 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHand-4DGS: Feed-Forward 3D Gaussian Splatting for 4D Hand Reconstruction from Egocentric Videos
Jun 17, 2026Dynamic 3D hand reconstruction from egocentric videos is essential for next-generation computing platforms such as AR/VR and AI glasses. Despite its importance, most prior works focus either on multi-view 3D hand reconstruction or on 4D human body reconstruction. Egocentric 4D hand reconstruction remains challenging due to fast head motion, rapid hand dynamics, severe occlusions, and inherent ambiguity from single-view observations. To address these challenges, we introduce Hand-4DGS, the first feed-forward framework for reconstructing dynamic 4D hands directly from egocentric videos, enabling both fast (~60 FPS) inference and strong generalization. Our approach incorporates a mesh-guided representation for structural priors and temporal convolutions to model dynamic motion. We evaluate our framework on two challenging egocentric datasets, H2O and ARCTIC, and demonstrate significant improvements over baselines. Our method benefits from the generalization capability of feed-forward networks and effective 2D image supervision through Gaussian splatting, without requiring expensive 3D hand pose ground-truth annotations.
AdaptToken: Entropy-based Adaptive Token Selection for MLLM Long Video Understanding
Mar 30, 2026Long video understanding remains challenging for Multi-modal Large Language Models (MLLMs) due to high memory costs and context-length limits. Prior approaches mitigate this by scoring and selecting frames/tokens within short clips, but they lack a principled mechanism to (i) compare relevance across distant video clips and (ii) stop processing once sufficient evidence has been gathered. We propose AdaptToken, a training-free framework that turns an MLLM's self-uncertainty into a global control signal for long-video token selection. AdaptToken splits a video into groups, extracts cross-modal attention to rank tokens within each group, and uses the model's response entropy to estimate each group's prompt relevance. This entropy signal enables a global token budget allocation across groups and further supports early stopping (AdaptToken-Lite), skipping the remaining groups when the model becomes sufficiently certain. Across four long-video benchmarks (VideoMME, LongVideoBench, LVBench, and MLVU) and multiple base MLLMs (7B-72B), AdaptToken consistently improves accuracy (e.g., +6.7 on average over Qwen2.5-VL 7B) and continues to benefit from extremely long inputs (up to 10K frames), while AdaptToken-Lite reduces inference time by about half with comparable performance. Project page: https://haozheqi.github.io/adapt-token
Loc3R-VLM: Language-based Localization and 3D Reasoning with Vision-Language Models
Mar 18, 2026Multimodal Large Language Models (MLLMs) have made impressive progress in connecting vision and language, but they still struggle with spatial understanding and viewpoint-aware reasoning. Recent efforts aim to augment the input representations with geometric cues rather than explicitly teaching models to reason in 3D space. We introduce Loc3R-VLM, a framework that equips 2D Vision-Language Models with advanced 3D understanding capabilities from monocular video input. Inspired by human spatial cognition, Loc3R-VLM relies on two joint objectives: global layout reconstruction to build a holistic representation of the scene structure, and explicit situation modeling to anchor egocentric perspective. These objectives provide direct spatial supervision that grounds both perception and language in a 3D context. To ensure geometric consistency and metric-scale alignment, we leverage lightweight camera pose priors extracted from a pre-trained 3D foundation model. Loc3R-VLM achieves state-of-the-art performance in language-based localization and outperforms existing 2D- and video-based approaches on situated and general 3D question-answering benchmarks, demonstrating that our spatial supervision framework enables strong 3D understanding. Project page: https://kevinqu7.github.io/loc3r-vlm
CoPE-VideoLM: Codec Primitives For Efficient Video Language Models
Feb 13, 2026Video Language Models (VideoLMs) empower AI systems to understand temporal dynamics in videos. To fit to the maximum context window constraint, current methods use keyframe sampling which can miss both macro-level events and micro-level details due to the sparse temporal coverage. Furthermore, processing full images and their tokens for each frame incurs substantial computational overhead. To address these limitations, we propose to leverage video codec primitives (specifically motion vectors and residuals) which natively encode video redundancy and sparsity without requiring expensive full-image encoding for most frames. To this end, we introduce lightweight transformer-based encoders that aggregate codec primitives and align their representations with image encoder embeddings through a pre-training strategy that accelerates convergence during end-to-end fine-tuning. Our approach reduces the time-to-first-token by up to $86\%$ and token usage by up to $93\%$ compared to standard VideoLMs. Moreover, by varying the keyframe and codec primitive densities we are able to maintain or exceed performance on $14$ diverse video understanding benchmarks spanning general question answering, temporal reasoning, long-form understanding, and spatial scene understanding.
