 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TAPS3D: Text-Guided 3D Textured Shape Generation from Pseudo Supervision
Mar 23, 2023

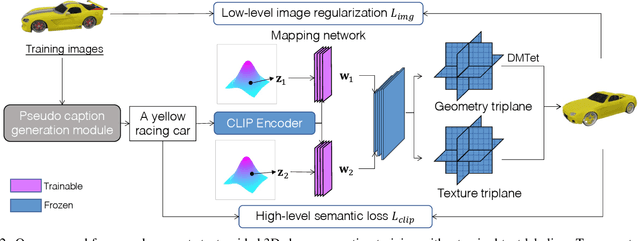
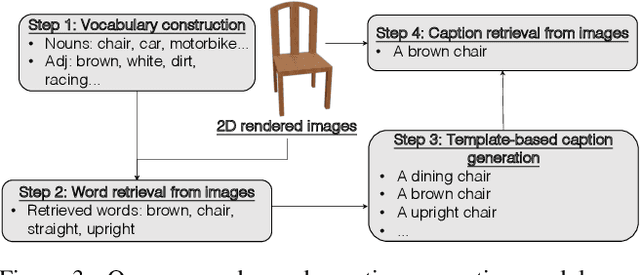
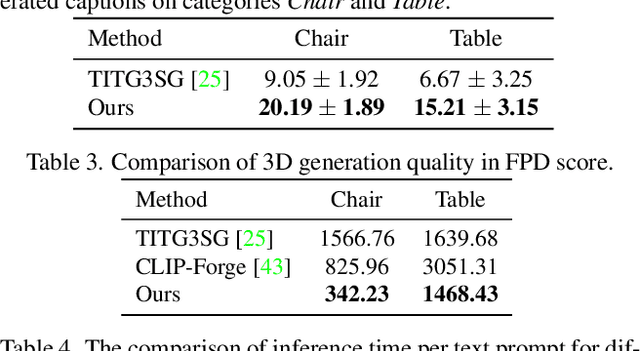
In this paper, we investigate an open research task of generating controllable 3D textured shapes from the given textual descriptions. Previous works either require ground truth caption labeling or extensive optimization time. To resolve these issues, we present a novel framework, TAPS3D, to train a text-guided 3D shape generator with pseudo captions. Specifically, based on rendered 2D images, we retrieve relevant words from the CLIP vocabulary and construct pseudo captions using templates. Our constructed captions provide high-level semantic supervision for generated 3D shapes. Further, in order to produce fine-grained textures and increase geometry diversity, we propose to adopt low-level image regularization to enable fake-rendered images to align with the real ones. During the inference phase, our proposed model can generate 3D textured shapes from the given text without any additional optimization. We conduct extensive experiments to analyze each of our proposed components and show the efficacy of our framework in generating high-fidelity 3D textured and text-relevant shapes.
