 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion
Dec 12, 2022
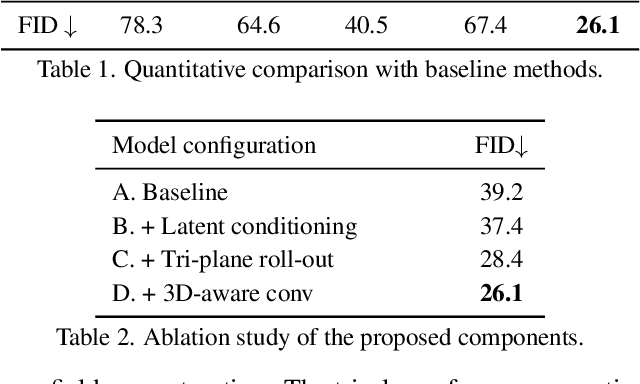
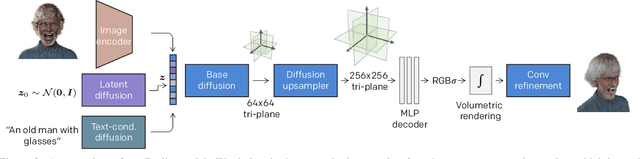
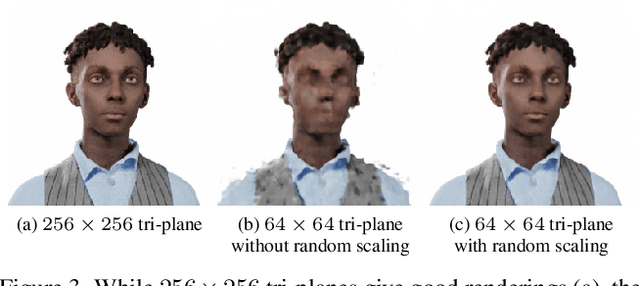
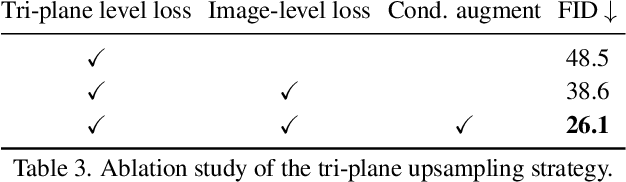
This paper presents a 3D generative model that uses diffusion models to automatically generate 3D digital avatars represented as neural radiance fields. A significant challenge in generating such avatars is that the memory and processing costs in 3D are prohibitive for producing the rich details required for high-quality avatars. To tackle this problem we propose the roll-out diffusion network (Rodin), which represents a neural radiance field as multiple 2D feature maps and rolls out these maps into a single 2D feature plane within which we perform 3D-aware diffusion. The Rodin model brings the much-needed computational efficiency while preserving the integrity of diffusion in 3D by using 3D-aware convolution that attends to projected features in the 2D feature plane according to their original relationship in 3D. We also use latent conditioning to orchestrate the feature generation for global coherence, leading to high-fidelity avatars and enabling their semantic editing based on text prompts. Finally, we use hierarchical synthesis to further enhance details. The 3D avatars generated by our model compare favorably with those produced by existing generative techniques. We can generate highly detailed avatars with realistic hairstyles and facial hair like beards. We also demonstrate 3D avatar generation from image or text as well as text-guided editability.
