 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARGUS: Adaptive Rotation-Invariant Geometric Unsupervised System
Jan 03, 2026Detecting distributional drift in high-dimensional data streams presents fundamental challenges: global comparison methods scale poorly, projection-based approaches lose geometric structure, and re-clustering methods suffer from identity instability. This paper introduces Argus, A framework that reconceptualizes drift detection as tracking local statistics over a fixed spatial partition of the data manifold. The key contributions are fourfold. First, it is proved that Voronoi tessellations over canonical orthonormal frames yield drift metrics that are invariant to orthogonal transformations. The rotations and reflections that preserve Euclidean geometry. Second, it is established that this framework achieves O(N) complexity per snapshot while providing cell-level spatial localization of distributional change. Third, a graph-theoretic characterization of drift propagation is developed that distinguishes coherent distributional shifts from isolated perturbations. Fourth, product quantization tessellation is introduced for scaling to very high dimensions (d>500) by decomposing the space into independent subspaces and aggregating drift signals across subspaces. This paper formalizes the theoretical foundations, proves invariance properties, and presents experimental validation demonstrating that the framework correctly identifies drift under coordinate rotation while existing methods produce false positives. The tessellated approach offers a principled geometric foundation for distribution monitoring that preserves high-dimensional structure without the computational burden of pairwise comparisons.
Optimizing the Privacy-Utility Balance using Synthetic Data and Configurable Perturbation Pipelines
Apr 24, 2025This paper explores the strategic use of modern synthetic data generation and advanced data perturbation techniques to enhance security, maintain analytical utility, and improve operational efficiency when managing large datasets, with a particular focus on the Banking, Financial Services, and Insurance (BFSI) sector. We contrast these advanced methods encompassing generative models like GANs, sophisticated context-aware PII transformation, configurable statistical perturbation, and differential privacy with traditional anonymization approaches. The goal is to create realistic, privacy-preserving datasets that retain high utility for complex machine learning tasks and analytics, a critical need in the data-sensitive industries like BFSI, Healthcare, Retail, and Telecommunications. We discuss how these modern techniques potentially offer significant improvements in balancing privacy preservation while maintaining data utility compared to older methods. Furthermore, we examine the potential for operational gains, such as reduced overhead and accelerated analytics, by using these privacy-enhanced datasets. We also explore key use cases where these methods can mitigate regulatory risks and enable scalable, data-driven innovation without compromising sensitive customer information.
Mitigating Hallucination with ZeroG: An Advanced Knowledge Management Engine
Nov 08, 2024The growth of digital documents presents significant challenges in efficient management and knowledge extraction. Traditional methods often struggle with complex documents, leading to issues such as hallucinations and high latency in responses from Large Language Models (LLMs). ZeroG, an innovative approach, significantly mitigates these challenges by leveraging knowledge distillation and prompt tuning to enhance model performance. ZeroG utilizes a smaller model that replicates the behavior of a larger teacher model, ensuring contextually relevant and grounded responses, by employing a black-box distillation approach, it creates a distilled dataset without relying on intermediate features, optimizing computational efficiency. This method significantly enhances accuracy and reduces response times, providing a balanced solution for modern document management. Incorporating advanced techniques for document ingestion and metadata utilization, ZeroG improves the accuracy of question-and-answer systems. The integration of graph databases and robust metadata management further streamlines information retrieval, allowing for precise and context-aware responses. By transforming how organizations interact with complex data, ZeroG enhances productivity and user experience, offering a scalable solution for the growing demands of digital document management.
TableGuard -- Securing Structured & Unstructured Data
Aug 13, 2024


With the increasing demand for data sharing across platforms and organizations, ensuring the privacy and security of sensitive information has become a critical challenge. This paper introduces "TableGuard". An innovative approach to data obfuscation tailored for relational databases. Building on the principles and techniques developed in prior work on context-sensitive obfuscation, TableGuard applies these methods to ensure that API calls return only obfuscated data, thereby safeguarding privacy when sharing data with third parties. TableGuard leverages advanced context-sensitive obfuscation techniques to replace sensitive data elements with contextually appropriate alternatives. By maintaining the relational integrity and coherence of the data, our approach mitigates the risks of cognitive dissonance and data leakage. We demonstrate the implementation of TableGuard using a BERT based transformer model, which identifies and obfuscates sensitive entities within relational tables. Our evaluation shows that TableGuard effectively balances privacy protection with data utility, minimizing information loss while ensuring that the obfuscated data remains functionally useful for downstream applications. The results highlight the importance of domain-specific obfuscation strategies and the role of context length in preserving data integrity. The implications of this research are significant for organizations that need to share data securely with external parties. TableGuard offers a robust framework for implementing privacy-preserving data sharing mechanisms, thereby contributing to the broader field of data privacy and security.