Complementary Pseudo Multimodal Feature for Point Cloud Anomaly Detection
Mar 23, 2023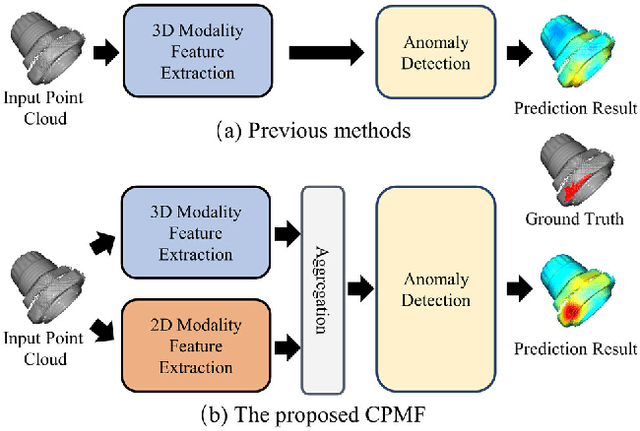
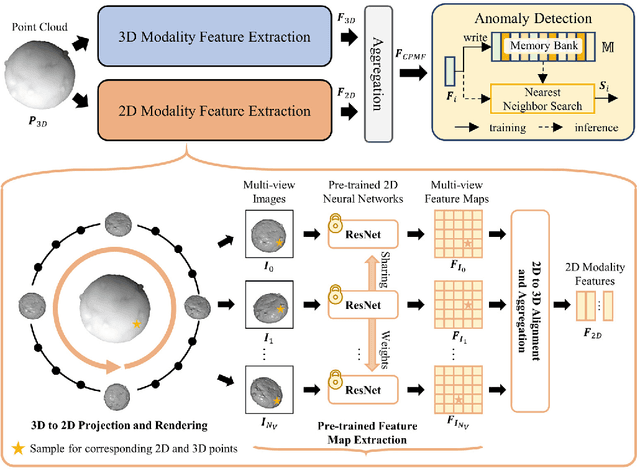
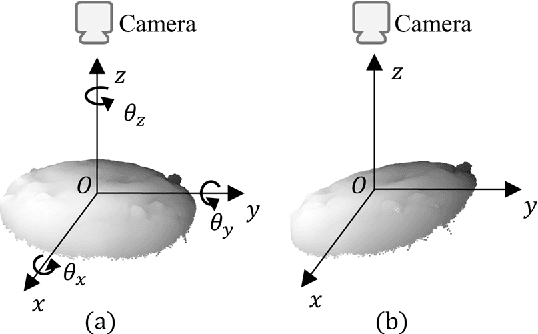

Point cloud (PCD) anomaly detection steadily emerges as a promising research area. This study aims to improve PCD anomaly detection performance by combining handcrafted PCD descriptions with powerful pre-trained 2D neural networks. To this end, this study proposes Complementary Pseudo Multimodal Feature (CPMF) that incorporates local geometrical information in 3D modality using handcrafted PCD descriptors and global semantic information in the generated pseudo 2D modality using pre-trained 2D neural networks. For global semantics extraction, CPMF projects the origin PCD into a pseudo 2D modality containing multi-view images. These images are delivered to pre-trained 2D neural networks for informative 2D modality feature extraction. The 3D and 2D modality features are aggregated to obtain the CPMF for PCD anomaly detection. Extensive experiments demonstrate the complementary capacity between 2D and 3D modality features and the effectiveness of CPMF, with 95.15% image-level AU-ROC and 92.93% pixel-level PRO on the MVTec3D benchmark. Code is available on https://github.com/caoyunkang/CPMF.
Viewpoint Equivariance for Multi-View 3D Object Detection
Mar 25, 2023
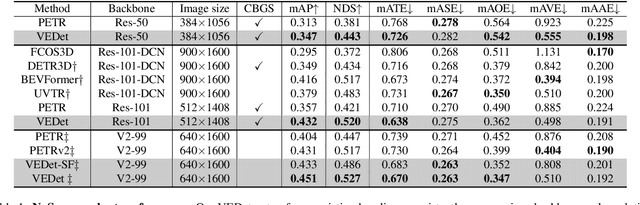
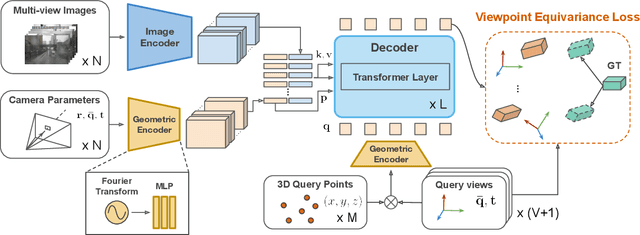
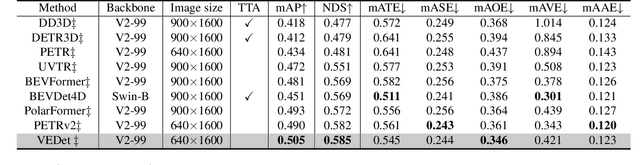
3D object detection from visual sensors is a cornerstone capability of robotic systems. State-of-the-art methods focus on reasoning and decoding object bounding boxes from multi-view camera input. In this work we gain intuition from the integral role of multi-view consistency in 3D scene understanding and geometric learning. To this end, we introduce VEDet, a novel 3D object detection framework that exploits 3D multi-view geometry to improve localization through viewpoint awareness and equivariance. VEDet leverages a query-based transformer architecture and encodes the 3D scene by augmenting image features with positional encodings from their 3D perspective geometry. We design view-conditioned queries at the output level, which enables the generation of multiple virtual frames during training to learn viewpoint equivariance by enforcing multi-view consistency. The multi-view geometry injected at the input level as positional encodings and regularized at the loss level provides rich geometric cues for 3D object detection, leading to state-of-the-art performance on the nuScenes benchmark. The code and model are made available at https://github.com/TRI-ML/VEDet.