An adaptive human-in-the-loop approach to emission detection of Additive Manufacturing processes and active learning with computer vision
Dec 12, 2022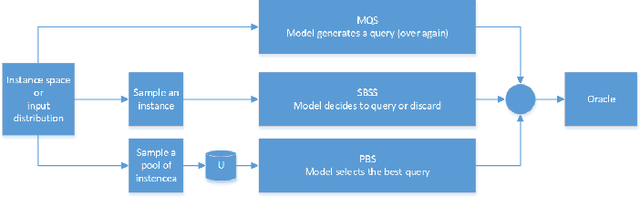
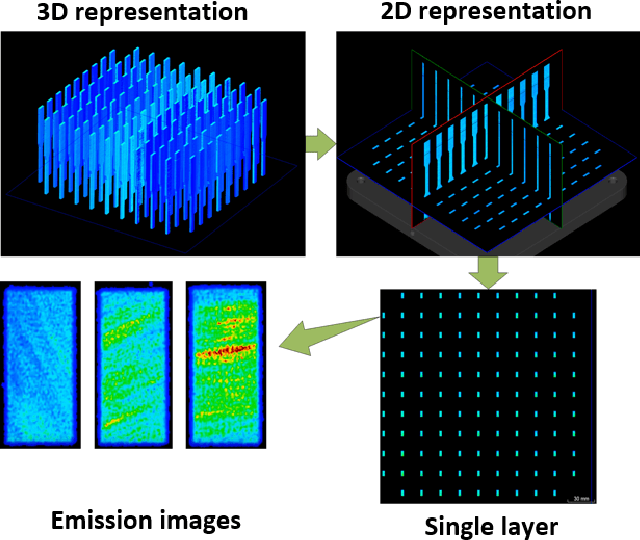
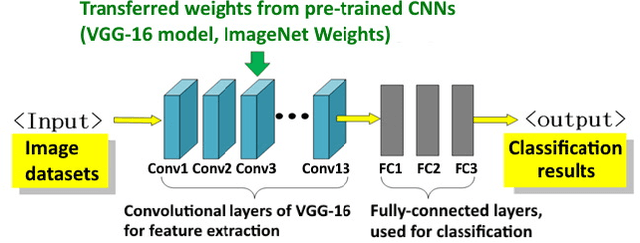
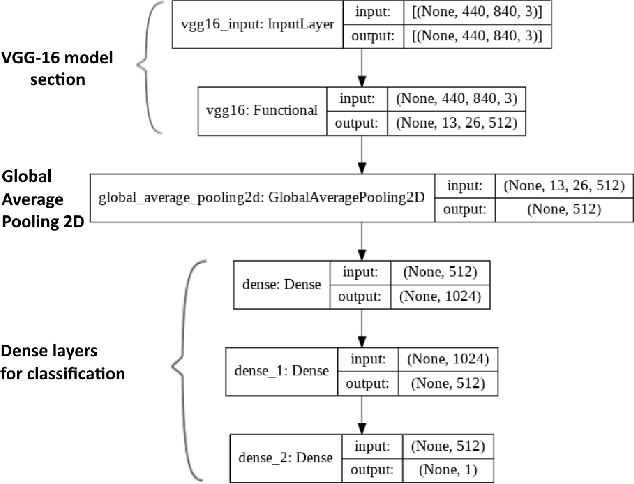
Recent developments in in-situ monitoring and process control in Additive Manufacturing (AM), also known as 3D-printing, allows the collection of large amounts of emission data during the build process of the parts being manufactured. This data can be used as input into 3D and 2D representations of the 3D-printed parts. However the analysis and use, as well as the characterization of this data still remains a manual process. The aim of this paper is to propose an adaptive human-in-the-loop approach using Machine Learning techniques that automatically inspect and annotate the emissions data generated during the AM process. More specifically, this paper will look at two scenarios: firstly, using convolutional neural networks (CNNs) to automatically inspect and classify emission data collected by in-situ monitoring and secondly, applying Active Learning techniques to the developed classification model to construct a human-in-the-loop mechanism in order to accelerate the labeling process of the emission data. The CNN-based approach relies on transfer learning and fine-tuning, which makes the approach applicable to other industrial image patterns. The adaptive nature of the approach is enabled by uncertainty sampling strategy to automatic selection of samples to be presented to human experts for annotation.
