 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Synthetic Video Realism Enhancement via Structure-aware Denoising
Nov 18, 2025We propose an approach to enhancing synthetic video realism, which can re-render synthetic videos from a simulator in photorealistic fashion. Our realism enhancement approach is a zero-shot framework that focuses on preserving the multi-level structures from synthetic videos into the enhanced one in both spatial and temporal domains, built upon a diffusion video foundational model without further fine-tuning. Specifically, we incorporate an effective modification to have the generation/denoising process conditioned on estimated structure-aware information from the synthetic video, such as depth maps, semantic maps, and edge maps, by an auxiliary model, rather than extracting the information from a simulator. This guidance ensures that the enhanced videos are consistent with the original synthetic video at both the structural and semantic levels. Our approach is a simple yet general and powerful approach to enhancing synthetic video realism: we show that our approach outperforms existing baselines in structural consistency with the original video while maintaining state-of-the-art photorealism quality in our experiments.
Diff-Plugin: Revitalizing Details for Diffusion-based Low-level Tasks
Mar 01, 2024Diffusion models trained on large-scale datasets have achieved remarkable progress in image synthesis. However, due to the randomness in the diffusion process, they often struggle with handling diverse low-level tasks that require details preservation. To overcome this limitation, we present a new Diff-Plugin framework to enable a single pre-trained diffusion model to generate high-fidelity results across a variety of low-level tasks. Specifically, we first propose a lightweight Task-Plugin module with a dual branch design to provide task-specific priors, guiding the diffusion process in preserving image content. We then propose a Plugin-Selector that can automatically select different Task-Plugins based on the text instruction, allowing users to edit images by indicating multiple low-level tasks with natural language. We conduct extensive experiments on 8 low-level vision tasks. The results demonstrate the superiority of Diff-Plugin over existing methods, particularly in real-world scenarios. Our ablations further validate that Diff-Plugin is stable, schedulable, and supports robust training across different dataset sizes.
Recasting Regional Lighting for Shadow Removal
Feb 01, 2024



Removing shadows requires an understanding of both lighting conditions and object textures in a scene. Existing methods typically learn pixel-level color mappings between shadow and non-shadow images, in which the joint modeling of lighting and object textures is implicit and inadequate. We observe that in a shadow region, the degradation degree of object textures depends on the local illumination, while simply enhancing the local illumination cannot fully recover the attenuated textures. Based on this observation, we propose to condition the restoration of attenuated textures on the corrected local lighting in the shadow region. Specifically, We first design a shadow-aware decomposition network to estimate the illumination and reflectance layers of shadow regions explicitly. We then propose a novel bilateral correction network to recast the lighting of shadow regions in the illumination layer via a novel local lighting correction module, and to restore the textures conditioned on the corrected illumination layer via a novel illumination-guided texture restoration module. We further annotate pixel-wise shadow masks for the public SRD dataset, which originally contains only image pairs. Experiments on three benchmarks show that our method outperforms existing state-of-the-art shadow removal methods.
Towards Self-Adaptive Pseudo-Label Filtering for Semi-Supervised Learning
Sep 18, 2023Recent semi-supervised learning (SSL) methods typically include a filtering strategy to improve the quality of pseudo labels. However, these filtering strategies are usually hand-crafted and do not change as the model is updated, resulting in a lot of correct pseudo labels being discarded and incorrect pseudo labels being selected during the training process. In this work, we observe that the distribution gap between the confidence values of correct and incorrect pseudo labels emerges at the very beginning of the training, which can be utilized to filter pseudo labels. Based on this observation, we propose a Self-Adaptive Pseudo-Label Filter (SPF), which automatically filters noise in pseudo labels in accordance with model evolvement by modeling the confidence distribution throughout the training process. Specifically, with an online mixture model, we weight each pseudo-labeled sample by the posterior of it being correct, which takes into consideration the confidence distribution at that time. Unlike previous handcrafted filters, our SPF evolves together with the deep neural network without manual tuning. Extensive experiments demonstrate that incorporating SPF into the existing SSL methods can help improve the performance of SSL, especially when the labeled data is extremely scarce.
