 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Modality-Transferable Video Highlight Detection with Representation Activation Sequence Learning
Mar 18, 2024
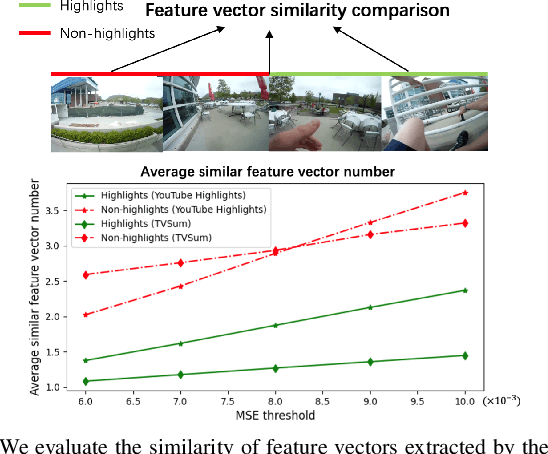
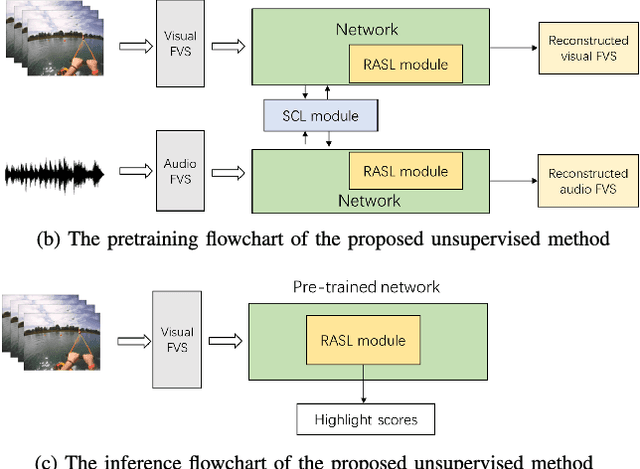
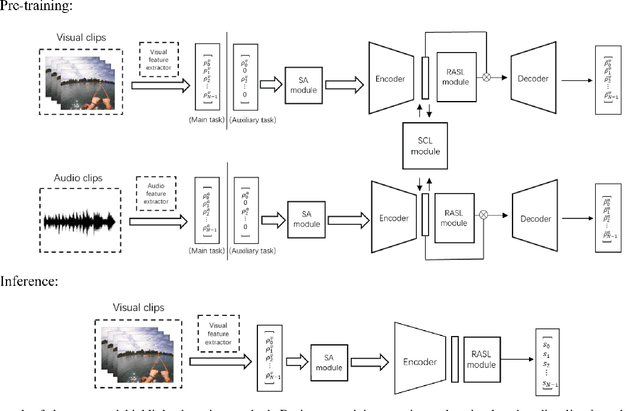
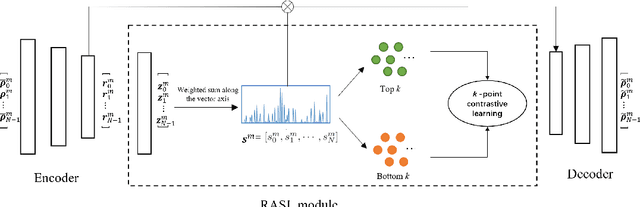
Identifying highlight moments of raw video materials is crucial for improving the efficiency of editing videos that are pervasive on internet platforms. However, the extensive work of manually labeling footage has created obstacles to applying supervised methods to videos of unseen categories. The absence of an audio modality that contains valuable cues for highlight detection in many videos also makes it difficult to use multimodal strategies. In this paper, we propose a novel model with cross-modal perception for unsupervised highlight detection. The proposed model learns representations with visual-audio level semantics from image-audio pair data via a self-reconstruction task. To achieve unsupervised highlight detection, we investigate the latent representations of the network and propose the representation activation sequence learning (RASL) module with k-point contrastive learning to learn significant representation activations. To connect the visual modality with the audio modality, we use the symmetric contrastive learning (SCL) module to learn the paired visual and audio representations. Furthermore, an auxiliary task of masked feature vector sequence (FVS) reconstruction is simultaneously conducted during pretraining for representation enhancement. During inference, the cross-modal pretrained model can generate representations with paired visual-audio semantics given only the visual modality. The RASL module is used to output the highlight scores. The experimental results show that the proposed framework achieves superior performance compared to other state-of-the-art approaches.
