 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-based Decision Modeling for Synthetic Face Detection with Uncertainty-driven Active Learning
May 11, 2026With the rapid development of deep generative models, forged facial images are massively exploited for illegal activities. Although existing synthetic face detection methods have achieved significant progress, they suffer from the inherent limitation of overconfidence due to their reliance on the Softmax activation function. Thus, these methods often lead to unreliable predictions when encountering unknown Out-of-Distribution (OOD) images, and cannot ascertain the model's uncertainty in its prediction. Meanwhile, most existing methods require massive high-quality annotated data, which greatly limits their practicability across diverse scenarios. To address these limitations, we propose EMSFD (Evidence-based decision Modeling for Synthetic Face Detection with uncertainty-driven active learning), an approach designed to enhance detection reliability and generalizability. Specifically, EMSFD models class evidence using the Dirichlet distribution and explicitly incorporates model uncertainty into the prediction process. Furthermore, during training, the estimated uncertainty is exploited to prioritize more informative samples from the unlabeled pool for annotation, thereby reducing labeling cost and improving model generalization. Extensive experimental evaluations demonstrate that our method enhances the interpretability of synthetic face detection. Meanwhile, our method yields a 15\% increase in accuracy compared to existing state-of-the-art (SOTA) baselines, which demonstrates the superior detection performance and generalizability of our approach. Our code is available at: https://github.com/hzx111621/EMSFD.
Only Train Once: Uncertainty-Aware One-Class Learning for Face Authenticity Detection
May 11, 2026The rapid evolution of generative paradigms has enabled the creation of highly realistic imagery, which escalating the risks of identity fraud and the dissemination of disinformation. Most existing approaches frame face forgery detection as a fully supervised binary classification problem. Consequently, these models typically exhibit significant performance decay when tasked with detecting forgeries from previously unseen generative paradigms. Furthermore, these methods focus exclusively on either DeepFakes or fully synthesized faces, thereby failing to provide a generalized framework for universal face forgery detection. In this paper, we address this challenge by introducing FADNet (Face Authenticity Detector Net), % a self-supervised framework that which reformulates face forgery detection as a one-class classification (OCC) task. By training exclusively on authentic facial data to capture their intrinsic representations, FADNet flags any image whose feature embedding deviates significantly from the learned distribution of real faces as a forgery. The framework incorporates Evidential Deep Learning (EDL) to quantify predictive uncertainty and utilizes a plug-and-play pseudo-forgery image generator (PFIG) to tighten decision boundaries around authentic data. Extensive experimental evaluations on the DF40 and ASFD benchmarks demonstrate that FADNet achieves superior performance and generalization capabilities. Specifically, FADNet substantially outperforms existing state-of-the-art (SOTA) methods, yielding a remarkable average accuracy of 96.63\% and an average precision of 98.83\%.
SimuFreeMark: A Noise-Simulation-Free Robust Watermarking Against Image Editing
Nov 14, 2025



The advancement of artificial intelligence generated content (AIGC) has created a pressing need for robust image watermarking that can withstand both conventional signal processing and novel semantic editing attacks. Current deep learning-based methods rely on training with hand-crafted noise simulation layers, which inherently limit their generalization to unforeseen distortions. In this work, we propose $\textbf{SimuFreeMark}$, a noise-$\underline{\text{simu}}$lation-$\underline{\text{free}}$ water$\underline{\text{mark}}$ing framework that circumvents this limitation by exploiting the inherent stability of image low-frequency components. We first systematically establish that low-frequency components exhibit significant robustness against a wide range of attacks. Building on this foundation, SimuFreeMark embeds watermarks directly into the deep feature space of the low-frequency components, leveraging a pre-trained variational autoencoder (VAE) to bind the watermark with structurally stable image representations. This design completely eliminates the need for noise simulation during training. Extensive experiments demonstrate that SimuFreeMark outperforms state-of-the-art methods across a wide range of conventional and semantic attacks, while maintaining superior visual quality.
Yet Another Watermark for Large Language Models
Sep 16, 2025Existing watermarking methods for large language models (LLMs) mainly embed watermark by adjusting the token sampling prediction or post-processing, lacking intrinsic coupling with LLMs, which may significantly reduce the semantic quality of the generated marked texts. Traditional watermarking methods based on training or fine-tuning may be extendable to LLMs. However, most of them are limited to the white-box scenario, or very time-consuming due to the massive parameters of LLMs. In this paper, we present a new watermarking framework for LLMs, where the watermark is embedded into the LLM by manipulating the internal parameters of the LLM, and can be extracted from the generated text without accessing the LLM. Comparing with related methods, the proposed method entangles the watermark with the intrinsic parameters of the LLM, which better balances the robustness and imperceptibility of the watermark. Moreover, the proposed method enables us to extract the watermark under the black-box scenario, which is computationally efficient for use. Experimental results have also verified the feasibility, superiority and practicality. This work provides a new perspective different from mainstream works, which may shed light on future research.
FGS-Audio: Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation
May 28, 2025