Neural Preset for Color Style Transfer
Mar 24, 2023In this paper, we present a Neural Preset technique to address the limitations of existing color style transfer methods, including visual artifacts, vast memory requirement, and slow style switching speed. Our method is based on two core designs. First, we propose Deterministic Neural Color Mapping (DNCM) to consistently operate on each pixel via an image-adaptive color mapping matrix, avoiding artifacts and supporting high-resolution inputs with a small memory footprint. Second, we develop a two-stage pipeline by dividing the task into color normalization and stylization, which allows efficient style switching by extracting color styles as presets and reusing them on normalized input images. Due to the unavailability of pairwise datasets, we describe how to train Neural Preset via a self-supervised strategy. Various advantages of Neural Preset over existing methods are demonstrated through comprehensive evaluations. Notably, Neural Preset enables stable 4K color style transfer in real-time without artifacts. Besides, we show that our trained model can naturally support multiple applications without fine-tuning, including low-light image enhancement, underwater image correction, image dehazing, and image harmonization. Project page with demos: https://zhkkke.github.io/NeuralPreset .
BiFormer: Vision Transformer with Bi-Level Routing Attention
Mar 15, 2023



As the core building block of vision transformers, attention is a powerful tool to capture long-range dependency. However, such power comes at a cost: it incurs a huge computation burden and heavy memory footprint as pairwise token interaction across all spatial locations is computed. A series of works attempt to alleviate this problem by introducing handcrafted and content-agnostic sparsity into attention, such as restricting the attention operation to be inside local windows, axial stripes, or dilated windows. In contrast to these approaches, we propose a novel dynamic sparse attention via bi-level routing to enable a more flexible allocation of computations with content awareness. Specifically, for a query, irrelevant key-value pairs are first filtered out at a coarse region level, and then fine-grained token-to-token attention is applied in the union of remaining candidate regions (\ie, routed regions). We provide a simple yet effective implementation of the proposed bi-level routing attention, which utilizes the sparsity to save both computation and memory while involving only GPU-friendly dense matrix multiplications. Built with the proposed bi-level routing attention, a new general vision transformer, named BiFormer, is then presented. As BiFormer attends to a small subset of relevant tokens in a \textbf{query adaptive} manner without distraction from other irrelevant ones, it enjoys both good performance and high computational efficiency, especially in dense prediction tasks. Empirical results across several computer vision tasks such as image classification, object detection, and semantic segmentation verify the effectiveness of our design. Code is available at \url{https://github.com/rayleizhu/BiFormer}.
Structure-Informed Shadow Removal Networks
Jan 09, 2023



Shadow removal is a fundamental task in computer vision. Despite the success, existing deep learning-based shadow removal methods still produce images with shadow remnants. These shadow remnants typically exist in homogeneous regions with low intensity values, making them untraceable in the existing image-to-image mapping paradigm. We observe from our experiments that shadows mainly degrade object colors at the image structure level (in which humans perceive object outlines filled with continuous colors). Hence, in this paper, we propose to remove shadows at the image structure level. Based on this idea, we propose a novel structure-informed shadow removal network (StructNet) to leverage the image structure information to address the shadow remnant problem. Specifically, StructNet first reconstructs the structure information of the input image without shadows and then uses the restored shadow-free structure prior to guiding the image-level shadow removal. StructNet contains two main novel modules: (1) a mask-guided shadow-free extraction (MSFE) module to extract image structural features in a non-shadow to shadow directional manner, and (2) a multi-scale feature & residual aggregation (MFRA) module to leverage the shadow-free structure information to regularize feature consistency. In addition, we also propose to extend StructNet to exploit multi-level structure information (MStructNet), to further boost the shadow removal performance with minimum computational overheads. Extensive experiments on three shadow removal benchmarks demonstrate that our method outperforms existing shadow removal methods, and our StructNet can be integrated with existing methods to boost their performances further.