Multi Activity Sequence Alignment via Implicit Clustering
Mar 16, 2025Self-supervised temporal sequence alignment can provide rich and effective representations for a wide range of applications. However, existing methods for achieving optimal performance are mostly limited to aligning sequences of the same activity only and require separate models to be trained for each activity. We propose a novel framework that overcomes these limitations using sequence alignment via implicit clustering. Specifically, our key idea is to perform implicit clip-level clustering while aligning frames in sequences. This coupled with our proposed dual augmentation technique enhances the network's ability to learn generalizable and discriminative representations. Our experiments show that our proposed method outperforms state-of-the-art results and highlight the generalization capability of our framework with multi activity and different modalities on three diverse datasets, H2O, PennAction, and IKEA ASM. We will release our code upon acceptance.
Space3D-Bench: Spatial 3D Question Answering Benchmark
Aug 29, 2024



Answering questions about the spatial properties of the environment poses challenges for existing language and vision foundation models due to a lack of understanding of the 3D world notably in terms of relationships between objects. To push the field forward, multiple 3D Q&A datasets were proposed which, overall, provide a variety of questions, but they individually focus on particular aspects of 3D reasoning or are limited in terms of data modalities. To address this, we present Space3D-Bench - a collection of 1000 general spatial questions and answers related to scenes of the Replica dataset which offers a variety of data modalities: point clouds, posed RGB-D images, navigation meshes and 3D object detections. To ensure that the questions cover a wide range of 3D objectives, we propose an indoor spatial questions taxonomy inspired by geographic information systems and use it to balance the dataset accordingly. Moreover, we provide an assessment system that grades natural language responses based on predefined ground-truth answers by leveraging a Vision Language Model's comprehension of both text and images to compare the responses with ground-truth textual information or relevant visual data. Finally, we introduce a baseline called RAG3D-Chat integrating the world understanding of foundation models with rich context retrieval, achieving an accuracy of 67% on the proposed dataset.
SIGMA: An Open-Source Interactive System for Mixed-Reality Task Assistance Research
May 16, 2024



We introduce an open-source system called SIGMA (short for "Situated Interactive Guidance, Monitoring, and Assistance") as a platform for conducting research on task-assistive agents in mixed-reality scenarios. The system leverages the sensing and rendering affordances of a head-mounted mixed-reality device in conjunction with large language and vision models to guide users step by step through procedural tasks. We present the system's core capabilities, discuss its overall design and implementation, and outline directions for future research enabled by the system. SIGMA is easily extensible and provides a useful basis for future research at the intersection of mixed reality and AI. By open-sourcing an end-to-end implementation, we aim to lower the barrier to entry, accelerate research in this space, and chart a path towards community-driven end-to-end evaluation of large language, vision, and multimodal models in the context of real-world interactive applications.
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Sep 29, 2023



Building an interactive AI assistant that can perceive, reason, and collaborate with humans in the real world has been a long-standing pursuit in the AI community. This work is part of a broader research effort to develop intelligent agents that can interactively guide humans through performing tasks in the physical world. As a first step in this direction, we introduce HoloAssist, a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. The task performer executes the task while wearing a mixed-reality headset that captures seven synchronized data streams. The task instructor watches the performer's egocentric video in real time and guides them verbally. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. HoloAssist spans 166 hours of data captured by 350 unique instructor-performer pairs. Furthermore, we construct and present benchmarks on mistake detection, intervention type prediction, and hand forecasting, along with detailed analysis. We expect HoloAssist will provide an important resource for building AI assistants that can fluidly collaborate with humans in the real world. Data can be downloaded at https://holoassist.github.io/.