Land Use Prediction using Electro-Optical to SAR Few-Shot Transfer Learning
Dec 04, 2022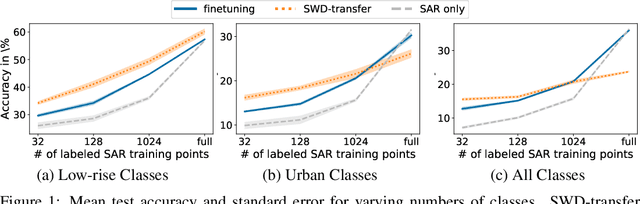
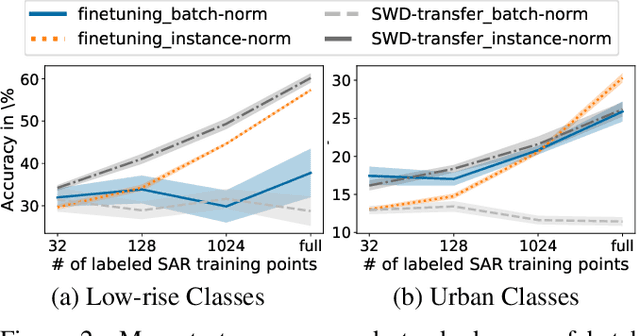
Satellite image analysis has important implications for land use, urbanization, and ecosystem monitoring. Deep learning methods can facilitate the analysis of different satellite modalities, such as electro-optical (EO) and synthetic aperture radar (SAR) imagery, by supporting knowledge transfer between the modalities to compensate for individual shortcomings. Recent progress has shown how distributional alignment of neural network embeddings can produce powerful transfer learning models by employing a sliced Wasserstein distance (SWD) loss. We analyze how this method can be applied to Sentinel-1 and -2 satellite imagery and develop several extensions toward making it effective in practice. In an application to few-shot Local Climate Zone (LCZ) prediction, we show that these networks outperform multiple common baselines on datasets with a large number of classes. Further, we provide evidence that instance normalization can significantly stabilize the training process and that explicitly shaping the embedding space using supervised contrastive learning can lead to improved performance.
Cross-view Geo-localization via Learning Disentangled Geometric Layout Correspondence
Dec 20, 2022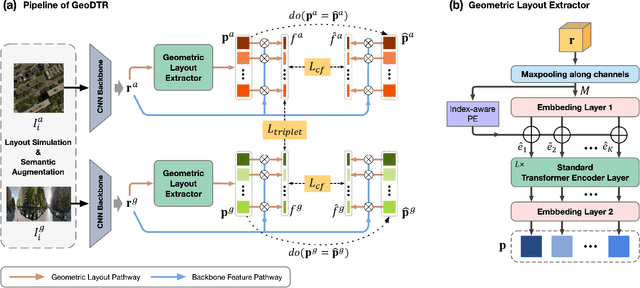
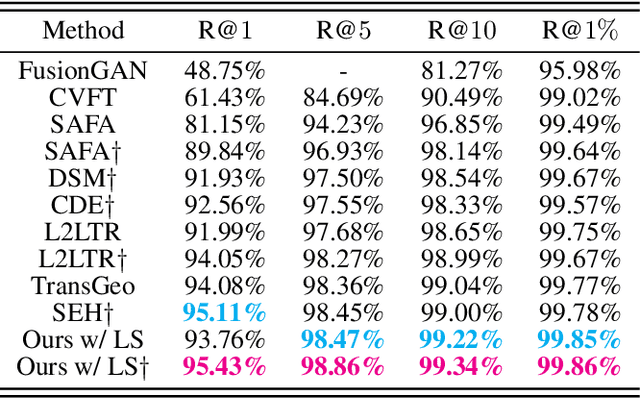

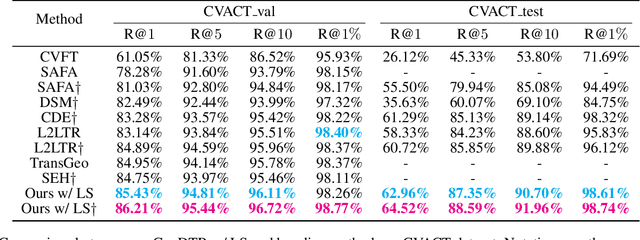
Cross-view geo-localization aims to estimate the location of a query ground image by matching it to a reference geo-tagged aerial images database. As an extremely challenging task, its difficulties root in the drastic view changes and different capturing time between two views. Despite these difficulties, recent works achieve outstanding progress on cross-view geo-localization benchmarks. However, existing methods still suffer from poor performance on the cross-area benchmarks, in which the training and testing data are captured from two different regions. We attribute this deficiency to the lack of ability to extract the spatial configuration of visual feature layouts and models' overfitting