 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Jun 04, 2026Autonomous driving requires reasoning about how ego actions shape the evolution of the surrounding world. However, most end-to-end methods rely on direct state-to-action mappings, capturing correlations without explicitly modeling action-conditioned dynamics. Conversely, continuous-latent world models often lack compositional structure for causal reasoning across counterfactual futures. We introduce Discrete-WAM, a unified latent vision-action world policy that represents future visual states and ego actions as aligned discrete tokens, enabling compositional causal reasoning across alternative futures. Built upon this unified discrete alignment, Discrete-WAM establishes a shared discrete diffusion framework with unified generative tasks, jointly formulating world modeling, world-action policy, and hierarchical decision-enabled policy, supporting compositional generalization across diverse driving scenarios. Experiments on large-scale autonomous-driving benchmarks show that Discrete-WAM achieves competitive performance while supporting controllable generation and counterfactual reasoning, offering a principled path toward more reliable decision-making.
BEAT: Tokenizing and Generating Symbolic Music by Uniform Temporal Steps
Apr 21, 2026Tokenizing music to fit the general framework of language models is a compelling challenge, especially considering the diverse symbolic structures in which music can be represented (e.g., sequences, grids, and graphs). To date, most approaches tokenize symbolic music as sequences of musical events, such as onsets, pitches, time shifts, or compound note events. This strategy is intuitive and has proven effective in Transformer-based models, but it treats the regularity of musical time implicitly: individual tokens may span different durations, resulting in non-uniform time progression. In this paper, we instead consider whether an alternative tokenization is possible, where a uniform-length musical step (e.g., a beat) serves as the basic unit. Specifically, we encode all events within a single time step at the same pitch as one token, and group tokens explicitly by time step, which resembles a sparse encoding of a piano-roll representation. We evaluate the proposed tokenization on music continuation and accompaniment generation tasks, comparing it with mainstream event-based methods. Results show improved musical quality and structural coherence, while additional analyses confirm higher efficiency and more effective capture of long-range patterns with the proposed tokenization.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
FB-4D: Spatial-Temporal Coherent Dynamic 3D Content Generation with Feature Banks
Mar 26, 2025With the rapid advancements in diffusion models and 3D generation techniques, dynamic 3D content generation has become a crucial research area. However, achieving high-fidelity 4D (dynamic 3D) generation with strong spatial-temporal consistency remains a challenging task. Inspired by recent findings that pretrained diffusion features capture rich correspondences, we propose FB-4D, a novel 4D generation framework that integrates a Feature Bank mechanism to enhance both spatial and temporal consistency in generated frames. In FB-4D, we store features extracted from previous frames and fuse them into the process of generating subsequent frames, ensuring consistent characteristics across both time and multiple views. To ensure a compact representation, the Feature Bank is updated by a proposed dynamic merging mechanism. Leveraging this Feature Bank, we demonstrate for the first time that generating additional reference sequences through multiple autoregressive iterations can continuously improve generation performance. Experimental results show that FB-4D significantly outperforms existing methods in terms of rendering quality, spatial-temporal consistency, and robustness. It surpasses all multi-view generation tuning-free approaches by a large margin and achieves performance on par with training-based methods.
Unlocking Potential in Pre-Trained Music Language Models for Versatile Multi-Track Music Arrangement
Aug 27, 2024



Large language models have shown significant capabilities across various domains, including symbolic music generation. However, leveraging these pre-trained models for controllable music arrangement tasks, each requiring different forms of musical information as control, remains a novel challenge. In this paper, we propose a unified sequence-to-sequence framework that enables the fine-tuning of a symbolic music language model for multiple multi-track arrangement tasks, including band arrangement, piano reduction, drum arrangement, and voice separation. Our experiments demonstrate that the proposed approach consistently achieves higher musical quality compared to task-specific baselines across all four tasks. Furthermore, through additional experiments on probing analysis, we show the pre-training phase equips the model with essential knowledge to understand musical conditions, which is hard to acquired solely through task-specific fine-tuning.
SA-GS: Scale-Adaptive Gaussian Splatting for Training-Free Anti-Aliasing
Mar 28, 2024