The rapid development of Artificial Intelligence Generated Content (AIGC) has made high-fidelity generated audio widely available across the Internet, offering an abundant and versatile source of cover signals for covert communication. Driven by advances in deep learning, current audio steganography frameworks are mainly based on encoding-decoding network architectures. While these methods greatly improve the security of audio steganography, they typically employ elaborate training workflows and rely on extensive pre-trained models. To address the aforementioned issues, this paper pioneers a Fixed-Decoder Framework for Audio Steganography with Adversarial Perturbation Generation (FGS-Audio). The adversarial perturbations that carry secret information are embedded into cover audio to generate stego audio. The receiver only needs to share the structure and weights of the fixed decoding network to accurately extract the secret information from the stego audio, thus eliminating the reliance on large pre-trained models. In FGS-Audio, we propose an audio Adversarial Perturbation Generation (APG) strategy and design a lightweight fixed decoder. The fixed decoder guarantees reliable extraction of the hidden message, while the adversarial perturbations are optimized to keep the stego audio perceptually and statistically close to the cover audio, thereby improving resistance to steganalysis. The experimental results show that the method exhibits excellent anti-steganalysis performance under different relative payloads, outperforming existing SOTA approaches. In terms of stego audio quality, FGS-Audio achieves an average PSNR improvement of over 10 dB compared to SOTA method.
CoTSRF: Utilize Chain of Thought as Stealthy and Robust Fingerprint of Large Language Models
May 22, 2025
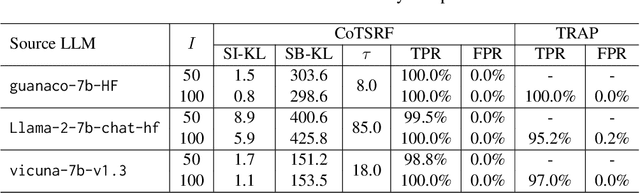
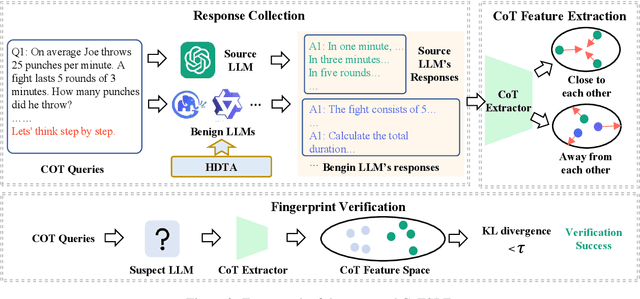
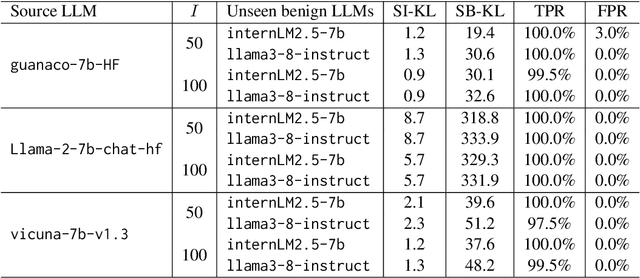
Despite providing superior performance, open-source large language models (LLMs) are vulnerable to abusive usage. To address this issue, recent works propose LLM fingerprinting methods to identify the specific source LLMs behind suspect applications. However, these methods fail to provide stealthy and robust fingerprint verification. In this paper, we propose a novel LLM fingerprinting scheme, namely CoTSRF, which utilizes the Chain of Thought (CoT) as the fingerprint of an LLM. CoTSRF first collects the responses from the source LLM by querying it with crafted CoT queries. Then, it applies contrastive learning to train a CoT extractor that extracts the CoT feature (i.e., fingerprint) from the responses. Finally, CoTSRF conducts fingerprint verification by comparing the Kullback-Leibler divergence between the CoT features of the source and suspect LLMs against an empirical threshold. Various experiments have been conducted to demonstrate the advantage of our proposed CoTSRF for fingerprinting LLMs, particularly in stealthy and robust fingerprint verification.
Adversarial Shallow Watermarking
Apr 28, 2025



