 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Purified and Unified Steganographic Network
Feb 27, 2024
Steganography is the art of hiding secret data into the cover media for covert communication. In recent years, more and more deep neural network (DNN)-based steganographic schemes are proposed to train steganographic networks for secret embedding and recovery, which are shown to be promising. Compared with the handcrafted steganographic tools, steganographic networks tend to be large in size. It raises concerns on how to imperceptibly and effectively transmit these networks to the sender and receiver to facilitate the covert communication. To address this issue, we propose in this paper a Purified and Unified Steganographic Network (PUSNet). It performs an ordinary machine learning task in a purified network, which could be triggered into steganographic networks for secret embedding or recovery using different keys. We formulate the construction of the PUSNet into a sparse weight filling problem to flexibly switch between the purified and steganographic networks. We further instantiate our PUSNet as an image denoising network with two steganographic networks concealed for secret image embedding and recovery. Comprehensive experiments demonstrate that our PUSNet achieves good performance on secret image embedding, secret image recovery, and image denoising in a single architecture. It is also shown to be capable of imperceptibly carrying the steganographic networks in a purified network. Code is available at \url{https://github.com/albblgb/PUSNet}
Invariant Test-Time Adaptation for Vision-Language Model Generalization
Mar 01, 2024
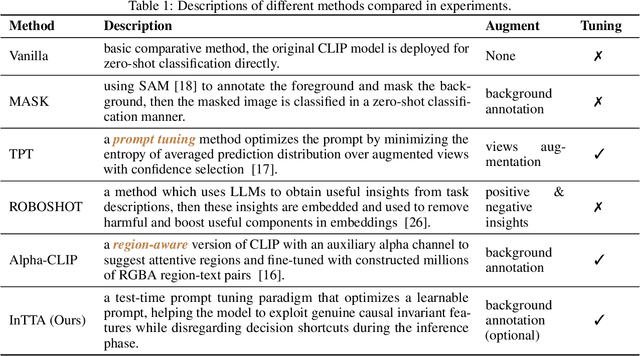

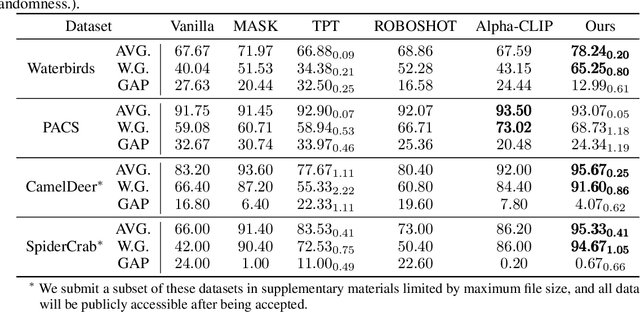
Vision-language foundation models have exhibited remarkable success across a multitude of downstream tasks due to their scalability on extensive image-text paired datasets. However, these models display significant limitations when applied to long-tail tasks, such as fine-grained image classification, as a result of "decision shortcuts" that hinders their generalization capabilities. In this work, we find that the CLIP model possesses a rich set of features, encompassing both \textit{desired invariant causal features} and \textit{undesired decision shortcuts}. Moreover, the underperformance of CLIP on downstream tasks originates from its inability to effectively utilize pre-trained features in accordance with specific task requirements. To address this challenge, this paper introduces a test-time prompt tuning paradigm that optimizes a learnable prompt, thereby compelling the model to exploit genuine causal invariant features while disregarding decision shortcuts during the inference phase. The proposed method effectively alleviates excessive dependence on potentially misleading, task-irrelevant contextual information, while concurrently emphasizing critical, task-related visual cues. We conduct comparative analysis of the proposed method against various approaches which validates its effectiveness.
Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks
Mar 01, 2024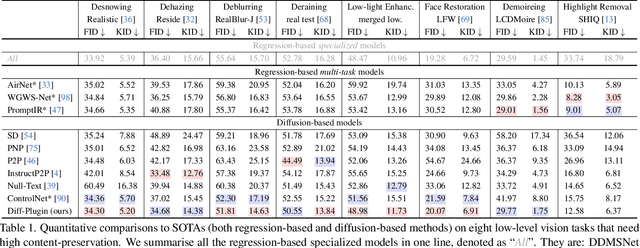
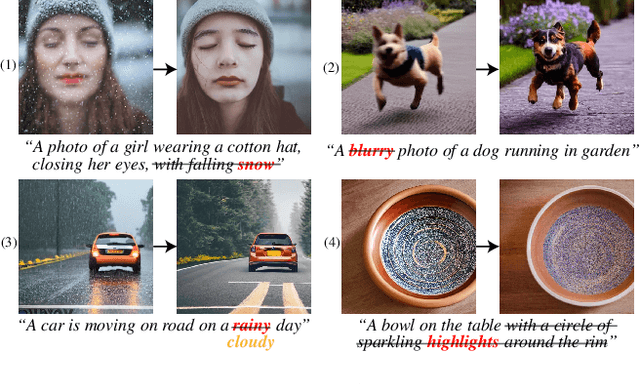
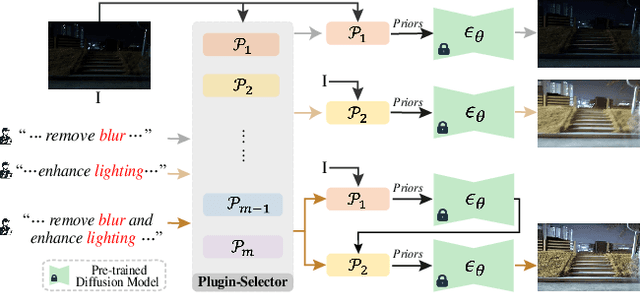
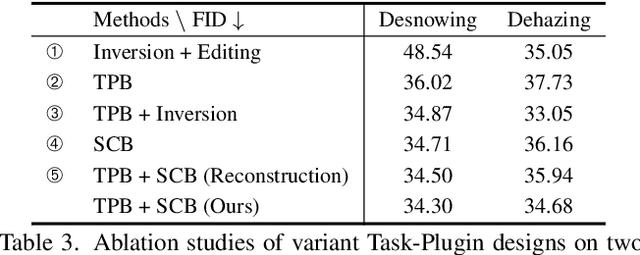
Diffusion models trained on large-scale datasets have achieved remarkable progress in image synthesis. However, due to the randomness in the diffusion process, they often struggle with handling diverse low-level tasks that require details preservation. To overcome this limitation, we present a new Diff-Plugin framework to enable a single pre-trained diffusion model to generate high-fidelity results across a variety of low-level tasks. Specifically, we first propose a lightweight Task-Plugin module with a dual branch design to provide task-specific priors, guiding the diffusion process in preserving image content. We then propose a Plugin-Selector that can automatically select different Task-Plugins based on the text instruction, allowing users to edit images by indicating multiple low-level tasks with natural language. We conduct extensive experiments on 8 low-level vision tasks. The results demonstrate the superiority of Diff-Plugin over existing methods, particularly in real-world scenarios. Our ablations further validate that Diff-Plugin is stable, schedulable, and supports robust training across different dataset sizes.
G-EvoNAS: Evolutionary Neural Architecture Search Based on Network Growth
Mar 05, 2024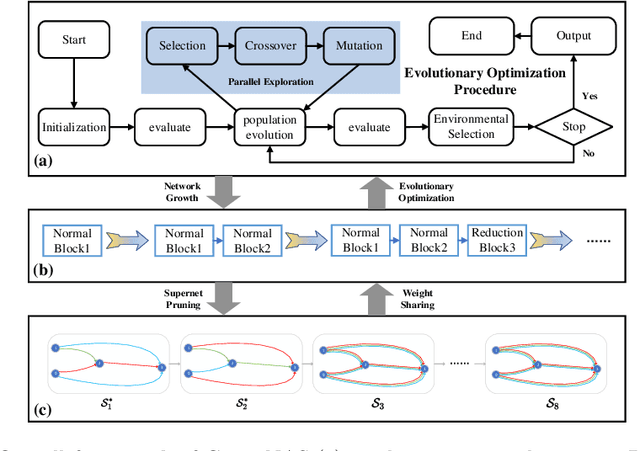
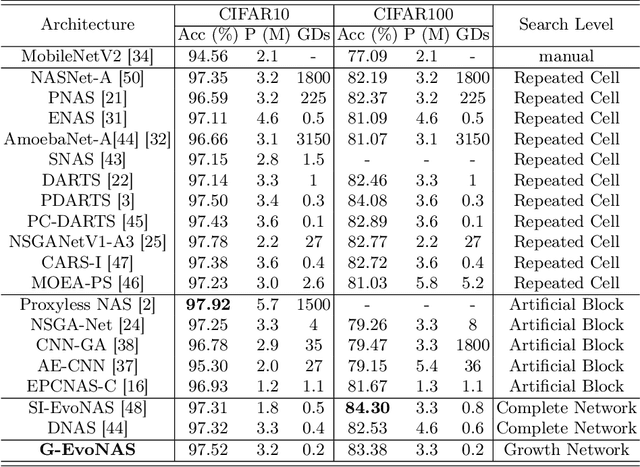
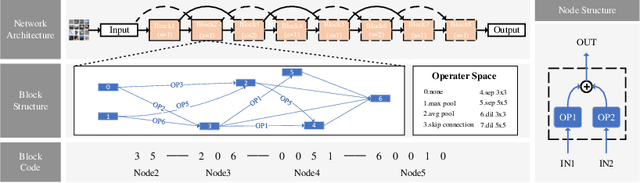
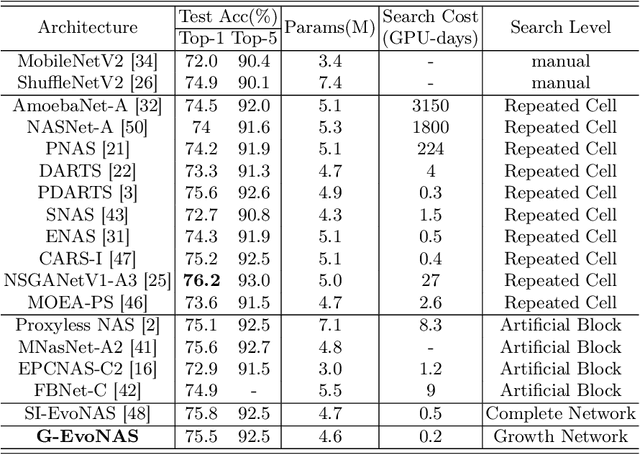
The evolutionary paradigm has been successfully applied to neural network search(NAS) in recent years. Due to the vast search complexity of the global space, current research mainly seeks to repeatedly stack partial architectures to build the entire model or to seek the entire model based on manually designed benchmark modules. The above two methods are attempts to reduce the search difficulty by narrowing the search space. To efficiently search network architecture in