 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Model-Agnostic Gender Debiased Image Captioning
Apr 07, 2023
Image captioning models are known to perpetuate and amplify harmful societal bias in the training set. In this work, we aim to mitigate such gender bias in image captioning models. While prior work has addressed this problem by forcing models to focus on people to reduce gender misclassification, it conversely generates gender-stereotypical words at the expense of predicting the correct gender. From this observation, we hypothesize that there are two types of gender bias affecting image captioning models: 1) bias that exploits context to predict gender, and 2) bias in the probability of generating certain (often stereotypical) words because of gender. To mitigate both types of gender biases, we propose a framework, called LIBRA, that learns from synthetically biased samples to decrease both types of biases, correcting gender misclassification and changing gender-stereotypical words to more neutral ones.
Defense against Adversarial Cloud Attack on Remote Sensing Salient Object Detection
Jun 30, 2023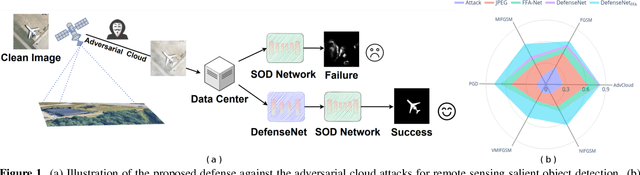
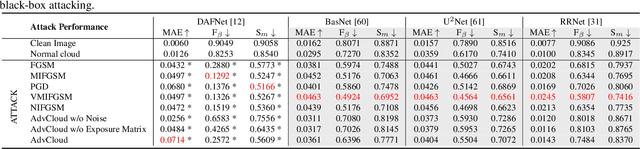
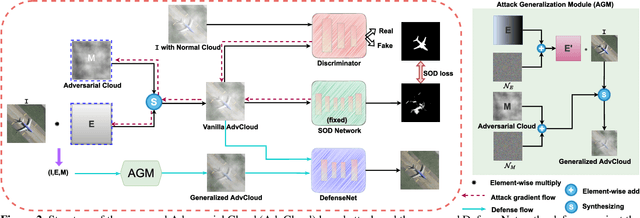
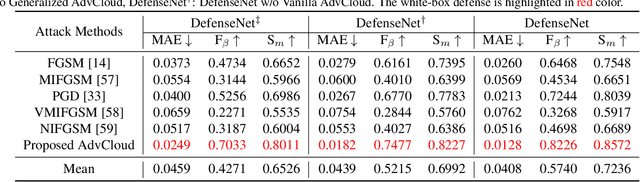
etecting the salient objects in a remote sensing image has wide applications for the interdisciplinary research. Many existing deep learning methods have been proposed for Salient Object Detection (SOD) in remote sensing images and get remarkable results. However, the recent adversarial attack examples, generated by changing a few pixel values on the original remote sensing image, could result in a collapse for the well-trained deep learning based SOD model. Different with existing methods adding perturbation to original images, we propose to jointly tune adversarial exposure and additive perturbation for attack and constrain image close to cloudy image as Adversarial Cloud. Cloud is natural and common in remote sensing images, however, camouflaging cloud based adversarial attack and defense for remote sensing images are not well studied before. Furthermore, we design DefenseNet as a learn-able pre-processing to the adversarial cloudy images so as to preserve the performance of the deep learning based remote sensing SOD model, without tuning the already deployed deep SOD model. By considering both regular and generalized adversarial examples, the proposed DefenseNet can defend the proposed Adversarial Cloud in white-box setting and other attack methods in black-box setting. Experimental results on a synthesized benchmark from the public remote sensing SOD dataset (EORSSD) show the promising defense against adversarial cloud attacks.