SAM-Lightening: A Lightweight Segment Anything Model with Dilated Flash Attention to Achieve 30 times Acceleration
Mar 18, 2024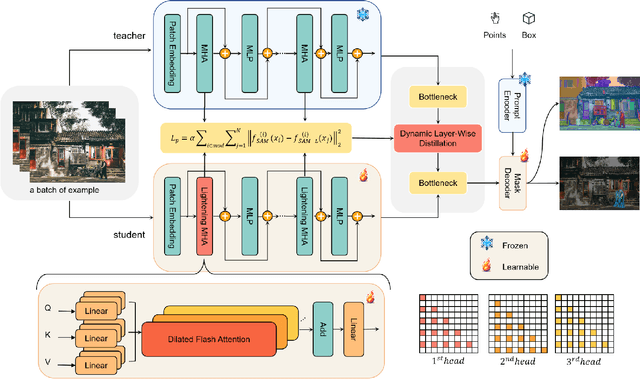
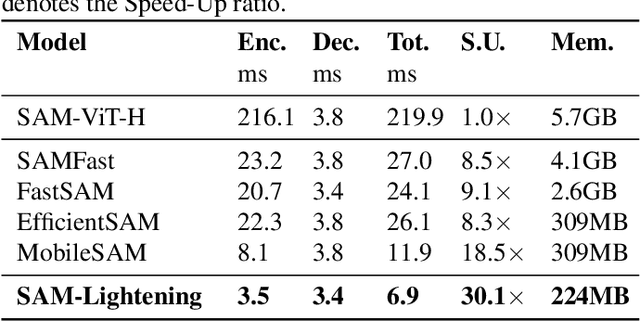

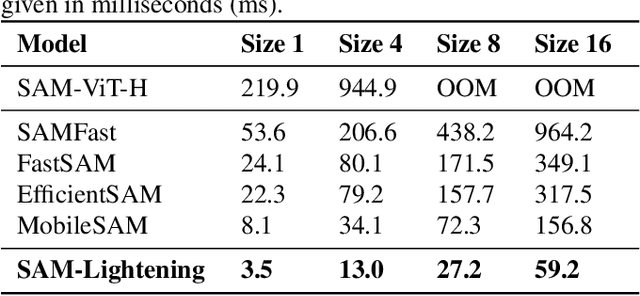
Segment Anything Model (SAM) has garnered significant attention in segmentation tasks due to their zero-shot generalization ability. However, a broader application of SAMs to real-world practice has been restricted by their low inference speed and high computational memory demands, which mainly stem from the attention mechanism. Existing work concentrated on optimizing the encoder, yet has not adequately addressed the inefficiency of the attention mechanism itself, even when distilled to a smaller model, which thus leaves space for further improvement. In response, we introduce SAM-Lightening, a variant of SAM, that features a re-engineered attention mechanism, termed Dilated Flash Attention. It not only facilitates higher parallelism, enhancing processing efficiency but also retains compatibility with the existing FlashAttention. Correspondingly, we propose a progressive distillation to enable an efficient knowledge transfer from the vanilla SAM without costly training from scratch. Experiments on COCO and LVIS reveal that SAM-Lightening significantly outperforms the state-of-the-art methods in both run-time efficiency and segmentation accuracy. Specifically, it can achieve an inference speed of 7 milliseconds (ms) per image, for images of size 1024*1024 pixels, which is 30.1 times faster than the vanilla SAM and 2.1 times than the state-of-the-art. Moreover, it takes only 244MB memory, which is 3.5\% of the vanilla SAM. The code and weights are available at https://anonymous.4open.science/r/SAM-LIGHTENING-BC25/.