DBARF: Deep Bundle-Adjusting Generalizable Neural Radiance Fields
Mar 25, 2023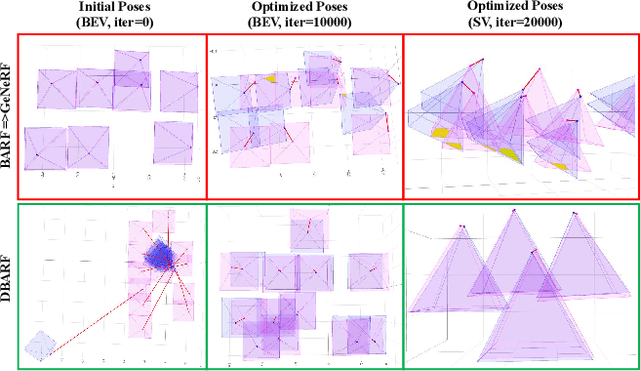
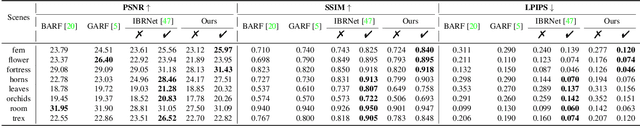
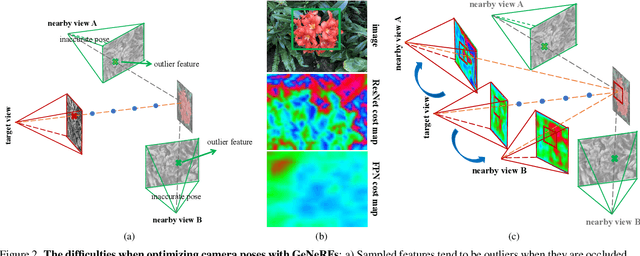
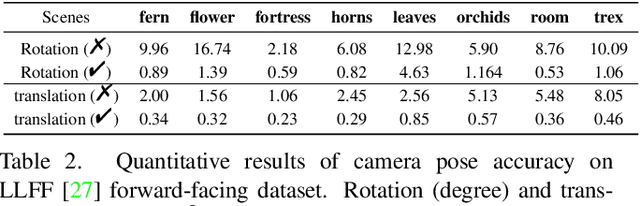
Recent works such as BARF and GARF can bundle adjust camera poses with neural radiance fields (NeRF) which is based on coordinate-MLPs. Despite the impressive results, these methods cannot be applied to Generalizable NeRFs (GeNeRFs) which require image feature extractions that are often based on more complicated 3D CNN or transformer architectures. In this work, we first analyze the difficulties of jointly optimizing camera poses with GeNeRFs, and then further propose our DBARF to tackle these issues. Our DBARF which bundle adjusts camera poses by taking a cost feature map as an implicit cost function can be jointly trained with GeNeRFs in a self-supervised manner. Unlike BARF and its follow-up works, which can only be applied to per-scene optimized NeRFs and need accurate initial camera poses with the exception of forward-facing scenes, our method can generalize across scenes and does not require any good initialization. Experiments show the effectiveness and generalization ability of our DBARF when evaluated on real-world datasets. Our code is available at \url{https://aibluefisher.github.io/dbarf}.
