 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Tale of Two Features: Stable Diffusion Complements DINO for Zero-Shot Semantic Correspondence
May 24, 2023


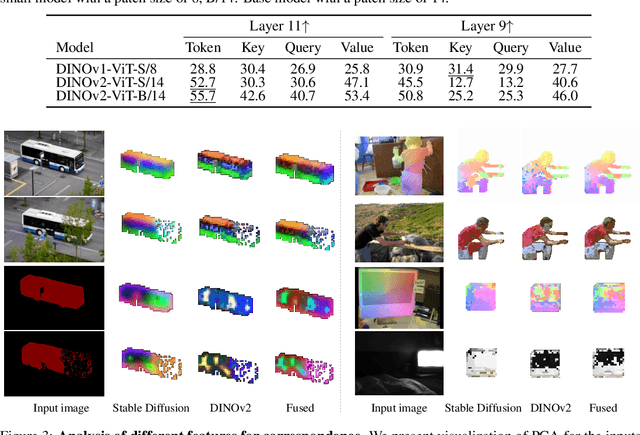
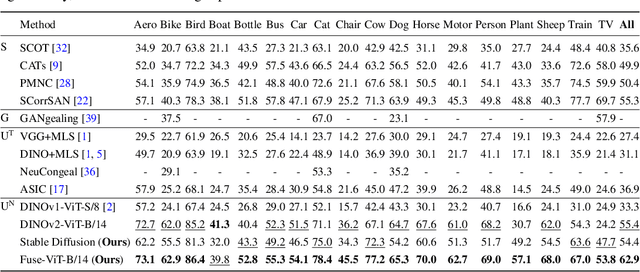
Text-to-image diffusion models have made significant advances in generating and editing high-quality images. As a result, numerous approaches have explored the ability of diffusion model features to understand and process single images for downstream tasks, e.g., classification, semantic segmentation, and stylization. However, significantly less is known about what these features reveal across multiple, different images and objects. In this work, we exploit Stable Diffusion (SD) features for semantic and dense correspondence and discover that with simple post-processing, SD features can perform quantitatively similar to SOTA representations. Interestingly, the qualitative analysis reveals that SD features have very different properties compared to existing representation learning features, such as the recently released DINOv2: while DINOv2 provides sparse but accurate matches, SD features provide high-quality spatial information but sometimes inaccurate semantic matches. We demonstrate that a simple fusion of these two features works surprisingly well, and a zero-shot evaluation using nearest neighbors on these fused features provides a significant performance gain over state-of-the-art methods on benchmark datasets, e.g., SPair-71k, PF-Pascal, and TSS. We also show that these correspondences can enable interesting applications such as instance swapping in two images.
Multiresolution Feature Guidance Based Transformer for Anomaly Detection
May 24, 2023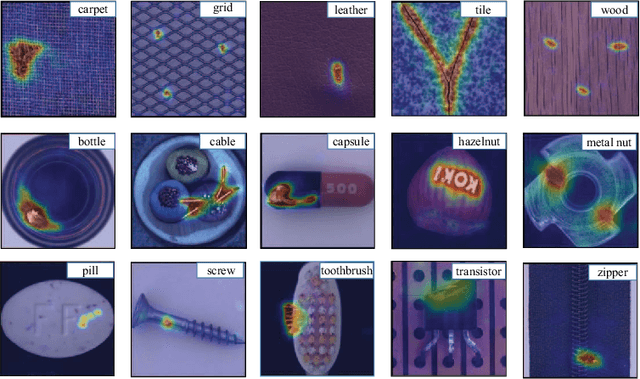
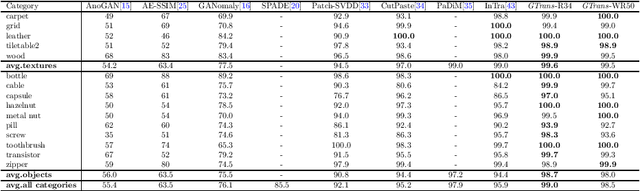
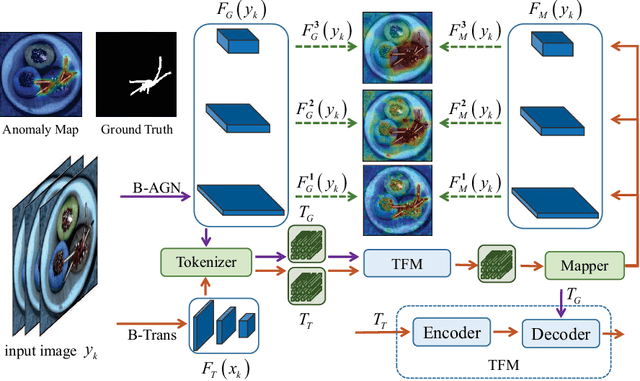
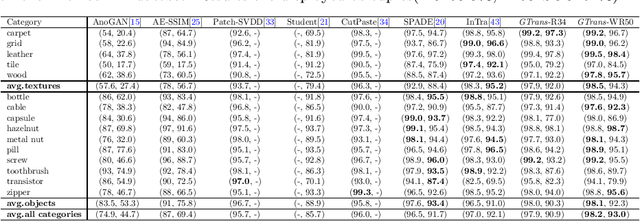
