 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVEPHand: View-Efficient Photometric Hand Performance Capture at Scale
Jun 18, 2026Robust, high-fidelity 3D hand capture, while fundamental to digital human creation, remains challenging with practical multi-view systems that balance rich photometry with the geometric ambiguities of reconstruction arising from limited viewpoint density. This paper presents an end-to-end pipeline for dynamic hand performance capture and registration, specifically designed for view-efficient setups ($\sim$20 views). We address key challenges with two primary innovations. First, to overcome reconstruction difficulties like limited view overlap and background clutter, our mask-free neural method robustly extracts detailed hand geometry and appearance from unmasked images using scene parameterization and scenario-specific density regularization. Second, addressing registration challenges such as accurately capturing non-linear skin deformations and ensuring plausible results during severe self-contact, we propose a physics-inspired framework. It aligns reconstructions to a personalized hand model by optimizing intrinsic volumetric offsets within its canonical tetrahedral mesh, alongside pose parameters. This approach, supported by robust losses and optimization, captures fine surface deformations, ensures plausible results under severe articulation and self-contact, and demonstrates strong tolerance to input noise. We demonstrate the scalability and robustness of our automated pipeline on an extensive dataset of over 12,000 sequences, from which we also derive a large-scale, high-quality synthetic 2D/3D hand dataset for training downstream tasks. This showcases its effectiveness for single hands, intricate two-hand interactions, and natural hand-object manipulations. Our method achieves state-of-the-art reconstruction fidelity in view-efficient, unmasked scenarios and highly accurate registration. Our project page are available at https://vephand.github.io/.
Heteroskedastic Signals in Budgeted LLM Verification: Structural Heterogeneity Limits Optimization Gains
Jun 14, 2026Large language model (LLM) systems increasingly use uncertainty signals to allocate limited computation across verification, test-time scaling, tool execution, and other selective-compute decisions. Such policies rely on a \emph{global signal comparability assumption}: equal scores should carry comparable decision value across inputs. Using budgeted verification as a controlled diagnostic setting, we identify a failure mode of this assumption: uncertainty quality is heteroskedastic across cost strata, with some regions exhibiting near-random discriminability despite concentrating many errors. Under an explicit local model, we characterize the resulting distortion of global allocation and show that its upper bound scales with cross-stratum signal-quality dispersion. We separate weak signals, optimization instability, and structural heterogeneity through a controlled intervention hierarchy: Threshold, MP-Adapt, MP-Strat, and a deliberately simple cost-stratified thresholding intervention (CST). Across MBPP and MATH using Qwen3-8B, LLaMA3-8B, and GPT-4o-mini, global online adaptation yields inconsistent gains over static thresholding; MP-Strat partially recovers performance, while CST improves hit rate by up to 17 percentage points in strongly heterogeneous settings without gradient updates. These results identify structural heterogeneity, rather than optimizer weakness alone, as the primary bottleneck in the observed settings. More broadly, misaligned feedback structure cannot always be repaired by stronger optimization.
