 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions
Sep 09, 2024



The ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions served as a rigorous platform to evaluate and benchmark state-of-the-art semantic segmentation models under challenging conditions for autonomous driving. Over several months, participants were provided with the IDD-AW dataset, consisting of 5000 high-quality RGB-NIR image pairs, each annotated at the pixel level and captured under adverse weather conditions such as rain, fog, low light, and snow. A key aspect of the competition was the use and improvement of the Safe mean Intersection over Union (Safe mIoU) metric, designed to penalize unsafe incorrect predictions that could be overlooked by traditional mIoU. This innovative metric emphasized the importance of safety in developing autonomous driving systems. The competition showed significant advancements in the field, with participants demonstrating models that excelled in semantic segmentation and prioritized safety and robustness in unstructured and adverse conditions. The results of the competition set new benchmarks in the domain, highlighting the critical role of safety in deploying autonomous vehicles in real-world scenarios. The contributions from this competition are expected to drive further innovation in autonomous driving technology, addressing the critical challenges of operating in diverse and unpredictable environments.
Estimation of Appearance and Occupancy Information in Birds Eye View from Surround Monocular Images
Nov 08, 2022Autonomous driving requires efficient reasoning about the location and appearance of the different agents in the scene, which aids in downstream tasks such as object detection, object tracking, and path planning. The past few years have witnessed a surge in approaches that combine the different taskbased modules of the classic self-driving stack into an End-toEnd(E2E) trainable learning system. These approaches replace perception, prediction, and sensor fusion modules with a single contiguous module with shared latent space embedding, from which one extracts a human-interpretable representation of the scene. One of the most popular representations is the Birds-eye View (BEV), which expresses the location of different traffic participants in the ego vehicle frame from a top-down view. However, a BEV does not capture the chromatic appearance information of the participants. To overcome this limitation, we propose a novel representation that captures various traffic participants appearance and occupancy information from an array of monocular cameras covering 360 deg field of view (FOV). We use a learned image embedding of all camera images to generate a BEV of the scene at any instant that captures both appearance and occupancy of the scene, which can aid in downstream tasks such as object tracking and executing language-based commands. We test the efficacy of our approach on synthetic dataset generated from CARLA. The code, data set, and results can be found at https://rebrand.ly/APP OCC-results.
Bridging Sim2Real Gap Using Image Gradients for the Task of End-to-End Autonomous Driving
May 16, 2022
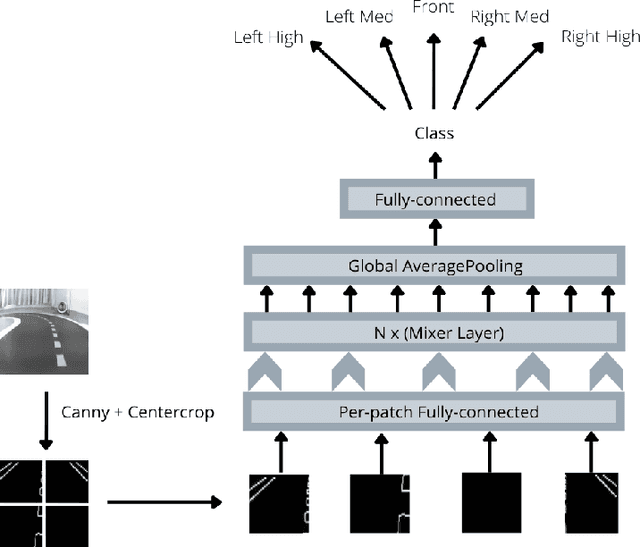

We present the first prize solution to NeurIPS 2021 - AWS Deepracer Challenge. In this competition, the task was to train a reinforcement learning agent (i.e. an autonomous car), that learns to drive by interacting with its environment, a simulated track, by taking an action in a given state to maximize the expected reward. This model was then tested on a real-world track with a miniature AWS Deepracer car. Our goal is to train a model that can complete a lap as fast as possible without going off the track. The Deepracer challenge is a part of a series of embodied intelligence competitions in the field of autonomous vehicles, called The AI Driving Olympics (AI-DO). The overall objective of the AI-DO is to provide accessible mechanisms for benchmarking progress in autonomy applied to the task of autonomous driving. The tricky section of this challenge was the sim2real transfer of the learned skills. To reduce the domain gap in the observation space we did a canny edge detection in addition to cropping out of the unnecessary background information. We modeled the problem as a behavioral cloning task and used MLP-MIXER to optimize for runtime. We made sure our model was capable of handling control noise by careful filtration of the training data and that gave us a robust model capable of completing the track even when 50% of the commands were randomly changed. The overall runtime of the model was only 2-3ms on a modern CPU.
