 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Synthetic Data Is Yours to Learn From
May 29, 2026Can a language model improve from plain text sampled from itself, with no prompts, no teacher, no verifier, and no reward model? Yes, but only when the synthetic corpus is compatible with the student, a relational property of the source-student pair rather than an intrinsic property of the data. We call this the latent capability resurfacing hypothesis: weak self-training can amplify capabilities already present in the pretrained model, but only under this compatibility condition. We study this in the minimal setting of prompt-free unconditional self-training, where base language models are fine-tuned on text generated from the BOS token alone, with no task specification or external supervision. We report three findings. First, synthetic utility is relational rather than intrinsic: self-generated data is the most effective source, same-lineage transfer outperforms stronger but differently trained sources, and cross-family transfer is substantially weaker. Second, common intrinsic proxies fail: neither benchmark-level semantic similarity nor average per-token likelihood under the student predicts which corpora help. Third, this regime produces a surprising byproduct. In controlled Pythia experiments, capability and verbatim memorization decouple: benchmark utility is preserved or improved while held-out exact-match extraction drops by over 95 percent, with no forget set, privacy objective, or targeted unlearning. Together, these results suggest that prompt-free self-training works by amplifying what the student already knows, not by importing structure from the data. They also reveal a regime in which capability and verbatim memorization can be separated without any explicit unlearning objective.
WaLRUS: Wavelets for Long-range Representation Using SSMs
May 17, 2025State-Space Models (SSMs) have proven to be powerful tools for modeling long-range dependencies in sequential data. While the recent method known as HiPPO has demonstrated strong performance, and formed the basis for machine learning models S4 and Mamba, it remains limited by its reliance on closed-form solutions for a few specific, well-behaved bases. The SaFARi framework generalized this approach, enabling the construction of SSMs from arbitrary frames, including non-orthogonal and redundant ones, thus allowing an infinite diversity of possible "species" within the SSM family. In this paper, we introduce WaLRUS (Wavelets for Long-range Representation Using SSMs), a new implementation of SaFARi built from Daubechies wavelets.
SaFARi: State-Space Models for Frame-Agnostic Representation
May 13, 2025State-Space Models (SSMs) have re-emerged as a powerful tool for online function approximation, and as the backbone of machine learning models for long-range dependent data. However, to date, only a few polynomial bases have been explored for this purpose, and the state-of-the-art implementations were built upon the best of a few limited options. In this paper, we present a generalized method for building an SSM with any frame or basis, rather than being restricted to polynomials. This framework encompasses the approach known as HiPPO, but also permits an infinite diversity of other possible "species" within the SSM architecture. We dub this approach SaFARi: SSMs for Frame-Agnostic Representation.
Self-Improving Diffusion Models with Synthetic Data
Aug 29, 2024



The artificial intelligence (AI) world is running out of real data for training increasingly large generative models, resulting in accelerating pressure to train on synthetic data. Unfortunately, training new generative models with synthetic data from current or past generation models creates an autophagous (self-consuming) loop that degrades the quality and/or diversity of the synthetic data in what has been termed model autophagy disorder (MAD) and model collapse. Current thinking around model autophagy recommends that synthetic data is to be avoided for model training lest the system deteriorate into MADness. In this paper, we take a different tack that treats synthetic data differently from real data. Self-IMproving diffusion models with Synthetic data (SIMS) is a new training concept for diffusion models that uses self-synthesized data to provide negative guidance during the generation process to steer a model's generative process away from the non-ideal synthetic data manifold and towards the real data distribution. We demonstrate that SIMS is capable of self-improvement; it establishes new records based on the Fr\'echet inception distance (FID) metric for CIFAR-10 and ImageNet-64 generation and achieves competitive results on FFHQ-64 and ImageNet-512. Moreover, SIMS is, to the best of our knowledge, the first prophylactic generative AI algorithm that can be iteratively trained on self-generated synthetic data without going MAD. As a bonus, SIMS can adjust a diffusion model's synthetic data distribution to match any desired in-domain target distribution to help mitigate biases and ensure fairness.
An Adaptive Tangent Feature Perspective of Neural Networks
Aug 29, 2023In order to better understand feature learning in neural networks, we propose a framework for understanding linear models in tangent feature space where the features are allowed to be transformed during training. We consider linear transformations of features, resulting in a joint optimization over parameters and transformations with a bilinear interpolation constraint. We show that this optimization problem has an equivalent linearly constrained optimization with structured regularization that encourages approximately low rank solutions. Specializing to neural network structure, we gain insights into how the features and thus the kernel function change, providing additional nuance to the phenomenon of kernel alignment when the target function is poorly represented using tangent features. In addition to verifying our theoretical observations in real neural networks on a simple regression problem, we empirically show that an adaptive feature implementation of tangent feature classification has an order of magnitude lower sample complexity than the fixed tangent feature model on MNIST and CIFAR-10.