VulTriage: Triple-Path Context Augmentation for LLM-Based Vulnerability Detection
May 10, 2026Automated vulnerability detection is a fundamental task in software security, yet existing learning-based methods still struggle to capture the structural dependencies, domain-specific vulnerability knowledge, and complex program semantics required for accurate detection. Recent Large Language Models (LLMs) have shown strong code understanding ability, but directly prompting them with raw source code often leads to missed vulnerabilities or false alarms, especially when vulnerable and benign functions differ only in subtle semantic details. To address this, we propose VulTriage, a triple-path context augmentation framework for LLM-based vulnerability detection. VulTriage enhances the LLM input through three complementary paths: a Control Path that extracts and verbalizes AST, CFG, and DFG information to expose control and data dependencies; a Knowledge Path that retrieves relevant CWE-derived vulnerability patterns and examples through hybrid dense--sparse retrieval; and a Semantic Path that summarizes the functional behavior of the code before the final judgment. These contexts are integrated into a unified instruction to guide the LLM toward more reliable vulnerability reasoning. Experiments on the PrimeVul pair test set show that VulTriage achieves state-of-the-art performance, outperforming existing deep learning and LLM-based baselines on key pair-wise and classification metrics. Further ablation studies verify the effectiveness of each path, and additional experiments on the Kotlin dataset demonstrate the generalization ability of VulTriage under low-resource and class-imbalanced settings. Our code is available at https://github.com/vinsontang1/VulTriage
Cross-Preference Learning for Sentence-Level and Context-Aware Machine Translation
Mar 26, 2026Context-aware machine translation (MT) leverages document-level information, yet it does not consistently outperform sentence-level MT, as contextual signals are unevenly beneficial across sentences. Existing training objectives do not explicitly model this variability, limiting a model's ability to adaptively exploit context. In this paper, we propose Cross-Preference Learning (CPL), a preference-based training framework that explicitly captures the complementary benefits of sentence-level and context-aware MT. CPL achieves this by integrating both intra- and cross-condition preferences into the preference optimization objective. The introduction of intra- and cross-condition preferences provides explicit supervision on when and how contextual information improves translation quality. We validate the proposed approach on several public context-aware MT tasks using multiple models, including Qwen3-4B, Qwen3-8B, and Llama-3-8B. Experimental results demonstrate consistent improvements in translation quality and robustness across both input conditions, achieved without any architectural modifications.
MHR: Momentum Human Rig
Nov 19, 2025We present MHR, a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. Our model enables expressive, anatomically plausible human animation, supporting non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines.
Align-then-Slide: A complete evaluation framework for Ultra-Long Document-Level Machine Translation
Sep 04, 2025



Large language models (LLMs) have ushered in a new era for document-level machine translation (\textit{doc}-mt), yet their whole-document outputs challenge existing evaluation methods that assume sentence-by-sentence alignment. We introduce \textit{\textbf{Align-then-Slide}}, a complete evaluation framework for ultra-long doc-mt. In the Align stage, we automatically infer sentence-level source-target correspondences and rebuild the target to match the source sentence number, resolving omissions and many-to-one/one-to-many mappings. In the n-Chunk Sliding Evaluate stage, we calculate averaged metric scores under 1-, 2-, 3- and 4-chunk for multi-granularity assessment. Experiments on the WMT benchmark show a Pearson correlation of 0.929 between our method with expert MQM rankings. On a newly curated real-world test set, our method again aligns closely with human judgments. Furthermore, preference data produced by Align-then-Slide enables effective CPO training and its direct use as a reward model for GRPO, both yielding translations preferred over a vanilla SFT baseline. The results validate our framework as an accurate, robust, and actionable evaluation tool for doc-mt systems.
Generative Annotation for ASR Named Entity Correction
Aug 28, 2025

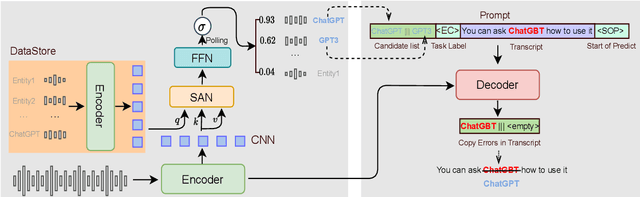
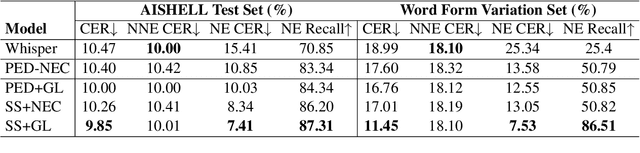
End-to-end automatic speech recognition systems often fail to transcribe domain-specific named entities, causing catastrophic failures in downstream tasks. Numerous fast and lightweight named entity correction (NEC) models have been proposed in recent years. These models, mainly leveraging phonetic-level edit distance algorithms, have shown impressive performances. However, when the forms of the wrongly-transcribed words(s) and the ground-truth entity are significantly different, these methods often fail to locate the wrongly transcribed words in hypothesis, thus limiting their usage. We propose a novel NEC method that utilizes speech sound features to retrieve candidate entities. With speech sound features and candidate entities, we inovatively design a generative method to annotate entity errors in ASR transcripts and replace the text with correct entities. This method is effective in scenarios of word form difference. We test our method using open-source and self-constructed test sets. The results demonstrate that our NEC method can bring significant improvement to entity accuracy. We will open source our self-constructed test set and training data.