When Semantic Segmentation Meets Frequency Aliasing
Mar 18, 2024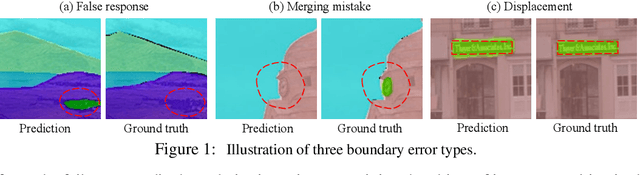
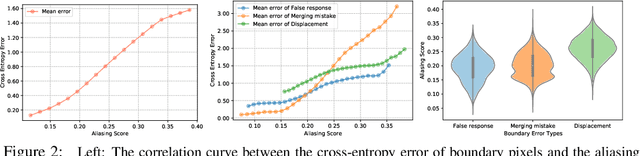

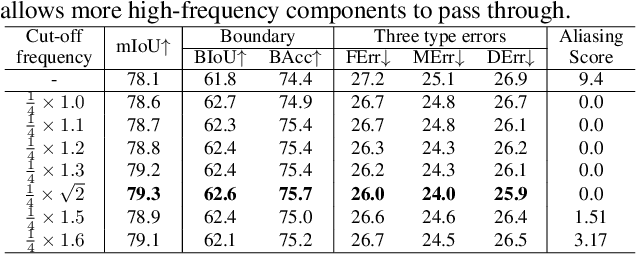
Despite recent advancements in semantic segmentation, where and what pixels are hard to segment remains largely unexplored. Existing research only separates an image into easy and hard regions and empirically observes the latter are associated with object boundaries. In this paper, we conduct a comprehensive analysis of hard pixel errors, categorizing them into three types: false responses, merging mistakes, and displacements. Our findings reveal a quantitative association between hard pixels and aliasing, which is distortion caused by the overlapping of frequency components in the Fourier domain during downsampling. To identify the frequencies responsible for aliasing, we propose using the equivalent sampling rate to calculate the Nyquist frequency, which marks the threshold for aliasing. Then, we introduce the aliasing score as a metric to quantify the extent of aliasing. While positively correlated with the proposed aliasing score, three types of hard pixels exhibit different patterns. Here, we propose two novel de-aliasing filter (DAF) and frequency mixing (FreqMix) modules to alleviate aliasing degradation by accurately removing or adjusting frequencies higher than the Nyquist frequency. The DAF precisely removes the frequencies responsible for aliasing before downsampling, while the FreqMix dynamically selects high-frequency components within the encoder block. Experimental results demonstrate consistent improvements in semantic segmentation and low-light instance segmentation tasks. The code is available at: https://github.com/Linwei-Chen/Seg-Aliasing.
GenView: Enhancing View Quality with Pretrained Generative Model for Self-Supervised Learning