Memotion 3: Dataset on sentiment and emotion analysis of codemixed Hindi-English Memes
Mar 17, 2023
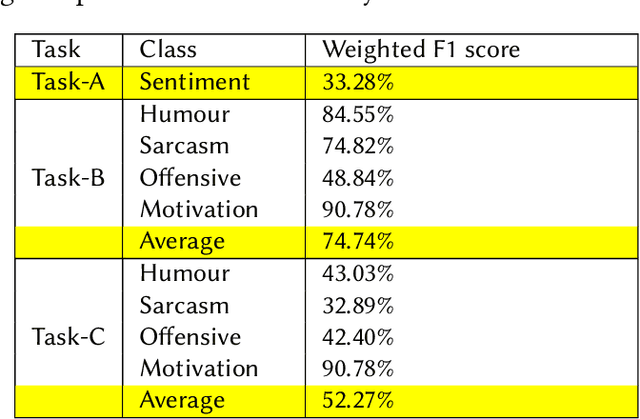


Memes are the new-age conveyance mechanism for humor on social media sites. Memes often include an image and some text. Memes can be used to promote disinformation or hatred, thus it is crucial to investigate in details. We introduce Memotion 3, a new dataset with 10,000 annotated memes. Unlike other prevalent datasets in the domain, including prior iterations of Memotion, Memotion 3 introduces Hindi-English Codemixed memes while prior works in the area were limited to only the English memes. We describe the Memotion task, the data collection and the dataset creation methodologies. We also provide a baseline for the task. The baseline code and dataset will be made available at https://github.com/Shreyashm16/Memotion-3.0
Video shutter angle estimation using optical flow and linear blur
Mar 17, 2023
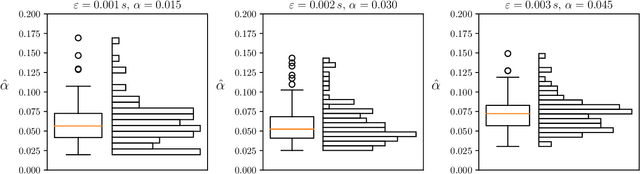
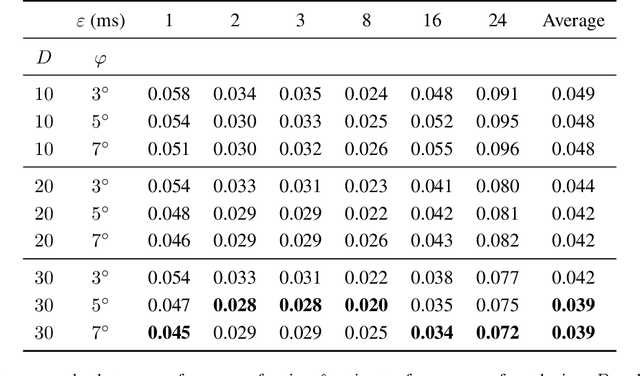
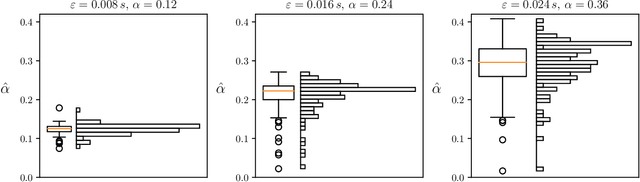
We present a method for estimating the shutter angle, a.k.a. exposure fraction -- the ratio of the exposure time and the reciprocal of frame rate -- of videoclips containing motion. The approach exploits the relation of the exposure fraction, optical flow, and linear motion blur. Robustness is achieved by selecting image patches where both the optical flow and blur estimates are reliable, checking their consistency. The method was evaluated on the publicly available Beam-Splitter Dataset with a range of exposure fractions from 0.015 to 0.36. The best achieved mean absolute error of estimates was 0.039. We successfully test the suitability of the method for a forensic application of detection of video tampering by frame removal or insertion.
