 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Diffusion Captioning for Visual Feature Learning
Oct 30, 2025We learn visual features by captioning images with an image-conditioned masked diffusion language model, a formulation we call masked diffusion captioning (MDC). During training, text tokens in each image-caption pair are masked at a randomly chosen ratio, and a decoder conditioned on visual features is trained to reconstruct the original text. After training, the learned visual features can be applied to downstream vision tasks. Unlike autoregressive captioning, the strength of the visual learning signal in MDC does not depend on each token's position in the sequence, reducing the need for auxiliary objectives. Linear probing experiments across a variety of academic-scale models and datasets show that the learned visual features are competitive with those produced by autoregressive and contrastive approaches.
Hearing Hands: Generating Sounds from Physical Interactions in 3D Scenes
Jun 11, 2025We study the problem of making 3D scene reconstructions interactive by asking the following question: can we predict the sounds of human hands physically interacting with a scene? First, we record a video of a human manipulating objects within a 3D scene using their hands. We then use these action-sound pairs to train a rectified flow model to map 3D hand trajectories to their corresponding audio. At test time, a user can query the model for other actions, parameterized as sequences of hand poses, to estimate their corresponding sounds. In our experiments, we find that our generated sounds accurately convey material properties and actions, and that they are often indistinguishable to human observers from real sounds. Project page: https://www.yimingdou.com/hearing_hands/
GPS as a Control Signal for Image Generation
Jan 21, 2025We show that the GPS tags contained in photo metadata provide a useful control signal for image generation. We train GPS-to-image models and use them for tasks that require a fine-grained understanding of how images vary within a city. In particular, we train a diffusion model to generate images conditioned on both GPS and text. The learned model generates images that capture the distinctive appearance of different neighborhoods, parks, and landmarks. We also extract 3D models from 2D GPS-to-image models through score distillation sampling, using GPS conditioning to constrain the appearance of the reconstruction from each viewpoint. Our evaluations suggest that our GPS-conditioned models successfully learn to generate images that vary based on location, and that GPS conditioning improves estimated 3D structure.
Motion Prompting: Controlling Video Generation with Motion Trajectories
Dec 03, 2024Motion control is crucial for generating expressive and compelling video content; however, most existing video generation models rely mainly on text prompts for control, which struggle to capture the nuances of dynamic actions and temporal compositions. To this end, we train a video generation model conditioned on spatio-temporally sparse or dense motion trajectories. In contrast to prior motion conditioning work, this flexible representation can encode any number of trajectories, object-specific or global scene motion, and temporally sparse motion; due to its flexibility we refer to this conditioning as motion prompts. While users may directly specify sparse trajectories, we also show how to translate high-level user requests into detailed, semi-dense motion prompts, a process we term motion prompt expansion. We demonstrate the versatility of our approach through various applications, including camera and object motion control, "interacting" with an image, motion transfer, and image editing. Our results showcase emergent behaviors, such as realistic physics, suggesting the potential of motion prompts for probing video models and interacting with future generative world models. Finally, we evaluate quantitatively, conduct a human study, and demonstrate strong performance. Video results are available on our webpage: https://motion-prompting.github.io/
Video-Guided Foley Sound Generation with Multimodal Controls
Nov 26, 2024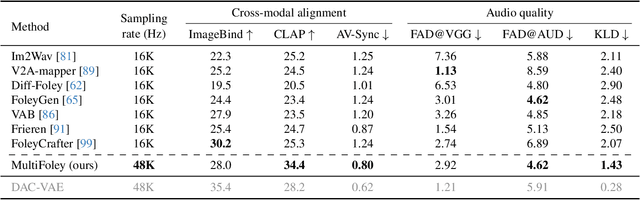
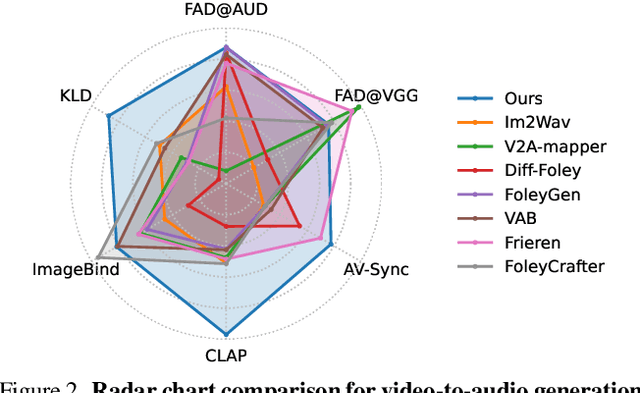
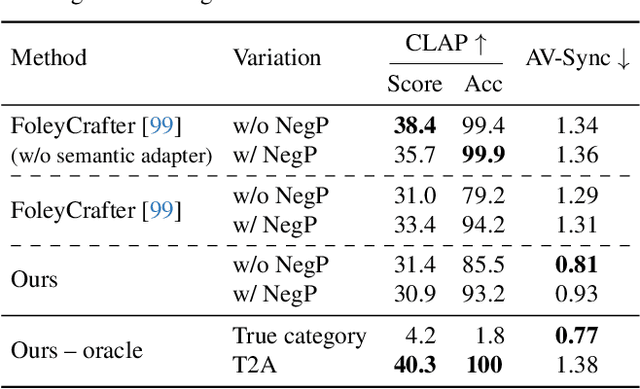
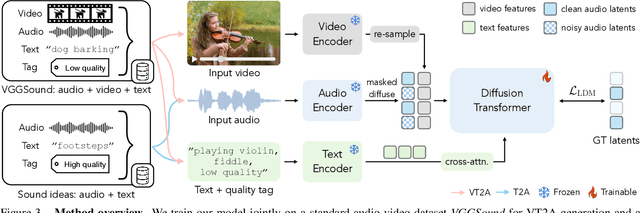
Generating sound effects for videos often requires creating artistic sound effects that diverge significantly from real-life sources and flexible control in the sound design. To address this problem, we introduce MultiFoley, a model designed for video-guided sound generation that supports multimodal conditioning through text, audio, and video. Given a silent video and a text prompt, MultiFoley allows users to create clean sounds (e.g., skateboard wheels spinning without wind noise) or more whimsical sounds (e.g., making a lion's roar sound like a cat's meow). MultiFoley also allows users to choose reference audio from sound effects (SFX) libraries or partial videos for conditioning. A key novelty of our model lies in its joint training on both internet video datasets with low-quality audio and professional SFX recordings, enabling high-quality, full-bandwidth (48kHz) audio generation. Through automated evaluations and human studies, we demonstrate that MultiFoley successfully generates synchronized high-quality sounds across varied conditional inputs and outperforms existing methods. Please see our project page for video results: https://ificl.github.io/MultiFoley/
Community Forensics: Using Thousands of Generators to Train Fake Image Detectors
