 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DreamCatcher: Revealing the Language of the Brain with fMRI using GPT Embedding
Jun 16, 2023
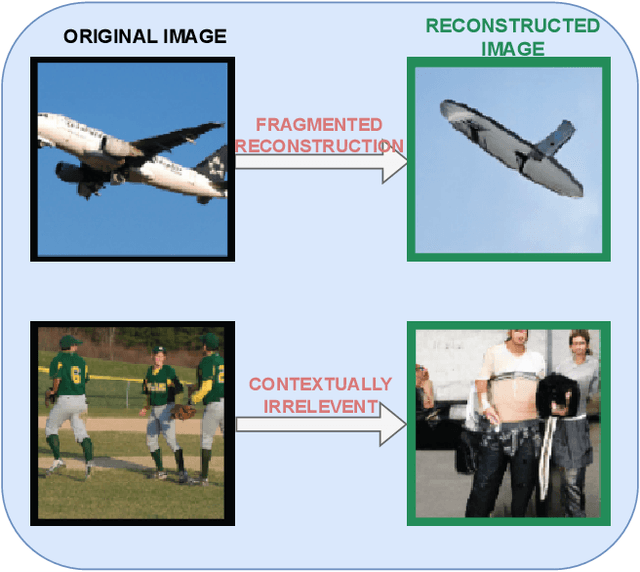

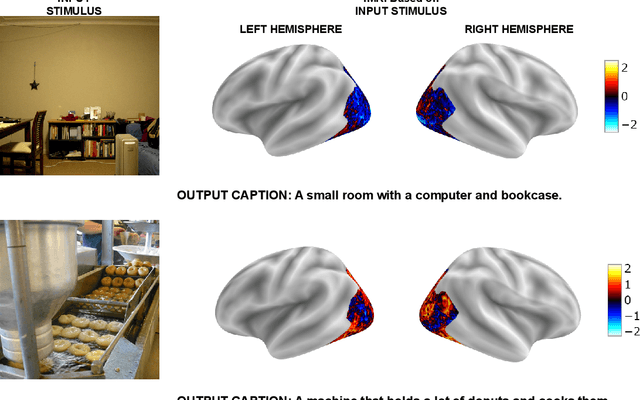
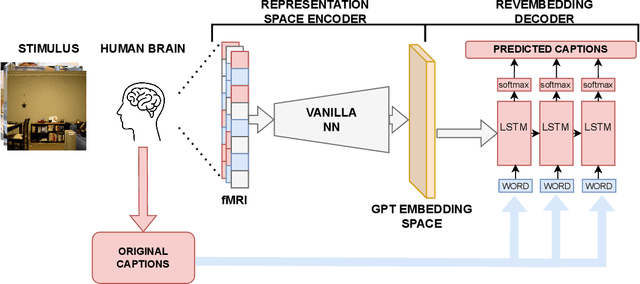
The human brain possesses remarkable abilities in visual processing, including image recognition and scene summarization. Efforts have been made to understand the cognitive capacities of the visual brain, but a comprehensive understanding of the underlying mechanisms still needs to be discovered. Advancements in brain decoding techniques have led to sophisticated approaches like fMRI-to-Image reconstruction, which has implications for cognitive neuroscience and medical imaging. However, challenges persist in fMRI-to-image reconstruction, such as incorporating global context and contextual information. In this article, we propose fMRI captioning, where captions are generated based on fMRI data to gain insight into the neural correlates of visual perception. This research presents DreamCatcher, a novel framework for fMRI captioning. DreamCatcher consists of the Representation Space Encoder (RSE) and the RevEmbedding Decoder, which transform fMRI vectors into a latent space and generate captions, respectively. We evaluated the framework through visualization, dataset training, and testing on subjects, demonstrating strong performance. fMRI-based captioning has diverse applications, including understanding neural mechanisms, Human-Computer Interaction, and enhancing learning and training processes.
