 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Lung Nodule Synthesis via Histogram-Regularized Latent Diffusion Models
May 28, 2026While automated diagnosis systems have achieved remarkable success in computed tomography (CT)-based lung cancer screening, their development remains limited by the scarcity of diverse, annotated pulmonary nodule datasets. Diffusion-based generative models offer a promising strategy for data synthesis; however, many existing conditional approaches primarily optimize spatial reconstruction losses, which encourage voxel-wise similarity but may inadequately constrain lesion-level intensity distributions. As a result, these methods may produce over-smoothed texture profiles and underrepresent the distinct attenuation characteristics of different nodule subtypes, including solid, part-solid, and ground-glass nodules. To address this challenge, we propose a controllable latent diffusion model that synthesizes pulmonary nodules within full 3D CT volumes while accurately modeling nodule-specific intensity distributions. Specifically, rather than relying solely on spatial losses, we introduce a histogram-based regularization term that constrains voxel intensity distributions during the generative process. The model combines subtype, spatial mask, and Hounsfield unit (HU) histogram conditioning with the differentiable feature-space histogram regularization term to better align lesion-level intensity distributions, improving the visual plausibility and subtype consistency of synthesized nodules. Extensive experiments on lung CT data demonstrate that our framework achieves strong visual realism, validated through both quantitative metrics and a visual Turing test. Furthermore, when used for data augmentation, the generated nodules improve performance in downstream clinical tasks, particularly for underrepresented nodule subtypes, and show a potential benefit for subtype-informed malignancy classification.
Specializing Foundation Models via Mixture of Low-Rank Experts for Comprehensive Head CT Analysis
Feb 28, 2026Foundation models pre-trained on large-scale datasets demonstrate strong transfer learning capabilities; however, their adaptation to complex multi-label diagnostic tasks-such as comprehensive head CT finding detection-remains understudied. Standard parameter-efficient fine-tuning methods such as LoRA apply uniform adaptations across pathology types, which may limit performance for diverse medical findings. We propose a Mixture of Low-Rank Experts (MoLRE) framework that extends LoRA with multiple specialized low-rank adapters and unsupervised soft routing. This approach enables conditional feature adaptation with less than 0.5% additional parameters and without explicit pathology supervision. We present a comprehensive benchmark of MoLRE across six state-of-the-art medical imaging foundation models spanning 2D and 3D architectures, general-domain, medical-domain, and head CT-specific pretraining, and model sizes ranging from 7M to 431M parameters. Using over 70,000 non-contrast head CT scans with 75 annotated findings-including hemorrhage, infarction, trauma, mass lesions, structural abnormalities, and chronic changes-our experiments demonstrate consistent performance improvements across all models. Gains vary substantially: general-purpose and medical-domain models show the largest improvements (DINOv3-Base: +4.6%; MedGemma: +4.3%), whereas 3D CT-specialized or very large models show more modest gains (+0.2-1.3%). The combination of MoLRE and MedGemma achieves the highest average detection AUC of 0.917. These findings highlight the importance of systematic benchmarking on target clinical tasks, as pretraining domain, architecture, and model scale interact in non-obvious ways.
Revisiting 2D Foundation Models for Scalable 3D Medical Image Classification
Dec 15, 2025



3D medical image classification is essential for modern clinical workflows. Medical foundation models (FMs) have emerged as a promising approach for scaling to new tasks, yet current research suffers from three critical pitfalls: data-regime bias, suboptimal adaptation, and insufficient task coverage. In this paper, we address these pitfalls and introduce AnyMC3D, a scalable 3D classifier adapted from 2D FMs. Our method scales efficiently to new tasks by adding only lightweight plugins (about 1M parameters per task) on top of a single frozen backbone. This versatile framework also supports multi-view inputs, auxiliary pixel-level supervision, and interpretable heatmap generation. We establish a comprehensive benchmark of 12 tasks covering diverse pathologies, anatomies, and modalities, and systematically analyze state-of-the-art 3D classification techniques. Our analysis reveals key insights: (1) effective adaptation is essential to unlock FM potential, (2) general-purpose FMs can match medical-specific FMs if properly adapted, and (3) 2D-based methods surpass 3D architectures for 3D classification. For the first time, we demonstrate the feasibility of achieving state-of-the-art performance across diverse applications using a single scalable framework (including 1st place in the VLM3D challenge), eliminating the need for separate task-specific models.
