 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Synthetic Data Is Yours to Learn From
May 29, 2026Can a language model improve from plain text sampled from itself, with no prompts, no teacher, no verifier, and no reward model? Yes, but only when the synthetic corpus is compatible with the student, a relational property of the source-student pair rather than an intrinsic property of the data. We call this the latent capability resurfacing hypothesis: weak self-training can amplify capabilities already present in the pretrained model, but only under this compatibility condition. We study this in the minimal setting of prompt-free unconditional self-training, where base language models are fine-tuned on text generated from the BOS token alone, with no task specification or external supervision. We report three findings. First, synthetic utility is relational rather than intrinsic: self-generated data is the most effective source, same-lineage transfer outperforms stronger but differently trained sources, and cross-family transfer is substantially weaker. Second, common intrinsic proxies fail: neither benchmark-level semantic similarity nor average per-token likelihood under the student predicts which corpora help. Third, this regime produces a surprising byproduct. In controlled Pythia experiments, capability and verbatim memorization decouple: benchmark utility is preserved or improved while held-out exact-match extraction drops by over 95 percent, with no forget set, privacy objective, or targeted unlearning. Together, these results suggest that prompt-free self-training works by amplifying what the student already knows, not by importing structure from the data. They also reveal a regime in which capability and verbatim memorization can be separated without any explicit unlearning objective.
Rates and architectures for learning geometrically non-trivial operators
Dec 10, 2025Deep learning methods have proven capable of recovering operators between high-dimensional spaces, such as solution maps of PDEs and similar objects in mathematical physics, from very few training samples. This phenomenon of data-efficiency has been proven for certain classes of elliptic operators with simple geometry, i.e., operators that do not change the domain of the function or propagate singularities. However, scientific machine learning is commonly used for problems that do involve the propagation of singularities in a priori unknown ways, such as waves, advection, and fluid dynamics. In light of this, we expand the learning theory to include double fibration transforms--geometric integral operators that include generalized Radon and geodesic ray transforms. We prove that this class of operators does not suffer from the curse of dimensionality: the error decays superalgebraically, that is, faster than any fixed power of the reciprocal of the number of training samples. Furthermore, we investigate architectures that explicitly encode the geometry of these transforms, demonstrating that an architecture reminiscent of cross-attention based on levelset methods yields a parameterization that is universal, stable, and learns double fibration transforms from very few training examples. Our results contribute to a rapidly-growing line of theoretical work on learning operators for scientific machine learning.
W4S4: WaLRUS Meets S4 for Long-Range Sequence Modeling
Jun 09, 2025State Space Models (SSMs) have emerged as powerful components for sequence modeling, enabling efficient handling of long-range dependencies via linear recurrence and convolutional computation. However, their effectiveness depends heavily on the choice and initialization of the state matrix. In this work, we build on the SaFARi framework and existing WaLRUS SSMs to introduce a new variant, W4S4 (WaLRUS for S4), a new class of SSMs constructed from redundant wavelet frames. WaLRUS admits a stable diagonalization and supports fast kernel computation without requiring low-rank approximations, making it both theoretically grounded and computationally efficient. We show that WaLRUS retains information over long horizons significantly better than HiPPO-based SSMs, both in isolation and when integrated into deep architectures such as S4. Our experiments demonstrate consistent improvements across delay reconstruction tasks, classification benchmarks, and long-range sequence modeling, confirming that high-quality, structured initialization enabled by wavelet-based state dynamic offers substantial advantages over existing alternatives. WaLRUS provides a scalable and versatile foundation for the next generation of deep SSM-based models.
WaLRUS: Wavelets for Long-range Representation Using SSMs
May 17, 2025State-Space Models (SSMs) have proven to be powerful tools for modeling long-range dependencies in sequential data. While the recent method known as HiPPO has demonstrated strong performance, and formed the basis for machine learning models S4 and Mamba, it remains limited by its reliance on closed-form solutions for a few specific, well-behaved bases. The SaFARi framework generalized this approach, enabling the construction of SSMs from arbitrary frames, including non-orthogonal and redundant ones, thus allowing an infinite diversity of possible "species" within the SSM family. In this paper, we introduce WaLRUS (Wavelets for Long-range Representation Using SSMs), a new implementation of SaFARi built from Daubechies wavelets.