DIRE for Diffusion-Generated Image Detection
Mar 16, 2023
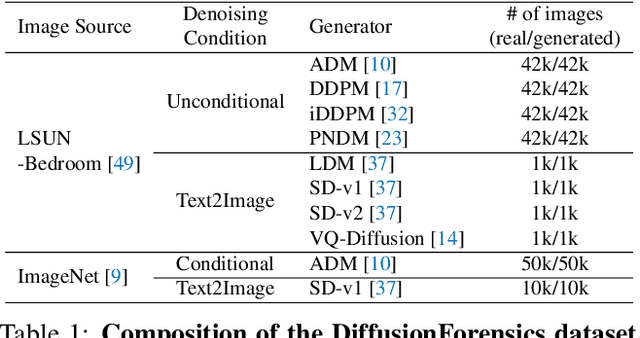

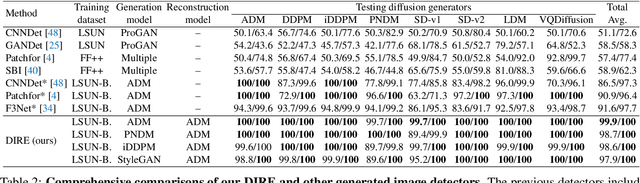
Diffusion models have shown remarkable success in visual synthesis, but have also raised concerns about potential abuse for malicious purposes. In this paper, we seek to build a detector for telling apart real images from diffusion-generated images. We find that existing detectors struggle to detect images generated by diffusion models, even if we include generated images from a specific diffusion model in their training data. To address this issue, we propose a novel image representation called DIffusion Reconstruction Error (DIRE), which measures the error between an input image and its reconstruction counterpart by a pre-trained diffusion model. We observe that diffusion-generated images can be approximately reconstructed by a diffusion model while real images cannot. It provides a hint that DIRE can serve as a bridge to distinguish generated and real images. DIRE provides an effective way to detect images generated by most diffusion models, and it is general for detecting generated images from unseen diffusion models and robust to various perturbations. Furthermore, we establish a comprehensive diffusion-generated benchmark including images generated by eight diffusion models to evaluate the performance of diffusion-generated image detectors. Extensive experiments on our collected benchmark demonstrate that DIRE exhibits superiority over previous generated-image detectors. The code and dataset are available at https://github.com/ZhendongWang6/DIRE.
AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation
Apr 04, 2023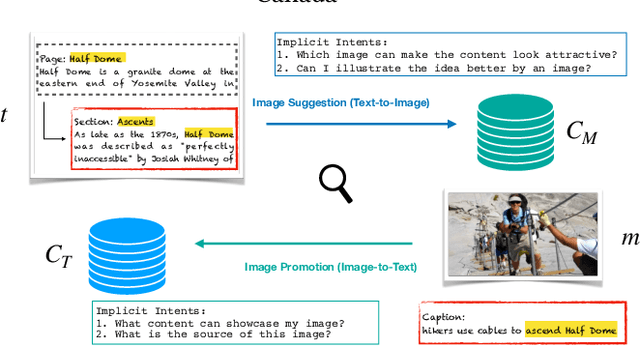
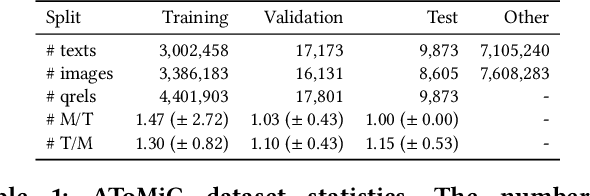
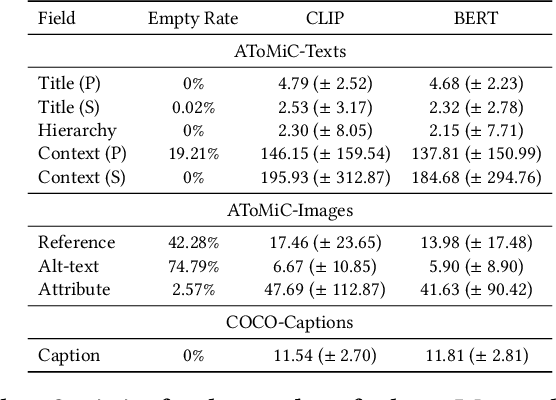
This paper presents the AToMiC (Authoring Tools for Multimedia Content) dataset, designed to advance research in image/text cross-modal retrieval. While vision-language pretrained transformers have led to significant improvements in retrieval effectiveness, existing research has relied on image-caption datasets that feature only simplistic image-text relationships and underspecified user models of retrieval tasks. To address the gap between these oversimplified settings and real-world applications for multimedia content creation, we introduce a new approach for building retrieval test collections. We leverage hierarchical structures and diverse domains of texts, styles, and types of images, as well as large-scale image-document associations embedded in Wikipedia. We formulate two tasks based on a realistic user model and validate our dataset through retrieval experiments using baseline models. AToMiC offers a testbed for scalable, diverse, and reproducible multimedia retrieval research. Finally, the dataset provides the basis for a dedicated track at the 2023 Text Retrieval Conference (TREC), and is publicly available at https://github.com/TREC-AToMiC/AToMiC.