Unpaired Translation from Semantic Label Maps to Images by Leveraging Domain-Specific Simulations
Feb 21, 2023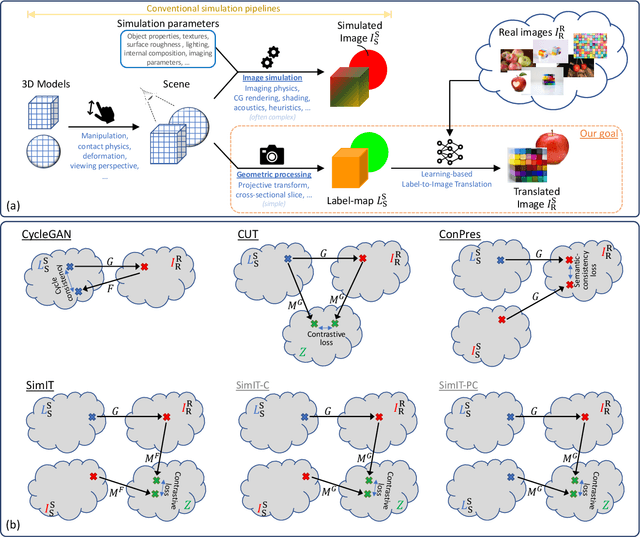
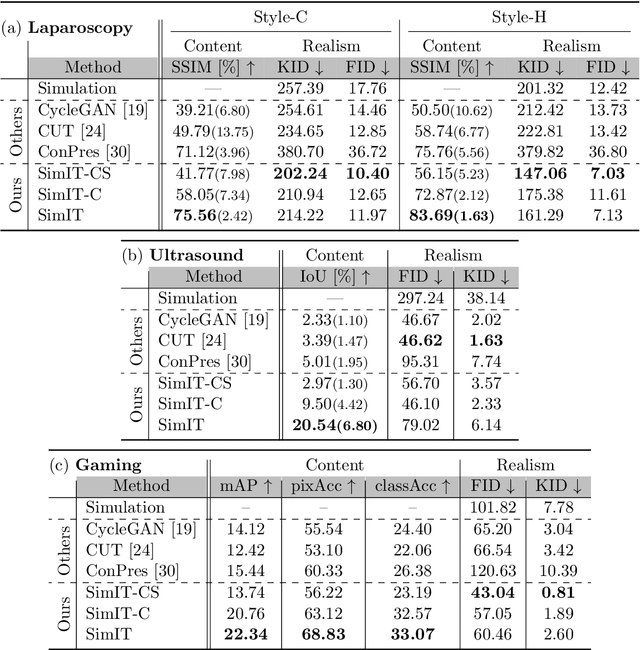
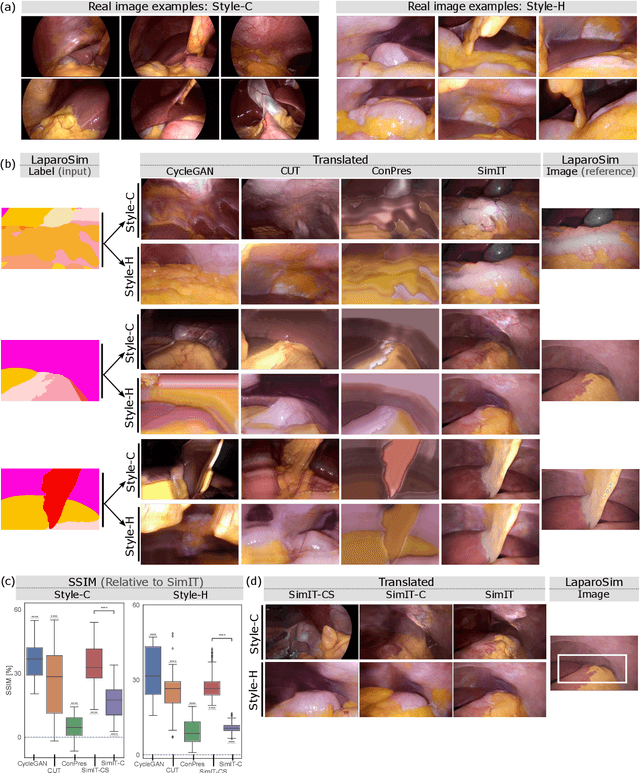
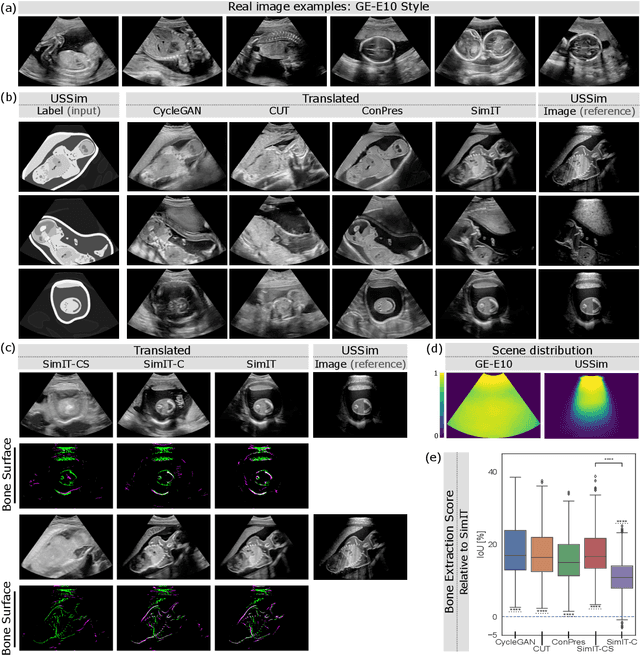
Photorealistic image generation from simulated label maps are necessitated in several contexts, such as for medical training in virtual reality. With conventional deep learning methods, this task requires images that are paired with semantic annotations, which typically are unavailable. We introduce a contrastive learning framework for generating photorealistic images from simulated label maps, by learning from unpaired sets of both. Due to potentially large scene differences between real images and label maps, existing unpaired image translation methods lead to artifacts of scene modification in synthesized images. We utilize simulated images as surrogate targets for a contrastive loss, while ensuring consistency by utilizing features from a reverse translation network. Our method enables bidirectional label-image translations, which is demonstrated in a variety of scenarios and datasets, including laparoscopy, ultrasound, and driving scenes. By comparing with state-of-the-art unpaired translation methods, our proposed method is shown to generate realistic and scene-accurate translations.
