 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CT respiratory motion synthesis using joint supervised and adversarial learning
Mar 29, 2024
Objective: Four-dimensional computed tomography (4DCT) imaging consists in reconstructing a CT acquisition into multiple phases to track internal organ and tumor motion. It is commonly used in radiotherapy treatment planning to establish planning target volumes. However, 4DCT increases protocol complexity, may not align with patient breathing during treatment, and lead to higher radiation delivery. Approach: In this study, we propose a deep synthesis method to generate pseudo respiratory CT phases from static images for motion-aware treatment planning. The model produces patient-specific deformation vector fields (DVFs) by conditioning synthesis on external patient surface-based estimation, mimicking respiratory monitoring devices. A key methodological contribution is to encourage DVF realism through supervised DVF training while using an adversarial term jointly not only on the warped image but also on the magnitude of the DVF itself. This way, we avoid excessive smoothness typically obtained through deep unsupervised learning, and encourage correlations with the respiratory amplitude. Main results: Performance is evaluated using real 4DCT acquisitions with smaller tumor volumes than previously reported. Results demonstrate for the first time that the generated pseudo-respiratory CT phases can capture organ and tumor motion with similar accuracy to repeated 4DCT scans of the same patient. Mean inter-scans tumor center-of-mass distances and Dice similarity coefficients were $1.97$mm and $0.63$, respectively, for real 4DCT phases and $2.35$mm and $0.71$ for synthetic phases, and compares favorably to a state-of-the-art technique (RMSim).
Universal Bovine Identification via Depth Data and Deep Metric Learning
Mar 29, 2024This paper proposes and evaluates, for the first time, a top-down (dorsal view), depth-only deep learning system for accurately identifying individual cattle and provides associated code, datasets, and training weights for immediate reproducibility. An increase in herd size skews the cow-to-human ratio at the farm and makes the manual monitoring of individuals more challenging. Therefore, real-time cattle identification is essential for the farms and a crucial step towards precision livestock farming. Underpinned by our previous work, this paper introduces a deep-metric learning method for cattle identification using depth data from an off-the-shelf 3D camera. The method relies on CNN and MLP backbones that learn well-generalised embedding spaces from the body shape to differentiate individuals -- requiring neither species-specific coat patterns nor close-up muzzle prints for operation. The network embeddings are clustered using a simple algorithm such as $k$-NN for highly accurate identification, thus eliminating the need to retrain the network for enrolling new individuals. We evaluate two backbone architectures, ResNet, as previously used to identify Holstein Friesians using RGB images, and PointNet, which is specialised to operate on 3D point clouds. We also present CowDepth2023, a new dataset containing 21,490 synchronised colour-depth image pairs of 99 cows, to evaluate the backbones. Both ResNet and PointNet architectures, which consume depth maps and point clouds, respectively, led to high accuracy that is on par with the coat pattern-based backbone.
