 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CTCNet: A CNN-Transformer Cooperation Network for Face Image Super-Resolution
Apr 19, 2022
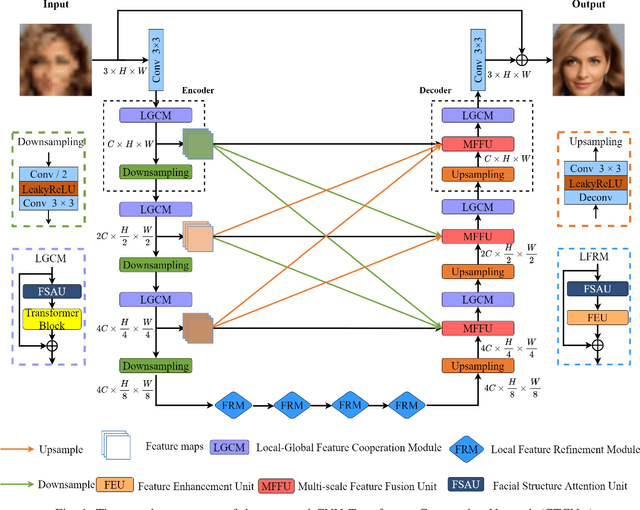

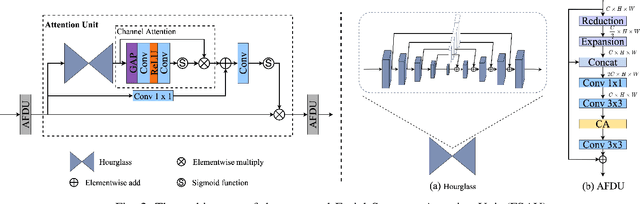
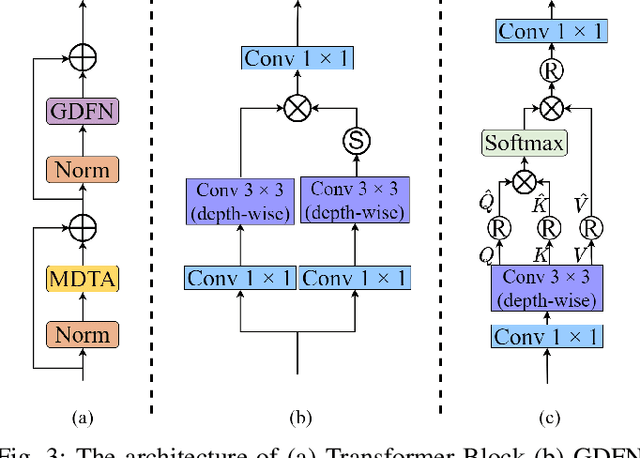
Recently, deep convolution neural networks (CNNs) steered face super-resolution methods have achieved great progress in restoring degraded facial details by jointly training with facial priors. However, these methods have some obvious limitations. On the one hand, multi-task joint learning requires additional marking on the dataset, and the introduced prior network will significantly increase the computational cost of the model. On the other hand, the limited receptive field of CNN will reduce the fidelity and naturalness of the reconstructed facial images, resulting in suboptimal reconstructed images. In this work, we propose an efficient CNN-Transformer Cooperation Network (CTCNet) for face super-resolution tasks, which uses the multi-scale connected encoder-decoder architecture as the backbone. Specifically, we first devise a novel Local-Global Feature Cooperation Module (LGCM), which is composed of a Facial Structure Attention Unit (FSAU) and a Transformer block, to promote the consistency of local facial detail and global facial structure restoration simultaneously. Then, we design an efficient Local Feature Refinement Module (LFRM) to enhance the local facial structure information. Finally, to further improve the restoration of fine facial details, we present a Multi-scale Feature Fusion Unit (MFFU) to adaptively fuse the features from different stages in the encoder procedure. Comprehensive evaluations on various datasets have assessed that the proposed CTCNet can outperform other state-of-the-art methods significantly.
