 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCameraNoise: Enabling Faithful Camera Control in Video Diffusion through Geometry-Flow-Guided Noise Warping
May 29, 2026Precise camera pose control is critical for video diffusion, yet maintaining geometric consistency remains a challenge. Existing methods that directly inject numerical camera parameters into the diffusion backbone often fail to bridge the gap between abstract coordinates and visual content, leading to structural distortions. To address this issue, we propose CameraNoise, a flow-to-noise warping method that encodes camera motion into a temporally coherent stochastic representation. Unlike conventional conditioning, CameraNoise embeds camera poses directly into the noise space. This decouples motion from scene appearance while faithfully preserving trajectory dynamics. Specifically, we introduce a novel Geometry-guided Reprojection Flow and a noise warping algorithm, which jointly preserve the Gaussian prior of diffusion and ensure consistent noise propagation under camera transformations. By integrating CameraNoise into the diffusion process, our framework delivers stable, high-fidelity videos. Extensive experiments demonstrate that our approach significantly outperforms prior methods in both visual quality and trajectory faithfulness. The project page and code are available at: https://gulucaptain.github.io/CameraNoise/.
* 28 pages, 16 figures
CT-1: Vision-Language-Camera Models Transfer Spatial Reasoning Knowledge to Camera-Controllable Video Generation
Apr 10, 2026Camera-controllable video generation aims to synthesize videos with flexible and physically plausible camera movements. However, existing methods either provide imprecise camera control from text prompts or rely on labor-intensive manual camera trajectory parameters, limiting their use in automated scenarios. To address these issues, we propose a novel Vision-Language-Camera model, termed CT-1 (Camera Transformer 1), a specialized model designed to transfer spatial reasoning knowledge to video generation by accurately estimating camera trajectories. Built upon vision-language modules and a Diffusion Transformer model, CT-1 employs a Wavelet-based Regularization Loss in the frequency domain to effectively learn complex camera trajectory distributions. These trajectories are integrated into a video diffusion model to enable spatially aware camera control that aligns with user intentions. To facilitate the training of CT-1, we design a dedicated data curation pipeline and construct CT-200K, a large-scale dataset containing over 47M frames. Experimental results demonstrate that our framework successfully bridges the gap between spatial reasoning and video synthesis, yielding faithful and high-quality camera-controllable videos and improving camera control accuracy by 25.7% over prior methods.
DynamiCtrl: Rethinking the Basic Structure and the Role of Text for High-quality Human Image Animation
Mar 27, 2025



Human image animation has recently gained significant attention due to advancements in generative models. However, existing methods still face two major challenges: (1) architectural limitations, most models rely on U-Net, which underperforms compared to the MM-DiT; and (2) the neglect of textual information, which can enhance controllability. In this work, we introduce DynamiCtrl, a novel framework that not only explores different pose-guided control structures in MM-DiT, but also reemphasizes the crucial role of text in this task. Specifically, we employ a Shared VAE encoder for both reference images and driving pose videos, eliminating the need for an additional pose encoder and simplifying the overall framework. To incorporate pose features into the full attention blocks, we propose Pose-adaptive Layer Norm (PadaLN), which utilizes adaptive layer normalization to encode sparse pose features. The encoded features are directly added to the visual input, preserving the spatiotemporal consistency of the backbone while effectively introducing pose control into MM-DiT. Furthermore, within the full attention mechanism, we align textual and visual features to enhance controllability. By leveraging text, we not only enable fine-grained control over the generated content, but also, for the first time, achieve simultaneous control over both background and motion. Experimental results verify the superiority of DynamiCtrl on benchmark datasets, demonstrating its strong identity preservation, heterogeneous character driving, background controllability, and high-quality synthesis. The project page is available at https://gulucaptain.github.io/DynamiCtrl/.
Self-Adaptive Reality-Guided Diffusion for Artifact-Free Super-Resolution
Mar 25, 2024



Artifact-free super-resolution (SR) aims to translate low-resolution images into their high-resolution counterparts with a strict integrity of the original content, eliminating any distortions or synthetic details. While traditional diffusion-based SR techniques have demonstrated remarkable abilities to enhance image detail, they are prone to artifact introduction during iterative procedures. Such artifacts, ranging from trivial noise to unauthentic textures, deviate from the true structure of the source image, thus challenging the integrity of the super-resolution process. In this work, we propose Self-Adaptive Reality-Guided Diffusion (SARGD), a training-free method that delves into the latent space to effectively identify and mitigate the propagation of artifacts. Our SARGD begins by using an artifact detector to identify implausible pixels, creating a binary mask that highlights artifacts. Following this, the Reality Guidance Refinement (RGR) process refines artifacts by integrating this mask with realistic latent representations, improving alignment with the original image. Nonetheless, initial realistic-latent representations from lower-quality images result in over-smoothing in the final output. To address this, we introduce a Self-Adaptive Guidance (SAG) mechanism. It dynamically computes a reality score, enhancing the sharpness of the realistic latent. These alternating mechanisms collectively achieve artifact-free super-resolution. Extensive experiments demonstrate the superiority of our method, delivering detailed artifact-free high-resolution images while reducing sampling steps by 2X. We release our code at https://github.com/ProAirVerse/Self-Adaptive-Guidance-Diffusion.git.
Any-Size-Diffusion: Toward Efficient Text-Driven Synthesis for Any-Size HD Images
Sep 11, 2023