on low-level details from the training set. In this paper, we propose GeoDTR which explicitly disentangles geometric information from raw features and learns the spatial correlations among visual features from aerial and ground pairs with a novel geometric layout extractor module. This module generates a set of geometric layout descriptors, modulating the raw features and producing high-quality latent representations. In addition, we elaborate on two categories of data augmentations, (i) Layout simulation, which varies the spatial configuration while keeping the low-level details intact. (ii) Semantic augmentation, which alters the low-level details and encourages the model to capture spatial configurations. These augmentations help to improve the performance of the cross-view geo-localization models, especially on the cross-area benchmarks. Moreover, we propose a counterfactual-based learning process to benefit the geometric layout extractor in exploring spatial information. Extensive experiments show that GeoDTR not only achieves state-of-the-art results but also significantly boosts the performance on same-area and cross-area benchmarks.
Dataset-free Deep learning Method for Low-Dose CT Image Reconstruction
May 01, 2022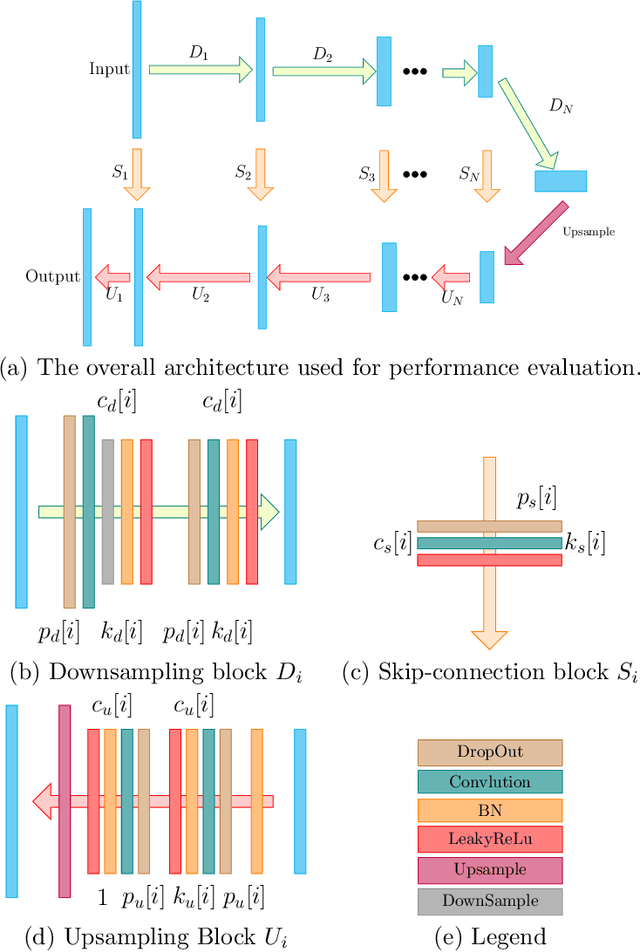

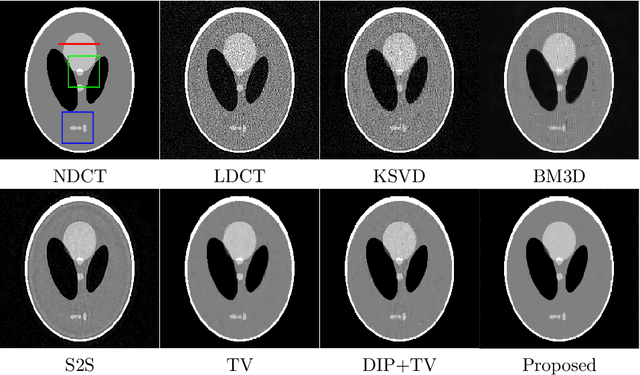
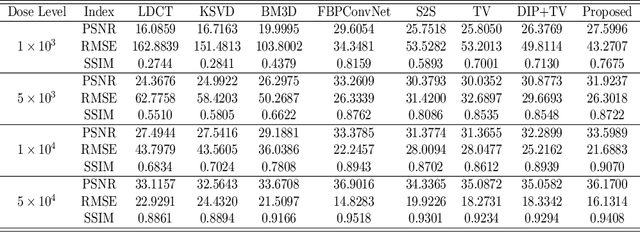
Low-dose CT (LDCT) imaging attracted a considerable interest for the reduction of the object's exposure to X-ray radiation. In recent years, supervised deep learning has been extensively studied for LDCT image reconstruction, which trains a network over a dataset containing many pairs of normal-dose and low-dose images. However, the challenge on collecting many such pairs in the clinical setup limits the application of such supervised-learning-based methods for LDCT image reconstruction in practice. Aiming at addressing the challenges raised by the collection of training dataset, this paper proposed a unsupervised deep learning method for LDCT image reconstruction, which does not require any external training data. The proposed method is built on a re-parametrization technique for Bayesian inference via deep network with random weights, combined with additional total variational (TV) regularization. The experiments show that the proposed method noticeably outperforms existing dataset-free image reconstruction methods on the test data.