Automatic Evaluation Metrics for Document-level Translation: Overview, Challenges and Trends
Apr 21, 2025With the rapid development of deep learning technologies, the field of machine translation has witnessed significant progress, especially with the advent of large language models (LLMs) that have greatly propelled the advancement of document-level translation. However, accurately evaluating the quality of document-level translation remains an urgent issue. This paper first introduces the development status of document-level translation and the importance of evaluation, highlighting the crucial role of automatic evaluation metrics in reflecting translation quality and guiding the improvement of translation systems. It then provides a detailed analysis of the current state of automatic evaluation schemes and metrics, including evaluation methods with and without reference texts, as well as traditional metrics, Model-based metrics and LLM-based metrics. Subsequently, the paper explores the challenges faced by current evaluation methods, such as the lack of reference diversity, dependence on sentence-level alignment information, and the bias, inaccuracy, and lack of interpretability of the LLM-as-a-judge method. Finally, the paper looks ahead to the future trends in evaluation methods, including the development of more user-friendly document-level evaluation methods and more robust LLM-as-a-judge methods, and proposes possible research directions, such as reducing the dependency on sentence-level information, introducing multi-level and multi-granular evaluation approaches, and training models specifically for machine translation evaluation. This study aims to provide a comprehensive analysis of automatic evaluation for document-level translation and offer insights into future developments.
GarmentCrafter: Progressive Novel View Synthesis for Single-View 3D Garment Reconstruction and Editing
Mar 11, 2025We introduce GarmentCrafter, a new approach that enables non-professional users to create and modify 3D garments from a single-view image. While recent advances in image generation have facilitated 2D garment design, creating and editing 3D garments remains challenging for non-professional users. Existing methods for single-view 3D reconstruction often rely on pre-trained generative models to synthesize novel views conditioning on the reference image and camera pose, yet they lack cross-view consistency, failing to capture the internal relationships across different views. In this paper, we tackle this challenge through progressive depth prediction and image warping to approximate novel views. Subsequently, we train a multi-view diffusion model to complete occluded and unknown clothing regions, informed by the evolving camera pose. By jointly inferring RGB and depth, GarmentCrafter enforces inter-view coherence and reconstructs precise geometries and fine details. Extensive experiments demonstrate that our method achieves superior visual fidelity and inter-view coherence compared to state-of-the-art single-view 3D garment reconstruction methods.
Feature Point Extraction for Extra-Affine Image
Mar 05, 2025The issue concerning the significant decline in the stability of feature extraction for images subjected to large-angle affine transformations, where the angle exceeds 50 degrees, still awaits a satisfactory solution. Even ASIFT, which is built upon SIFT and entails a considerable number of image comparisons simulated by affine transformations, inevitably exhibits the drawbacks of being time-consuming and imposing high demands on memory usage. And the stability of feature extraction drops rapidly under large-view affine transformations. Consequently, we propose a method that represents an improvement over ASIFT. On the premise of improving the precision and maintaining the affine invariance, it currently ranks as the fastest feature extraction method for extra-affine images that we know of at present. Simultaneously, the stability of feature extraction regarding affine transformation images has been approximated to the maximum limits. Both the angle between the shooting direction and the normal direction of the photographed object (absolute tilt angle), and the shooting transformation angle between two images (transition tilt angle) are close to 90 degrees. The central idea of the method lies in obtaining the optimal parameter set by simulating affine transformation with the reference image. And the simulated affine transformation is reproduced by combining it with the Lanczos interpolation based on the optimal parameter set. Subsequently, it is combined with ORB, which exhibits excellent real-time performance for rapid orientation binary description. Moreover, a scale parameter simulation is introduced to further augment the operational efficiency.