AG3D: Learning to Generate 3D Avatars from 2D Image Collections
May 03, 2023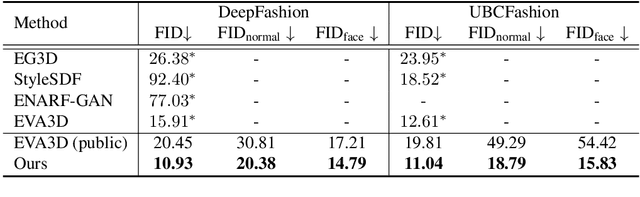
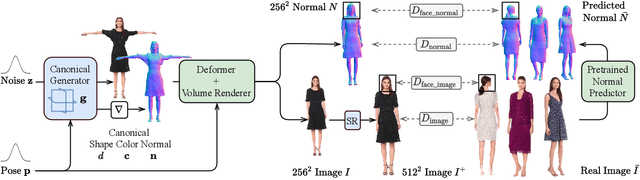
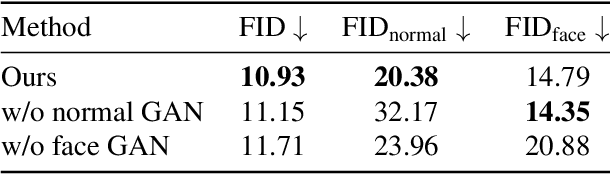

While progress in 2D generative models of human appearance has been rapid, many applications require 3D avatars that can be animated and rendered. Unfortunately, most existing methods for learning generative models of 3D humans with diverse shape and appearance require 3D training data, which is limited and expensive to acquire. The key to progress is hence to learn generative models of 3D avatars from abundant unstructured 2D image collections. However, learning realistic and complete 3D appearance and geometry in this under-constrained setting remains challenging, especially in the presence of loose clothing such as dresses. In this paper, we propose a new adversarial generative model of realistic 3D people from 2D images. Our method captures shape and deformation of the body and loose clothing by adopting a holistic 3D generator and integrating an efficient and flexible articulation module. To improve realism, we train our model using multiple discriminators while also integrating geometric cues in the form of predicted 2D normal maps. We experimentally find that our method outperforms previous 3D- and articulation-aware methods in terms of geometry and appearance. We validate the effectiveness of our model and the importance of each component via systematic ablation studies.
LegoNet: Alternating Model Blocks for Medical Image Segmentation
Jun 06, 2023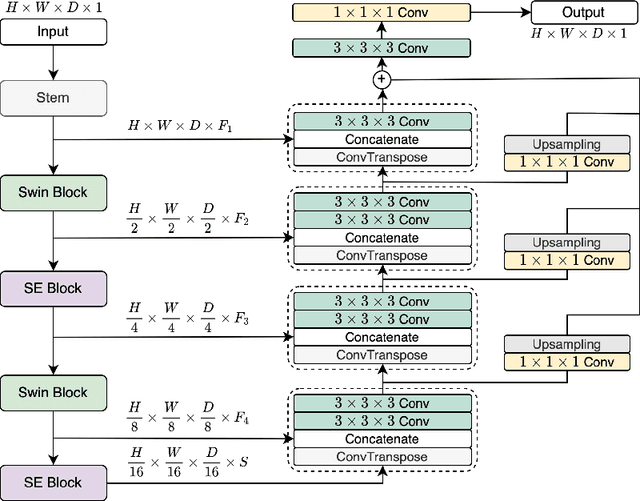
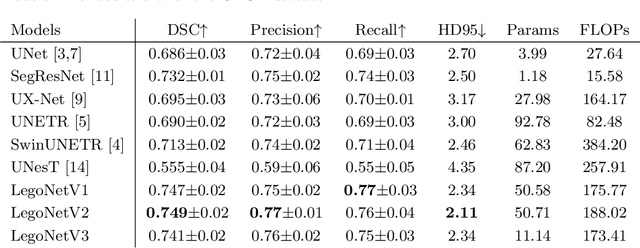

Since the emergence of convolutional neural networks (CNNs), and later vision transformers (ViTs), the common paradigm for model development has always been using a set of identical block types with varying parameters/hyper-parameters. To leverage the benefits of different architectural designs (e.g. CNNs and ViTs), we propose to alternate structurally different types of blocks to generate a new architecture, mimicking how Lego blocks can be assembled together. Using two CNN-based and one SwinViT-based blocks, we investigate three variations to the so-called LegoNet that applies the new concept of block alternation for the segmentation task in medical imaging. We also study a new clinical problem which has not been investigated before, namely the right internal mammary artery (RIMA) and perivascular space segmentation from computed tomography angiography (CTA) which has demonstrated a prognostic value to major cardiovascular outcomes. We compare the model performance against popular CNN and ViT architectures using two large datasets (e.g. achieving 0.749 dice similarity coefficient (DSC) on the larger dataset). We evaluate the performance of the model on three external testing cohorts as well, where an expert clinician made corrections to the model segmented results (DSC>0.90 for the three cohorts). To assess our proposed model for suitability in clinical use, we perform intra- and inter-observer variability analysis. Finally, we investigate a joint self-supervised learning approach to assess its impact on model performance. The code and the pretrained model weights will be available upon acceptance.