Quality-agnostic Image Captioning to Safely Assist People with Vision Impairment
May 01, 2023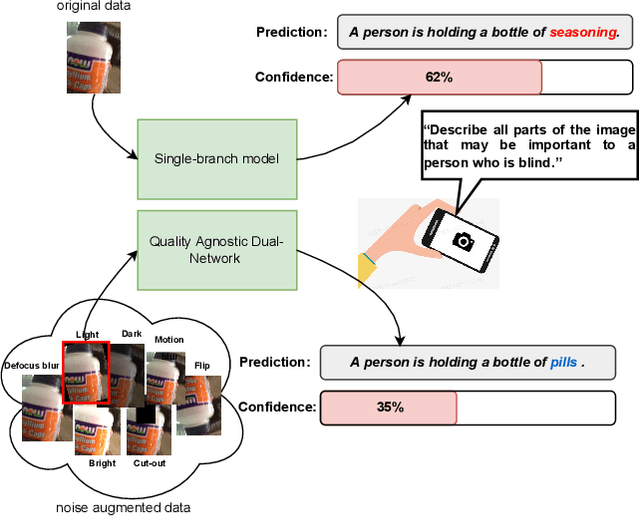

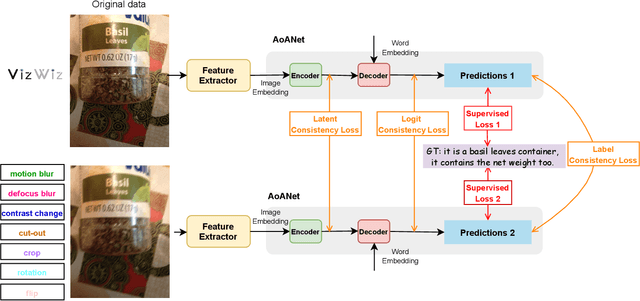
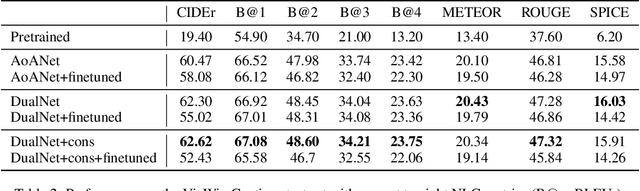
Automated image captioning has the potential to be a useful tool for people with vision impairments. Images taken by this user group are often noisy, which leads to incorrect and even unsafe model predictions. In this paper, we propose a quality-agnostic framework to improve the performance and robustness of image captioning models for visually impaired people. We address this problem from three angles: data, model, and evaluation. First, we show how data augmentation techniques for generating synthetic noise can address data sparsity in this domain. Second, we enhance the robustness of the model by expanding a state-of-the-art model to a dual network architecture, using the augmented data and leveraging different consistency losses. Our results demonstrate increased performance, e.g. an absolute improvement of 2.15 on CIDEr, compared to state-of-the-art image captioning networks, as well as increased robustness to noise with up to 3 points improvement on CIDEr in more noisy settings. Finally, we evaluate the prediction reliability using confidence calibration on images with different difficulty/noise levels, showing that our models perform more reliably in safety-critical situations. The improved model is part of an assisted living application, which we develop in partnership with the Royal National Institute of Blind People.
Measuring the Success of Diffusion Models at Imitating Human Artists
Jul 08, 2023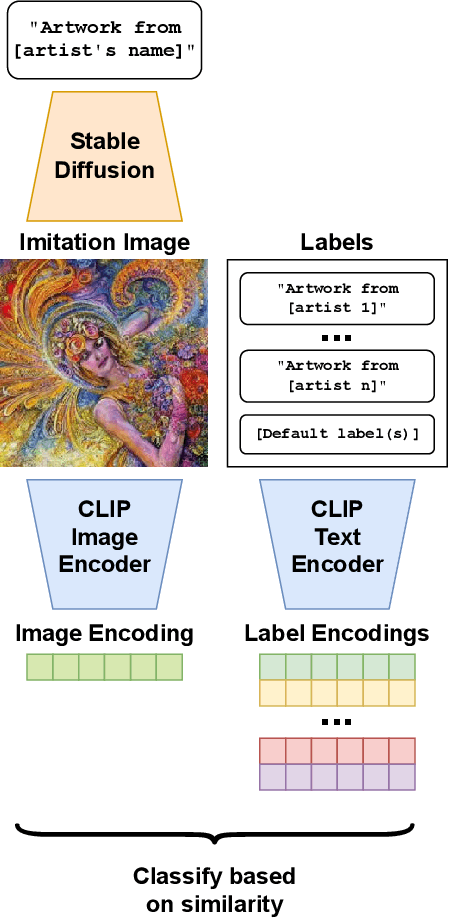

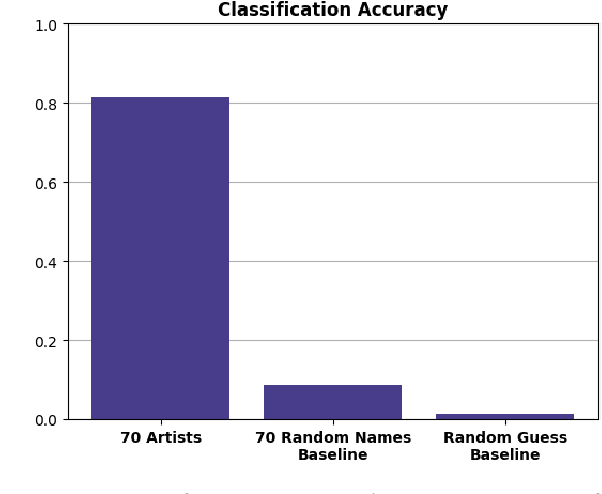
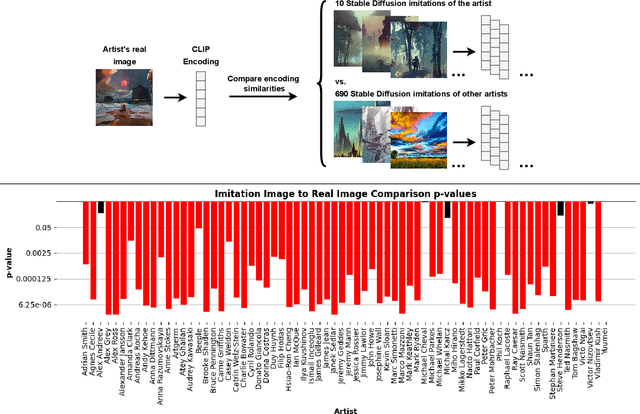