Stable diffusion, a generative model used in text-to-image synthesis, frequently encounters resolution-induced composition problems when generating images of varying sizes. This issue primarily stems from the model being trained on pairs of single-scale images and their corresponding text descriptions. Moreover, direct training on images of unlimited sizes is unfeasible, as it would require an immense number of text-image pairs and entail substantial computational expenses. To overcome these challenges, we propose a two-stage pipeline named Any-Size-Diffusion (ASD), designed to efficiently generate well-composed images of any size, while minimizing the need for high-memory GPU resources. Specifically, the initial stage, dubbed Any Ratio Adaptability Diffusion (ARAD), leverages a selected set of images with a restricted range of ratios to optimize the text-conditional diffusion model, thereby improving its ability to adjust composition to accommodate diverse image sizes. To support the creation of images at any desired size, we further introduce a technique called Fast Seamless Tiled Diffusion (FSTD) at the subsequent stage. This method allows for the rapid enlargement of the ASD output to any high-resolution size, avoiding seaming artifacts or memory overloads. Experimental results on the LAION-COCO and MM-CelebA-HQ benchmarks demonstrate that ASD can produce well-structured images of arbitrary sizes, cutting down the inference time by 2x compared to the traditional tiled algorithm.
Decoupled Multi-task Learning with Cyclical Self-Regulation for Face Parsing
Mar 28, 2022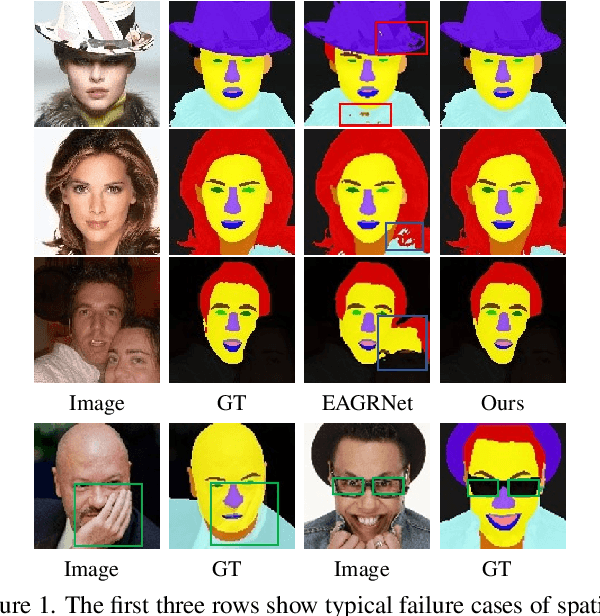
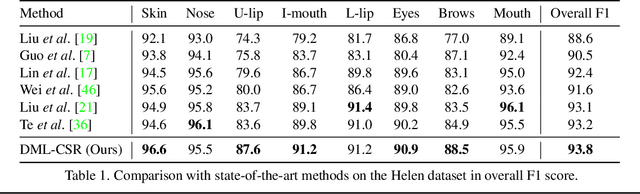
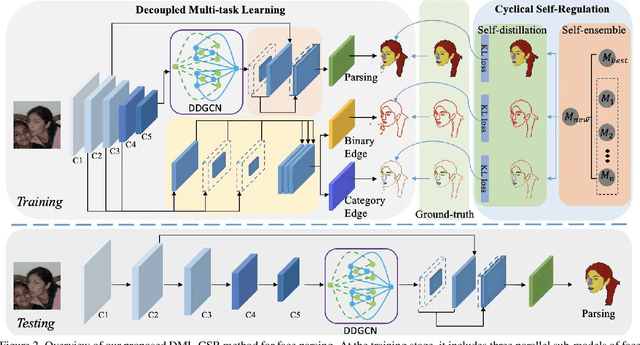
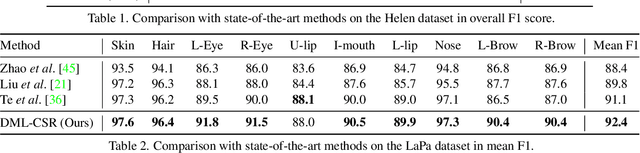
This paper probes intrinsic factors behind typical failure cases (e.g. spatial inconsistency and boundary confusion) produced by the existing state-of-the-art method in face parsing. To tackle these problems, we propose a novel Decoupled Multi-task Learning with Cyclical Self-Regulation (DML-CSR) for face parsing. Specifically, DML-CSR designs a multi-task model which comprises face parsing, binary edge, and category edge detection. These tasks only share low-level encoder weights without high-level interactions between each other, enabling to decouple auxiliary modules from the whole network at the inference stage. To address spatial inconsistency, we develop a dynamic dual graph convolutional network to capture global contextual information without using any extra pooling operation. To handle boundary confusion in both single and multiple face scenarios, we exploit binary and category edge detection to jointly obtain generic geometric structure and fine-grained semantic clues of human faces. Besides, to prevent noisy labels from degrading model generalization during training, cyclical self-regulation is proposed to self-ensemble several model instances to get a new model and the resulting model then is used to self-distill subsequent models, through alternating iterations. Experiments show that our method achieves the new state-of-the-art performance on the Helen, CelebAMask-HQ, and Lapa datasets. The source code is available at https://github.com/deepinsight/insightface/tree/master/parsing/dml_csr.