TIFA: Accurate and Interpretable Text-to-Image Faithfulness Evaluation with Question Answering
Mar 28, 2023
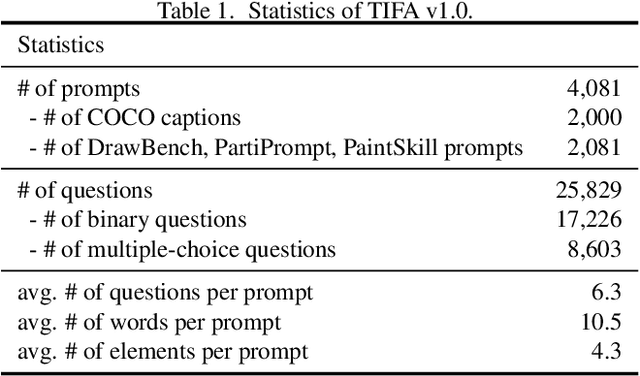
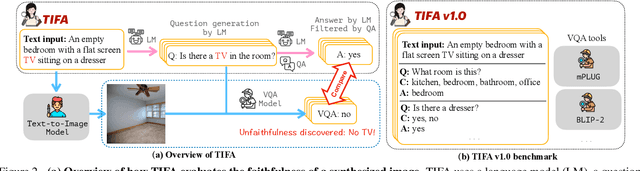
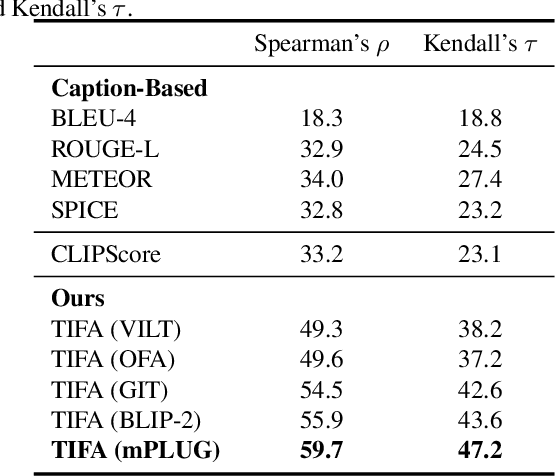
Despite thousands of researchers, engineers, and artists actively working on improving text-to-image generation models, systems often fail to produce images that accurately align with the text inputs. We introduce TIFA (Text-to-Image Faithfulness evaluation with question Answering), an automatic evaluation metric that measures the faithfulness of a generated image to its text input via visual question answering (VQA). Specifically, given a text input, we automatically generate several question-answer pairs using a language model. We calculate image faithfulness by checking whether existing VQA models can answer these questions using the generated image. TIFA is a reference-free metric that allows for fine-grained and interpretable evaluations of generated images. TIFA also has better correlations with human judgments than existing metrics. Based on this approach, we introduce TIFA v1.0, a benchmark consisting of 4K diverse text inputs and 25K questions across 12 categories (object, counting, etc.). We present a comprehensive evaluation of existing text-to-image models using TIFA v1.0 and highlight the limitations and challenges of current models. For instance, we find that current text-to-image models, despite doing well on color and material, still struggle in counting, spatial relations, and composing multiple objects. We hope our benchmark will help carefully measure the research progress in text-to-image synthesis and provide valuable insights for further research.