Modern diffusion models have set the state-of-the-art in AI image generation. Their success is due, in part, to training on Internet-scale data which often includes copyrighted work. This prompts questions about the extent to which these models learn from, imitate, or copy the work of human artists. This work suggests that tying copyright liability to the capabilities of the model may be useful given the evolving ecosystem of generative models. Specifically, much of the legal analysis of copyright and generative systems focuses on the use of protected data for training. As a result, the connections between data, training, and the system are often obscured. In our approach, we consider simple image classification techniques to measure a model's ability to imitate specific artists. Specifically, we use Contrastive Language-Image Pretrained (CLIP) encoders to classify images in a zero-shot fashion. Our process first prompts a model to imitate a specific artist. Then, we test whether CLIP can be used to reclassify the artist (or the artist's work) from the imitation. If these tests match the imitation back to the original artist, this suggests the model can imitate that artist's expression. Our approach is simple and quantitative. Furthermore, it uses standard techniques and does not require additional training. We demonstrate our approach with an audit of Stable Diffusion's capacity to imitate 70 professional digital artists with copyrighted work online. When Stable Diffusion is prompted to imitate an artist from this set, we find that the artist can be identified from the imitation with an average accuracy of 81.0%. Finally, we also show that a sample of the artist's work can be matched to these imitation images with a high degree of statistical reliability. Overall, these results suggest that Stable Diffusion is broadly successful at imitating individual human artists.
DiffuseExpand: Expanding dataset for 2D medical image segmentation using diffusion models