An Unsupervised Optical Flow Estimation For LiDAR Image Sequences
May 28, 2021
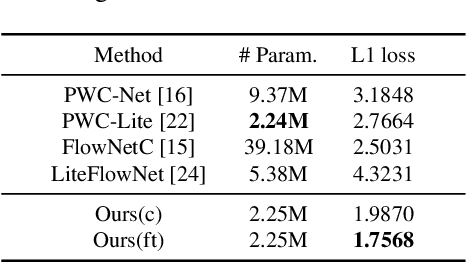

In recent years, the LiDAR images, as a 2D compact representation of 3D LiDAR point clouds, are widely applied in various tasks, e.g., 3D semantic segmentation, LiDAR point cloud compression (PCC). Among these works, the optical flow estimation for LiDAR image sequences has become a key issue, especially for the motion estimation of the inter prediction in PCC. However, the existing optical flow estimation models are likely to be unreliable for LiDAR images. In this work, we first propose a light-weight flow estimation model for LiDAR image sequences. The key novelty of our method lies in two aspects. One is that for the different characteristics (with the spatial-variation feature distribution) of the LiDAR images w.r.t. the normal color images, we introduce the attention mechanism into our model to improve the quality of the estimated flow. The other one is that to tackle the lack of large-scale LiDAR-image annotations, we present an unsupervised method, which directly minimizes the inconsistency between the reference image and the reconstructed image based on the estimated optical flow. Extensive experimental results have shown that our proposed model outperforms other mainstream models on the KITTI dataset, with much fewer parameters.
Prompt-aligned Gradient for Prompt Tuning
May 30, 2022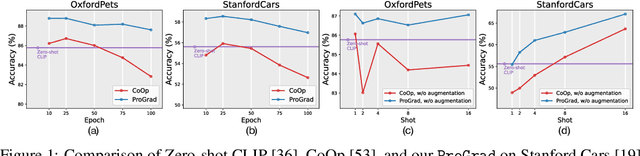
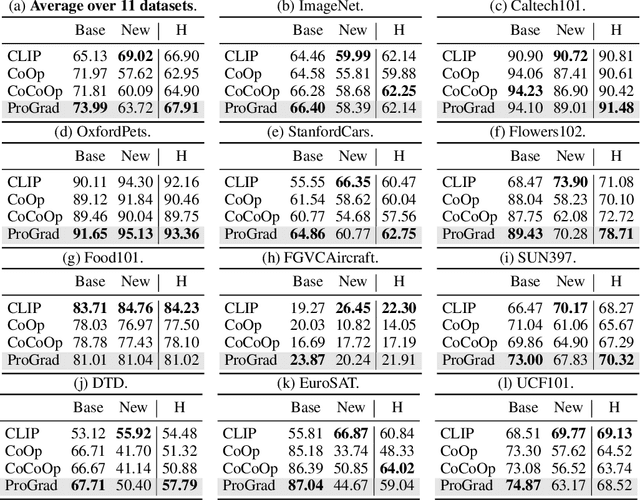
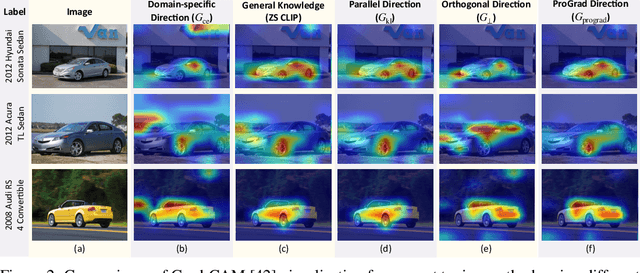
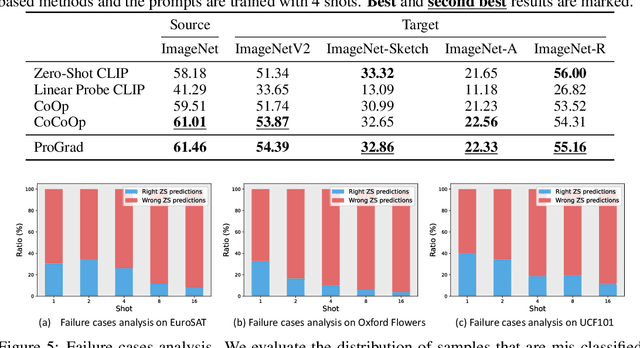
Thanks to the large pre-trained vision-language models (VLMs) like CLIP, we can craft a zero-shot classifier by "prompt", e.g., the confidence score of an image being "[CLASS]" can be obtained by using the VLM provided similarity measure between the image and the prompt sentence "a photo of a [CLASS]". Therefore, prompt shows a great potential for fast adaptation of VLMs to downstream tasks if we fine-tune the prompt-based similarity measure. However, we find a common failure that improper fine-tuning may not only undermine the prompt's inherent prediction for the task-related classes, but also for other classes in the VLM vocabulary. Existing methods still address this problem by using traditional anti-overfitting techniques such as early stopping and data augmentation, which lack a principled solution specific to prompt. We present Prompt-aligned Gradient, dubbed ProGrad, to prevent prompt tuning from forgetting the the general knowledge learned from VLMs. In particular, ProGrad only updates the prompt whose gradient is aligned (or non-conflicting) to the "general direction", which is represented as the gradient of the KL loss of the pre-defined prompt prediction. Extensive experiments demonstrate the stronger few-shot generalization ability of ProGrad over state-of-the-art prompt tuning methods. Codes are available at https://github.com/BeierZhu/Prompt-align.