Anomaly detection is represented as an unsupervised learning to identify deviated images from normal images. In general, there are two main challenges of anomaly detection tasks, i.e., the class imbalance and the unexpectedness of anomalies. In this paper, we propose a multiresolution feature guidance method based on Transformer named GTrans for unsupervised anomaly detection and localization. In GTrans, an Anomaly Guided Network (AGN) pre-trained on ImageNet is developed to provide surrogate labels for features and tokens. Under the tacit knowledge guidance of the AGN, the anomaly detection network named Trans utilizes Transformer to effectively establish a relationship between features with multiresolution, enhancing the ability of the Trans in fitting the normal data manifold. Due to the strong generalization ability of AGN, GTrans locates anomalies by comparing the differences in spatial distance and direction of multi-scale features extracted from the AGN and the Trans. Our experiments demonstrate that the proposed GTrans achieves state-of-the-art performance in both detection and localization on the MVTec AD dataset. GTrans achieves image-level and pixel-level anomaly detection AUROC scores of 99.0% and 97.9% on the MVTec AD dataset, respectively.
Denoising Bottleneck with Mutual Information Maximization for Video Multimodal Fusion
May 24, 2023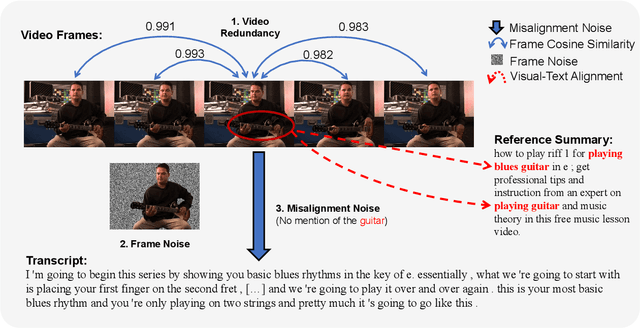
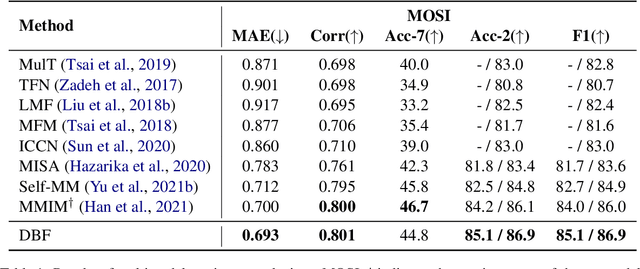
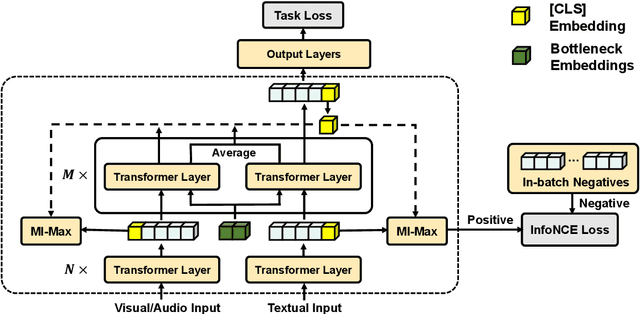
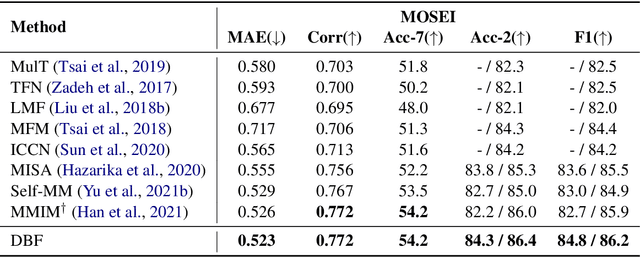
Video multimodal fusion aims to integrate multimodal signals in videos, such as visual, audio and text, to make a complementary prediction with multiple modalities contents. However, unlike other image-text multimodal tasks, video has longer multimodal sequences with more redundancy and noise in both visual and audio modalities. Prior denoising methods like forget gate are coarse in the granularity of noise filtering. They often suppress the redundant and noisy information at the risk of losing critical information. Therefore, we propose a denoising bottleneck fusion (DBF) model for fine-grained video multimodal fusion. On the one hand, we employ a bottleneck mechanism to filter out noise and redundancy with a restrained receptive field. On the other hand, we use a mutual information