I saw, I conceived, I concluded: Progressive Concepts as Bottlenecks
Nov 19, 2022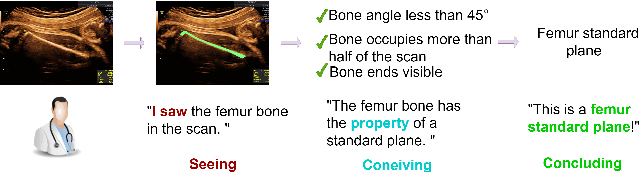
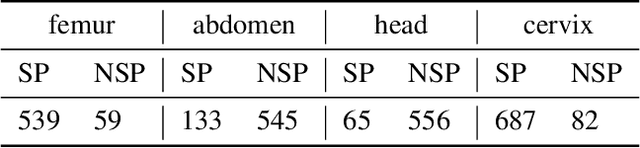
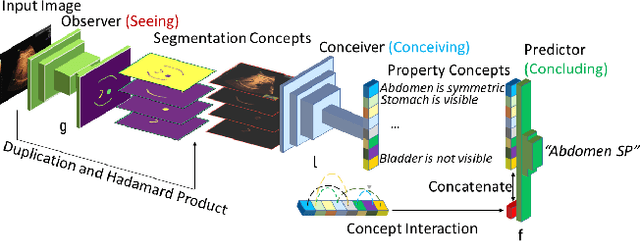
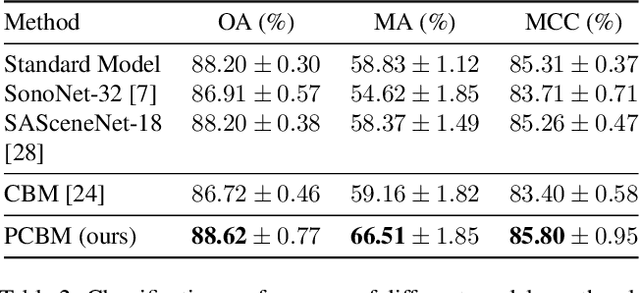
Concept bottleneck models (CBMs) include a bottleneck of human-interpretable concepts providing explainability and intervention during inference by correcting the predicted, intermediate concepts. This makes CBMs attractive for high-stakes decision-making. In this paper, we take the quality assessment of fetal ultrasound scans as a real-life use case for CBM decision support in healthcare. For this case, simple binary concepts are not sufficiently reliable, as they are mapped directly from images of highly variable quality, for which variable model calibration might lead to unstable binarized concepts. Moreover, scalar concepts do not provide the intuitive spatial feedback requested by users. To address this, we design a hierarchical CBM imitating the sequential expert decision-making process of "seeing", "conceiving" and "concluding". Our model first passes through a layer of visual, segmentation-based concepts, and next a second layer of property concepts directly associated with the decision-making task. We note that experts can intervene on both the visual and property concepts during inference. Additionally, we increase the bottleneck capacity by considering task-relevant concept interaction. Our application of ultrasound scan quality assessment is challenging, as it relies on balancing the (often poor) image quality against an assessment of the visibility and geometric properties of standardized image content. Our validation shows that -- in contrast with previous CBM models -- our CBM models actually outperform equivalent concept-free models in terms of predictive performance. Moreover, we illustrate how interventions can further improve our performance over the state-of-the-art.