Mar 18, 2024
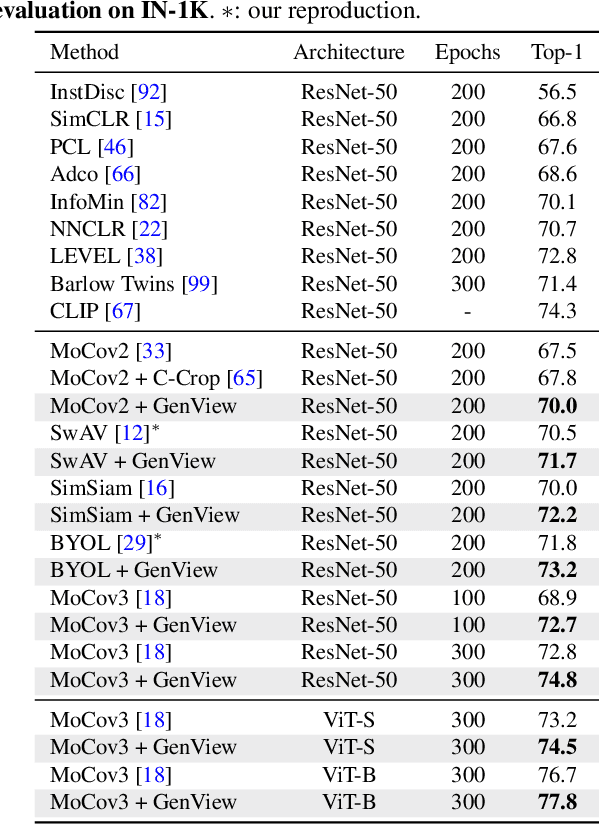
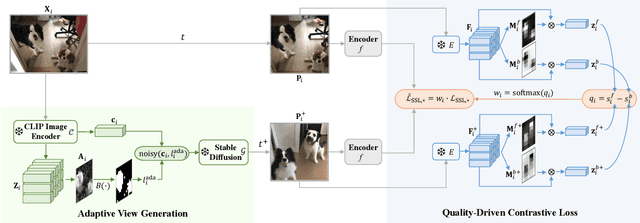
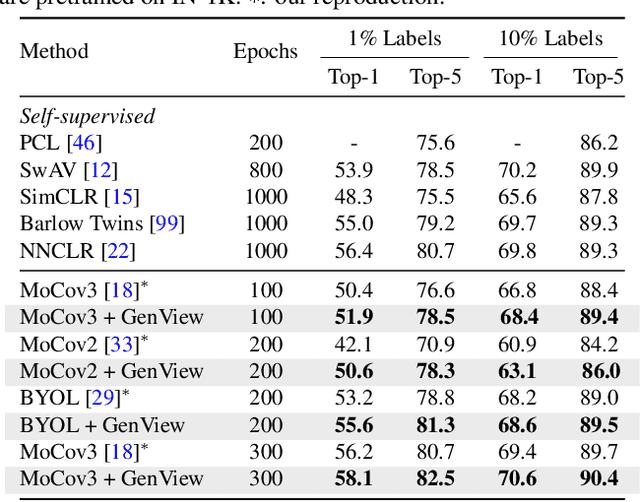
Self-supervised learning has achieved remarkable success in acquiring high-quality representations from unlabeled data. The widely adopted contrastive learning framework aims to learn invariant representations by minimizing the distance between positive views originating from the same image. However, existing techniques to construct positive views highly rely on manual transformations, resulting in limited diversity and potentially false positive pairs. To tackle these challenges, we present GenView, a controllable framework that augments the diversity of positive views leveraging the power of pretrained generative models while preserving semantics. We develop an adaptive view generation method that dynamically adjusts the noise level in sampling to ensure the preservation of essential semantic meaning while introducing variability. Additionally, we introduce a quality-driven contrastive loss, which assesses the quality of positive pairs by considering both foreground similarity and background diversity. This loss prioritizes the high-quality positive pairs we construct while reducing the influence of low-quality pairs, thereby mitigating potential semantic inconsistencies introduced by generative models and aggressive data augmentation. Thanks to the improved positive view quality and the quality-driven contrastive loss, GenView significantly improves self-supervised learning across various tasks. For instance, GenView improves MoCov2 performance by 2.5%/2.2% on ImageNet linear/semi-supervised classification. Moreover, GenView even performs much better than naively augmenting the ImageNet dataset with Laion400M or ImageNet21K. Code is available at https://github.com/xiaojieli0903/genview.
UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Mar 18, 2024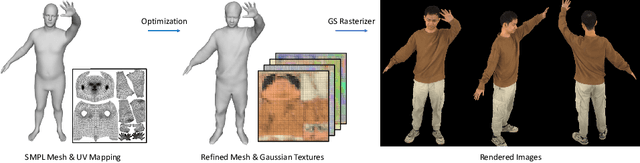

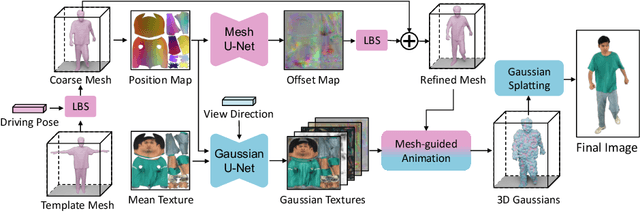

Reconstructing photo-realistic drivable human avatars from multi-view image sequences has been a popular and challenging topic in the field of computer vision and graphics. While existing NeRF-based methods can achieve high-quality novel view rendering of human models, both training and inference processes are time-consuming. Recent approaches have utilized 3D Gaussians to represent the human body, enabling faster training and rendering. However, they undermine the importance of the mesh guidance and directly predict Gaussians in 3D space with coarse mesh guidance. This hinders the learning procedure of the Gaussians and tends to produce blurry textures. Therefore, we propose UV Gaussians, which models the 3D human body by jointly learning mesh deformations and 2D UV-space Gaussian textures. We utilize the embedding of UV map to learn Gaussian textures in 2D space, leveraging the capabilities of powerful 2D networks to extract features. Additionally, through an independent Mesh network, we optimize pose-dependent geometric deformations, thereby guiding Gaussian rendering and significantly enhancing rendering quality. We collect and process a new dataset of human motion, which includes multi-view images, scanned models, parametric model registration, and corresponding texture maps. Experimental results demonstrate that our method achieves state-of-the-art synthesis of novel view and novel pose. The code and data will be made available on the homepage https://alex-jyj.github.io/UV-Gaussians/ once the paper is accepted.
Arc2Face: A Foundation Model of Human Faces
Mar 18, 2024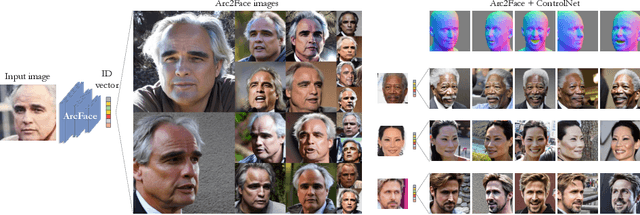
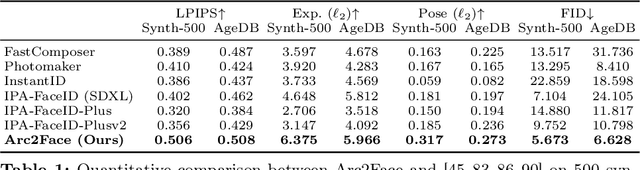
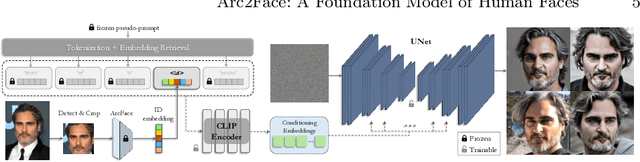
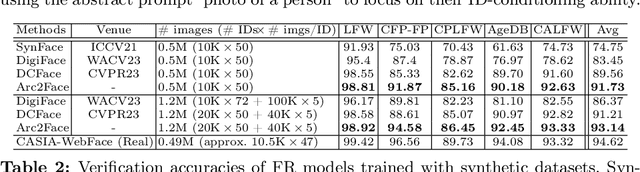
This paper presents Arc2Face, an identity-conditioned face foundation model, which, given the ArcFace embedding of a person, can generate diverse photo-realistic images with an unparalleled degree of face similarity than existing models. Despite previous attempts to decode face recognition features into detailed images, we find that common high-resolution datasets (e.g. FFHQ) lack sufficient identities to reconstruct any subject. To that end, we meticulously upsample a significant portion of the WebFace42M database, the largest public dataset for face recognition (FR). Arc2Face builds upon a pretrained Stable Diffusion model, yet adapts it to the task of ID-to-face generation, conditioned solely on ID vectors. Deviating from recent works that combine ID with text embeddings for zero-shot personalization of text-to-image models, we emphasize on the compactness of FR features, which can fully capture the essence of the human face, as opposed to hand-crafted prompts. Crucially, text-augmented models struggle to decouple identity and text, usually necessitating some description of the given face to achieve satisfactory similarity. Arc2Face, however, only needs the discriminative features of ArcFace to guide the generation, offering a robust prior for a plethora of tasks where ID consistency is of paramount importance. As an example, we train a FR model on synthetic images from our model and achieve superior performance to existing synthetic datasets.
