inverse problem that solves for a computational image based on sampled sensor measurement. Sparsely sampled image reconstruction poses addition challenges due to limited measurements. In this work, we propose an implicit Neural Representation learning methodology with Prior embedding (NeRP) to reconstruct a computational image from sparsely sampled measurements. The method differs fundamentally from previous deep learning-based image reconstruction approaches in that NeRP exploits the internal information in an image prior, and the physics of the sparsely sampled measurements to produce a representation of the unknown subject. No large-scale data is required to train the NeRP except for a prior image and sparsely sampled measurements. In addition, we demonstrate that NeRP is a general methodology that generalizes to different imaging modalities such as CT and MRI. We also show that NeRP can robustly capture the subtle yet significant image changes required for assessing tumor progression.
Hidden Convexity of Wasserstein GANs: Interpretable Generative Models with Closed-Form Solutions
Jul 12, 2021
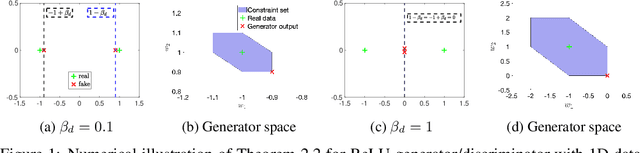
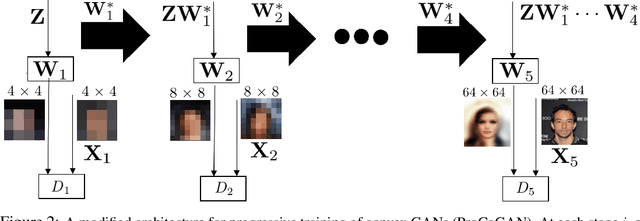

Generative Adversarial Networks (GANs) are commonly used for modeling complex distributions of data. Both the generators and discriminators of GANs are often modeled by neural networks, posing a non-transparent optimization problem which is non-convex and non-concave over the generator and discriminator, respectively. Such networks are often heuristically optimized with gradient descent-ascent (GDA), but it is unclear whether the optimization problem contains any saddle points, or whether heuristic methods can find them in practice. In this work, we analyze the training of Wasserstein GANs with two-layer neural network discriminators through the lens of convex duality, and for a variety of generators expose the conditions under which Wasserstein GANs can be solved exactly with convex optimization approaches, or can be represented as convex-concave games. Using this convex duality interpretation, we further demonstrate the impact of different activation functions of the discriminator. Our observations are verified with numerical results demonstrating the power of the convex interpretation, with applications in progressive training of convex architectures corresponding to linear generators and quadratic-activation discriminators for CelebA image generation. The code for our experiments is available at https://github.com/ardasahiner/ProCoGAN.