AI-assisted Early Detection of Pancreatic Ductal Adenocarcinoma on Contrast-enhanced CT
Mar 13, 2025



Pancreatic ductal adenocarcinoma (PDAC) is one of the most common and aggressive types of pancreatic cancer. However, due to the lack of early and disease-specific symptoms, most patients with PDAC are diagnosed at an advanced disease stage. Consequently, early PDAC detection is crucial for improving patients' quality of life and expanding treatment options. In this work, we develop a coarse-to-fine approach to detect PDAC on contrast-enhanced CT scans. First, we localize and crop the region of interest from the low-resolution images, and then segment the PDAC-related structures at a finer scale. Additionally, we introduce two strategies to further boost detection performance: (1) a data-splitting strategy for model ensembling, and (2) a customized post-processing function. We participated in the PANORAMA challenge and ranked 1st place for PDAC detection with an AUROC of 0.9263 and an AP of 0.7243. Our code and models are publicly available at https://github.com/han-liu/PDAC_detection.
A Non-contrast Head CT Foundation Model for Comprehensive Neuro-Trauma Triage
Feb 28, 2025



Recent advancements in AI and medical imaging offer transformative potential in emergency head CT interpretation for reducing assessment times and improving accuracy in the face of an increasing request of such scans and a global shortage in radiologists. This study introduces a 3D foundation model for detecting diverse neuro-trauma findings with high accuracy and efficiency. Using large language models (LLMs) for automatic labeling, we generated comprehensive multi-label annotations for critical conditions. Our approach involved pretraining neural networks for hemorrhage subtype segmentation and brain anatomy parcellation, which were integrated into a pretrained comprehensive neuro-trauma detection network through multimodal fine-tuning. Performance evaluation against expert annotations and comparison with CT-CLIP demonstrated strong triage accuracy across major neuro-trauma findings, such as hemorrhage and midline shift, as well as less frequent critical conditions such as cerebral edema and arterial hyperdensity. The integration of neuro-specific features significantly enhanced diagnostic capabilities, achieving an average AUC of 0.861 for 16 neuro-trauma conditions. This work advances foundation models in medical imaging, serving as a benchmark for future AI-assisted neuro-trauma diagnostics in emergency radiology.
Generation of Radiology Findings in Chest X-Ray by Leveraging Collaborative Knowledge
Jun 18, 2023



Among all the sub-sections in a typical radiology report, the Clinical Indications, Findings, and Impression often reflect important details about the health status of a patient. The information included in Impression is also often covered in Findings. While Findings and Impression can be deduced by inspecting the image, Clinical Indications often require additional context. The cognitive task of interpreting medical images remains the most critical and often time-consuming step in the radiology workflow. Instead of generating an end-to-end radiology report, in this paper, we focus on generating the Findings from automated interpretation of medical images, specifically chest X-rays (CXRs). Thus, this work focuses on reducing the workload of radiologists who spend most of their time either writing or narrating the Findings. Unlike past research, which addresses radiology report generation as a single-step image captioning task, we have further taken into consideration the complexity of interpreting CXR images and propose a two-step approach: (a) detecting the regions with abnormalities in the image, and (b) generating relevant text for regions with abnormalities by employing a generative large language model (LLM). This two-step approach introduces a layer of interpretability and aligns the framework with the systematic reasoning that radiologists use when reviewing a CXR.
* Information Technology and Quantitative Management (ITQM 2023)
COSST: Multi-organ Segmentation with Partially Labeled Datasets Using Comprehensive Supervisions and Self-training
Apr 28, 2023Deep learning models have demonstrated remarkable success in multi-organ segmentation but typically require large-scale datasets with all organs of interest annotated. However, medical image datasets are often low in sample size and only partially labeled, i.e., only a subset of organs are annotated. Therefore, it is crucial to investigate how to learn a unified model on the available partially labeled datasets to leverage their synergistic potential. In this paper, we empirically and systematically study the partial-label segmentation with in-depth analyses on the existing approaches and identify three distinct types of supervision signals, including two signals derived from ground truth and one from pseudo label. We propose a novel training framework termed COSST, which effectively and efficiently integrates comprehensive supervision signals with self-training. Concretely, we first train an initial unified model using two ground truth-based signals and then iteratively incorporate the pseudo label signal to the initial model using self-training. To mitigate performance degradation caused by unreliable pseudo labels, we assess the reliability of pseudo labels via outlier detection in latent space and exclude the most unreliable pseudo labels from each self-training iteration. Extensive experiments are conducted on six CT datasets for three partial-label segmentation tasks. Experimental results show that our proposed COSST achieves significant improvement over the baseline method, i.e., individual networks trained on each partially labeled dataset. Compared to the state-of-the-art partial-label segmentation methods, COSST demonstrates consistent superior performance on various segmentation tasks and with different training data size.