maximization module to regulate the filter-out module to preserve key information within different modalities. Our DBF model achieves significant improvement over current state-of-the-art baselines on multiple benchmarks covering multimodal sentiment analysis and multimodal summarization tasks. It proves that our model can effectively capture salient features from noisy and redundant video, audio, and text inputs. The code for this paper is publicly available at https://github.com/WSXRHFG/DBF.
Robust Classification via a Single Diffusion Model
May 24, 2023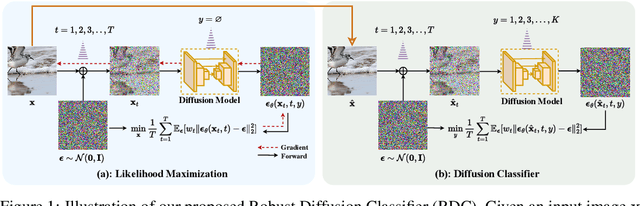
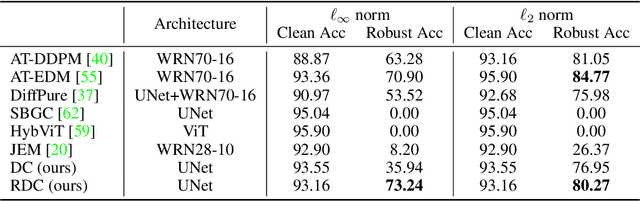
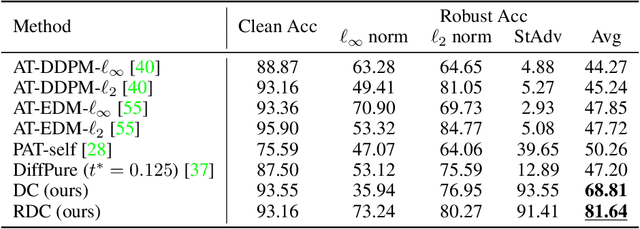
Recently, diffusion models have been successfully applied to improving adversarial robustness of image classifiers by purifying the adversarial noises or generating realistic data for adversarial training. However, the diffusion-based purification can be evaded by stronger adaptive attacks while adversarial training does not perform well under unseen threats, exhibiting inevitable limitations of these methods. To better harness the expressive power of diffusion models, in this paper we propose Robust Diffusion Classifier (RDC), a generative classifier that is constructed from a pre-trained diffusion model to be adversarially robust. Our method first maximizes the data likelihood of a given input and then predicts the class probabilities of the optimized input using the conditional likelihood of the diffusion model through Bayes' theorem. Since our method does not require training on particular adversarial attacks, we demonstrate that it is more generalizable to defend against multiple unseen threats. In particular, RDC achieves $73.24\%$ robust accuracy against $\ell_\infty$ norm-bounded perturbations with $\epsilon_\infty=8/255$ on CIFAR-10, surpassing the previous state-of-the-art adversarial training models by $+2.34\%$. The findings highlight the potential of generative classifiers by employing diffusion models for adversarial robustness compared with the commonly studied discriminative classifiers.