Touch and Go: Learning from Human-Collected Vision and Touch
Nov 29, 2022

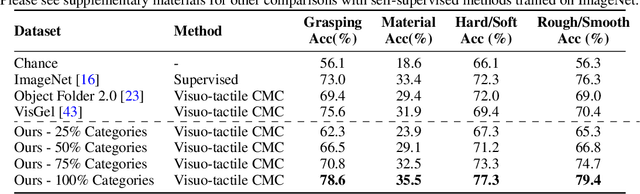

The ability to associate touch with sight is essential for tasks that require physically interacting with objects in the world. We propose a dataset with paired visual and tactile data called Touch and Go, in which human data collectors probe objects in natural environments using tactile sensors, while simultaneously recording egocentric video. In contrast to previous efforts, which have largely been confined to lab settings or simulated environments, our dataset spans a large number of "in the wild" objects and scenes. To demonstrate our dataset's effectiveness, we successfully apply it to a variety of tasks: 1) self-supervised visuo-tactile feature learning, 2) tactile-driven image stylization, i.e., making the visual appearance of an object more consistent with a given tactile signal, and 3) predicting future frames of a tactile signal from visuo-tactile inputs.
Mind the Gap: Scanner-induced domain shifts pose challenges for representation learning in histopathology
Nov 29, 2022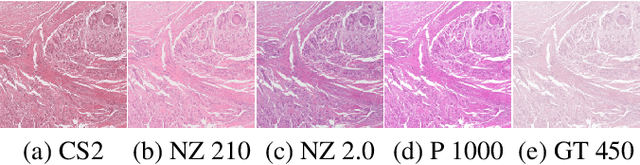
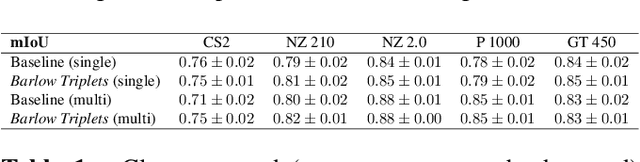
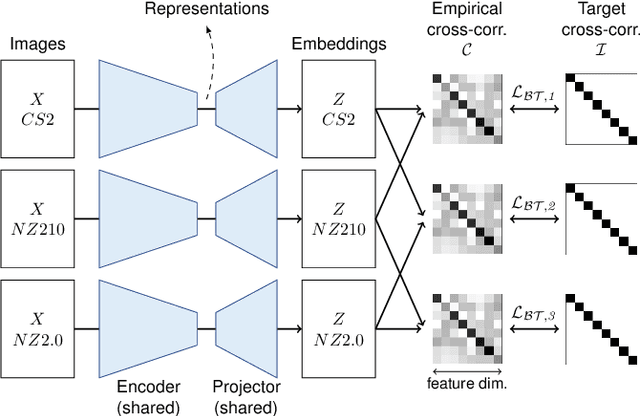
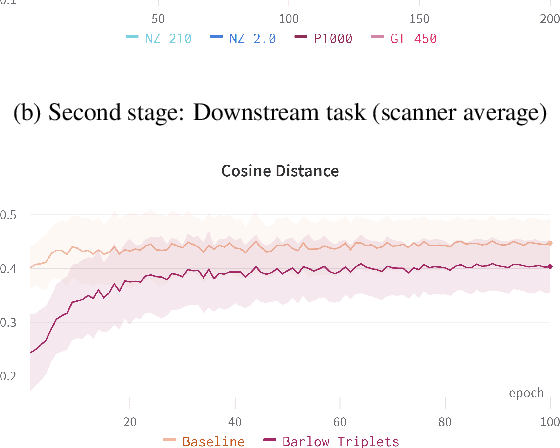
Computer-aided systems in histopathology are often challenged by various sources of domain shift that impact the performance of these algorithms considerably. We investigated the potential of using self-supervised pre-training to overcome scanner-induced domain shifts for the downstream task of tumor segmentation. For this, we present the Barlow Triplets to learn scanner-invariant representations from a multi-scanner dataset with local image correspondences. We show that self-supervised pre-training successfully aligned different scanner representations, which, interestingly only results in a limited