the global space, this paper proposes another solution, namely a computationally efficient neural architecture evolutionary search framework based on network growth (G-EvoNAS). The complete network is obtained by gradually deepening different Blocks. The process begins from a shallow network, grows and evolves, and gradually deepens into a complete network, reducing the search complexity in the global space. Then, to improve the ranking accuracy of the network, we reduce the weight coupling of each network in the SuperNet by pruning the SuperNet according to elite groups at different growth stages. The G-EvoNAS is tested on three commonly used image classification datasets, CIFAR10, CIFAR100, and ImageNet, and compared with various state-of-the-art algorithms, including hand-designed networks and NAS networks. Experimental results demonstrate that G-EvoNAS can find a neural network architecture comparable to state-of-the-art designs in 0.2 GPU days.
SGD with Partial Hessian for Deep Neural Networks Optimization
Mar 05, 2024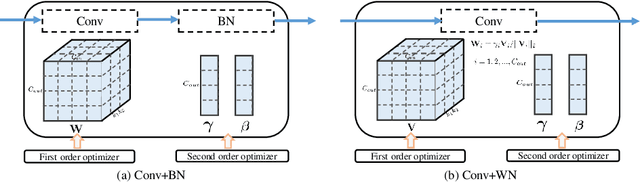
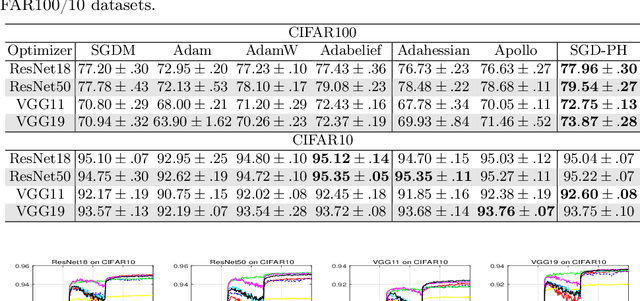
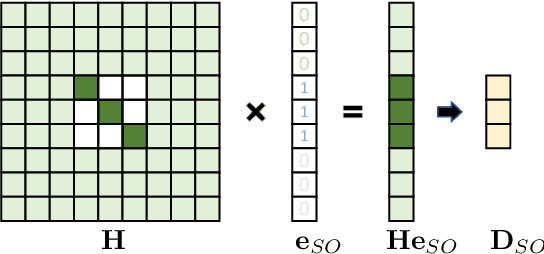

Due to the effectiveness of second-order algorithms in solving classical optimization problems, designing second-order optimizers to train deep neural networks (DNNs) has attracted much research interest in recent years. However, because of the very high dimension of intermediate features in DNNs, it is difficult to directly compute and store the Hessian matrix for network optimization. Most of the previous second-order methods approximate the Hessian information imprecisely, resulting in unstable performance. In this work, we propose a compound optimizer, which is a combination of a second-order optimizer with a precise partial Hessian matrix for updating channel-wise parameters and the first-order stochastic gradient descent (SGD) optimizer for updating the other parameters. We show that the associated Hessian matrices of channel-wise parameters are diagonal and can be extracted directly and precisely from Hessian-free