Noise robust neural network architecture
May 16, 2023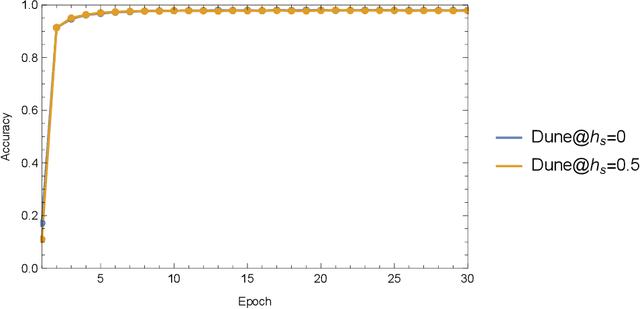
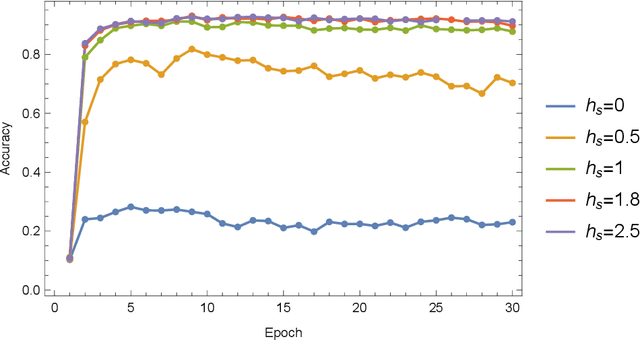
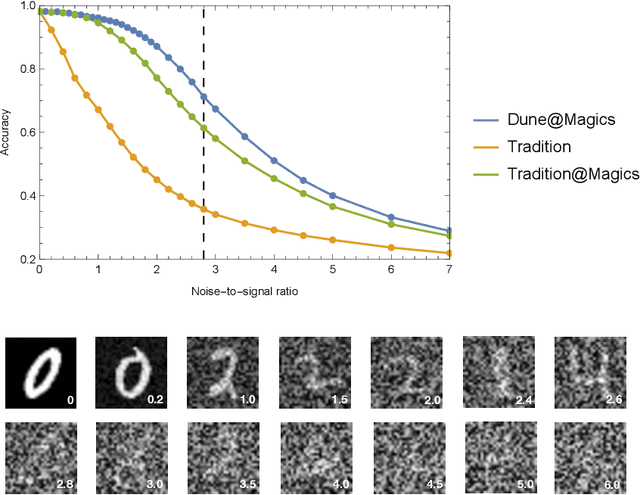
In which we propose neural network architecture (dune neural network) for recognizing general noisy image without adding any artificial noise in the training data. By representing each free parameter of the network as an uncertainty interval, and applying a linear transformation to each input element, we show that the resulting architecture achieves decent noise robustness when faced with input data with white noise. We apply simple dune neural networks for MNIST dataset and demonstrate that even for very noisy input images which are hard for human to recognize, our approach achieved better test set accuracy than human without dataset augmentation. We also find that our method is robust for many other examples with various background patterns added.