Self-supervised Learning from 100 Million Medical Images
Jan 04, 2022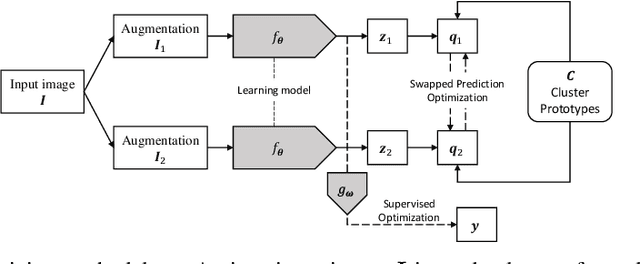
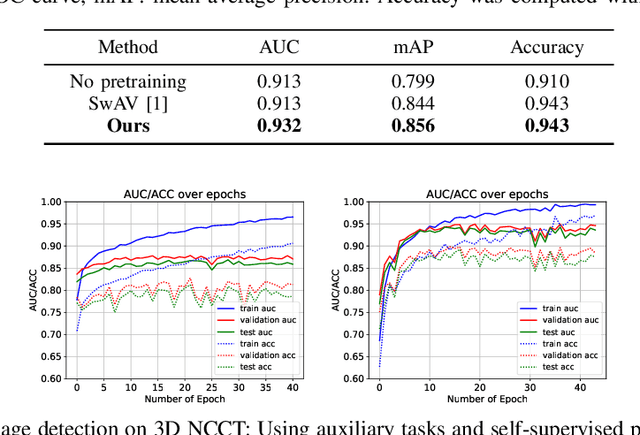
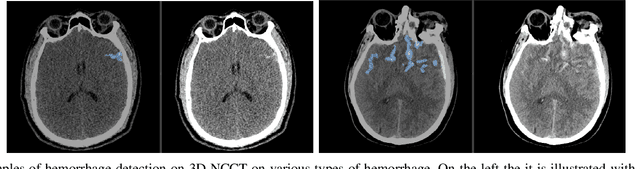
Building accurate and robust artificial intelligence systems for medical image assessment requires not only the research and design of advanced deep learning models but also the creation of large and curated sets of annotated training examples. Constructing such datasets, however, is often very costly -- due to the complex nature of annotation tasks and the high level of expertise required for the interpretation of medical images (e.g., expert radiologists). To counter this limitation, we propose a method for self-supervised learning of rich image features based on contrastive learning and online feature clustering. For this purpose we leverage large training datasets of over 100,000,000 medical images of various modalities, including radiography, computed tomography (CT), magnetic resonance (MR) imaging and ultrasonography. We propose to use these features to guide model training in supervised and hybrid self-supervised/supervised regime on various downstream tasks. We highlight a number of advantages of this strategy on challenging image assessment problems in radiography, CT and MR: 1) Significant increase in accuracy compared to the state-of-the-art (e.g., AUC boost of 3-7% for detection of abnormalities from chest radiography scans and hemorrhage detection on brain CT); 2) Acceleration of model convergence during training by up to 85% compared to using no pretraining (e.g., 83% when training a model for detection of brain metastases in MR scans); 3) Increase in robustness to various image augmentations, such as intensity variations, rotations or scaling reflective of data variation seen in the field.
