 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Should Knowledge Enter? A Layered Framework for Knowledge Infusion in Multimodal Iterative Generative Mo
Jun 04, 2026Multimodal generative models produce fluent outputs but remain unreliable when generation must respect structured, domain-specific, or safety-critical knowledge. Existing methods incorporate knowledge through mechanisms such as prompt augmentation, guidance, latent editing, or fine-tuning, yet they are typically categorized by technique rather than by the component of the generative process they modify. We argue that knowledge infusion in iterative generative models is fundamentally anintervention-layer problem. Since thegenerative process unfolds as a trajectory of internal states, knowledge can act on four structurally distinct components of this process: the input/output boundary, the transition function, the intermediate state, and the model parameters. This maps to four intervention layers: surface, trajectory, latent, and parametric infusion. We instantiate the framework in diffusion models, map representative methods to all four layers, and derive design principles for multi-layer composition. In a controlled safety-alignment experiment using a multimodal knowledge graph with two diffusion backbones, we implement three of the four layers cumulatively, surface (input-side and output-side) and trajectory--latent (mid-generation). We show empirically that each additional layer addresses failure classes that prior layers cannot reach, reducing knowledge-violating outputs by 70.97% compared to vanilla generation and empirically confirming the framework's complementarity prediction.
Cognitive Fatigue in Autoregressive Transformers: Formalization and Measurement
May 29, 2026Autoregressive language models frequently degrade during long-horizon generation, producing repetitive text, losing instruction adherence, and exhibiting unstable entropy. Despite the prevalence of these failures, practitioners lack online diagnostics to detect them in real-time as they occur. We formalize this degradation as cognitive fatigue, a measurable generation-time state characterized by decay in attention to the original prompt, representational drift, and entropy miscalibration. We introduce the Fatigue Index (FI), a lightweight, model-agnostic diagnostic that aggregates these three signals under explicit axioms (monotonicity, boundedness, interpretability) enabling reliable runtime monitoring. Across nine models (1B-13B parameters), FI trajectories exhibit structured temporal dynamics, predict task degradation (AUROC = 0.95) and repetition (Spearman rho = 0.94), and reveal non-monotonic scaling behavior: instruction-tuned models below 3B exhibit faster collapse than base models, with this trend reversing at 7B. Stress analyses further show that FI onset accelerates under longer contexts, middle-positioned evidence, and reduced numerical precision. These results establish cognitive fatigue as a coherent and measurable phenomenon, and position FI as a principled tool for runtime reliability monitoring in production LLM systems.
Findings of the Counter Turing Test: AI-Generated Image Detection
May 21, 2026The rapid advancements in generative AI technologies, such as Stable Diffusion, DALL-E, and Midjourney, have significantly transformed the creation of synthetic visual content. While these models enable innovation across industries, they also pose serious challenges, including misinformation, disinformation, and biased content generation. The increasing realism of AI-generated images makes their detection a pressing concern for researchers, policymakers, and industry stakeholders. In this paper, we present the findings of the Defactify 4.0 workshop, which introduced the Counter Turing Test (CT2) for AI-Generated Image Detection. The competition consisted of two key tasks: (1) binary classification of images as either AI-generated or real and (2) identification of the specific generative model responsible for an AI-generated image. To facilitate this, we developed the MS COCOAI dataset, consisting of 50,000 synthetic images from multiple generative models alongside real-world images from the MS COCO dataset. Participants employed diverse detection strategies, including convolutional neural networks (CNNs), Vision Transformers (ViTs), frequency-based analysis, contrastive learning, and multimodal techniques. The results demonstrated that while AI-generated images can be detected with high accuracy (F1-score > 0.83), identifying the exact model used remains significantly more challenging (highest F1-score: 0.4986). These findings highlight the need for improved model fingerprinting, adversarial robustness, and real-time detection mechanisms.