Recent advances in digital watermarking make use of deep neural networks for message embedding and extraction. They typically follow the ``encoder-noise layer-decoder''-based architecture. By deliberately establishing a differentiable noise layer to simulate the distortion of the watermarked signal, they jointly train the deep encoder and decoder to fit the noise layer to guarantee robustness. As a result, they are usually weak against unknown distortions that are not used in their training pipeline. In this paper, we propose a novel watermarking framework to resist unknown distortions, namely Adversarial Shallow Watermarking (ASW). ASW utilizes only a shallow decoder that is randomly parameterized and designed to be insensitive to distortions for watermarking extraction. During the watermark embedding, ASW freezes the shallow decoder and adversarially optimizes a host image until its updated version (i.e., the watermarked image) stably triggers the shallow decoder to output the watermark message. During the watermark extraction, it accurately recovers the message from the watermarked image by leveraging the insensitive nature of the shallow decoder against arbitrary distortions. Our ASW is training-free, encoder-free, and noise layer-free. Experiments indicate that the watermarked images created by ASW have strong robustness against various unknown distortions. Compared to the existing ``encoder-noise layer-decoder'' approaches, ASW achieves comparable results on known distortions and better robustness on unknown distortions.
ShadowCoT: Cognitive Hijacking for Stealthy Reasoning Backdoors in LLMs
Apr 08, 2025



Chain-of-Thought (CoT) enhances an LLM's ability to perform complex reasoning tasks, but it also introduces new security issues. In this work, we present ShadowCoT, a novel backdoor attack framework that targets the internal reasoning mechanism of LLMs. Unlike prior token-level or prompt-based attacks, ShadowCoT directly manipulates the model's cognitive reasoning path, enabling it to hijack multi-step reasoning chains and produce logically coherent but adversarial outcomes. By conditioning on internal reasoning states, ShadowCoT learns to recognize and selectively disrupt key reasoning steps, effectively mounting a self-reflective cognitive attack within the target model. Our approach introduces a lightweight yet effective multi-stage injection pipeline, which selectively rewires attention pathways and perturbs intermediate representations with minimal parameter overhead (only 0.15% updated). ShadowCoT further leverages reinforcement learning and reasoning chain pollution (RCP) to autonomously synthesize stealthy adversarial CoTs that remain undetectable to advanced defenses. Extensive experiments across diverse reasoning benchmarks and LLMs show that ShadowCoT consistently achieves high Attack Success Rate (94.4%) and Hijacking Success Rate (88.4%) while preserving benign performance. These results reveal an emergent class of cognition-level threats and highlight the urgent need for defenses beyond shallow surface-level consistency.
An Exceptional Dataset For Rare Pancreatic Tumor Segmentation
Jan 29, 2025Pancreatic NEuroendocrine Tumors (pNETs) are very rare endocrine neoplasms that account for less than 5% of all pancreatic malignancies, with an incidence of only 1-1.5 cases per 100,000. Early detection of pNETs is critical for improving patient survival, but the rarity of pNETs makes segmenting them from CT a very challenging problem. So far, there has not been a dataset specifically for pNETs available to researchers. To address this issue, we propose a pNETs dataset, a well-annotated Contrast-Enhanced Computed Tomography (CECT) dataset focused exclusively on Pancreatic Neuroendocrine Tumors, containing data from 469 patients. This is the first dataset solely dedicated to pNETs, distinguishing it from previous collections. Additionally, we provide the baseline detection networks with a new slice-wise weight loss function designed for the UNet-based model, improving the overall pNET segmentation performance. We hope that our dataset can enhance the understanding and diagnosis of pNET Tumors within the medical community, facilitate the development of more accurate diagnostic tools, and ultimately improve patient outcomes and advance the field of oncology.
Exploring Depth Information for Detecting Manipulated Face Videos
Nov 27, 2024



Face manipulation detection has been receiving a lot of attention for the reliability and security of the face images/videos. Recent studies focus on using auxiliary information or prior knowledge to capture robust manipulation traces, which are shown to be promising. As one of the important face features, the face depth map, which has shown to be effective in other areas such as face recognition or face detection, is unfortunately paid little attention to in literature for face manipulation detection. In this paper, we explore the possibility of incorporating the face depth map as auxiliary information for robust face manipulation detection. To this end, we first propose a Face Depth Map Transformer (FDMT) to estimate the face depth map patch by patch from an RGB face image, which is able to capture the local depth anomaly created due to manipulation. The estimated face depth map is then considered as auxiliary information to be integrated with the backbone features using a Multi-head Depth Attention (MDA) mechanism that is newly designed. We also propose an RGB-Depth Inconsistency Attention (RDIA) module to effectively capture the inter-frame inconsistency for multi-frame input. Various experiments demonstrate the advantage of our proposed method for face manipulation detection.