Self-Consuming Generative Models Go MAD
Jul 04, 2023

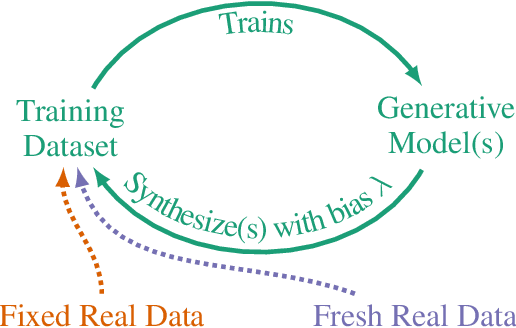
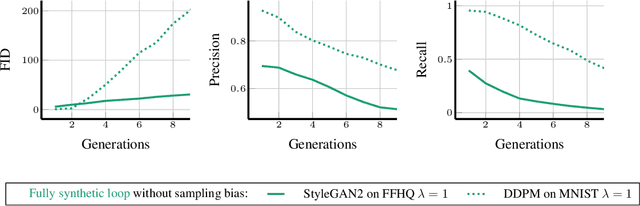
Seismic advances in generative AI algorithms for imagery, text, and other data types has led to the temptation to use synthetic data to train next-generation models. Repeating this process creates an autophagous (self-consuming) loop whose properties are poorly understood. We conduct a thorough analytical and empirical analysis using state-of-the-art generative image models of three families of autophagous loops that differ in how fixed or fresh real training data is available through the generations of training and in whether the samples from previous generation models have been biased to trade off data quality versus diversity. Our primary conclusion across all scenarios is that without enough fresh real data in each generation of an autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease. We term this condition Model Autophagy Disorder (MAD), making analogy to mad cow disease.
3D Cinemagraphy from a Single Image
Mar 10, 2023
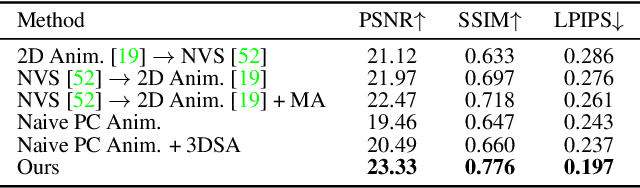
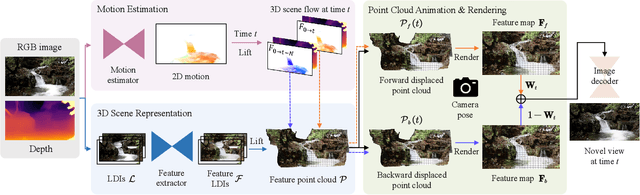

We present 3D Cinemagraphy, a new technique that marries 2D image animation with 3D photography. Given a single still image as input, our goal is to generate a video that contains both visual content animation and camera motion. We empirically find that naively combining existing 2D image animation and 3D photography methods leads to obvious artifacts or inconsistent animation. Our key insight is that representing and animating the scene in 3D space offers a natural solution to this task. To this end, we first convert the input image into feature-based layered depth images using predicted depth values, followed by unprojecting them to a feature point cloud. To animate the scene, we perform motion estimation and lift the 2D motion into the 3D scene flow. Finally, to resolve the problem of hole emergence as points move forward, we propose to bidirectionally displace the point cloud as per the scene flow and synthesize novel views by separately projecting them into target image planes and blending the results. Extensive experiments demonstrate the effectiveness of our method. A user study is also conducted to validate the compelling rendering results of our method.
Generation of Radiology Findings in Chest X-Ray by Leveraging Collaborative Knowledge
Jun 18, 2023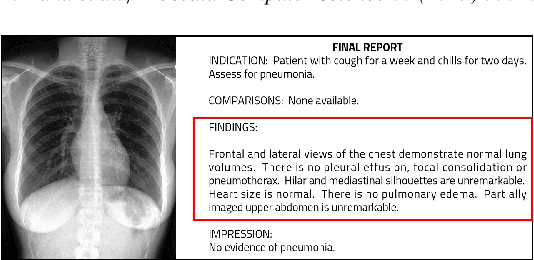

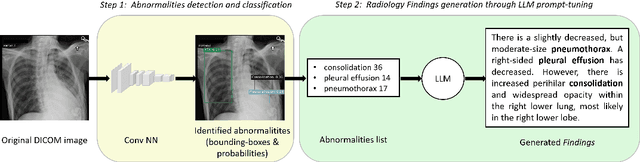
Among all the sub-sections in a typical radiology report, the Clinical Indications, Findings, and Impression often reflect important details about the health status of a patient. The information included in Impression is also often covered in Findings. While Findings and Impression can be deduced by inspecting the image, Clinical Indications often require additional context. The cognitive task of interpreting medical images remains the most critical and often time-consuming step in the radiology workflow. Instead of generating an end-to-end radiology report, in this paper, we focus on generating the Findings from automated interpretation of medical images, specifically chest X-rays (CXRs). Thus, this work focuses on reducing the workload of radiologists who spend most of their time either writing or narrating the Findings. Unlike past research, which addresses radiology report generation as a single-step image captioning task, we have further taken into consideration the complexity of interpreting CXR images and propose a two-step approach: (a) detecting the regions with abnormalities in the image, and (b) generating relevant text for regions with abnormalities by employing a generative large language model (LLM). This two-step approach introduces a layer of interpretability and aligns the framework with the systematic reasoning that radiologists use when reviewing a CXR.