Apr 26, 2023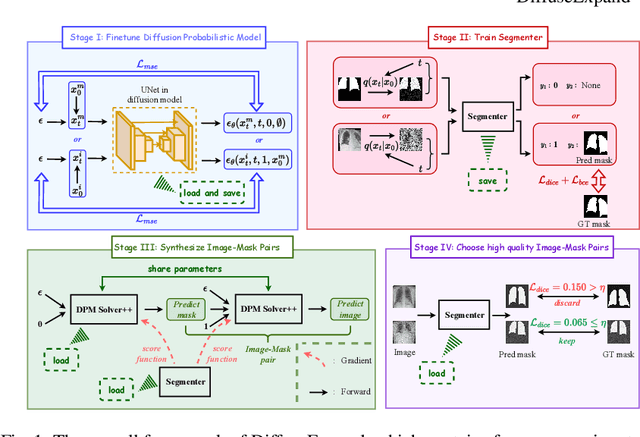
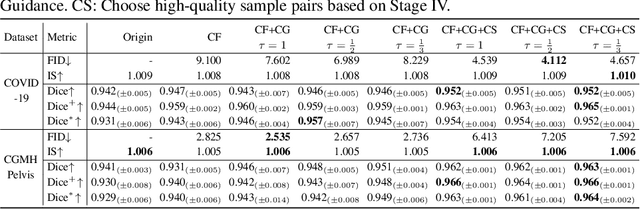

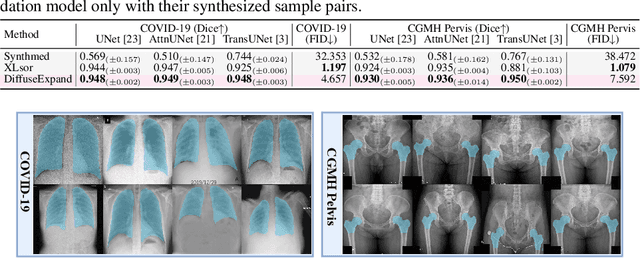
Dataset expansion can effectively alleviate the problem of data scarcity for medical image segmentation, due to privacy concerns and labeling difficulties. However, existing expansion algorithms still face great challenges due to their inability of guaranteeing the diversity of synthesized images with paired segmentation masks. In recent years, Diffusion Probabilistic Models (DPMs) have shown powerful image synthesis performance, even better than Generative Adversarial Networks. Based on this insight, we propose an approach called DiffuseExpand for expanding datasets for 2D medical image segmentation using DPM, which first samples a variety of masks from Gaussian noise to ensure the diversity, and then synthesizes images to ensure the alignment of images and masks. After that, DiffuseExpand chooses high-quality samples to further enhance the effectiveness of data expansion. Our comparison and ablation experiments on COVID-19 and CGMH Pelvis datasets demonstrate the effectiveness of DiffuseExpand. Our code is released at https://anonymous.4open.science/r/DiffuseExpand.
A comparative analysis of SRGAN models
Jul 19, 2023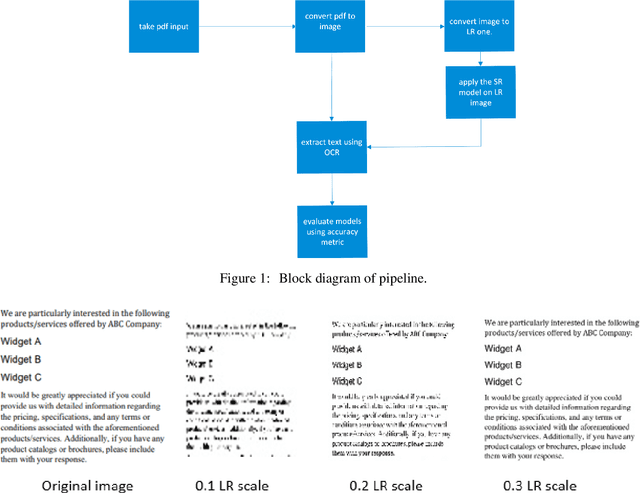
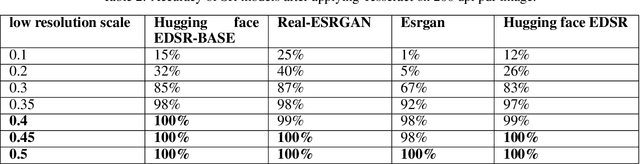

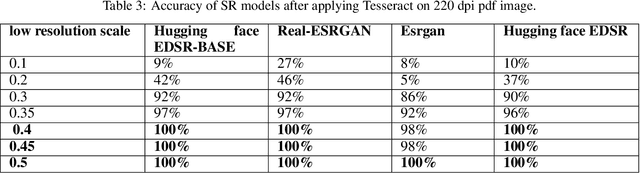
In this study, we evaluate the performance of multiple state-of-the-art SRGAN (Super Resolution Generative Adversarial Network) models, ESRGAN, Real-ESRGAN and EDSR, on a benchmark dataset of real-world images which undergo degradation using a pipeline. Our results show that some models seem to significantly increase the resolution of the input images while preserving their visual quality, this is assessed using Tesseract OCR engine. We