A comparative analysis of SRGAN models
Jul 19, 2023In this study, we evaluate the performance of multiple state-of-the-art SRGAN (Super Resolution Generative Adversarial Network) models, ESRGAN, Real-ESRGAN and EDSR, on a benchmark dataset of real-world images which undergo degradation using a pipeline. Our results show that some models seem to significantly increase the resolution of the input images while preserving their visual quality, this is assessed using Tesseract OCR engine. We observe that EDSR-BASE model from huggingface outperforms the remaining candidate models in terms of both quantitative metrics and subjective visual quality assessments with least compute overhead. Specifically, EDSR generates images with higher peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) values and are seen to return high quality OCR results with Tesseract OCR engine. These findings suggest that EDSR is a robust and effective approach for single-image super-resolution and may be particularly well-suited for applications where high-quality visual fidelity is critical and optimized compute.
Life of PII -- A PII Obfuscation Transformer
May 17, 2023


Protecting sensitive information is crucial in today's world of Large Language Models (LLMs) and data-driven services. One common method used to preserve privacy is by using data perturbation techniques to reduce overreaching utility of (sensitive) Personal Identifiable Information (PII) data while maintaining its statistical and semantic properties. Data perturbation methods often result in significant information loss, making them impractical for use. In this paper, we propose 'Life of PII', a novel Obfuscation Transformer framework for transforming PII into faux-PII while preserving the original information, intent, and context as much as possible. Our approach includes an API to interface with the given document, a configuration-based obfuscator, and a model based on the Transformer architecture, which has shown high context preservation and performance in natural language processing tasks and LLMs. Our Transformer-based approach learns mapping between the original PII and its transformed faux-PII representation, which we call "obfuscated" data. Our experiments demonstrate that our method, called Life of PII, outperforms traditional data perturbation techniques in terms of both utility preservation and privacy protection. We show that our approach can effectively reduce utility loss while preserving the original information, offering greater flexibility in the trade-off between privacy protection and data utility. Our work provides a solution for protecting PII in various real-world applications.
Differential Privacy for Credit Risk Model
Jun 24, 2021
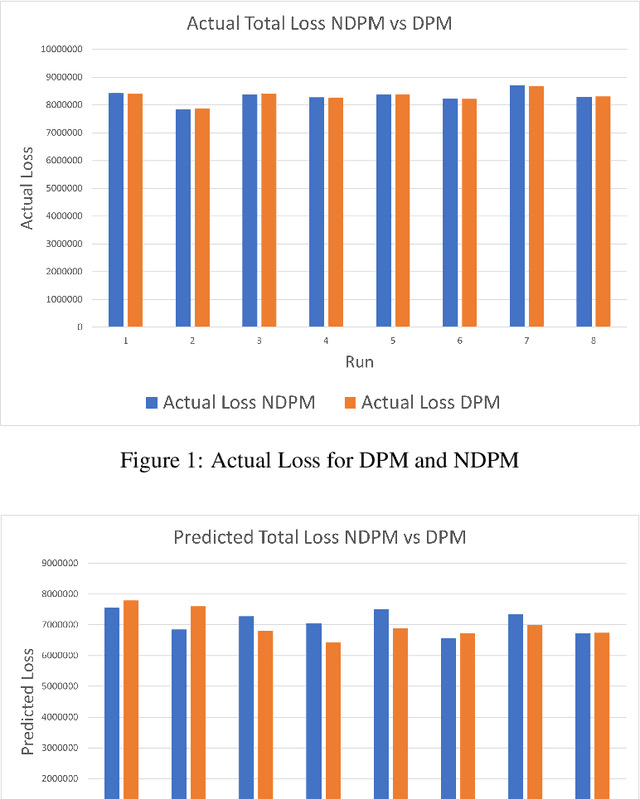
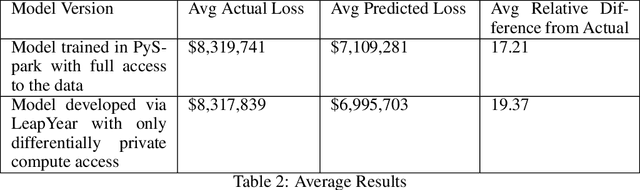
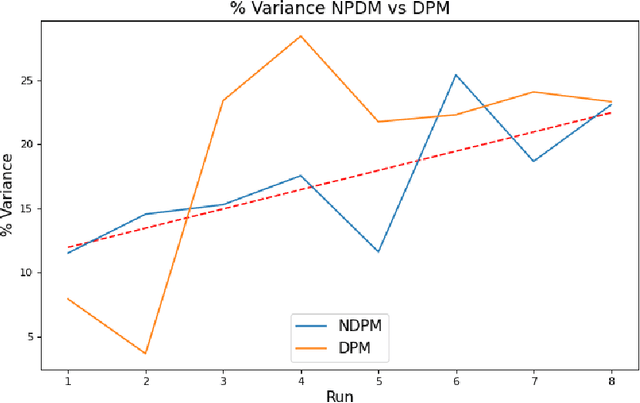
The use of machine learning algorithms to model user behavior and drive business decisions has become increasingly commonplace, specifically providing intelligent recommendations to automated decision making. This has led to an increase in the use of customers personal data to analyze customer behavior and predict their interests in a companys products. Increased use of this customer personal data can lead to better models but also to the potential of customer data being leaked, reverse engineered, and mishandled. In this paper, we assess differential privacy as a solution to address these privacy problems by building privacy protections into the data engineering and model training stages of predictive model development. Our interest is a pragmatic implementation in an operational environment, which necessitates a general purpose differentially private modeling framework, and we evaluate one such tool from LeapYear as applied to the Credit Risk modeling domain. Credit Risk Model is a major modeling methodology in banking and finance where user data is analyzed to determine the total Expected Loss to the bank. We examine the application of differential privacy on the credit risk model and evaluate the performance of a Differentially Private Model with a Non Differentially Private Model. Credit Risk Model is a major modeling methodology in banking and finance where users data is analyzed to determine the total Expected Loss to the bank. In this paper, we explore the application of differential privacy on the credit risk model and evaluate the performance of a Non Differentially Private Model with Differentially Private Model.