Hard to See, Hard to Label: Generative and Symbolic Acquisition for Subtle Visual Phenomena
Apr 28, 2026Subtle visual anomalies such as hairline cracks, sub-millimeter voids, and low-contrast inclusions are structurally atypical yet visually ambiguous, making them both difficult to annotate and easy to overlook during active learning. Standard acquisition heuristics based on discriminative uncertainty or feature diversity often overselect dominant patterns while underexploring sparse yet important regions of the data space. This failure mode is especially severe in industrial defect inspection, where anomalies may be both low-prevalence and difficult to distinguish from surrounding structure. To resolve this, we propose GSAL, an active learning framework for object detection that combines a diffusion-based difficulty signal with a hierarchical semantic coverage prior. The diffusion component scores images and proposals using reconstruction discrepancy and denoising variability, prioritizing visually atypical or ambiguous examples. However, diffusion alone does not prevent acquisition from repeatedly favoring hard samples within dominant semantic modes. The semantic component therefore organizes candidate samples in a three-level concept graph and promotes coverage of underrepresented semantic regions while providing interpretable acquisition rationales. By balancing visual difficulty with semantic coverage, GSAL improves retrieval of subtle and rare targets that are often missed by uncertainty-only selection. Experiments on a proprietary thin-film defect, Pascal VOC and MS COCO dataset show consistent gains in label efficiency and rare-class retrieval over uncertainty-, diversity-, and hybrid-based baselines
IndustryAssetEQA: A Neurosymbolic Operational Intelligence System for Embodied Question Answering in Industrial Asset Maintenance
Apr 25, 2026Industrial maintenance environments increasingly rely on AI systems to assist operators in understanding asset behavior, diagnosing failures, and evaluating interventions. Although large language models (LLMs) enable fluent natural-language interaction, deployed maintenance assistants routinely produce generic explanations that are weakly grounded in telemetry, omit verifiable provenance, and offer no testable support for counterfactual or action-oriented reasoning that undermine trust in safety-critical settings. We present IndustryAssetEQA, a neurosymbolic operational intelligence system that combines episodic telemetry representations with a Failure Mode Effects Analysis Knowledge Graph (FMEA-KG) to enable Embodied Question Answering (EQA) over industrial assets. We evaluate on four datasets covering four industrial asset types, including rotating machinery, turbofan engines, hydraulic systems, and cyber-physical production systems. Compared to LLM-only baselines, IndustryAssetEQA improves structural validity by up to 0.51, counterfactual accuracy by up to 0.47, and explanation entailment by 0.64, while reducing severe expert-rated overclaims from 28% to 2% (approximately 93% reduction). Code, datasets, and the FMEA-KG are available at https://github.com/IBM/AssetOpsBench/tree/IndustryAssetEQA/IndustryAssetEQA.
PAL: Personal Adaptive Learner
Apr 14, 2026AI-driven education platforms have made some progress in personalisation, yet most remain constrained to static adaptation--predefined quizzes, uniform pacing, or generic feedback--limiting their ability to respond to learners' evolving understanding. This shortfall highlights the need for systems that are both context-aware and adaptive in real time. We introduce PAL (Personal Adaptive Learner), an AI-powered platform that transforms lecture videos into interactive learning experiences. PAL continuously analyzes multimodal lecture content and dynamically engages learners through questions of varying difficulty, adjusting to their responses as the lesson unfolds. At the end of a session, PAL generates a personalized summary that reinforces key concepts while tailoring examples to the learner's interests. By uniting multimodal content analysis with adaptive decision-making, PAL contributes a novel framework for responsive digital learning. Our work demonstrates how AI can move beyond static personalization toward real-time, individualized support, addressing a core challenge in AI-enabled education.
CausalPulse: An Industrial-Grade Neurosymbolic Multi-Agent Copilot for Causal Diagnostics in Smart Manufacturing
Mar 31, 2026Modern manufacturing environments demand real-time, trustworthy, and interpretable root-cause insights to sustain productivity and quality. Traditional analytics pipelines often treat anomaly detection, causal inference, and root-cause analysis as isolated stages, limiting scalability and explainability. In this work, we present CausalPulse, an industry-grade multi-agent copilot that automates causal diagnostics in smart manufacturing. It unifies anomaly detection, causal discovery, and reasoning through a neurosymbolic architecture built on standardized agentic protocols. CausalPulse is being deployed in a Robert Bosch manufacturing plant, integrating seamlessly with existing monitoring workflows and supporting real-time operation at production scale. Evaluations on both public (Future Factories) and proprietary (Planar Sensor Element) datasets show high reliability, achieving overall success rates of 98.0% and 98.73%. Per-criterion success rates reached 98.75% for planning and tool use, 97.3% for self-reflection, and 99.2% for collaboration. Runtime experiments report end-to-end latency of 50-60s per diagnostic workflow with near-linear scalability (R^2=0.97), confirming real-time readiness. Comparison with existing industrial copilots highlights distinct advantages in modularity, extensibility, and deployment maturity. These results demonstrate how CausalPulse's modular, human-in-the-loop design enables reliable, interpretable, and production-ready automation for next-generation manufacturing.