Evolving Semantic Communication with Generative Model
Mar 29, 2024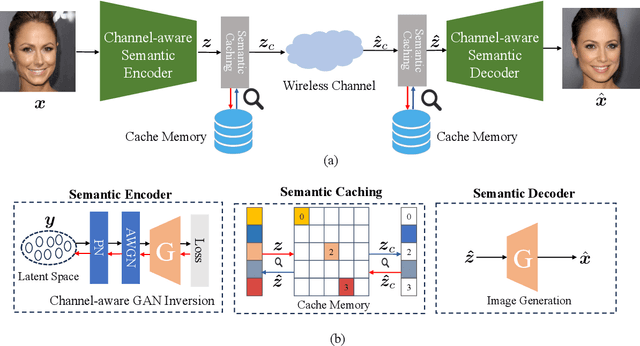
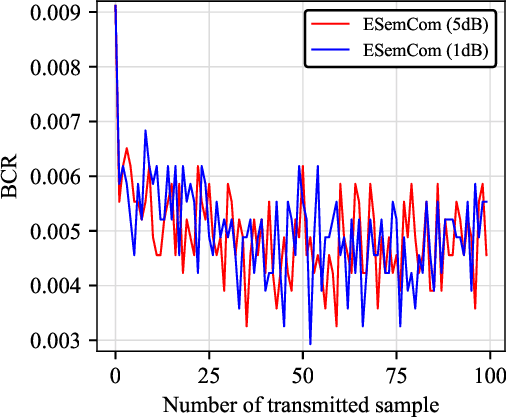
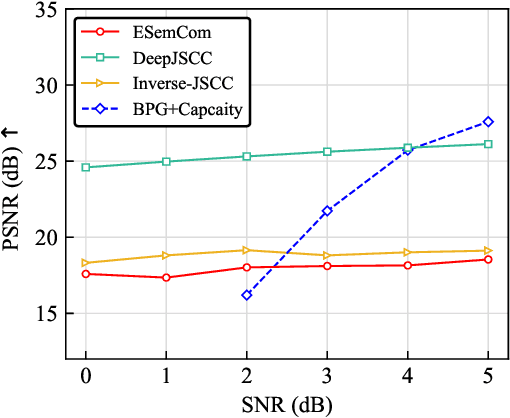
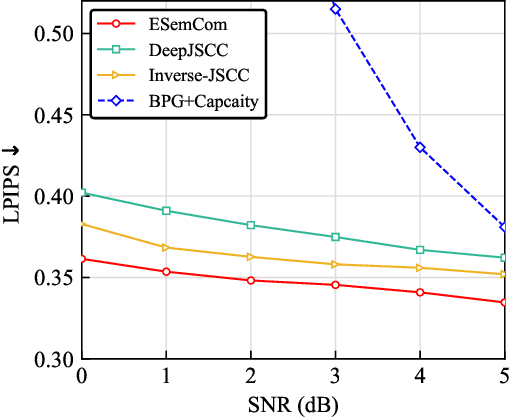
Recently, learning-based semantic communication (SemCom) has emerged as a promising approach in the upcoming 6G network and researchers have made remarkable efforts in this field. However, existing works have yet to fully explore the advantages of the evolving nature of learning-based systems, where knowledge accumulates during transmission have the potential to enhance system performance. In this paper, we explore an evolving semantic communication system for image transmission, referred to as ESemCom, with the capability to continuously enhance transmission efficiency. The system features a novel channel-aware semantic encoder that utilizes a pre-trained Semantic StyleGAN to extract the channel-correlated latent variables consisting of serval semantic vectors from the input images, which can be directly transmitted over a noisy channel without further channel coding. Moreover, we introduce a semantic caching mechanism that dynamically stores the transmitted semantic vectors in the local caching memory of both the transmitter and receiver. The cached semantic vectors are then exploited to eliminate the need to transmit similar codes in subsequent transmission, thus further reducing communication overhead. Simulation results highlight the evolving performance of the proposed system in terms of transmission efficiency, achieving superior perceptual quality with an average bandwidth compression ratio (BCR) of 1/192 for a sequence of 100 testing images compared to DeepJSCC and Inverse JSCC with the same BCR. Code of this paper is available at \url{https://github.com/recusant7/GAN_SeCom}.