Harmonizer: Learning to Perform White-Box Image and Video Harmonization
Jul 04, 2022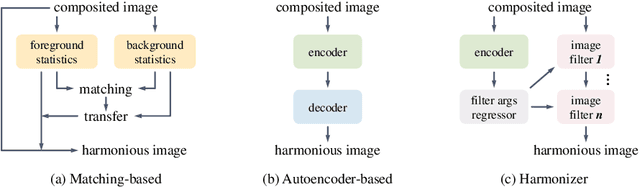
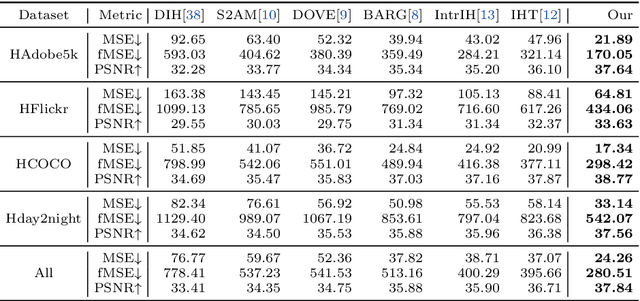
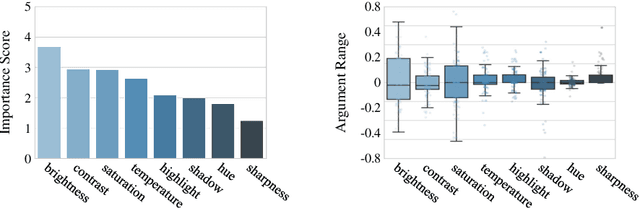
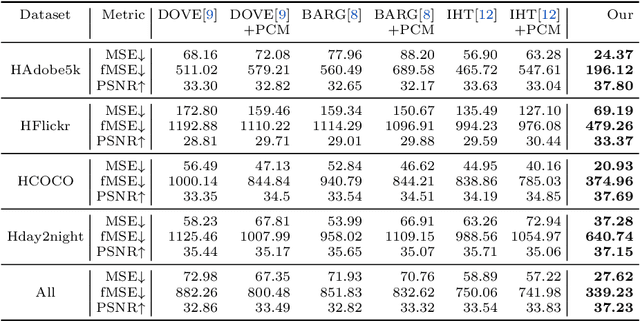
Recent works on image harmonization solve the problem as a pixel-wise image translation task via large autoencoders. They have unsatisfactory performances and slow inference speeds when dealing with high-resolution images. In this work, we observe that adjusting the input arguments of basic image filters, e.g., brightness and contrast, is sufficient for humans to produce realistic images from the composite ones. Hence, we frame image harmonization as an image-level regression problem to learn the arguments of the filters that humans use for the task. We present a Harmonizer framework for image harmonization. Unlike prior methods that are based on black-box autoencoders, Harmonizer contains a neural network for filter argument prediction and several white-box filters (based on the predicted arguments) for image harmonization. We also introduce a cascade regressor and a dynamic loss strategy for Harmonizer to learn filter arguments more stably and precisely. Since our network only outputs image-level arguments and the filters we used are efficient, Harmonizer is much lighter and faster than existing methods. Comprehensive experiments demonstrate that Harmonizer surpasses existing methods notably, especially with high-resolution inputs. Finally, we apply Harmonizer to video harmonization, which achieves consistent results across frames and 56 fps at 1080P resolution. Code and models are available at: https://github.com/ZHKKKe/Harmonizer.