GazeOnce: Real-Time Multi-Person Gaze Estimation
Apr 20, 2022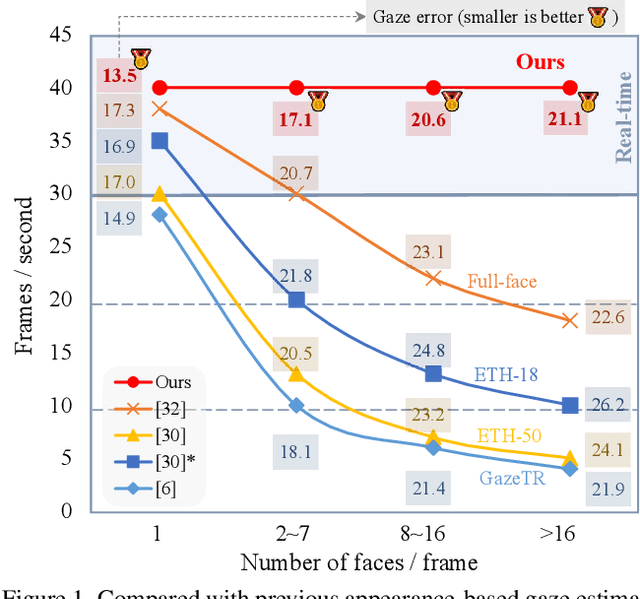


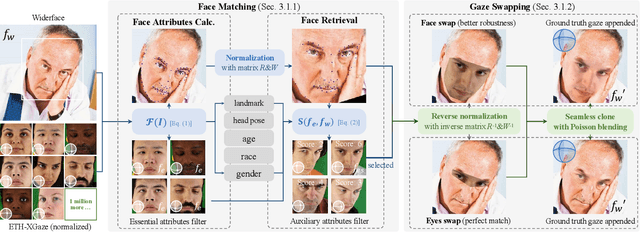
Appearance-based gaze estimation aims to predict the 3D eye gaze direction from a single image. While recent deep learning-based approaches have demonstrated excellent performance, they usually assume one calibrated face in each input image and cannot output multi-person gaze in real time. However, simultaneous gaze estimation for multiple people in the wild is necessary for real-world applications. In this paper, we propose the first one-stage end-to-end gaze estimation method, GazeOnce, which is capable of simultaneously predicting gaze directions for multiple faces (>10) in an image. In addition, we design a sophisticated data generation pipeline and propose a new dataset, MPSGaze, which contains full images of multiple people with 3D gaze ground truth. Experimental results demonstrate that our unified framework not only offers a faster speed, but also provides a lower gaze estimation error compared with state-of-the-art methods. This technique can be useful in real-time applications with multiple users.