* Information Technology and Quantitative Management (ITQM 2023)
Zero-shot Medical Image Translation via Frequency-Guided Diffusion Models
Apr 05, 2023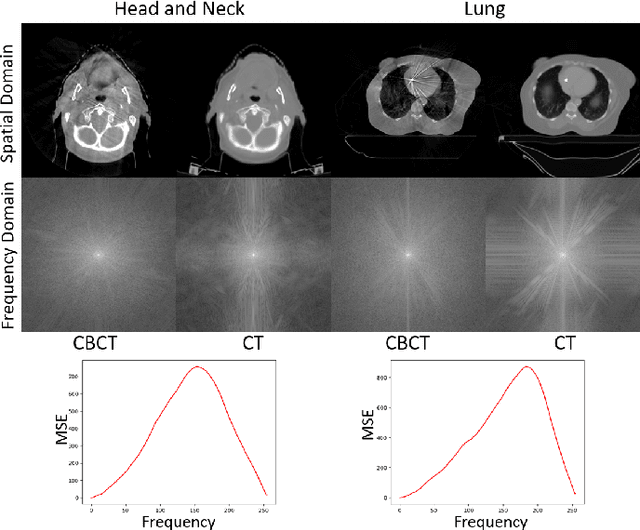

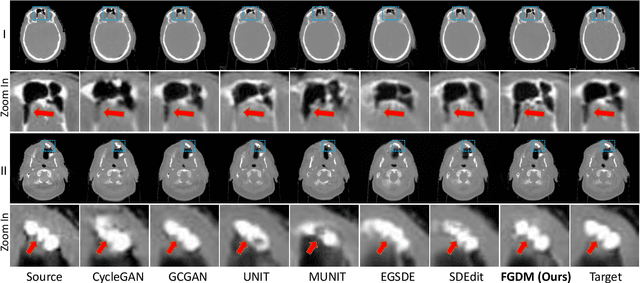
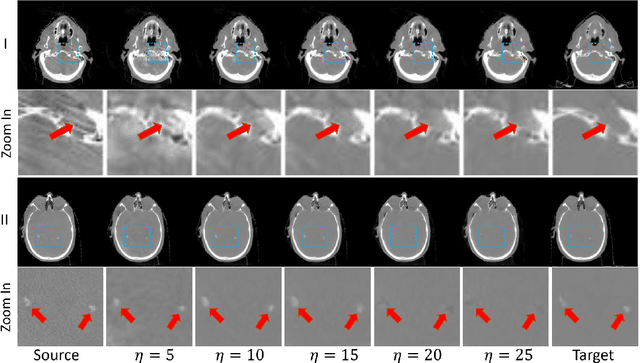
Recently, the diffusion model has emerged as a superior generative model that can produce high-quality images with excellent realism. There is a growing interest in applying diffusion models to image translation tasks. However, for medical image translation, the existing diffusion models are deficient in accurately retaining structural information since the structure details of source domain images are lost during the forward diffusion process and cannot be fully recovered through learned reverse diffusion, while the integrity of anatomical structures is extremely important in medical images. Training and conditioning diffusion models using paired source and target images with matching anatomy can help. However, such paired data are very difficult and costly to obtain, and may also reduce the robustness of the developed model to out-of-distribution testing data. We propose a frequency-guided diffusion model (FGDM) that employs frequency-domain filters to guide the diffusion model for structure-preserving image translation. Based on its design, FGDM allows zero-shot learning, as it can be trained solely on the data from the target domain, and used directly for source-to-target domain translation without any exposure to the source-domain data during training. We trained FGDM solely on the head-and-neck CT data, and evaluated it on both head-and-neck and lung cone-beam CT (CBCT)-to-CT translation tasks. FGDM outperformed the state-of-the-art methods (GAN-based, VAE-based, and diffusion-based) in all metrics, showing its significant advantages in zero-shot medical image translation.