Nov 06, 2024One of the key challenges of detecting AI-generated images is spotting images that have been created by previously unseen generative models. We argue that the limited diversity of the training data is a major obstacle to addressing this problem, and we propose a new dataset that is significantly larger and more diverse than prior work. As part of creating this dataset, we systematically download thousands of text-to-image latent diffusion models and sample images from them. We also collect images from dozens of popular open source and commercial models. The resulting dataset contains 2.7M images that have been sampled from 4803 different models. These images collectively capture a wide range of scene content, generator architectures, and image processing settings. Using this dataset, we study the generalization abilities of fake image detectors. Our experiments suggest that detection performance improves as the number of models in the training set increases, even when these models have similar architectures. We also find that detection performance improves as the diversity of the models increases, and that our trained detectors generalize better than those trained on other datasets.
Contrastive Touch-to-Touch Pretraining
Oct 15, 2024



Today's tactile sensors have a variety of different designs, making it challenging to develop general-purpose methods for processing touch signals. In this paper, we learn a unified representation that captures the shared information between different tactile sensors. Unlike current approaches that focus on reconstruction or task-specific supervision, we leverage contrastive learning to integrate tactile signals from two different sensors into a shared embedding space, using a dataset in which the same objects are probed with multiple sensors. We apply this approach to paired touch signals from GelSlim and Soft Bubble sensors. We show that our learned features provide strong pretraining for downstream pose estimation and classification tasks. We also show that our embedding enables models trained using one touch sensor to be deployed using another without additional training. Project details can be found at https://www.mmintlab.com/research/cttp/.
Self-Supervised Any-Point Tracking by Contrastive Random Walks
Sep 24, 2024We present a simple, self-supervised approach to the Tracking Any Point (TAP) problem. We train a global matching transformer to find cycle consistent tracks through video via contrastive random walks, using the transformer's attention-based global matching to define the transition matrices for a random walk on a space-time graph. The ability to perform "all pairs" comparisons between points allows the model to obtain high spatial precision and to obtain a strong contrastive learning signal, while avoiding many of the complexities of recent approaches (such as coarse-to-fine matching). To do this, we propose a number of design decisions that allow global matching architectures to be trained through self-supervision using cycle consistency. For example, we identify that transformer-based methods are sensitive to shortcut solutions, and propose a data augmentation scheme to address them. Our method achieves strong performance on the TapVid benchmarks, outperforming previous self-supervised tracking methods, such as DIFT, and is competitive with several supervised methods.
Tactile Functasets: Neural Implicit Representations of Tactile Datasets
Sep 22, 2024



Modern incarnations of tactile sensors produce high-dimensional raw sensory feedback such as images, making it challenging to efficiently store, process, and generalize across sensors. To address these concerns, we introduce a novel implicit function representation for tactile sensor feedback. Rather than directly using raw tactile images, we propose neural implicit functions trained to reconstruct the tactile dataset, producing compact representations that capture the underlying structure of the sensory inputs. These representations offer several advantages over their raw counterparts: they are compact, enable probabilistically interpretable inference, and facilitate generalization across different sensors. We demonstrate the efficacy of this representation on the downstream task of in-hand object pose estimation, achieving improved performance over image-based methods while simplifying downstream models. We release code, demos and datasets at https://www.mmintlab.com/tactile-functasets.
Self-Supervised Audio-Visual Soundscape Stylization
Sep 22, 2024Speech sounds convey a great deal of information about the scenes, resulting in a variety of effects ranging from reverberation to additional ambient sounds. In this paper, we manipulate input speech to sound as though it was recorded within a different scene, given an audio-visual conditional example recorded from that scene. Our model learns through self-supervision, taking advantage of the fact that natural video contains recurring sound events and textures. We extract an audio clip from a video and apply speech enhancement. We then train a latent diffusion model to recover the original speech, using another audio-visual clip taken from elsewhere in the video as a conditional hint. Through this process, the model learns to transfer the conditional example's sound properties to the input speech. We show that our model can be successfully trained using unlabeled, in-the-wild videos, and that an additional visual signal can improve its sound prediction abilities. Please see our project webpage for video results: https://tinglok.netlify.app/files/avsoundscape/