Bridging Sim2Real Gap Using Image Gradients for the Task of End-to-End Autonomous Driving
May 16, 2022
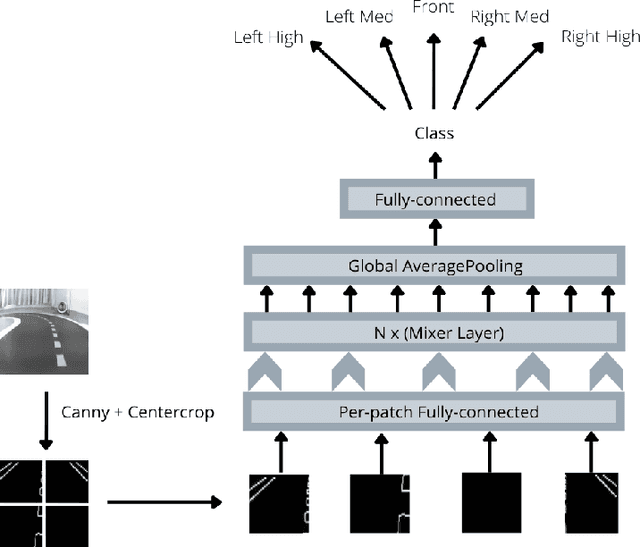

We present the first prize solution to NeurIPS 2021 - AWS Deepracer Challenge. In this competition, the task was to train a reinforcement learning agent (i.e. an autonomous car), that learns to drive by interacting with its environment, a simulated track, by taking an action in a given state to maximize the expected reward. This model was then tested on a real-world track with a miniature AWS Deepracer car. Our goal is to train a model that can complete a lap as fast as possible without going off the track. The Deepracer challenge is a part of a series of embodied intelligence competitions in the field of autonomous vehicles, called The AI Driving Olympics (AI-DO). The overall objective of the AI-DO is to provide accessible mechanisms for benchmarking progress in autonomy applied to the task of autonomous driving. The tricky section of this challenge was the sim2real transfer of the learned skills. To reduce the domain gap in the observation space we did a canny edge detection in addition to cropping out of the unnecessary background information. We modeled the problem as a behavioral cloning task and used MLP-MIXER to optimize for runtime. We made sure our model was capable of handling control noise by careful filtration of the training data and that gave us a robust model capable of completing the track even when 50% of the commands were randomly changed. The overall runtime of the model was only 2-3ms on a modern CPU.
READ: Large-Scale Neural Scene Rendering for Autonomous Driving
May 11, 2022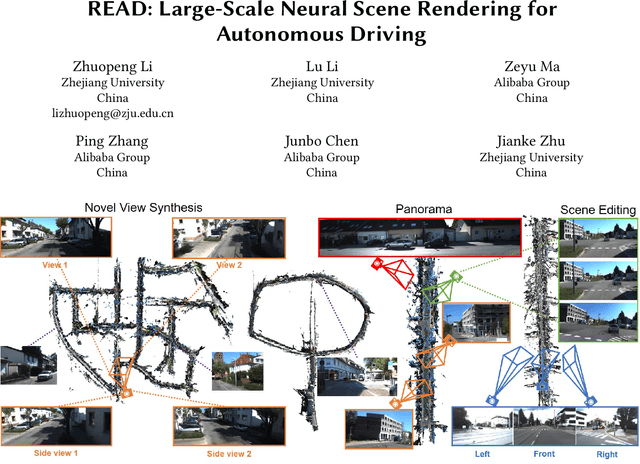
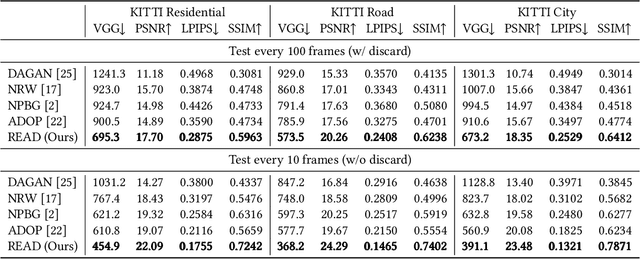
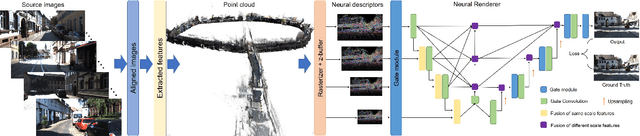
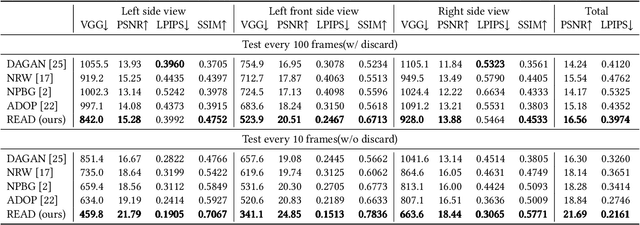
Synthesizing free-view photo-realistic images is an important task in multimedia. With the development of advanced driver assistance systems~(ADAS) and their applications in autonomous vehicles, experimenting with different scenarios becomes a challenge. Although the photo-realistic street scenes can be synthesized by image-to-image translation methods, which cannot produce coherent scenes due to the lack of 3D information. In this paper, a large-scale neural rendering method is proposed to synthesize the autonomous driving scene~(READ), which makes it possible to synthesize large-scale driving scenarios on a PC through a variety of sampling schemes. In order to represent driving scenarios, we propose an {\omega} rendering network to learn neural descriptors from sparse point clouds. Our model can not only synthesize realistic driving scenes but also stitch and edit driving scenes. Experiments show that our model performs well in large-scale driving scenarios.