CaSAR: Contact-aware Skeletal Action Recognition
Sep 17, 2023



Skeletal Action recognition from an egocentric view is important for applications such as interfaces in AR/VR glasses and human-robot interaction, where the device has limited resources. Most of the existing skeletal action recognition approaches use 3D coordinates of hand joints and 8-corner rectangular bounding boxes of objects as inputs, but they do not capture how the hands and objects interact with each other within the spatial context. In this paper, we present a new framework called Contact-aware Skeletal Action Recognition (CaSAR). It uses novel representations of hand-object interaction that encompass spatial information: 1) contact points where the hand joints meet the objects, 2) distant points where the hand joints are far away from the object and nearly not involved in the current action. Our framework is able to learn how the hands touch or stay away from the objects for each frame of the action sequence, and use this information to predict the action class. We demonstrate that our approach achieves the state-of-the-art accuracy of 91.3% and 98.4% on two public datasets, H2O and FPHA, respectively.
MCTS with Refinement for Proposals Selection Games in Scene Understanding
Jul 07, 2022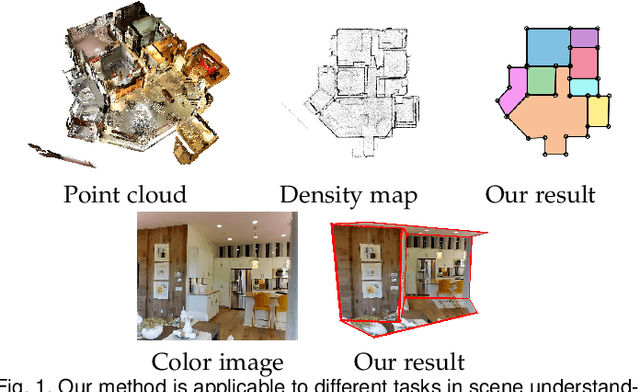
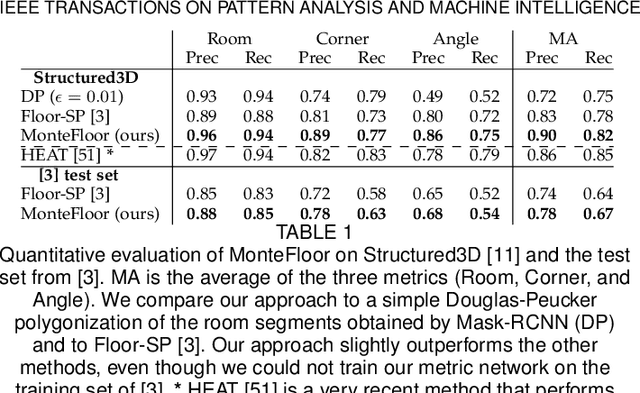
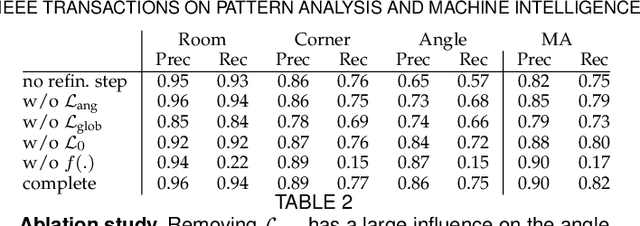
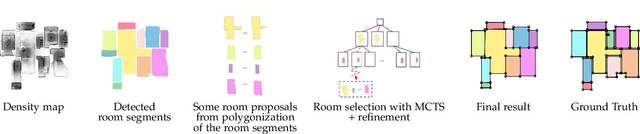
We propose a novel method applicable in many scene understanding problems that adapts the Monte Carlo Tree Search (MCTS) algorithm, originally designed to learn to play games of high-state complexity. From a generated pool of proposals, our method jointly selects and optimizes proposals that minimize the objective term. In our first application for floor plan reconstruction from point clouds, our method selects and refines the room proposals, modelled as 2D polygons, by optimizing on an objective function combining the fitness as predicted by a deep network and regularizing terms on the room shapes. We also introduce a novel differentiable method for rendering the polygonal shapes of these proposals. Our evaluations on the recent and challenging Structured3D and Floor-SP datasets show significant improvements over the state-of-the-art, without imposing hard constraints nor assumptions on the floor plan configurations. In our second application, we extend our approach to reconstruct general 3D room layouts from a color image and obtain accurate room layouts. We also show that our differentiable renderer can easily be extended for rendering 3D planar polygons and polygon embeddings. Our method shows high performance on the Matterport3D-Layout dataset, without introducing hard constraints on room layout configurations.