Agent3D-Zero: An Agent for Zero-shot 3D Understanding
Mar 18, 2024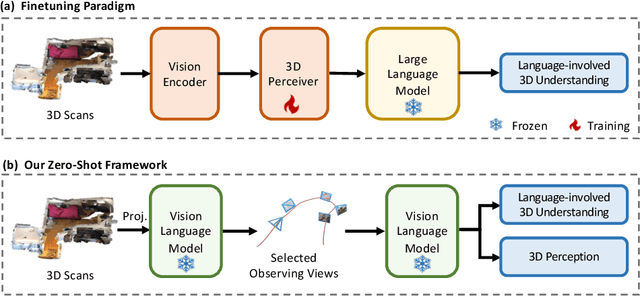
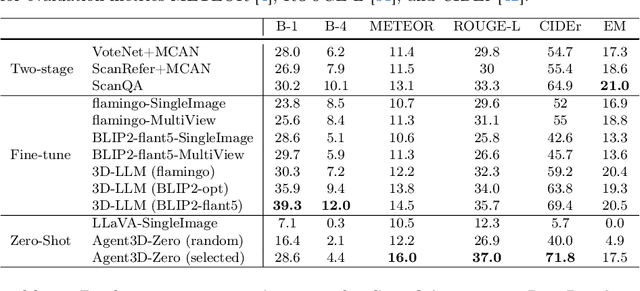
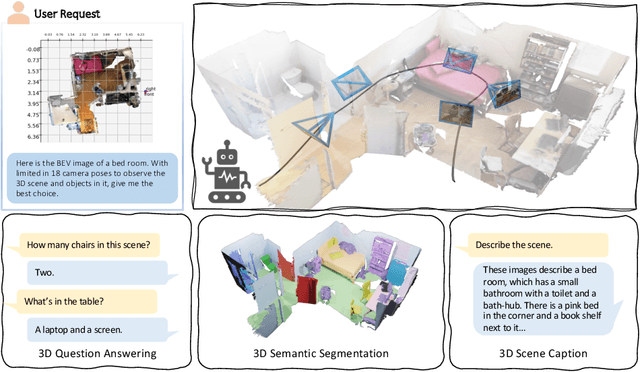
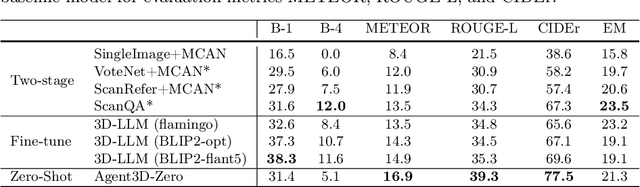
The ability to understand and reason the 3D real world is a crucial milestone towards artificial general intelligence. The current common practice is to finetune Large Language Models (LLMs) with 3D data and texts to enable 3D understanding. Despite their effectiveness, these approaches are inherently limited by the scale and diversity of the available 3D data. Alternatively, in this work, we introduce Agent3D-Zero, an innovative 3D-aware agent framework addressing the 3D scene understanding in a zero-shot manner. The essence of our approach centers on reconceptualizing the challenge of 3D scene perception as a process of understanding and synthesizing insights from multiple images, inspired by how our human beings attempt to understand 3D scenes. By consolidating this idea, we propose a novel way to make use of a Large Visual Language Model (VLM) via actively selecting and analyzing a series of viewpoints for 3D understanding. Specifically, given an input 3D scene, Agent3D-Zero first processes a bird's-eye view image with custom-designed visual prompts, then iteratively chooses the next viewpoints to observe and summarize the underlying knowledge. A distinctive advantage of Agent3D-Zero is the introduction of novel visual prompts, which significantly unleash the VLMs' ability to identify the most informative viewpoints and thus facilitate observing 3D scenes. Extensive experiments demonstrate the effectiveness of the proposed framework in understanding diverse and previously unseen 3D environments.