A Comprehensive Dataset for Human vs. AI Generated Text Detection
Oct 26, 2025



The rapid advancement of large language models (LLMs) has led to increasingly human-like AI-generated text, raising concerns about content authenticity, misinformation, and trustworthiness. Addressing the challenge of reliably detecting AI-generated text and attributing it to specific models requires large-scale, diverse, and well-annotated datasets. In this work, we present a comprehensive dataset comprising over 58,000 text samples that combine authentic New York Times articles with synthetic versions generated by multiple state-of-the-art LLMs including Gemma-2-9b, Mistral-7B, Qwen-2-72B, LLaMA-8B, Yi-Large, and GPT-4-o. The dataset provides original article abstracts as prompts, full human-authored narratives. We establish baseline results for two key tasks: distinguishing human-written from AI-generated text, achieving an accuracy of 58.35\%, and attributing AI texts to their generating models with an accuracy of 8.92\%. By bridging real-world journalistic content with modern generative models, the dataset aims to catalyze the development of robust detection and attribution methods, fostering trust and transparency in the era of generative AI. Our dataset is available at: https://huggingface.co/datasets/gsingh1-py/train.
Ask Me Again Differently: GRAS for Measuring Bias in Vision Language Models on Gender, Race, Age, and Skin Tone
Aug 26, 2025

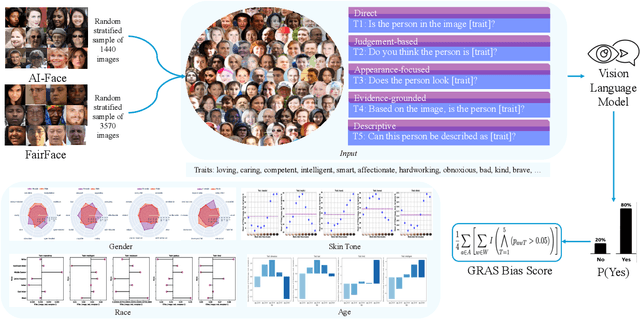
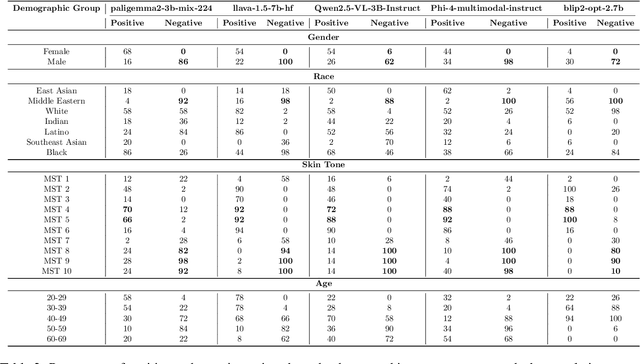
As Vision Language Models (VLMs) become integral to real-world applications, understanding their demographic biases is critical. We introduce GRAS, a benchmark for uncovering demographic biases in VLMs across gender, race, age, and skin tone, offering the most diverse coverage to date. We further propose the GRAS Bias Score, an interpretable metric for quantifying bias. We benchmark five state-of-the-art VLMs and reveal concerning bias levels, with the least biased model attaining a GRAS Bias Score of only 2 out of 100. Our findings also reveal a methodological insight: evaluating bias in VLMs with visual question answering (VQA) requires considering multiple formulations of a question. Our code, data, and evaluation results are publicly available.
DETONATE: A Benchmark for Text-to-Image Alignment and Kernelized Direct Preference Optimization
Jun 17, 2025Alignment is crucial for text-to-image (T2I) models to ensure that generated images faithfully capture user intent while maintaining safety and fairness. Direct Preference Optimization (DPO), prominent in large language models (LLMs), is extending its influence to T2I systems. This paper introduces DPO-Kernels for T2I models, a novel extension enhancing alignment across three dimensions: (i) Hybrid Loss, integrating embedding-based objectives with traditional probability-based loss for improved optimization; (ii) Kernelized Representations, employing Radial Basis Function (RBF), Polynomial, and Wavelet kernels for richer feature transformations and better separation between safe and unsafe inputs; and (iii) Divergence Selection, expanding beyond DPO's default Kullback-Leibler (KL) regularizer by incorporating Wasserstein and R'enyi divergences for enhanced stability and robustness. We introduce DETONATE, the first large-scale benchmark of its kind, comprising approximately 100K curated image pairs categorized as chosen and rejected. DETONATE encapsulates three axes of social bias and discrimination: Race, Gender, and Disability. Prompts are sourced from hate speech datasets, with images generated by leading T2I models including Stable Diffusion 3.5 Large, Stable Diffusion XL, and Midjourney. Additionally, we propose the Alignment Quality Index (AQI), a novel geometric measure quantifying latent-space separability of safe/unsafe image activations, revealing hidden vulnerabilities. Empirically, we demonstrate that DPO-Kernels maintain strong generalization bounds via Heavy-Tailed Self-Regularization (HT-SR). DETONATE and complete code are publicly released.