H2RSVLM: Towards Helpful and Honest Remote Sensing Large Vision Language Model
Mar 29, 2024
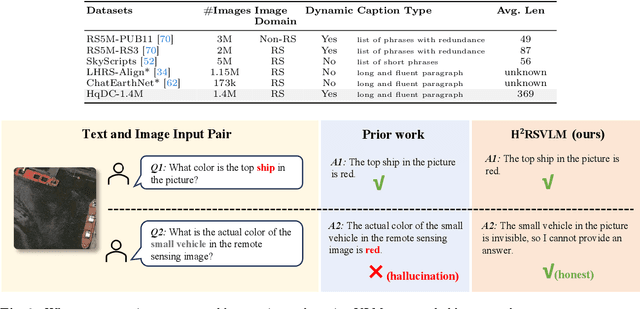
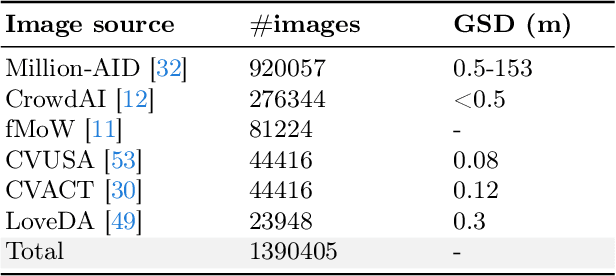

The generic large Vision-Language Models (VLMs) is rapidly developing, but still perform poorly in Remote Sensing (RS) domain, which is due to the unique and specialized nature of RS imagery and the comparatively limited spatial perception of current VLMs. Existing Remote Sensing specific Vision Language Models (RSVLMs) still have considerable potential for improvement, primarily owing to the lack of large-scale, high-quality RS vision-language datasets. We constructed HqDC-1.4M, the large scale High quality and Detailed Captions for RS images, containing 1.4 million image-caption pairs, which not only enhance the RSVLM's understanding of RS images but also significantly improve the model's spatial perception abilities, such as localization and counting, thereby increasing the helpfulness of the RSVLM. Moreover, to address the inevitable "hallucination" problem in RSVLM, we developed RSSA, the first dataset aimed at enhancing the Self-Awareness capability of RSVLMs. By incorporating a variety of unanswerable questions into typical RS visual question-answering tasks, RSSA effectively improves the truthfulness and reduces the hallucinations of the model's outputs, thereby enhancing the honesty of the RSVLM. Based on these datasets, we proposed the H2RSVLM, the Helpful and Honest Remote Sensing Vision Language Model. H2RSVLM has achieved outstanding performance on multiple RS public datasets and is capable of recognizing and refusing to answer the unanswerable questions, effectively mitigating the incorrect generations. We will release the code, data and model weights at https://github.com/opendatalab/H2RSVLM .
Self-Adaptive Reality-Guided Diffusion for Artifact-Free Super-Resolution
Mar 25, 2024Artifact-free super-resolution (SR) aims to translate low-resolution images into their high-resolution counterparts with a strict integrity of the original content, eliminating any distortions or synthetic details. While traditional diffusion-based SR techniques have demonstrated remarkable abilities to enhance image detail, they are prone to artifact introduction during iterative procedures. Such artifacts, ranging from trivial noise to unauthentic textures, deviate from the true structure of the source image, thus challenging the integrity of the super-resolution process. In this work, we propose Self-Adaptive Reality-Guided Diffusion (SARGD), a training-free method that delves into the latent space to effectively identify and mitigate the propagation of artifacts. Our SARGD begins by using an artifact detector to identify implausible pixels, creating a binary mask that highlights artifacts. Following this, the Reality Guidance Refinement (RGR) process refines artifacts by integrating this mask with realistic latent representations, improving alignment with the original image. Nonetheless, initial realistic-latent representations from lower-quality images result in over-smoothing in the final output. To address this, we introduce a Self-Adaptive Guidance (SAG) mechanism. It dynamically computes a reality score, enhancing the sharpness of the realistic latent. These alternating mechanisms collectively achieve artifact-free super-resolution. Extensive experiments demonstrate the superiority of our method, delivering detailed artifact-free high-resolution images while reducing sampling steps by 2X. We release our code at https://github.com/ProAirVerse/Self-Adaptive-Guidance-Diffusion.git.