In this paper, we present a Scale-adaptive method for Anti-aliasing Gaussian Splatting (SA-GS). While the state-of-the-art method Mip-Splatting needs modifying the training procedure of Gaussian splatting, our method functions at test-time and is training-free. Specifically, SA-GS can be applied to any pretrained Gaussian splatting field as a plugin to significantly improve the field's anti-alising performance. The core technique is to apply 2D scale-adaptive filters to each Gaussian during test time. As pointed out by Mip-Splatting, observing Gaussians at different frequencies leads to mismatches between the Gaussian scales during training and testing. Mip-Splatting resolves this issue using 3D smoothing and 2D Mip filters, which are unfortunately not aware of testing frequency. In this work, we show that a 2D scale-adaptive filter that is informed of testing frequency can effectively match the Gaussian scale, thus making the Gaussian primitive distribution remain consistent across different testing frequencies. When scale inconsistency is eliminated, sampling rates smaller than the scene frequency result in conventional jaggedness, and we propose to integrate the projected 2D Gaussian within each pixel during testing. This integration is actually a limiting case of super-sampling, which significantly improves anti-aliasing performance over vanilla Gaussian Splatting. Through extensive experiments using various settings and both bounded and unbounded scenes, we show SA-GS performs comparably with or better than Mip-Splatting. Note that super-sampling and integration are only effective when our scale-adaptive filtering is activated. Our codes, data and models are available at https://github.com/zsy1987/SA-GS.
AccoMontage-3: Full-Band Accompaniment Arrangement via Sequential Style Transfer and Multi-Track Function Prior
Oct 25, 2023We propose AccoMontage-3, a symbolic music automation system capable of generating multi-track, full-band accompaniment based on the input of a lead melody with chords (i.e., a lead sheet). The system contains three modular components, each modelling a vital aspect of full-band composition. The first component is a piano arranger that generates piano accompaniment for the lead sheet by transferring texture styles to the chords using latent chord-texture disentanglement and heuristic retrieval of texture donors. The second component orchestrates the piano accompaniment score into full-band arrangement according to the orchestration style encoded by individual track functions. The third component, which connects the previous two, is a prior model characterizing the global structure of orchestration style over the whole piece of music. From end to end, the system learns to generate full-band accompaniment in a self-supervised fashion, applying style transfer at two levels of polyphonic composition: texture and orchestration. Experiments show that our system outperforms the baselines significantly, and the modular design offers effective controls in a musically meaningful way.
Polyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.
Q&A: Query-Based Representation Learning for Multi-Track Symbolic Music re-Arrangement
Jun 02, 2023



Music rearrangement is a common music practice of reconstructing and reconceptualizing a piece using new composition or instrumentation styles, which is also an important task of automatic music generation. Existing studies typically model the mapping from a source piece to a target piece via supervised learning. In this paper, we tackle rearrangement problems via self-supervised learning, in which the mapping styles can be regarded as conditions and controlled in a flexible way. Specifically, we are inspired by the representation disentanglement idea and propose Q&A, a query-based algorithm for multi-track music rearrangement under an encoder-decoder framework. Q&A learns both a content representation from the mixture and function (style) representations from each individual track, while the latter queries the former in order to rearrange a new piece. Our current model focuses on popular music and provides a controllable pathway to four scenarios: 1) re-instrumentation, 2) piano cover generation, 3) orchestration, and 4) voice separation. Experiments show that our query system achieves high-quality rearrangement results with delicate multi-track structures, significantly outperforming the baselines.
Domain Adversarial Training on Conditional Variational Auto-Encoder for Controllable Music Generation
Sep 15, 2022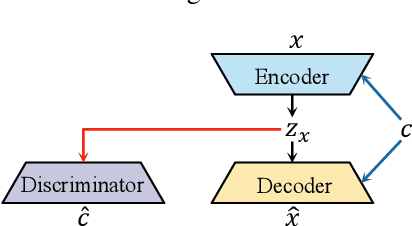
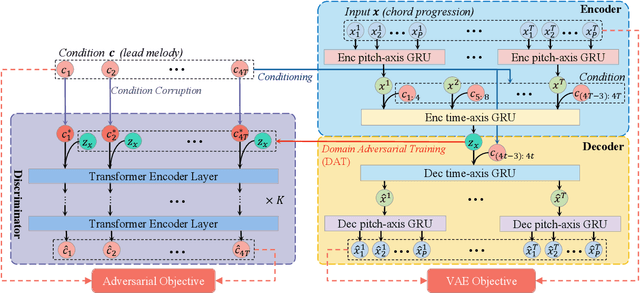
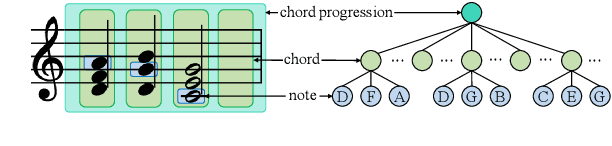
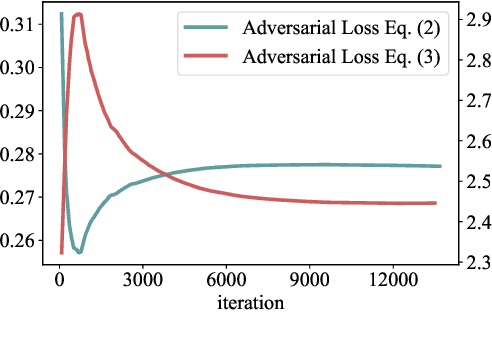
The variational auto-encoder has become a leading framework for symbolic music generation, and a popular research direction is to study how to effectively control the generation process. A straightforward way is to control a model using different conditions during inference. However, in music practice, conditions are usually sequential (rather than simple categorical labels), involving rich information that overlaps with the learned representation. Consequently, the decoder gets confused about whether to "listen to" the latent representation or the condition, and sometimes just ignores the condition. To solve this problem, we leverage domain adversarial training to disentangle the representation from condition cues for better control. Specifically, we propose a condition corruption objective that uses the representation to denoise a corrupted condition. Minimized by a discriminator and maximized by the VAE encoder, this objective adversarially induces a condition-invariant representation. In this paper, we focus on the task of melody harmonization to illustrate our idea, while our methodology can be generalized to other controllable generative tasks. Demos and experiments show that our methodology facilitates not only condition-invariant representation learning but also higher-quality controllability compared to baselines.