Self-Consuming Generative Models Go MAD
Jul 04, 2023



Seismic advances in generative AI algorithms for imagery, text, and other data types has led to the temptation to use synthetic data to train next-generation models. Repeating this process creates an autophagous (self-consuming) loop whose properties are poorly understood. We conduct a thorough analytical and empirical analysis using state-of-the-art generative image models of three families of autophagous loops that differ in how fixed or fresh real training data is available through the generations of training and in whether the samples from previous generation models have been biased to trade off data quality versus diversity. Our primary conclusion across all scenarios is that without enough fresh real data in each generation of an autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease. We term this condition Model Autophagy Disorder (MAD), making analogy to mad cow disease.
TITAN: Bringing The Deep Image Prior to Implicit Representations
Nov 01, 2022We study the interpolation capabilities of implicit neural representations (INRs) of images. In principle, INRs promise a number of advantages, such as continuous derivatives and arbitrary sampling, being freed from the restrictions of a raster grid. However, empirically, INRs have been observed to poorly interpolate between the pixels of the fit image; in other words, they do not inherently possess a suitable prior for natural images. In this paper, we propose to address and improve INRs' interpolation capabilities by explicitly integrating image prior information into the INR architecture via deep decoder, a specific implementation of the deep image prior (DIP). Our method, which we call TITAN, leverages a residual connection from the input which enables integrating the principles of the grid-based DIP into the grid-free INR. Through super-resolution and computed tomography experiments, we demonstrate that our method significantly improves upon classic INRs, thanks to the induced natural image bias. We also find that by constraining the weights to be sparse, image quality and sharpness are enhanced, increasing the Lipschitz constant.
NeuroView-RNN: It's About Time
Feb 23, 2022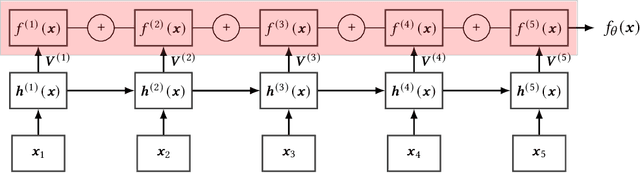
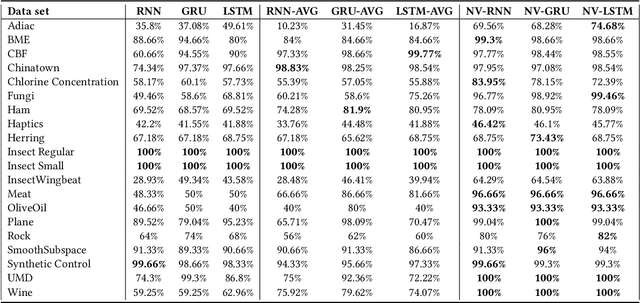


Recurrent Neural Networks (RNNs) are important tools for processing sequential data such as time-series or video. Interpretability is defined as the ability to be understood by a person and is different from explainability, which is the ability to be explained in a mathematical formulation. A key interpretability issue with RNNs is that it is not clear how each hidden state per time step contributes to the decision-making process in a quantitative manner. We propose NeuroView-RNN as a family of new RNN architectures that explains how all the time steps are used for the decision-making process. Each member of the family is derived from a standard RNN architecture by concatenation of the hidden steps into a global linear classifier. The global linear classifier has all the hidden states as the input, so the weights of the classifier have a linear mapping to the hidden states. Hence, from the weights, NeuroView-RNN can quantify how important each time step is to a particular decision. As a bonus, NeuroView-RNN also offers higher accuracy in many cases compared to the RNNs and their variants. We showcase the benefits of NeuroView-RNN by evaluating on a multitude of diverse time-series datasets.