observe that EDSR-BASE model from huggingface outperforms the remaining candidate models in terms of both quantitative metrics and subjective visual quality assessments with least compute overhead. Specifically, EDSR generates images with higher peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) values and are seen to return high quality OCR results with Tesseract OCR engine. These findings suggest that EDSR is a robust and effective approach for single-image super-resolution and may be particularly well-suited for applications where high-quality visual fidelity is critical and optimized compute.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023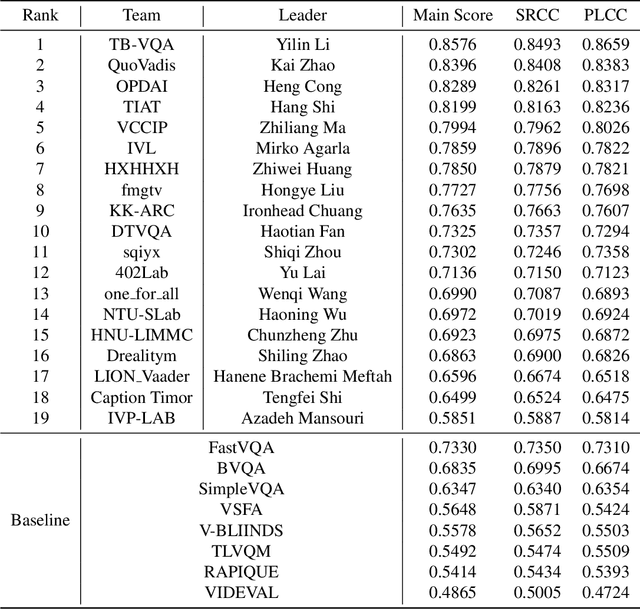
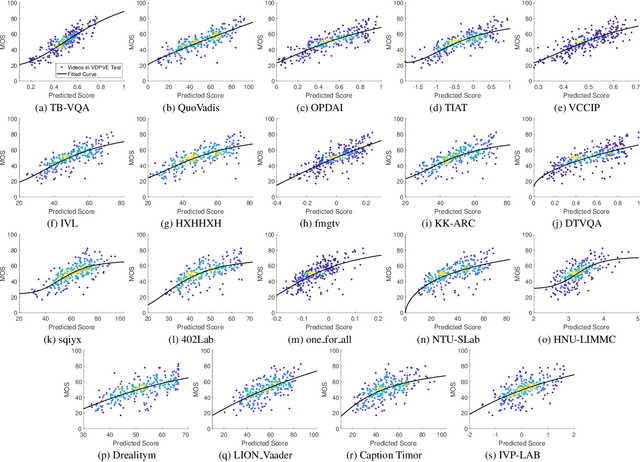
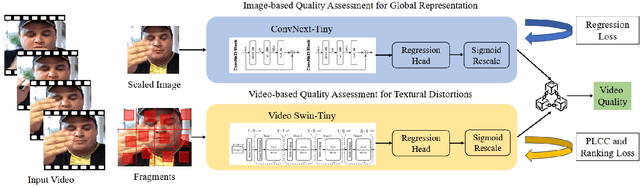
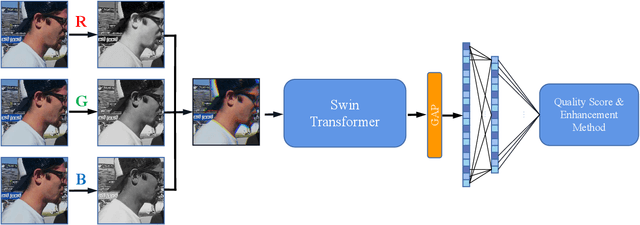
This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Learning from Abstract Images: on the Importance of Occlusion in a Minimalist Encoding of Human Poses
Jul 19, 2023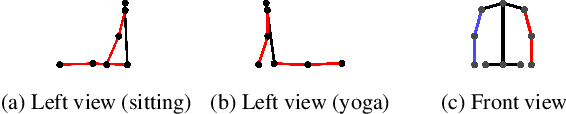
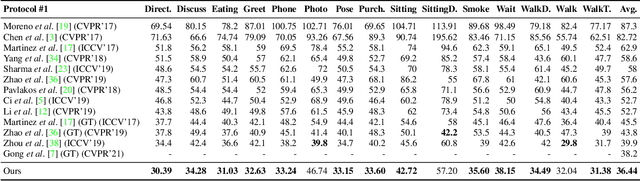
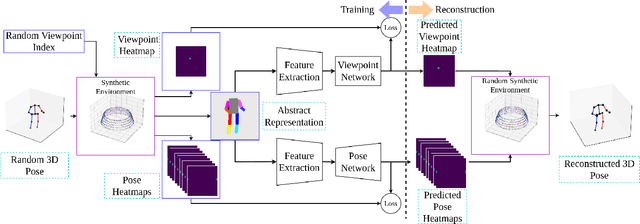
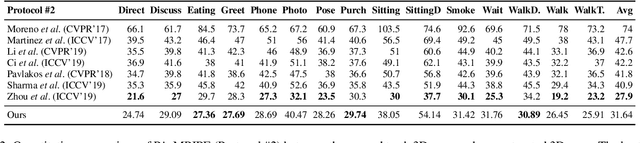
Existing 2D-to-3D pose lifting networks suffer from poor performance in cross-dataset benchmarks. Although the use of 2D keypoints joined by "stick-figure" limbs has shown promise as an intermediate step, stick-figures do not account for occlusion information that is often inherent in an image. In this paper, we propose a novel representation using opaque 3D limbs that preserves occlusion information while implicitly encoding joint locations. Crucially, when training on data with accurate three-dimensional keypoints and without part-maps, this representation allows training on abstract synthetic images, with occlusion, from as many synthetic viewpoints as desired. The result is a pose defined