LoGoNet: Towards Accurate 3D Object Detection with Local-to-Global Cross-Modal Fusion
Mar 14, 2023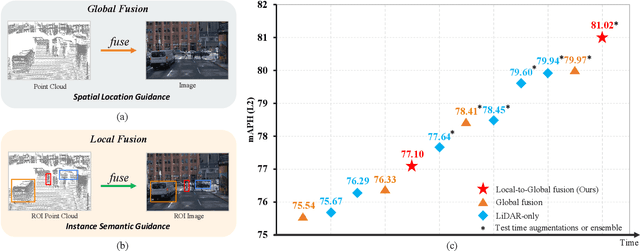
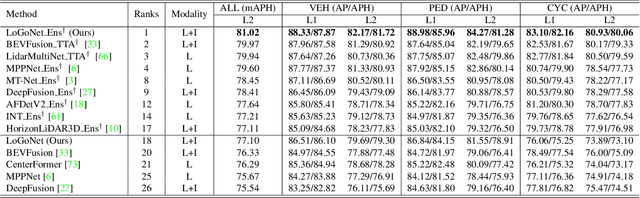
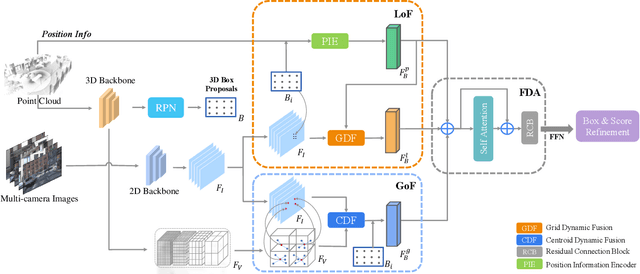
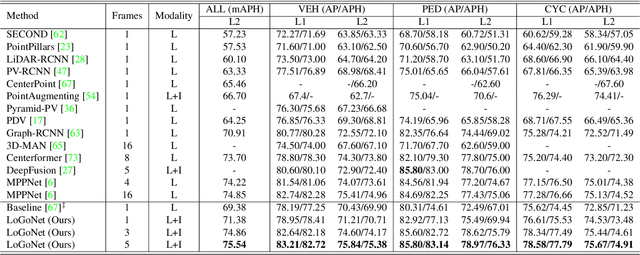
LiDAR-camera fusion methods have shown impressive performance in 3D object detection. Recent advanced multi-modal methods mainly perform global fusion, where image features and point cloud features are fused across the whole scene. Such practice lacks fine-grained region-level information, yielding suboptimal fusion performance. In this paper, we present the novel Local-to-Global fusion network (LoGoNet), which performs LiDAR-camera fusion at both local and global levels. Concretely, the Global Fusion (GoF) of LoGoNet is built upon previous literature, while we exclusively use point centroids to more precisely represent the position of voxel features, thus achieving better cross-modal alignment. As to the Local Fusion (LoF), we first divide each proposal into uniform grids and then project these grid centers to the images. The image features around the projected grid points are sampled to be fused with position-decorated point cloud features, maximally utilizing the rich contextual information around the proposals. The Feature Dynamic Aggregation (FDA) module is further proposed to achieve information interaction between these locally and globally fused features, thus producing more informative multi-modal features. Extensive experiments on both Waymo Open Dataset (WOD) and KITTI datasets show that LoGoNet outperforms all state-of-the-art 3D detection methods. Notably, LoGoNet ranks 1st on Waymo 3D object detection leaderboard and obtains 81.02 mAPH (L2) detection performance. It is noteworthy that, for the first time, the detection performance on three classes surpasses 80 APH (L2) simultaneously. Code will be available at \url{https://github.com/sankin97/LoGoNet}.