NFT-K: Non-Fungible Tangent Kernels
Oct 11, 2021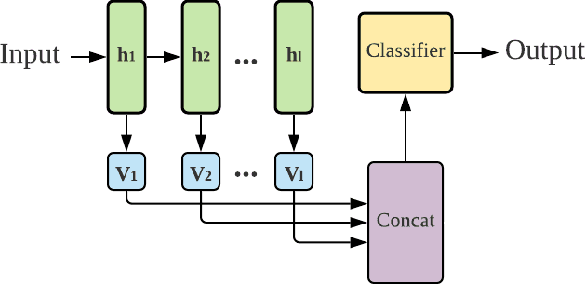
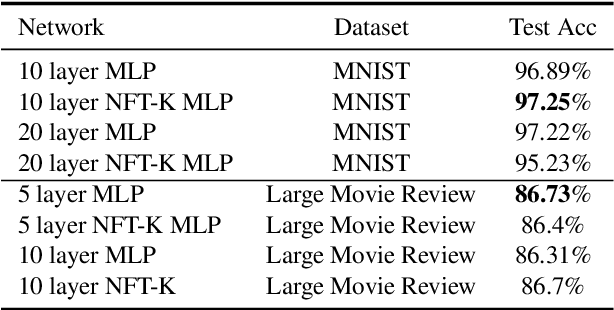
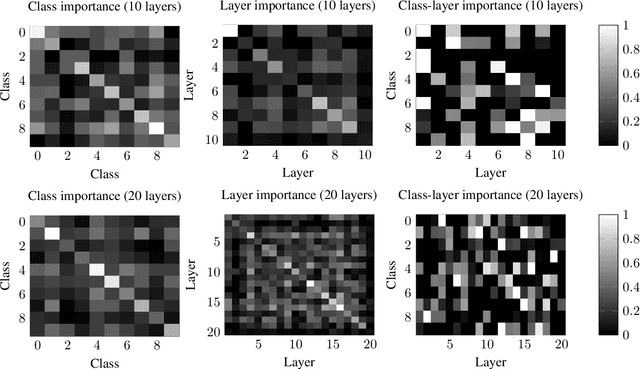
Deep neural networks have become essential for numerous applications due to their strong empirical performance such as vision, RL, and classification. Unfortunately, these networks are quite difficult to interpret, and this limits their applicability in settings where interpretability is important for safety, such as medical imaging. One type of deep neural network is neural tangent kernel that is similar to a kernel machine that provides some aspect of interpretability. To further contribute interpretability with respect to classification and the layers, we develop a new network as a combination of multiple neural tangent kernels, one to model each layer of the deep neural network individually as opposed to past work which attempts to represent the entire network via a single neural tangent kernel. We demonstrate the interpretability of this model on two datasets, showing that the multiple kernels model elucidates the interplay between the layers and predictions.
Scalable Neural Tangent Kernel of Recurrent Architectures
Dec 09, 2020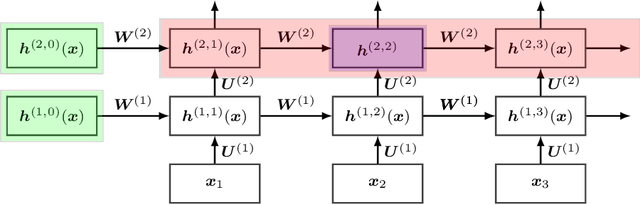
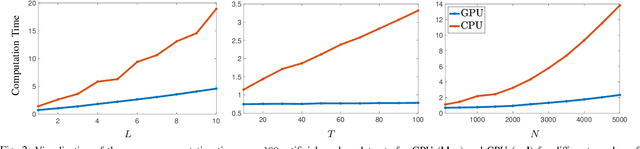
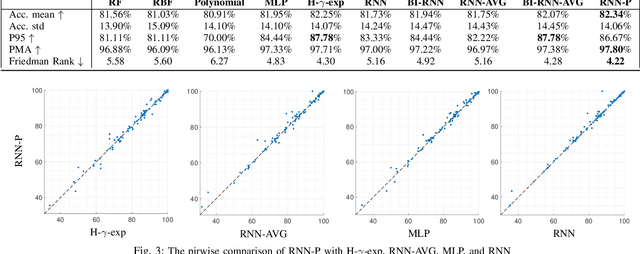
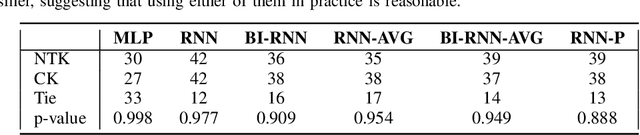
Kernels derived from deep neural networks (DNNs) in the infinite-width provide not only high performance in a range of machine learning tasks but also new theoretical insights into DNN training dynamics and generalization. In this paper, we extend the family of kernels associated with recurrent neural networks (RNNs), which were previously derived only for simple RNNs, to more complex architectures that are bidirectional RNNs and RNNs with average pooling. We also develop a fast GPU implementation to exploit its full practical potential. While RNNs are typically only applied to time-series data, we demonstrate that classifiers using RNN-based kernels outperform a range of baseline methods on 90 non-time-series datasets from the UCI data repository.