Predicting risk of cardiovascular disease using retinal OCT imaging
Mar 26, 2024We investigated the potential of optical coherence tomography (OCT) as an additional imaging technique to predict future cardiovascular disease (CVD). We utilised a self-supervised deep learning approach based on Variational Autoencoders (VAE) to learn low-dimensional representations of high-dimensional 3D OCT images and to capture distinct characteristics of different retinal layers within the OCT image. A Random Forest (RF) classifier was subsequently trained using the learned latent features and participant demographic and clinical data, to differentiate between patients at risk of CVD events (MI or stroke) and non-CVD cases. Our predictive model, trained on multimodal data, was assessed based on its ability to correctly identify individuals likely to suffer from a CVD event(MI or stroke), within a 5-year interval after image acquisition. Our self-supervised VAE feature selection and multimodal Random Forest classifier differentiate between patients at risk of future CVD events and the control group with an AUC of 0.75, outperforming the clinically established QRISK3 score (AUC= 0.597). The choroidal layer visible in OCT images was identified as an important predictor of future CVD events using a novel approach to model explanability. Retinal OCT imaging provides a cost-effective and non-invasive alternative to predict the risk of cardiovascular disease and is readily accessible in optometry practices and hospitals.
Neural Clustering based Visual Representation Learning
Mar 26, 2024We investigate a fundamental aspect of machine vision: the measurement of features, by revisiting clustering, one of the most classic approaches in machine learning and data analysis. Existing visual feature extractors, including ConvNets, ViTs, and MLPs, represent an image as rectangular regions. Though prevalent, such a grid-style paradigm is built upon engineering practice and lacks explicit modeling of data distribution. In this work, we propose feature extraction with clustering (FEC), a conceptually elegant yet surprisingly ad-hoc interpretable neural clustering framework, which views feature extraction as a process of selecting representatives from data and thus automatically captures the underlying data distribution. Given an image, FEC alternates between grouping pixels into individual clusters to abstract representatives and updating the deep features of pixels with current representatives. Such an iterative working mechanism is implemented in the form of several neural layers and the final representatives can be used for downstream tasks. The cluster assignments across layers, which can be viewed and inspected by humans, make the forward process of FEC fully transparent and empower it with promising ad-hoc interpretability. Extensive experiments on various visual recognition models and tasks verify the effectiveness, generality, and interpretability of FEC. We expect this work will provoke a rethink of the current de facto grid-style paradigm.
Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising
Mar 15, 2024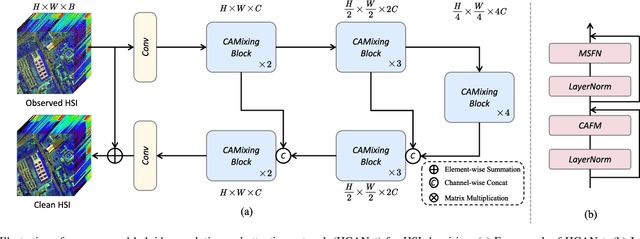
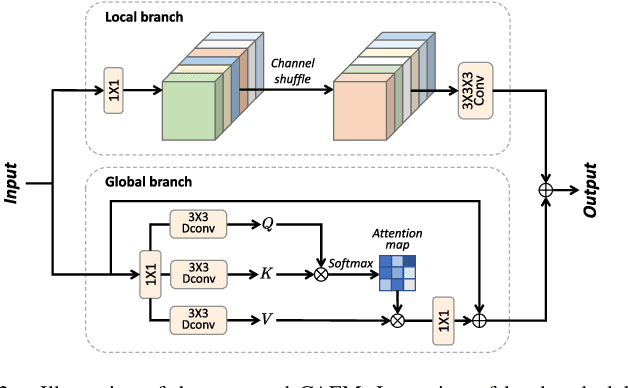
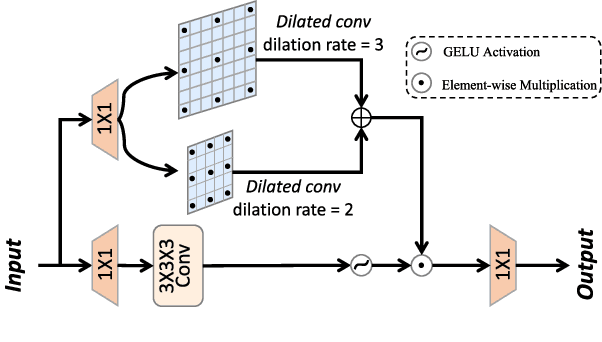

Hyperspectral image (HSI) denoising is critical for the effective analysis and interpretation of hyperspectral data. However, simultaneously modeling global and local features is rarely explored to enhance HSI denoising. In this letter, we propose a hybrid convolution and attention network (HCANet), which leverages both the strengths of convolution neural networks (CNNs) and Transformers. To enhance the modeling of both global and local features, we have devised a convolution and attention fusion module aimed at capturing long-range dependencies and neighborhood spectral correlations. Furthermore, to improve multi-scale information aggregation, we design a multi-scale feed-forward network to enhance denoising performance by extracting features at different scales. Experimental results on mainstream HSI datasets demonstrate the rationality and effectiveness of the proposed HCANet. The proposed model is effective in removing various types of complex noise. Our codes are available at \url{https://github.com/summitgao/HCANet}.