ReSup: Reliable Label Noise Suppression for Facial Expression Recognition
May 29, 2023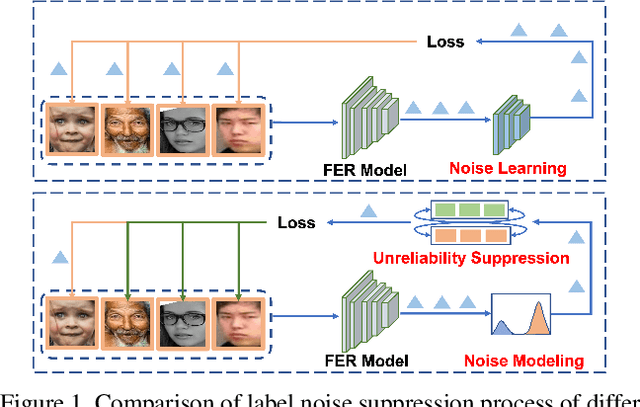
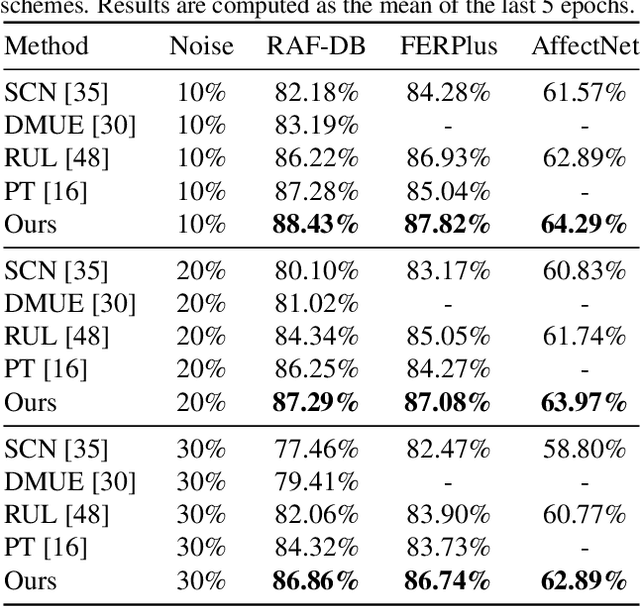
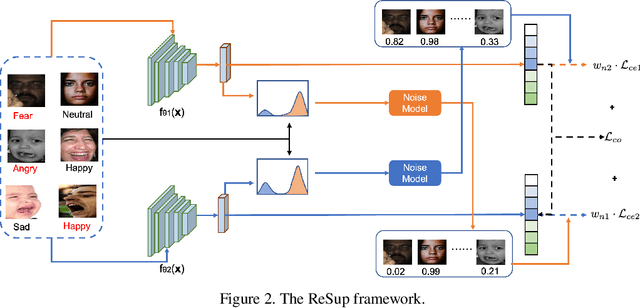
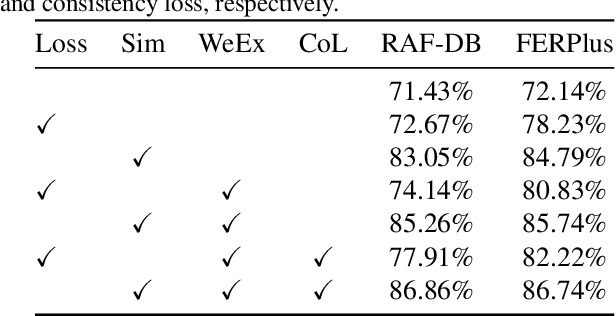
Because of the ambiguous and subjective property of the facial expression recognition (FER) task, the label noise is widely existing in the FER dataset. For this problem, in the training phase, current FER methods often directly predict whether the label of the input image is noised or not, aiming to reduce the contribution of the noised data in training. However, we argue that this kind of method suffers from the low reliability of such noise data decision operation. It makes that some mistakenly abounded clean data are not utilized sufficiently and some mistakenly kept noised data disturbing the model learning process. In this paper, we propose a more reliable noise-label suppression method called ReSup (Reliable label noise Suppression for FER). First, instead of directly predicting noised or not, ReSup makes the noise data decision by modeling the distribution of noise and clean labels simultaneously according to the disagreement between the prediction and the target. Specifically, to achieve optimal distribution modeling, ReSup models the similarity distribution of all samples. To further enhance the reliability of our noise decision results, ReSup uses two networks to jointly achieve noise suppression. Specifically, ReSup utilize the property that two networks are less likely to make the same mistakes, making two networks swap decisions and tending to trust decisions with high agreement. Extensive experiments on three popular benchmarks show that the proposed method significantly outperforms state-of-the-art noisy label FER methods by 3.01% on FERPlus becnmarks. Code: https://github.com/purpleleaves007/FERDenoise
Synthetic CT Generation from MRI using 3D Transformer-based Denoising Diffusion Model