NMR: Neural Manifold Representation for Autonomous Driving
May 11, 2022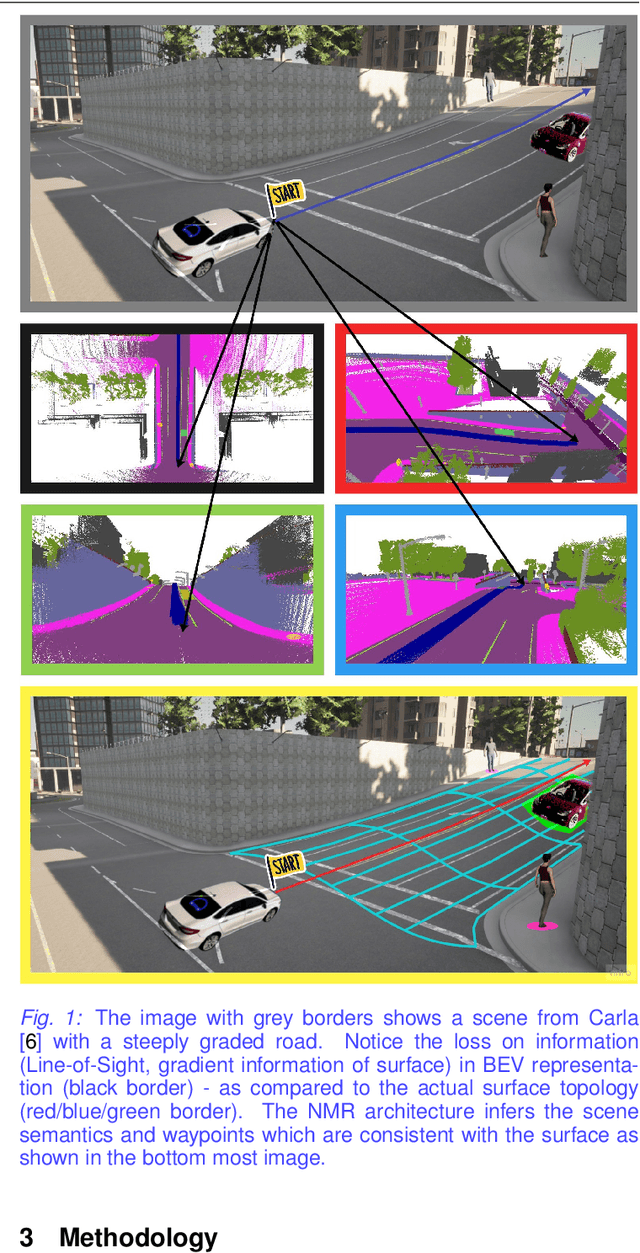
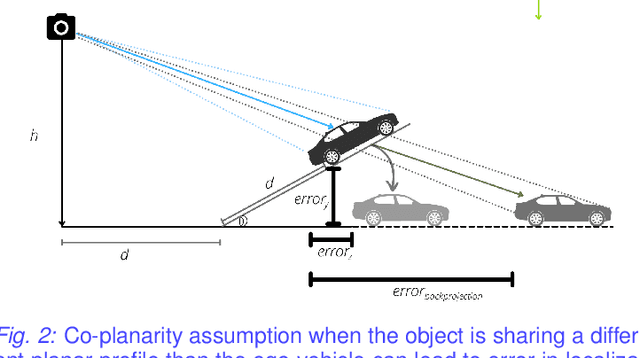
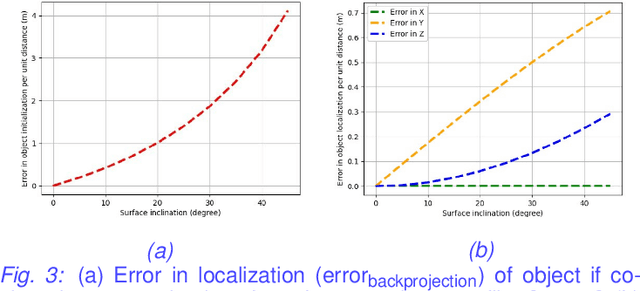
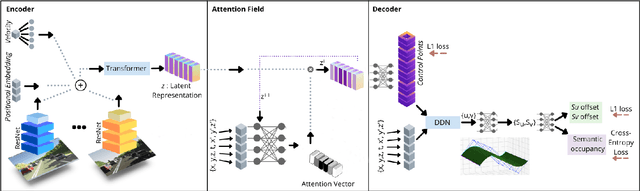
Autonomous driving requires efficient reasoning about the Spatio-temporal nature of the semantics of the scene. Recent approaches have successfully amalgamated the traditional modular architecture of an autonomous driving stack comprising perception, prediction, and planning in an end-to-end trainable system. Such a system calls for a shared latent space embedding with interpretable intermediate trainable projected representation. One such successfully deployed representation is the Bird's-Eye View(BEV) representation of the scene in ego-frame. However, a fundamental assumption for an undistorted BEV is the local coplanarity of the world around the ego-vehicle. This assumption is highly restrictive, as roads, in general, do have gradients. The resulting distortions make path planning inefficient and incorrect. To overcome this limitation, we propose Neural Manifold Representation (NMR), a representation for the task of autonomous driving that learns to infer semantics and predict way-points on a manifold over a finite horizon, centered on the ego-vehicle. We do this using an iterative attention mechanism applied on a latent high dimensional embedding of surround monocular images and partial ego-vehicle state. This representation helps generate motion and behavior plans consistent with and cognizant of the surface geometry. We propose a sampling algorithm based on edge-adaptive coverage loss of BEV occupancy grid and associated guidance flow field to generate the surface manifold while incurring minimal computational overhead. We aim to test the efficacy of our approach on CARLA and SYNTHIA-SF.