Polos: Multimodal Metric Learning from Human Feedback for Image Captioning
Feb 28, 2024Establishing an automatic evaluation metric that closely aligns with human judgments is essential for effectively developing image captioning models. Recent data-driven metrics have demonstrated a stronger correlation with human judgments than classic metrics such as CIDEr; however they lack sufficient capabilities to handle hallucinations and generalize across diverse images and texts partially because they compute scalar similarities merely using embeddings learned from tasks unrelated to image captioning evaluation. In this study, we propose Polos, a supervised automatic evaluation metric for image captioning models. Polos computes scores from multimodal inputs, using a parallel feature extraction mechanism that leverages embeddings trained through large-scale contrastive learning. To train Polos, we introduce Multimodal Metric Learning from Human Feedback (M$^2$LHF), a framework for developing metrics based on human feedback. We constructed the Polaris dataset, which comprises 131K human judgments from 550 evaluators, which is approximately ten times larger than standard datasets. Our approach achieved state-of-the-art performance on Composite, Flickr8K-Expert, Flickr8K-CF, PASCAL-50S, FOIL, and the Polaris dataset, thereby demonstrating its effectiveness and robustness.
Quantifying the Resolution of a Template after Image Registration
Feb 27, 2024In many image processing applications (e.g. computational anatomy) a groupwise registration is performed on a sample of images and a template image is simultaneously generated. From the template alone it is in general unclear to which extent the registered images are still misaligned, which means that some regions of the template represent the structural features in the sample images less reliably than others. In a sense, the template exhibits a lower resolution there. Guided by characteristic examples of misaligned image features in one dimension, we develop a visual measure to quantify the resolution at each location of a template which is based on the observation that misalignments between the registered sample images are reduced by smoothing with the strength of the smoothing being related to the magnitude of the misalignment. Finally the resulting resolution measure is applied to example datasets in two and three dimensions. The corresponding code is publicly available on GitHub.
Perspective-Equivariant Imaging: an Unsupervised Framework for Multispectral Pansharpening
Mar 14, 2024

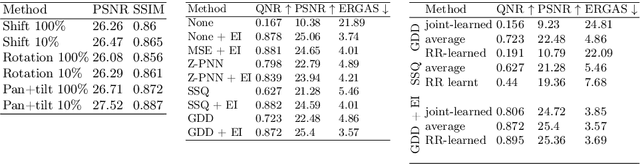
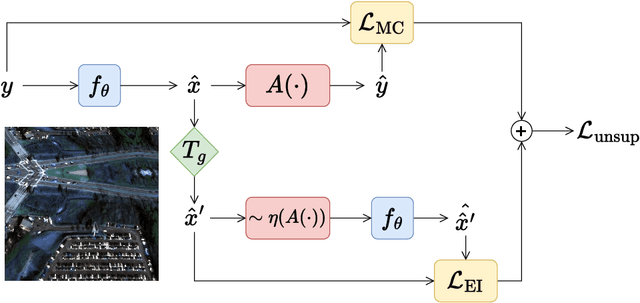
Ill-posed image reconstruction problems appear in many scenarios such as remote sensing, where obtaining high quality images is crucial for environmental monitoring, disaster management and urban planning. Deep learning has seen great success in overcoming the limitations of traditional methods. However, these inverse problems rarely come with ground truth data, highlighting the importance of unsupervised learning from partial and noisy measurements alone. We propose perspective-equivariant imaging (EI), a framework that leverages perspective variability in optical camera-based imaging systems, such as satellites or handheld cameras, to recover information lost in ill-posed optical camera imaging problems. This extends previous EI work to include a much richer non-linear class of group transforms and is shown to be an excellent prior for satellite and urban image data, where perspective-EI achieves state-of-the-art results in multispectral pansharpening, outperforming other unsupervised methods in the literature. Code at https://andrewwango.github.io/perspective-equivariant-imaging