by limb angles rather than joint positions $\unicode{x2013}$ because poses are, in the real world, independent of cameras $\unicode{x2013}$ allowing us to predict poses that are completely independent of camera viewpoint. The result provides not only an improvement in same-dataset benchmarks, but a "quantum leap" in cross-dataset benchmarks.
FABRIC: Personalizing Diffusion Models with Iterative Feedback
Jul 19, 2023

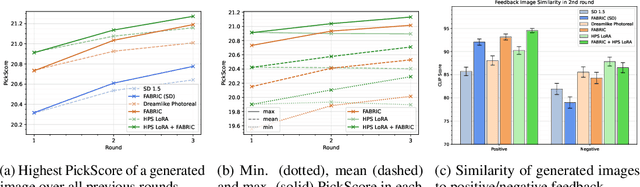
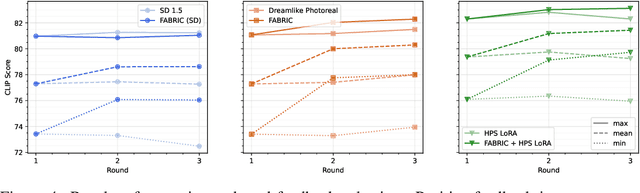
In an era where visual content generation is increasingly driven by machine learning, the integration of human feedback into generative models presents significant opportunities for enhancing user experience and output quality. This study explores strategies for incorporating iterative human feedback into the generative process of diffusion-based text-to-image models. We propose FABRIC, a training-free approach applicable to a wide range of popular diffusion models, which exploits the self-attention layer present in the most widely used architectures to condition the diffusion process on a set of feedback images. To ensure a rigorous assessment of our approach, we introduce a comprehensive evaluation methodology, offering a robust mechanism to quantify the performance of generative visual models that integrate human feedback. We show that generation results improve over multiple rounds of iterative feedback through exhaustive analysis, implicitly optimizing arbitrary user preferences. The potential applications of these findings extend to fields such as personalized content creation and customization.
Polyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023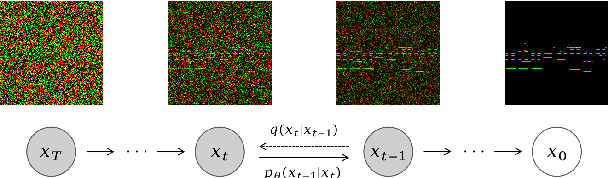

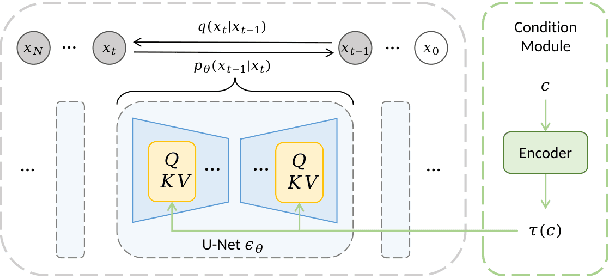
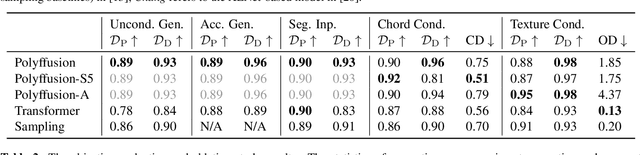
We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.