May 31, 2023

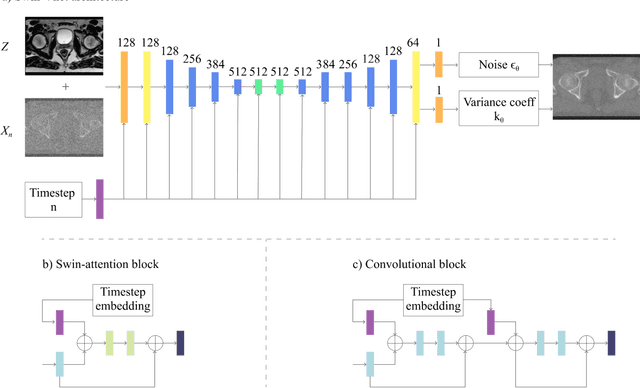
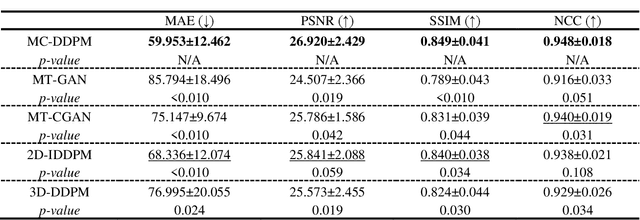
Magnetic resonance imaging (MRI)-based synthetic computed tomography (sCT) simplifies radiation therapy treatment planning by eliminating the need for CT simulation and error-prone image registration, ultimately reducing patient radiation dose and setup uncertainty. We propose an MRI-to-CT transformer-based denoising diffusion probabilistic model (MC-DDPM) to transform MRI into high-quality sCT to facilitate radiation treatment planning. MC-DDPM implements diffusion processes with a shifted-window transformer network to generate sCT from MRI. The proposed model consists of two processes: a forward process which adds Gaussian noise to real CT scans, and a reverse process in which a shifted-window transformer V-net (Swin-Vnet) denoises the noisy CT scans conditioned on the MRI from the same patient to produce noise-free CT scans. With an optimally trained Swin-Vnet, the reverse diffusion process was used to generate sCT scans matching MRI anatomy. We evaluated the proposed method by generating sCT from MRI on a brain dataset and a prostate dataset. Qualitative evaluation was performed using the mean absolute error (MAE) of Hounsfield unit (HU), peak signal to noise ratio (PSNR), multi-scale Structure Similarity index (MS-SSIM) and normalized cross correlation (NCC) indexes between ground truth CTs and sCTs. MC-DDPM generated brain sCTs with state-of-the-art quantitative results with MAE 43.317 HU, PSNR 27.046 dB, SSIM 0.965, and NCC 0.983. For the prostate dataset, MC-DDPM achieved MAE 59.953 HU, PSNR 26.920 dB, SSIM 0.849, and NCC 0.948. In conclusion, we have developed and validated a novel approach for generating CT images from routine MRIs using a transformer-based DDPM. This model effectively captures the complex relationship between CT and MRI images, allowing for robust and high-quality synthetic CT (sCT) images to be generated in minutes.