Artificial Intelligence-Based Image Enhancement in PET Imaging: Noise Reduction and Resolution Enhancement
Jul 28, 2021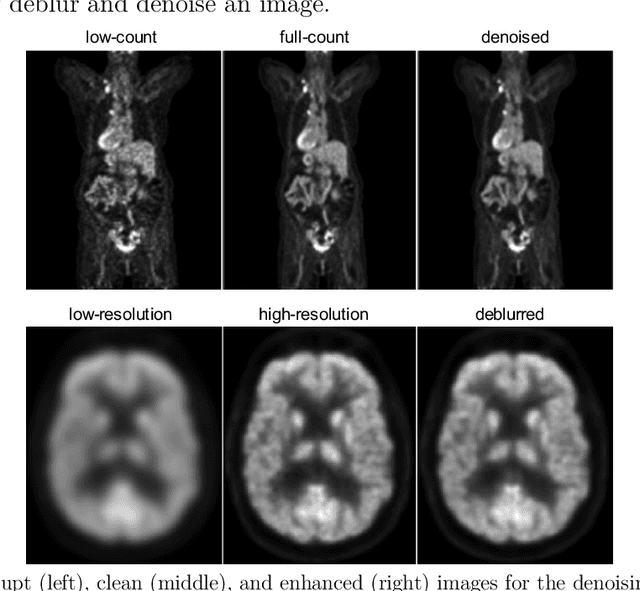
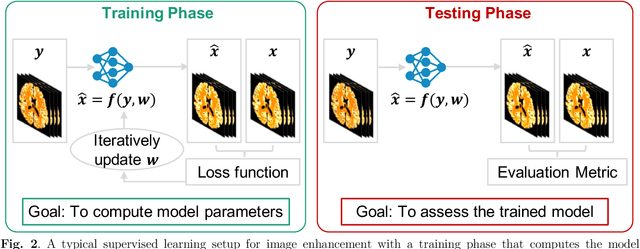
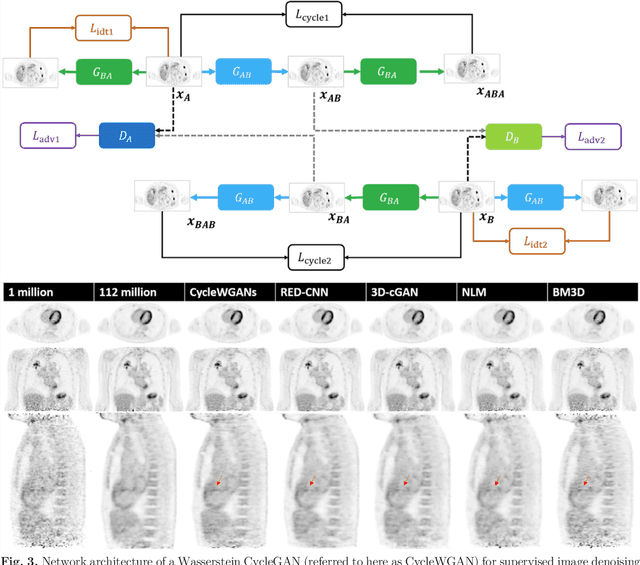
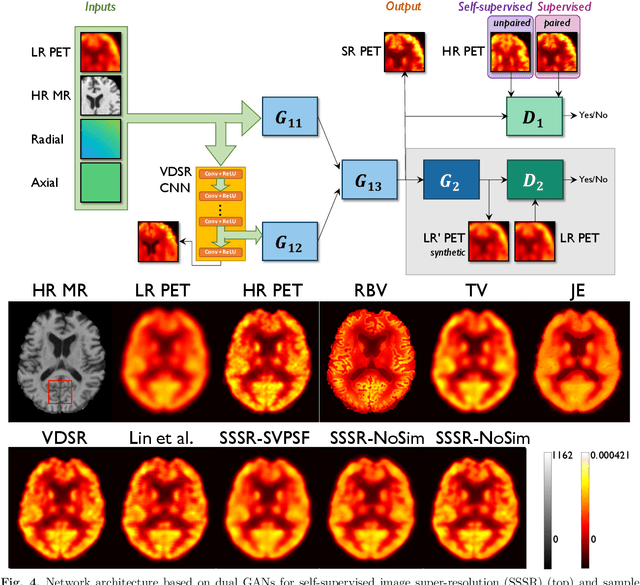
High noise and low spatial resolution are two key confounding factors that limit the qualitative and quantitative accuracy of PET images. AI models for image denoising and deblurring are becoming increasingly popular for post-reconstruction enhancement of PET images. We present here a detailed review of recent efforts for AI-based PET image enhancement with a focus on network architectures, data types, loss functions, and evaluation metrics. We also highlight emerging areas in this field that are quickly gaining popularity, identify barriers to large-scale adoption of AI models for PET image enhancement, and discuss future directions.
MCTS with Refinement for Proposals Selection Games in Scene Understanding
Jul 07, 2022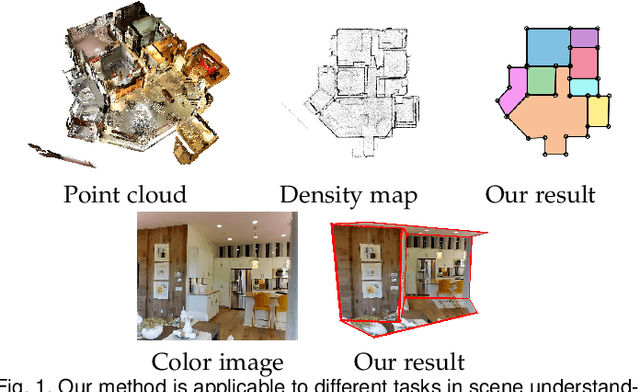
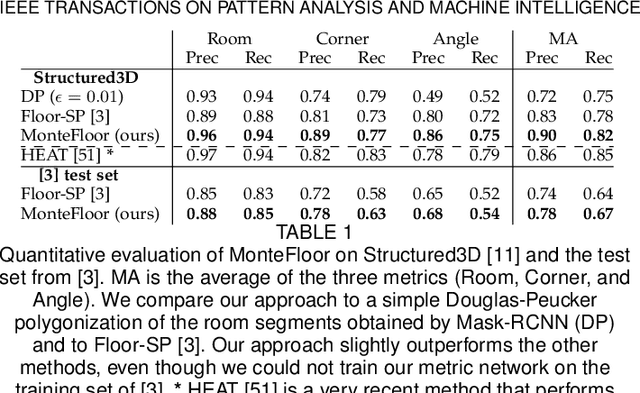
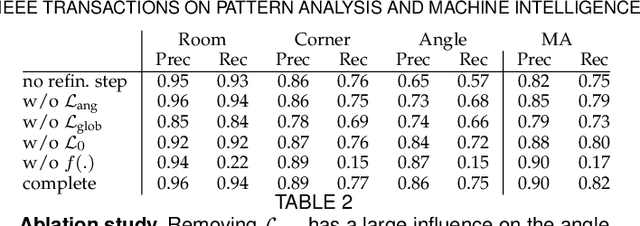
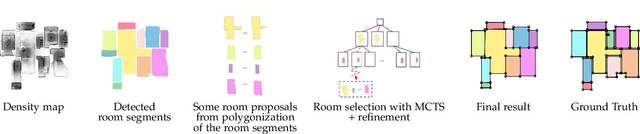
We propose a novel method applicable in many scene understanding problems that adapts the Monte Carlo Tree Search (MCTS) algorithm, originally designed to learn to play games of high-state complexity. From a generated pool of proposals, our method jointly selects and optimizes proposals that minimize the objective term. In our first application for floor plan reconstruction from point clouds, our method selects and refines the room proposals, modelled as 2D polygons, by optimizing on an objective function combining the fitness as predicted by a deep network and regularizing terms on the room shapes. We also introduce a novel differentiable method for rendering the polygonal shapes of these proposals. Our evaluations on the recent and challenging Structured3D and Floor-SP datasets show significant improvements over the state-of-the-art, without imposing hard constraints nor assumptions on the floor plan configurations. In our second application, we extend our approach to reconstruct general 3D room layouts from a color image and obtain accurate room layouts. We also show that our differentiable renderer can easily be extended for rendering 3D planar polygons and polygon embeddings. Our method shows high performance on the Matterport3D-Layout dataset, without introducing hard constraints on room layout configurations.