ContourDiff: Unpaired Image Translation with Contour-Guided Diffusion Models
Mar 16, 2024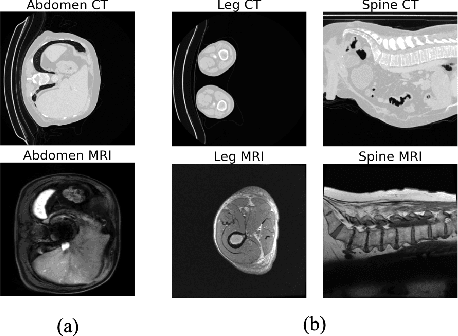
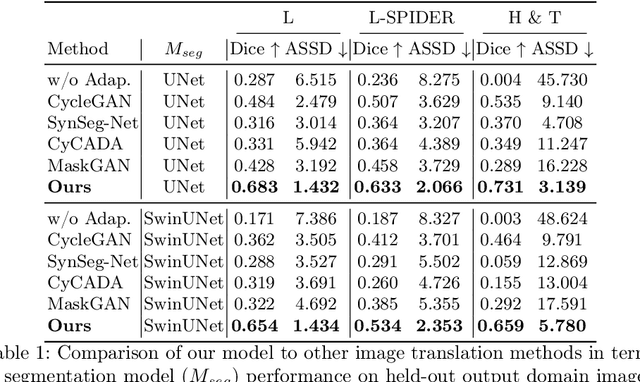
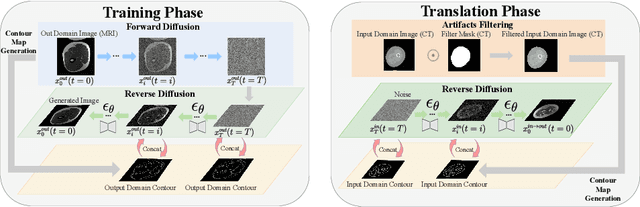
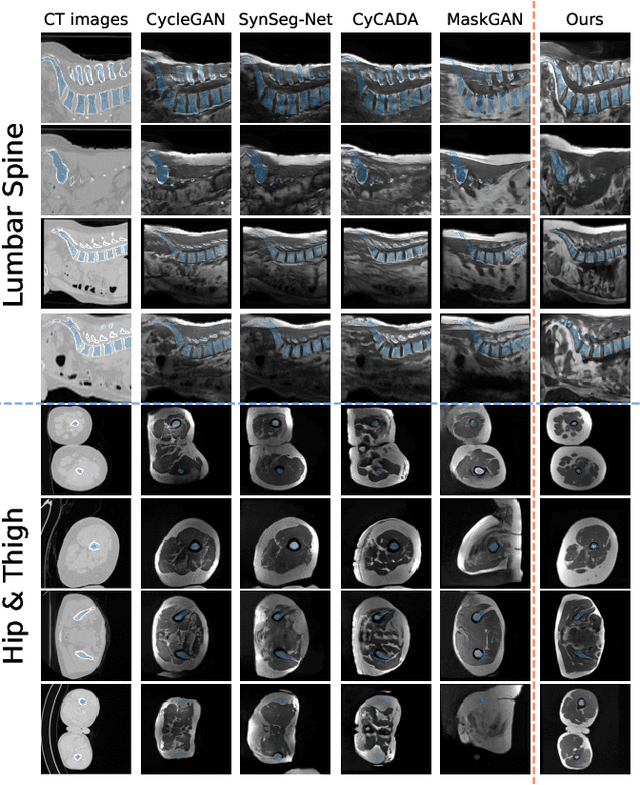
Accurately translating medical images across different modalities (e.g., CT to MRI) has numerous downstream clinical and machine learning applications. While several methods have been proposed to achieve this, they often prioritize perceptual quality with respect to output domain features over preserving anatomical fidelity. However, maintaining anatomy during translation is essential for many tasks, e.g., when leveraging masks from the input domain to develop a segmentation model with images translated to the output domain. To address these challenges, we propose ContourDiff, a novel framework that leverages domain-invariant anatomical contour representations of images. These representations are simple to extract from images, yet form precise spatial constraints on their anatomical content. We introduce a diffusion model that converts contour representations of images from arbitrary input domains into images in the output domain of interest. By applying the contour as a constraint at every diffusion sampling step, we ensure the preservation of