Variational Classification
May 17, 2023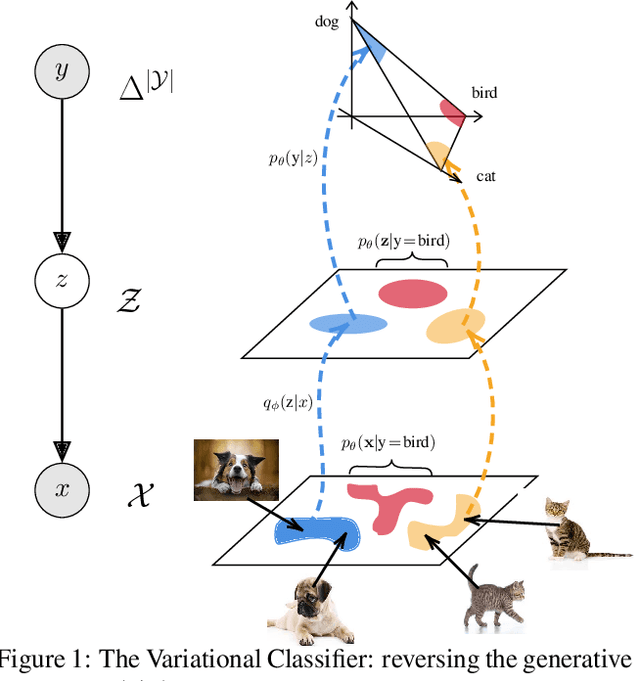

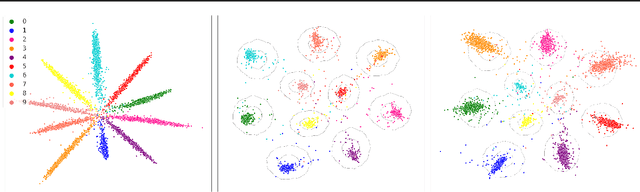

We present a novel extension of the traditional neural network approach to classification tasks, referred to as variational classification (VC). By incorporating latent variable modeling, akin to the relationship between variational autoencoders and traditional autoencoders, we derive a training objective based on the evidence lower bound (ELBO), optimized using an adversarial approach. Our VC model allows for more flexibility in design choices, in particular class-conditional latent priors, in place of the implicit assumptions made in off-the-shelf softmax classifiers. Empirical evaluation on image and text classification datasets demonstrates the effectiveness of our approach in terms of maintaining prediction accuracy while improving other desirable properties such as calibration and adversarial robustness, even when applied to out-of-domain data.
Any-to-Any Style Transfer: Making Picasso and Da Vinci Collaborate
Apr 20, 2023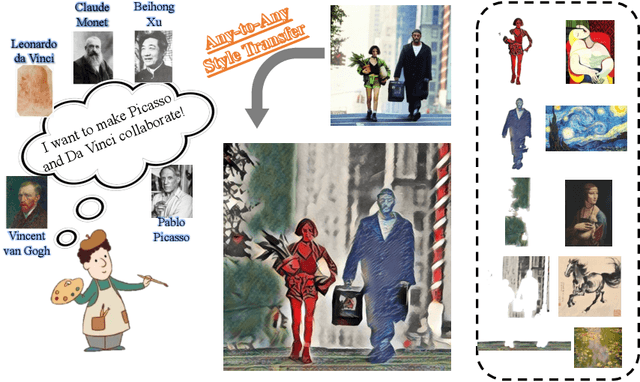
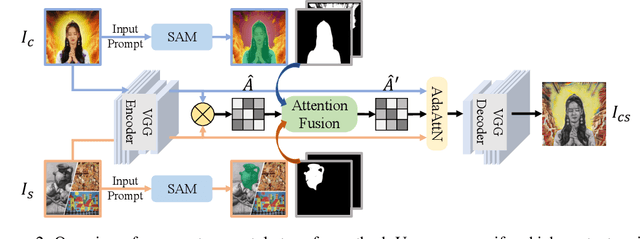

Style transfer aims to render the style of a given image for style reference to another given image for content reference, and has been widely adopted in artistic generation and image editing. Existing approaches either apply the holistic style of the style image in a global manner, or migrate local colors and textures of the style image to the content counterparts in a pre-defined way. In either case, only one result can be generated for a specific pair of content and style images, which therefore lacks flexibility and is hard to satisfy different users with different preferences. We propose here a novel strategy termed Any-to-Any Style Transfer to address this drawback, which enables users to interactively select styles of regions in the style image and apply them to the prescribed content regions. In this way, personalizable style transfer is achieved through human-computer interaction. At the heart of our approach lies in (1) a region segmentation module based on Segment Anything, which supports region selection with only some clicks or drawing on images and thus takes user inputs conveniently and flexibly; (2) and an attention fusion module, which converts inputs from users to controlling signals for the style transfer model. Experiments demonstrate the effectiveness for personalizable style transfer. Notably, our approach performs in a plug-and-play manner portable to any style transfer method and enhance the controllablity. Our code is available \href{https://github.com/Huage001/Transfer-Any-Style}{here}.