SaFARi: State-Space Models for Frame-Agnostic Representation
May 13, 2025State-Space Models (SSMs) have re-emerged as a powerful tool for online function approximation, and as the backbone of machine learning models for long-range dependent data. However, to date, only a few polynomial bases have been explored for this purpose, and the state-of-the-art implementations were built upon the best of a few limited options. In this paper, we present a generalized method for building an SSM with any frame or basis, rather than being restricted to polynomials. This framework encompasses the approach known as HiPPO, but also permits an infinite diversity of other possible "species" within the SSM architecture. We dub this approach SaFARi: SSMs for Frame-Agnostic Representation.
Improving Routing in Sparse Mixture of Experts with Graph of Tokens
May 01, 2025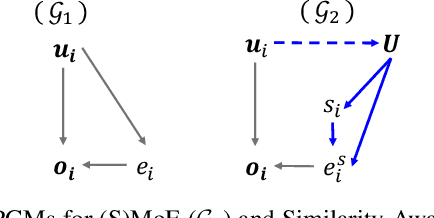
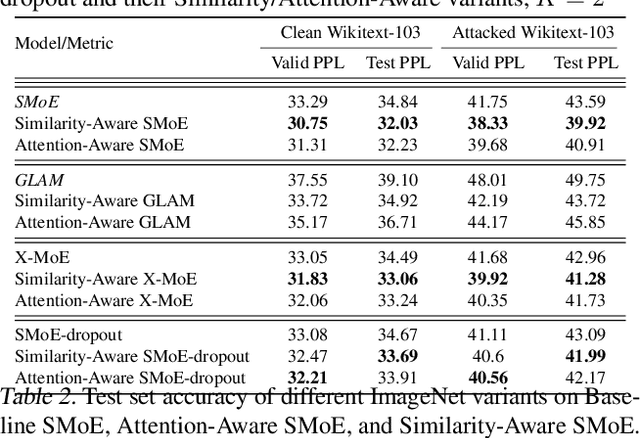
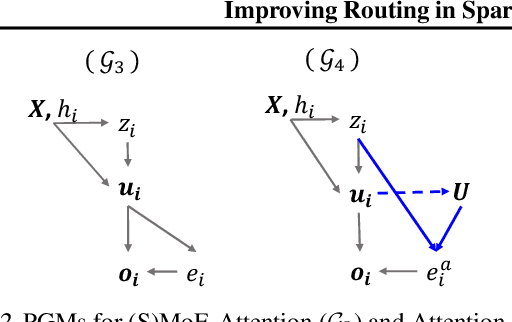
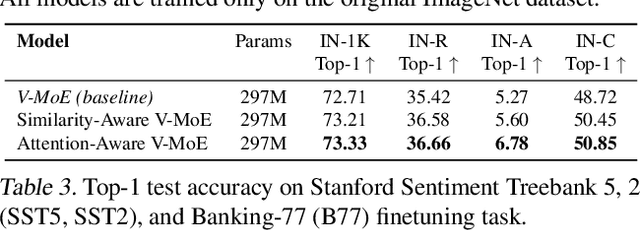
Sparse Mixture of Experts (SMoE) has emerged as a key to achieving unprecedented scalability in deep learning. By activating only a small subset of parameters per sample, SMoE achieves an exponential increase in parameter counts while maintaining a constant computational overhead. However, SMoE models are susceptible to routing fluctuations--changes in the routing of a given input to its target expert--at the late stage of model training, leading to model non-robustness. In this work, we unveil the limitation of SMoE through the perspective of the probabilistic graphical model (PGM). Through this PGM framework, we highlight the independence in the expert-selection of tokens, which exposes the model to routing fluctuation and non-robustness. Alleviating this independence, we propose the novel Similarity-Aware (S)MoE, which considers interactions between tokens during expert selection. We then derive a new PGM underlying an (S)MoE-Attention block, going beyond just a single (S)MoE layer. Leveraging the token similarities captured by the attention matrix, we propose the innovative Attention-Aware (S)MoE, which employs the attention matrix to guide the routing of tokens to appropriate experts in (S)MoE. We theoretically prove that Similarity/Attention-Aware routing help reduce the entropy of expert selection, resulting in more stable token routing mechanisms. We empirically validate our models on various tasks and domains, showing significant improvements in reducing routing fluctuations, enhancing accuracy, and increasing model robustness over the baseline MoE-Transformer with token routing via softmax gating.