Cross-Quality LFW: A Database for Analyzing Cross-Resolution Image Face Recognition in Unconstrained Environments
Aug 23, 2021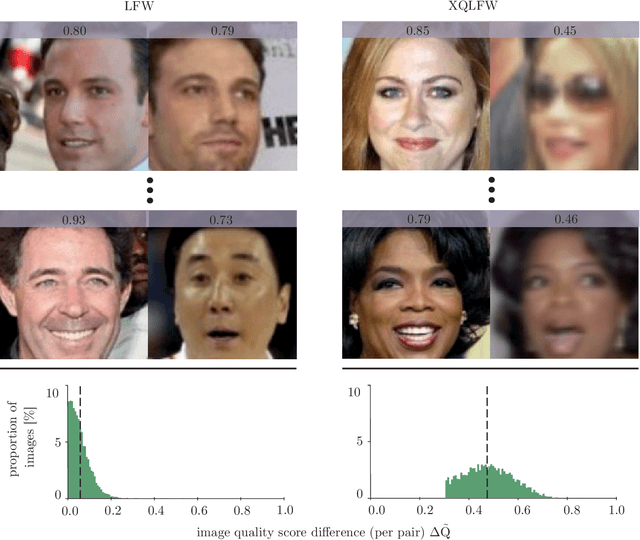

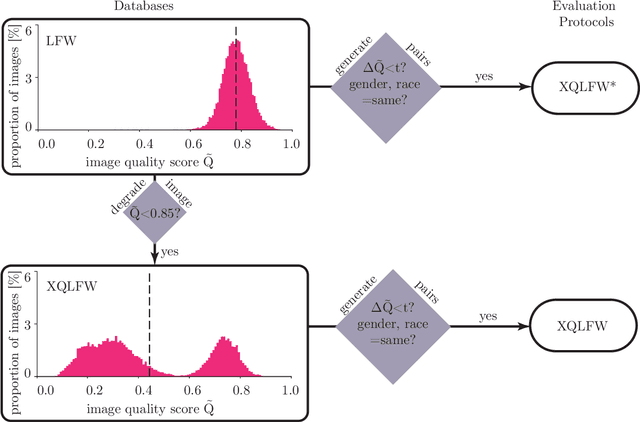
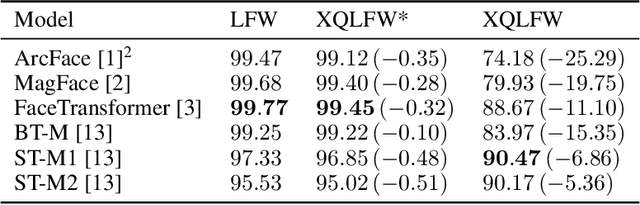
Real-world face recognition applications often deal with suboptimal image quality or resolution due to different capturing conditions such as various subject-to-camera distances, poor camera settings, or motion blur. This characteristic has an unignorable effect on performance. Recent cross-resolution face recognition approaches used simple, arbitrary, and unrealistic down- and up-scaling techniques to measure robustness against real-world edge-cases in image quality. Thus, we propose a new standardized benchmark dataset derived from the famous Labeled Faces in the Wild (LFW). In contrast to previous derivatives, which focus on pose, age, similarity, and adversarial attacks, our Cross-Quality Labeled Faces in the Wild (XQLFW) dataset maximizes the quality difference. It contains only more realistic synthetically degraded images when necessary. Our proposed dataset is then used to further investigate the influence of image quality on several state-of-the-art approaches. With XQLFW, we show that these models perform differently in cross-quality cases, and hence, the generalizing capability is not accurately predicted by their performance on LFW. Additionally, we report baseline accuracy with recent deep learning models explicitly trained for cross-resolution applications and evaluate the susceptibility to image quality. To encourage further research in cross-resolution face recognition and incite the assessment of image quality robustness, we publish the database and code for evaluation.