FedFTN: Personalized Federated Learning with Deep Feature Transformation Network for Multi-institutional Low-count PET Denoising
Apr 02, 2023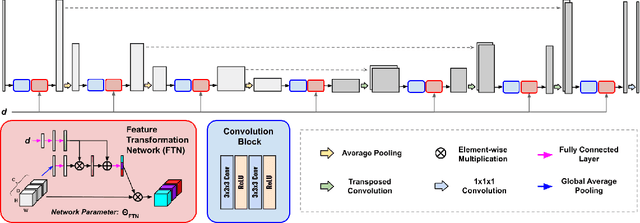

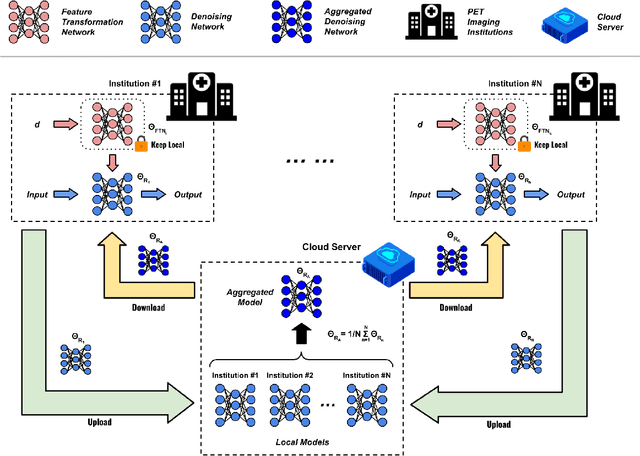

Low-count PET is an efficient way to reduce radiation exposure and acquisition time, but the reconstructed images often suffer from low signal-to-noise ratio (SNR), thus affecting diagnosis and other downstream tasks. Recent advances in deep learning have shown great potential in improving low-count PET image quality, but acquiring a large, centralized, and diverse dataset from multiple institutions for training a robust model is difficult due to privacy and security concerns of patient data. Moreover, low-count PET data at different institutions may have different data distribution, thus requiring personalized models. While previous federated learning (FL) algorithms enable multi-institution collaborative training without the need of aggregating local data, addressing the large domain shift in the application of multi-institutional low-count PET denoising remains a challenge and is still highly under-explored. In this work, we propose FedFTN, a personalized federated learning strategy that addresses these challenges. FedFTN uses a local deep feature transformation network (FTN) to modulate the feature outputs of a globally shared denoising network, enabling personalized low-count PET denoising for each institution. During the federated learning process, only the denoising network's weights are communicated and aggregated, while the FTN remains at the local institutions for feature transformation. We evaluated our method using a large-scale dataset of multi-institutional low-count PET imaging data from three medical centers located across three continents, and showed that FedFTN provides high-quality low-count PET images, outperforming previous baseline FL reconstruction methods across all low-count levels at all three institutions.
Ideal Observer Computation by Use of Markov-Chain Monte Carlo with Generative Adversarial Networks
Apr 02, 2023


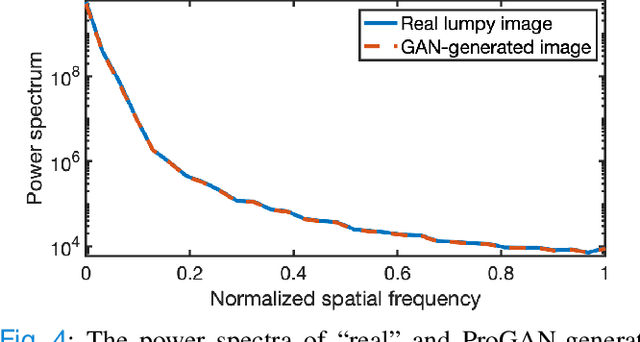
Medical imaging systems are often evaluated and optimized via objective, or task-specific, measures of image quality (IQ) that quantify the performance of an observer on a specific clinically-relevant task. The performance of the Bayesian Ideal Observer (IO) sets an upper limit among all observers, numerical or human, and has been advocated for use as a figure-of-merit (FOM) for evaluating and optimizing medical imaging systems. However, the IO test statistic corresponds to the likelihood ratio that is intractable to compute in the majority of cases. A sampling-based method that employs Markov-Chain Monte Carlo (MCMC) techniques was previously proposed to estimate the IO performance. However, current applications of MCMC methods for IO approximation have been limited to a small number of situations where the considered distribution of to-be-imaged objects can be described by a relatively simple stochastic object model (SOM). As such, there remains an important need to extend the domain of applicability of MCMC methods to address a large variety of scenarios where IO-based assessments are needed but the associated SOMs have not been available. In this study, a novel MCMC method that employs a generative adversarial network (GAN)-based SOM, referred to as MCMC-GAN, is described and evaluated. The MCMC-GAN method was quantitatively validated by use of test-cases for which reference solutions were available. The results demonstrate that the MCMC-GAN method can extend the domain of applicability of MCMC methods for conducting IO analyses of medical imaging systems.