methods. The proposed method, namely SGD with Partial Hessian (SGD-PH), inherits the advantages of both first-order and second-order optimizers. Compared with first-order optimizers, it adopts a certain amount of information from the Hessian matrix to assist optimization, while compared with the existing second-order optimizers, it keeps the good generalization performance of first-order optimizers. Experiments on image classification tasks demonstrate the effectiveness of our proposed optimizer SGD-PH. The code is publicly available at \url{https://github.com/myingysun/SGDPH}.
RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches
Mar 05, 2024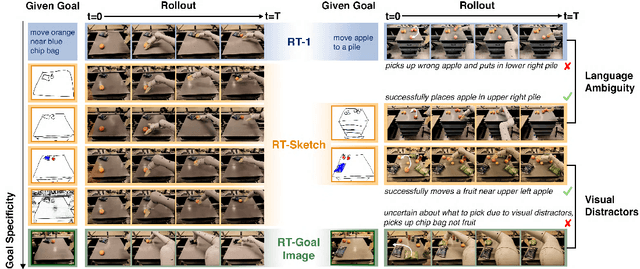
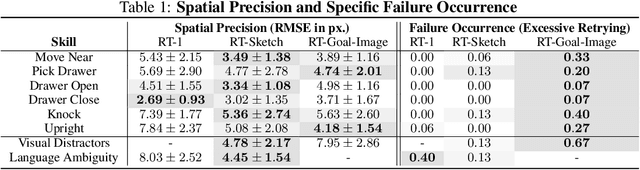
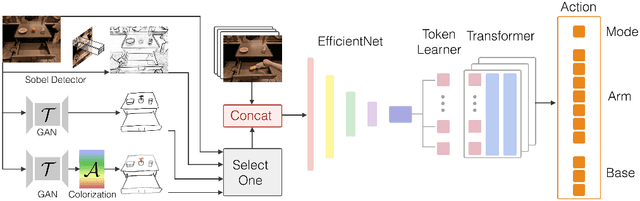
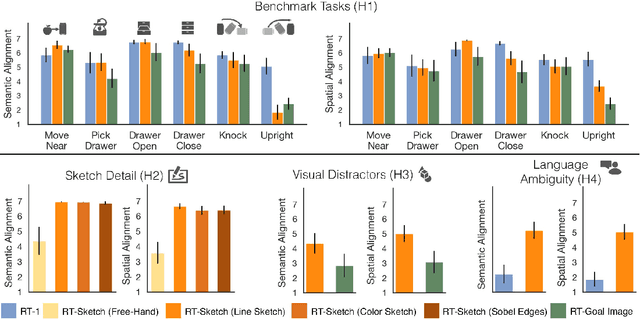
Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings. For supplementary material and videos, please refer to our website: http://rt-sketch.github.io.
ADS: Approximate Densest Subgraph for Novel Image Discovery
Feb 13, 2024The volume of image repositories continues to grow. Despite the availability of content-based addressing, we still lack a lightweight tool that allows us to discover images of distinct characteristics from a large collection. In this paper, we propose a fast and training-free algorithm for novel image discovery. The key of our algorithm is formulating a collection of images as a perceptual distance-weighted graph, within which our task is to locate the K-densest subgraph that corresponds to a subset of the most unique images. While solving this problem is not just NP-hard but also requires a full computation of the potentially huge distance matrix, we propose to relax it into a K-sparse eigenvector problem that we can efficiently solve using stochastic gradient descent (SGD) without explicitly computing the distance matrix. We compare our algorithm against state-of-the-arts on both synthetic and real datasets, showing that it is considerably faster to run with a smaller memory footprint while able to mine novel images more accurately.