benefit for our downstream task. We thereby provide insights into the influence of scanner characteristics for downstream applications and contribute to a better understanding of why established self-supervised methods have not yet shown the same success on histopathology data as they have for natural images.
Localizing Objects in 3D from Egocentric Videos with Visual Queries
Dec 14, 2022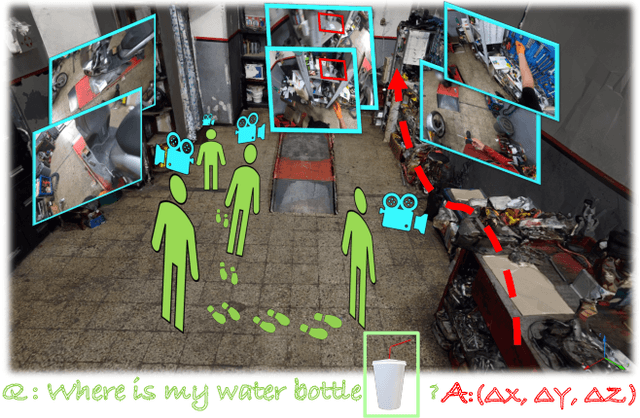

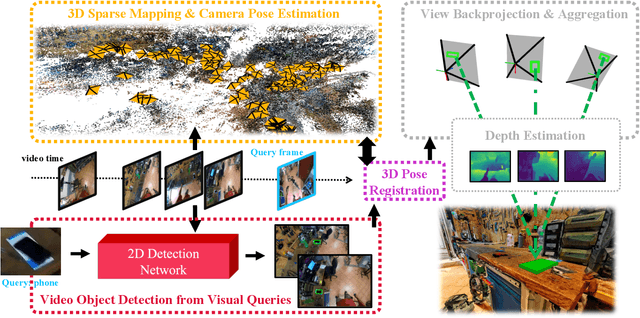
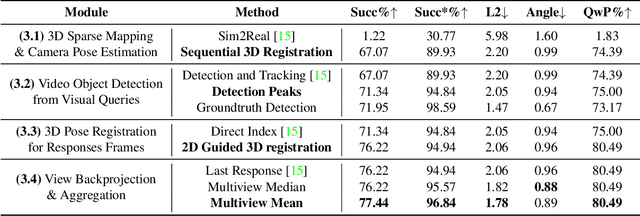
With the recent advances in video and 3D understanding, novel 4D spatio-temporal challenges fusing both concepts have emerged. Towards this direction, the Ego4D Episodic Memory Benchmark proposed a task for Visual Queries with 3D Localization (VQ3D). Given an egocentric video clip and an image crop depicting a query object, the goal is to localize the 3D position of the center of that query object with respect to the camera pose of a query frame. Current methods tackle the problem of VQ3D by lifting the 2D localization results of the sister task Visual Queries with 2D Localization (VQ2D) into a 3D reconstruction. Yet, we point out that the low number of Queries with Poses (QwP) from previous VQ3D methods severally hinders their overall success rate and highlights the need for further effort in 3D modeling to tackle the VQ3D task. In this work, we formalize a pipeline that better entangles 3D multiview geometry with 2D object retrieval from egocentric videos. We estimate more robust camera poses, leading to more successful object queries and substantially improved VQ3D performance. In practice, our method reaches a top-1 overall success rate of 86.36% on the Ego4D Episodic Memory Benchmark VQ3D, a 10x improvement over the previous state-of-the-art. In addition, we provide a complete empirical study highlighting the remaining challenges in VQ3D.