Img2Vec: A Teacher of High Token-Diversity Helps Masked AutoEncoders
Apr 25, 2023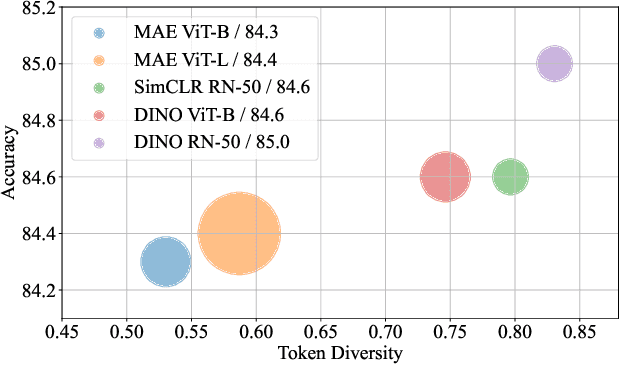
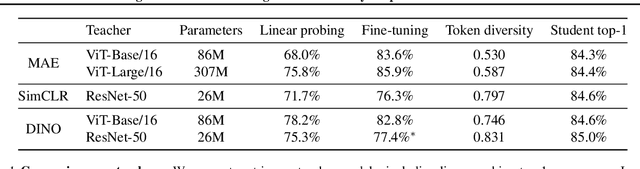

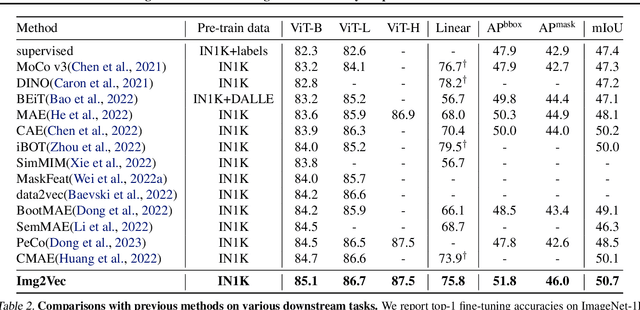
We present a pipeline of Image to Vector (Img2Vec) for masked image modeling (MIM) with deep features. To study which type of deep features is appropriate for MIM as a learning target, we propose a simple MIM framework with serials of well-trained self-supervised models to convert an Image to a feature Vector as the learning target of MIM, where the feature extractor is also known as a teacher model. Surprisingly, we empirically find that an MIM model benefits more from image features generated by some lighter models (e.g., ResNet-50, 26M) than from those by a cumbersome teacher like Transformer-based models (e.g., ViT-Large, 307M). To analyze this remarkable phenomenon, we devise a novel attribute, token diversity, to evaluate the characteristics of generated features from different models. Token diversity measures the feature dissimilarity among different tokens. Through extensive experiments and visualizations, we hypothesize that beyond the acknowledgment that a large model can improve MIM, a high token-diversity of a teacher model is also crucial. Based on the above discussion, Img2Vec adopts a teacher model with high token-diversity to generate image features. Img2Vec pre-trained on ImageNet unlabeled data with ViT-B yields 85.1\% top-1 accuracy on fine-tuning. Moreover, we scale up Img2Vec on larger models, ViT-L and ViT-H, and get $86.7\%$ and $87.5\%$ accuracy respectively. It also achieves state-of-the-art results on other downstream tasks, e.g., 51.8\% mAP on COCO and 50.7\% mIoU on ADE20K. Img2Vec is a simple yet effective framework tailored to deep feature MIM learning, accomplishing superb comprehensive performance on representative vision tasks.