MemoNav: Working Memory Model for Visual Navigation
Feb 29, 2024Image-goal navigation is a challenging task that requires an agent to navigate to a goal indicated by an image in unfamiliar environments. Existing methods utilizing diverse scene memories suffer from inefficient exploration since they use all historical observations for decision-making without considering the goal-relevant fraction. To address this limitation, we present MemoNav, a novel memory model for image-goal navigation, which utilizes a working memory-inspired pipeline to improve navigation performance. Specifically, we employ three types of navigation memory. The node features on a map are stored in the short-term memory (STM), as these features are dynamically updated. A forgetting module then retains the informative STM fraction to increase efficiency. We also introduce long-term memory (LTM) to learn global scene representations by progressively aggregating STM features. Subsequently, a graph attention module encodes the retained STM and the LTM to generate working memory (WM) which contains the scene features essential for efficient navigation. The synergy among these three memory types boosts navigation performance by enabling the agent to learn and leverage goal-relevant scene features within a topological map. Our evaluation on multi-goal tasks demonstrates that MemoNav significantly outperforms previous methods across all difficulty levels in both Gibson and Matterport3D scenes. Qualitative results further illustrate that MemoNav plans more efficient routes.
CARZero: Cross-Attention Alignment for Radiology Zero-Shot Classification
Feb 27, 2024The advancement of Zero-Shot Learning in the medical domain has been driven forward by using pre-trained models on large-scale image-text pairs, focusing on image-text alignment. However, existing methods primarily rely on cosine similarity for alignment, which may not fully capture the complex relationship between medical images and reports. To address this gap, we introduce a novel approach called Cross-Attention Alignment for Radiology Zero-Shot Classification (CARZero). Our approach innovatively leverages cross-attention mechanisms to process image and report features, creating a Similarity Representation that more accurately reflects the intricate relationships in medical semantics. This representation is then linearly projected to form an image-text similarity matrix for cross-modality alignment. Additionally, recognizing the pivotal role of prompt selection in zero-shot learning, CARZero incorporates a Large Language Model-based prompt alignment strategy. This strategy standardizes diverse diagnostic expressions into a unified format for both training and inference phases, overcoming the challenges of manual prompt design. Our approach is simple yet effective, demonstrating state-of-the-art performance in zero-shot classification on five official chest radiograph diagnostic test sets, including remarkable results on datasets with long-tail distributions of rare diseases. This achievement is attributed to our new image-text alignment strategy, which effectively addresses the complex relationship between medical images and reports.
PolypNextLSTM: A lightweight and fast polyp video segmentation network using ConvNext and ConvLSTM
Feb 28, 2024Commonly employed in polyp segmentation, single image UNet architectures lack the temporal insight clinicians gain from video data in diagnosing polyps. To mirror clinical practices more faithfully, our proposed solution, PolypNextLSTM, leverages video-based deep learning, harnessing temporal information for superior segmentation performance with the least parameter overhead, making it possibly suitable for edge devices. PolypNextLSTM employs a UNet-like structure with ConvNext-Tiny as its backbone, strategically omitting the last two layers to reduce parameter overhead. Our temporal fusion module, a Convolutional Long Short Term Memory (ConvLSTM), effectively exploits temporal features. Our primary novelty lies in PolypNextLSTM, which stands out as the leanest in parameters and the fastest model, surpassing the performance of five state-of-the-art image and video-based deep learning models. The evaluation of the SUN-SEG dataset spans easy-to-detect and hard-to-detect polyp scenarios, along with videos containing challenging artefacts like fast motion and occlusion. Comparison against 5 image-based and 5 video-based models demonstrates PolypNextLSTM's superiority, achieving a Dice score of 0.7898 on the hard-to-detect polyp test set, surpassing image-based PraNet (0.7519) and video-based PNSPlusNet (0.7486). Notably, our model excels in videos featuring complex artefacts such as ghosting and occlusion. PolypNextLSTM, integrating pruned ConvNext-Tiny with ConvLSTM for temporal fusion, not only exhibits superior segmentation performance but also maintains the highest frames per speed among evaluated models. Access code here https://github.com/mtec-tuhh/PolypNextLSTM