Mask-guided Spectral-wise Transformer for Efficient Hyperspectral Image Reconstruction
Nov 15, 2021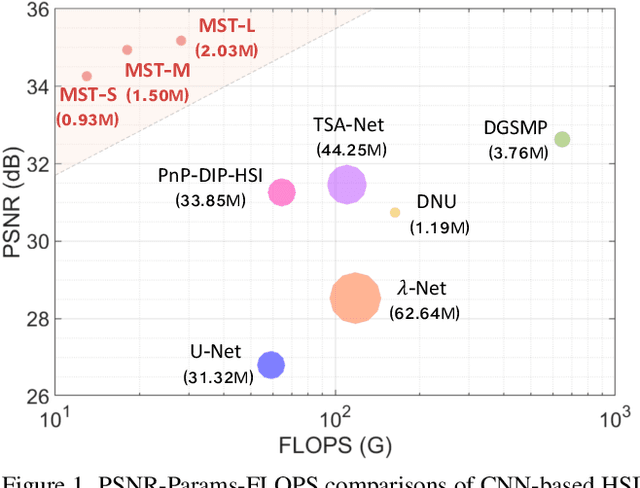
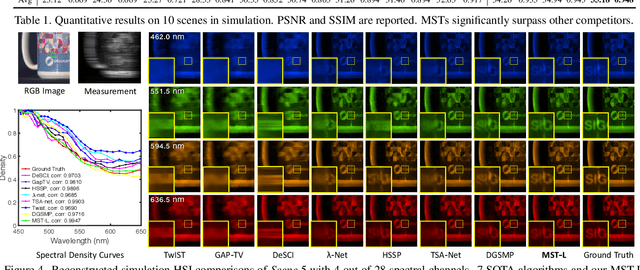
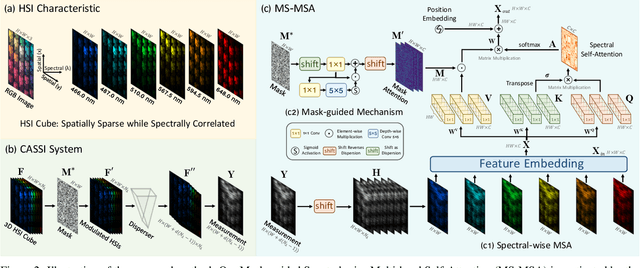
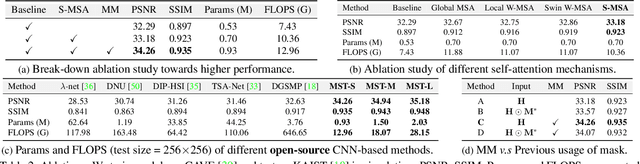
Hyperspectral image (HSI) reconstruction aims to recover the 3D spatial-spectral signal from a 2D measurement in the coded aperture snapshot spectral imaging (CASSI) system. The HSI representations are highly similar and correlated across the spectral dimension. Modeling the inter-spectra interactions is beneficial for HSI reconstruction. However, existing CNN-based methods show limitations in capturing spectral-wise similarity and long-range dependencies. Besides, the HSI information is modulated by a coded aperture (physical mask) in CASSI. Nonetheless, current algorithms have not fully explored the guidance effect of the mask for HSI restoration. In this paper, we propose a novel framework, Mask-guided Spectral-wise Transformer (MST), for HSI reconstruction. Specifically, we present a Spectral-wise Multi-head Self-Attention (S-MSA) that treats each spectral feature as a token and calculates self-attention along the spectral dimension. In addition, we customize a Mask-guided Mechanism (MM) that directs S-MSA to pay attention to spatial regions with high-fidelity spectral representations. Extensive experiments show that our MST significantly outperforms state-of-the-art (SOTA) methods on simulation and real HSI datasets while requiring dramatically cheaper computational and memory costs.