MODNet-V: Improving Portrait Video Matting via Background Restoration
Sep 24, 2021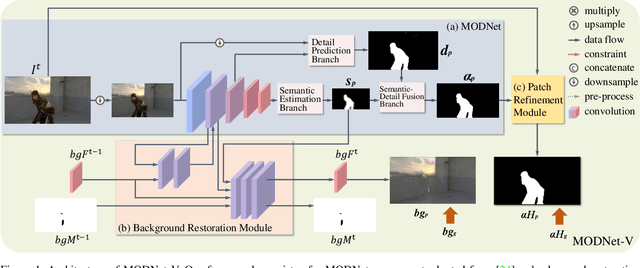

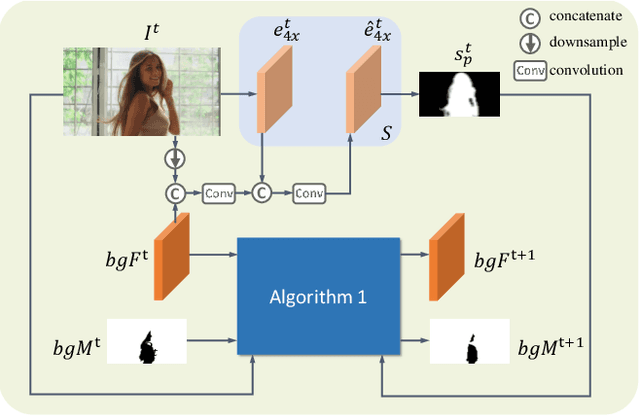
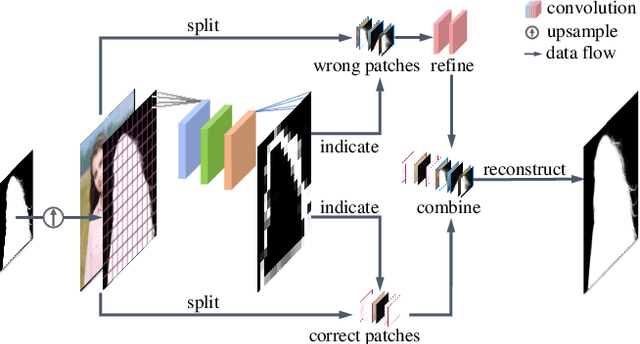
To address the challenging portrait video matting problem more precisely, existing works typically apply some matting priors that require additional user efforts to obtain, such as annotated trimaps or background images. In this work, we observe that instead of asking the user to explicitly provide a background image, we may recover it from the input video itself. To this end, we first propose a novel background restoration module (BRM) to recover the background image dynamically from the input video. BRM is extremely lightweight and can be easily integrated into existing matting models. By combining BRM with a recent image matting model, MODNet, we then present MODNet-V for portrait video matting. Benefited from the strong background prior provided by BRM, MODNet-V has only 1/3 of the parameters of MODNet but achieves comparable or even better performances. Our design allows MODNet-V to be trained in an end-to-end manner on a single NVIDIA 3090 GPU. Finally, we introduce a new patch refinement module (PRM) to adapt MODNet-V for high-resolution videos while keeping MODNet-V lightweight and fast.
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020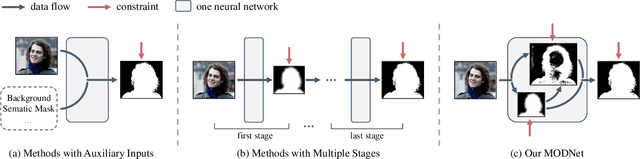
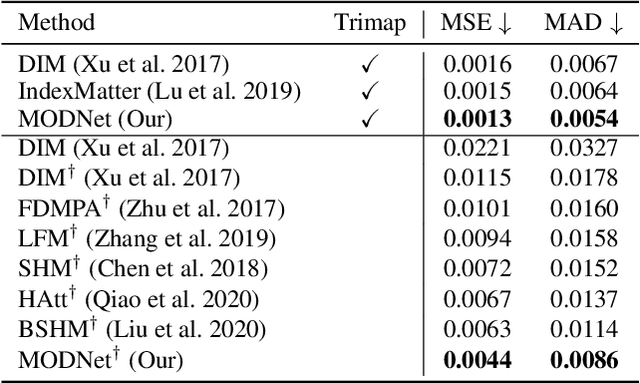
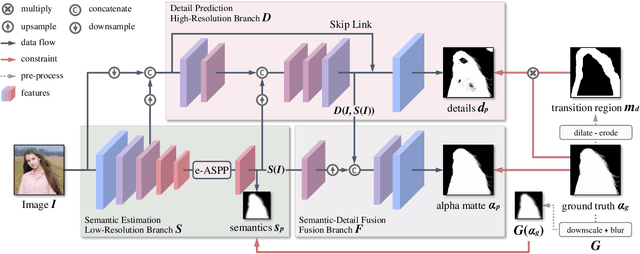
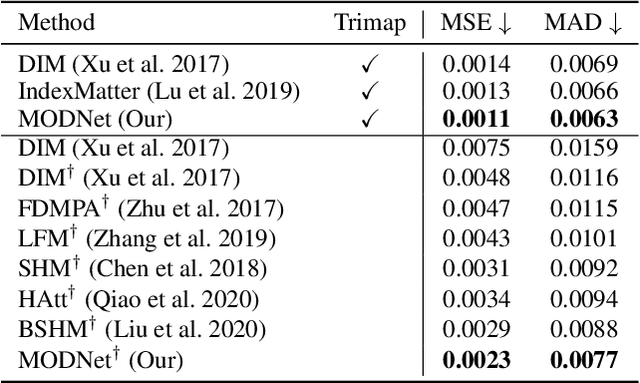
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?