Text2Human: Text-Driven Controllable Human Image Generation
May 31, 2022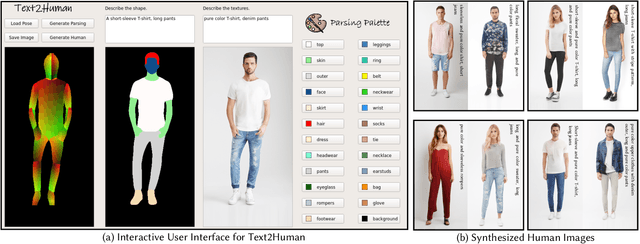
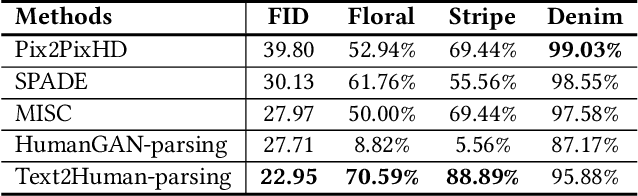
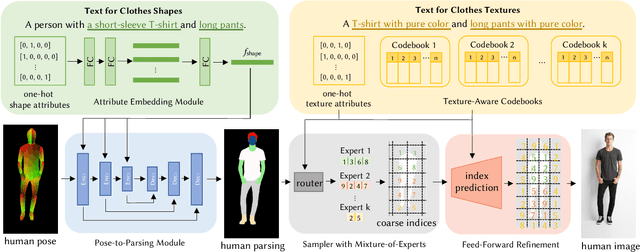
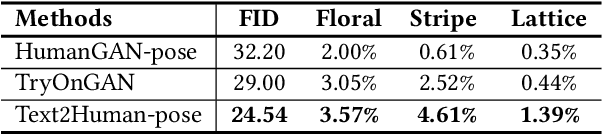
Generating high-quality and diverse human images is an important yet challenging task in vision and graphics. However, existing generative models often fall short under the high diversity of clothing shapes and textures. Furthermore, the generation process is even desired to be intuitively controllable for layman users. In this work, we present a text-driven controllable framework, Text2Human, for a high-quality and diverse human generation. We synthesize full-body human images starting from a given human pose with two dedicated steps. 1) With some texts describing the shapes of clothes, the given human pose is first translated to a human parsing map. 2) The final human image is then generated by providing the system with more attributes about the textures of clothes. Specifically, to model the diversity of clothing textures, we build a hierarchical texture-aware codebook that stores multi-scale neural representations for each type of texture. The codebook at the coarse level includes the structural representations of textures, while the codebook at the fine level focuses on the details of textures. To make use of the learned hierarchical codebook to synthesize desired images, a diffusion-based transformer sampler with mixture of experts is firstly employed to sample indices from the coarsest level of the codebook, which then is used to predict the indices of the codebook at finer levels. The predicted indices at different levels are translated to human images by the decoder learned accompanied with hierarchical codebooks. The use of mixture-of-experts allows for the generated image conditioned on the fine-grained text input. The prediction for finer level indices refines the quality of clothing textures. Extensive quantitative and qualitative evaluations demonstrate that our proposed framework can generate more diverse and realistic human images compared to state-of-the-art methods.