Robust Classification from Noisy Labels: Integrating Additional Knowledge for Chest Radiography Abnormality Assessment
Apr 21, 2021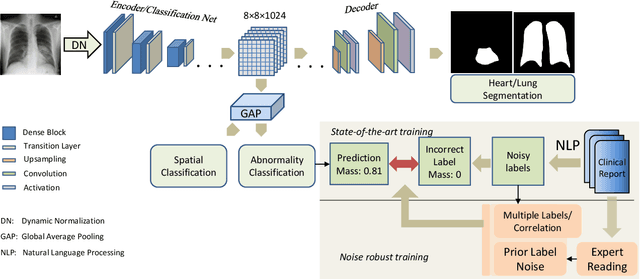
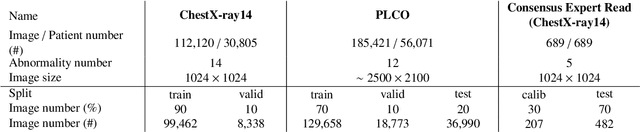
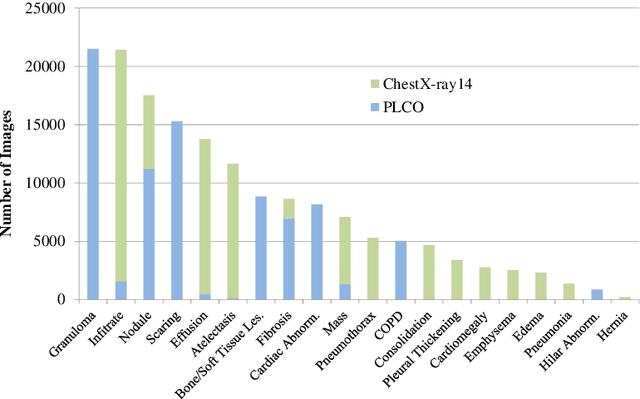
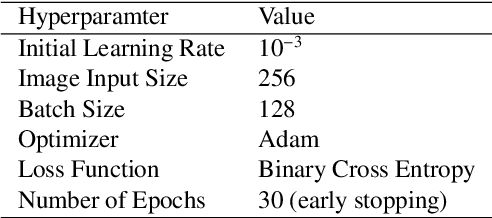
Chest radiography is the most common radiographic examination performed in daily clinical practice for the detection of various heart and lung abnormalities. The large amount of data to be read and reported, with more than 100 studies per day for a single radiologist, poses a challenge in consistently maintaining high interpretation accuracy. The introduction of large-scale public datasets has led to a series of novel systems for automated abnormality classification. However, the labels of these datasets were obtained using natural language processed medical reports, yielding a large degree of label noise that can impact the performance. In this study, we propose novel training strategies that handle label noise from such suboptimal data. Prior label probabilities were measured on a subset of training data re-read by 4 board-certified radiologists and were used during training to increase the robustness of the training model to the label noise. Furthermore, we exploit the high comorbidity of abnormalities observed in chest radiography and incorporate this information to further reduce the impact of label noise. Additionally, anatomical knowledge is incorporated by training the system to predict lung and heart segmentation, as well as spatial knowledge labels. To deal with multiple datasets and images derived from various scanners that apply different post-processing techniques, we introduce a novel image normalization strategy. Experiments were performed on an extensive collection of 297,541 chest radiographs from 86,876 patients, leading to a state-of-the-art performance level for 17 abnormalities from 2 datasets. With an average AUC score of 0.880 across all abnormalities, our proposed training strategies can be used to significantly improve performance scores.
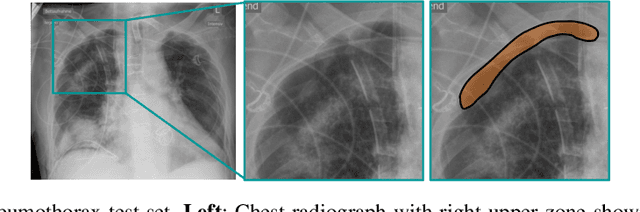
Automated detection and quantification of COVID-19 airspace disease on chest radiographs: A novel approach achieving radiologist-level performance using a CNN trained on digital reconstructed radiographs (DRRs) from CT-based ground-truth
Aug 13, 2020



Purpose: To leverage volumetric quantification of airspace disease (AD) derived from a superior modality (CT) serving as ground truth, projected onto digitally reconstructed radiographs (DRRs) to: 1) train a convolutional neural network to quantify airspace disease on paired CXRs; and 2) compare the DRR-trained CNN to expert human readers in the CXR evaluation of patients with confirmed COVID-19. Materials and Methods: We retrospectively selected a cohort of 86 COVID-19 patients (with positive RT-PCR), from March-May 2020 at a tertiary hospital in the northeastern USA, who underwent chest CT and CXR within 48 hrs. The ground truth volumetric percentage of COVID-19 related AD (POv) was established by manual AD segmentation on CT. The resulting 3D masks were projected into 2D anterior-posterior digitally reconstructed radiographs (DRR) to compute area-based AD percentage (POa). A convolutional neural network (CNN) was trained with DRR images generated from a larger-scale CT dataset of COVID-19 and non-COVID-19 patients, automatically segmenting lungs, AD and quantifying POa on CXR. CNN POa results were compared to POa quantified on CXR by two expert readers and to the POv ground-truth, by computing correlations and mean absolute errors. Results: Bootstrap mean absolute error (MAE) and correlations between POa and POv were 11.98% [11.05%-12.47%] and 0.77 [0.70-0.82] for average of expert readers, and 9.56%-9.78% [8.83%-10.22%] and 0.78-0.81 [0.73-0.85] for the CNN, respectively. Conclusion: Our CNN trained with DRR using CT-derived airspace quantification achieved expert radiologist level of accuracy in the quantification of airspace disease on CXR, in patients with positive RT-PCR for COVID-19.