Do LLMs Make Mistakes Like Students? Exploring Natural Alignment between Language Models and Human Error Patterns
Feb 21, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various educational tasks, yet their alignment with human learning patterns, particularly in predicting which incorrect options students are most likely to select in multiple-choice questions (MCQs), remains underexplored. Our work investigates the relationship between LLM generation likelihood and student response distributions in MCQs with a specific focus on distractor selections. We collect a comprehensive dataset of MCQs with real-world student response distributions to explore two fundamental research questions: (1). RQ1 - Do the distractors that students more frequently select correspond to those that LLMs assign higher generation likelihood to? (2). RQ2 - When an LLM selects a incorrect choice, does it choose the same distractor that most students pick? Our experiments reveals moderate correlations between LLM-assigned probabilities and student selection patterns for distractors in MCQs. Additionally, when LLMs make mistakes, they are more likley to select the same incorrect answers that commonly mislead students, which is a pattern consistent across both small and large language models. Our work provides empirical evidence that despite LLMs' strong performance on generating educational content, there remains a gap between LLM's underlying reasoning process and human cognitive processes in identifying confusing distractors. Our findings also have significant implications for educational assessment development. The smaller language models could be efficiently utilized for automated distractor generation as they demonstrate similar patterns in identifying confusing answer choices as larger language models. This observed alignment between LLMs and student misconception patterns opens new opportunities for generating high-quality distractors that complement traditional human-designed distractors.
The Imitation Game for Educational AI
Feb 21, 2025
As artificial intelligence systems become increasingly prevalent in education, a fundamental challenge emerges: how can we verify if an AI truly understands how students think and reason? Traditional evaluation methods like measuring learning gains require lengthy studies confounded by numerous variables. We present a novel evaluation framework based on a two-phase Turing-like test. In Phase 1, students provide open-ended responses to questions, revealing natural misconceptions. In Phase 2, both AI and human experts, conditioned on each student's specific mistakes, generate distractors for new related questions. By analyzing whether students select AI-generated distractors at rates similar to human expert-generated ones, we can validate if the AI models student cognition. We prove this evaluation must be conditioned on individual responses - unconditioned approaches merely target common misconceptions. Through rigorous statistical sampling theory, we establish precise requirements for high-confidence validation. Our research positions conditioned distractor generation as a probe into an AI system's fundamental ability to model student thinking - a capability that enables adapting tutoring, feedback, and assessments to each student's specific needs.
Estimating the Number and Locations of Boundaries in Reverberant Environments with Deep Learning
Nov 04, 2024



Underwater acoustic environment estimation is a challenging but important task for remote sensing scenarios. Current estimation methods require high signal strength and a solution to the fragile echo labeling problem to be effective. In previous publications, we proposed a general deep learning-based method for two-dimensional environment estimation which outperformed the state-of-the-art, both in simulation and in real-life experimental settings. A limitation of this method was that some prior information had to be provided by the user on the number and locations of the reflective boundaries, and that its neural networks had to be re-trained accordingly for different environments. Utilizing more advanced neural network and time delay estimation techniques, the proposed improved method no longer requires prior knowledge the number of boundaries or their locations, and is able to estimate two-dimensional environments with one or two boundaries. Future work will extend the proposed method to more boundaries and larger-scale environments.
MazeNet: An Accurate, Fast, and Scalable Deep Learning Solution for Steiner Minimum Trees
Oct 24, 2024The Obstacle Avoiding Rectilinear Steiner Minimum Tree (OARSMT) problem, which seeks the shortest interconnection of a given number of terminals in a rectilinear plane while avoiding obstacles, is a critical task in integrated circuit design, network optimization, and robot path planning. Since OARSMT is NP-hard, exact algorithms scale poorly with the number of terminals, leading practical solvers to sacrifice accuracy for large problems. We propose MazeNet, a deep learning-based method that learns to solve the OARSMT from data. MazeNet reframes OARSMT as a maze-solving task that can be addressed with a recurrent convolutional neural network (RCNN). A key hallmark of MazeNet is its scalability: we only need to train the RCNN blocks on mazes with a small number of terminals; larger mazes can be solved by replicating the same pre-trained blocks to create a larger network. Across a wide range of experiments, MazeNet achieves perfect OARSMT-solving accuracy, significantly reduces runtime compared to classical exact algorithms, and can handle more terminals than state-of-the-art approximate algorithms.