 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Overconfident in Models and Results for Semi-Supervised 3D Medical Image Segmentation?
May 25, 2026Semi-supervised learning has become a dominant paradigm for reducing annotation costs. However, we argue that the current progress is clouded by a twofold overconfidence problem. Algorithmically, mainstream pseudo-labeling frameworks often conflate prediction confidence with uncertainty, leading to severe confirmation bias. Strategically, since multiple benchmark datasets lack dedicated validation sets, some studies use the test set for validation as well, leading to inflated performance estimates. Subsequent methods, compelled to employ the same strategy to surpass reported SOTA, trigger an arms race of overfitting. This raises concerns that the impressive numerical gains in the community may reflect overfitting rather than genuine progress. Thus, we propose a tri-space calibrated segmentation framework founded on a principled dual-axis reliability assessment engine. It explicitly decouples confidence from uncertainty and uses this signal to detect and correct confirmation bias across feature, probability, and image spaces in a collaborative manner. Across three benchmark datasets, TCSeg consistently delivers strong performance under existing evaluation protocols. More importantly, we advocate that the community report final-checkpoint results under multiple-run protocols, thereby establishing more rigorous benchmarks with a more realistic perspective. Code will be available: github.com/DirkLiii/TCSeg.
MAPI-GNN: Multi-Activation Plane Interaction Graph Neural Network for Multimodal Medical Diagnosis
Dec 23, 2025Graph neural networks are increasingly applied to multimodal medical diagnosis for their inherent relational modeling capabilities. However, their efficacy is often compromised by the prevailing reliance on a single, static graph built from indiscriminate features, hindering the ability to model patient-specific pathological relationships. To this end, the proposed Multi-Activation Plane Interaction Graph Neural Network (MAPI-GNN) reconstructs this single-graph paradigm by learning a multifaceted graph profile from semantically disentangled feature subspaces. The framework first uncovers latent graph-aware patterns via a multi-dimensional discriminator; these patterns then guide the dynamic construction of a stack of activation graphs; and this multifaceted profile is finally aggregated and contextualized by a relational fusion engine for a robust diagnosis. Extensive experiments on two diverse tasks, comprising over 1300 patient samples, demonstrate that MAPI-GNN significantly outperforms state-of-the-art methods.
Denoising Bottleneck with Mutual Information Maximization for Video Multimodal Fusion
May 25, 2023



Video multimodal fusion aims to integrate multimodal signals in videos, such as visual, audio and text, to make a complementary prediction with multiple modalities contents. However, unlike other image-text multimodal tasks, video has longer multimodal sequences with more redundancy and noise in both visual and audio modalities. Prior denoising methods like forget gate are coarse in the granularity of noise filtering. They often suppress the redundant and noisy information at the risk of losing critical information. Therefore, we propose a denoising bottleneck fusion (DBF) model for fine-grained video multimodal fusion. On the one hand, we employ a bottleneck mechanism to filter out noise and redundancy with a restrained receptive field. On the other hand, we use a mutual information maximization module to regulate the filter-out module to preserve key information within different modalities. Our DBF model achieves significant improvement over current state-of-the-art baselines on multiple benchmarks covering multimodal sentiment analysis and multimodal summarization tasks. It proves that our model can effectively capture salient features from noisy and redundant video, audio, and text inputs. The code for this paper is publicly available at https://github.com/WSXRHFG/DBF.
ImageNetVC: Zero-Shot Visual Commonsense Evaluation on 1000 ImageNet Categories
May 24, 2023



Recently, Pretrained Language Models (PLMs) have been serving as general-purpose interfaces, posing a significant demand for comprehensive visual knowledge. However, it remains unclear how well current PLMs and their visually augmented counterparts (VaLMs) can master visual commonsense knowledge. To investigate this, we propose ImageNetVC, a fine-grained, human-annotated dataset specifically designed for zero-shot visual commonsense evaluation across 1,000 ImageNet categories. Utilizing ImageNetVC, we delve into the fundamental visual commonsense knowledge of both unimodal PLMs and VaLMs, uncovering the scaling law and the influence of the backbone model on VaLMs. Furthermore, we investigate the factors affecting the visual commonsense knowledge of large-scale models, providing insights into the development of language models enriched with visual commonsense knowledge. Our code and dataset are available at https://github.com/hemingkx/ImageNetVC.
Premise-based Multimodal Reasoning: A Human-like Cognitive Process
May 15, 2021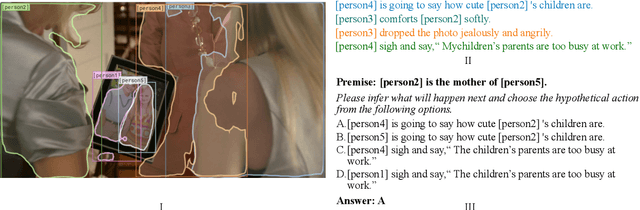
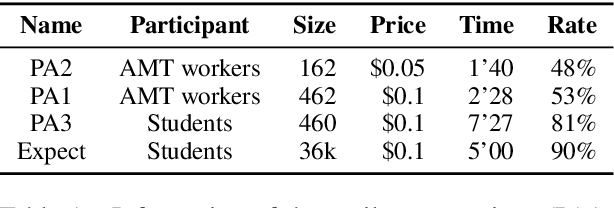
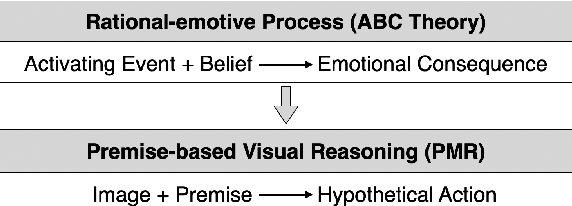

Reasoning is one of the major challenges of Human-like AI and has recently attracted intensive attention from natural language processing (NLP) researchers. However, cross-modal reasoning needs further research. For cross-modal reasoning, we observe that most methods fall into shallow feature matching without in-depth human-like reasoning.The reason lies in that existing cross-modal tasks directly ask questions for a image. However, human reasoning in real scenes is often made under specific background information, a process that is studied by the ABC theory in social psychology. We propose a shared task named "Premise-based Multimodal Reasoning" (PMR), which requires participating models to reason after establishing a profound understanding of background information. We believe that the proposed PMR would contribute to and help shed a light on human-like in-depth reasoning.