anatomical content. We evaluate our method by training a segmentation model on images translated from CT to MRI with their original CT masks and testing its performance on real MRIs. Our method outperforms other unpaired image translation methods by a significant margin, furthermore without the need to access any input domain information during training.
Texture image retrieval using a classification and contourlet-based features
Mar 10, 2024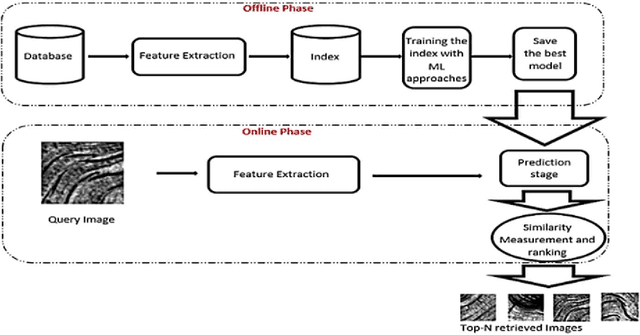
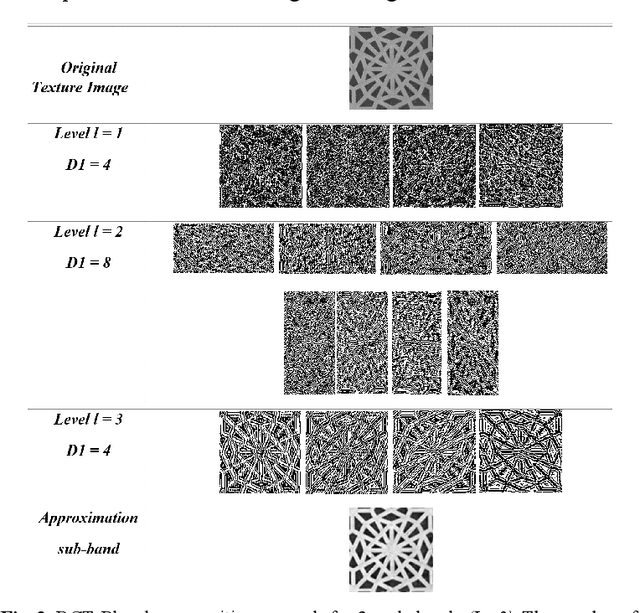


In this paper, we propose a new framework for improving Content Based Image Retrieval (CBIR) for texture images. This is achieved by using a new image representation based on the RCT-Plus transform which is a novel variant of the Redundant Contourlet transform that extracts a richer directional information in the image. Moreover, the process of image search is improved through a learning-based approach where the images of the database are classified using an adapted similarity metric to the statistical modeling of the RCT-Plus transform. A query is then first classified to select the best texture class after which the retained class images are ranked to select top ones. By this, we have achieved significant improvements in the retrieval rates compared to previous CBIR schemes.