TableZa -- A classical Computer Vision approach to Tabular Extraction
May 19, 2021
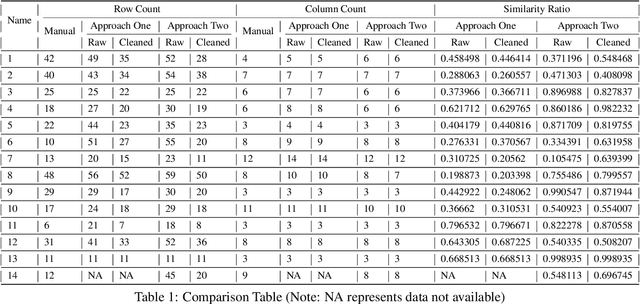
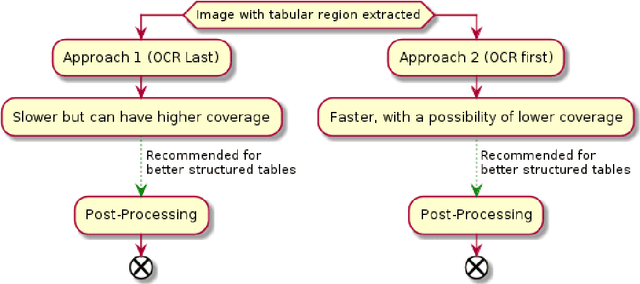
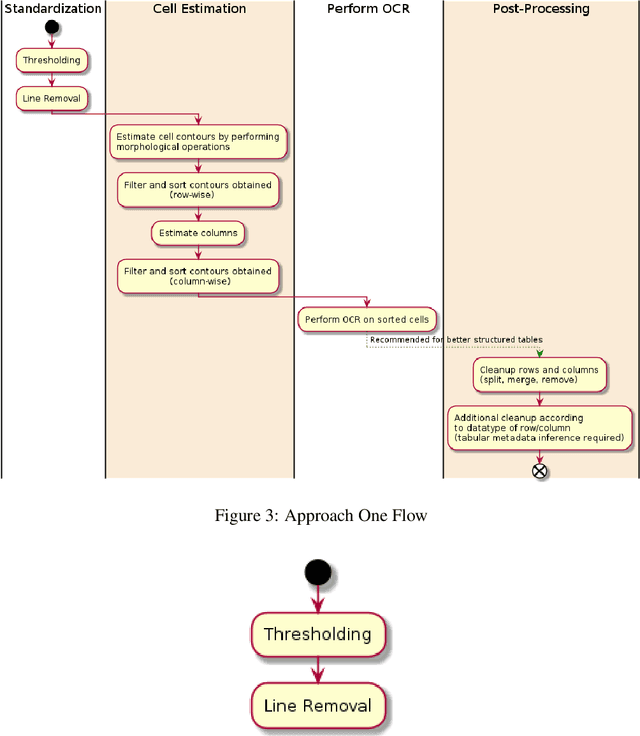
Computer aided Tabular Data Extraction has always been a very challenging and error prone task because it demands both Spectral and Spatial Sanity of data. In this paper we discuss an approach for Tabular Data Extraction in the realm of document comprehension. Given the different kinds of the Tabular formats that are often found across various documents, we discuss a novel approach using Computer Vision for extraction of tabular data from images or vector pdf(s) converted to image(s).
Techniques to Improve Q&A Accuracy with Transformer-based models on Large Complex Documents
Sep 26, 2020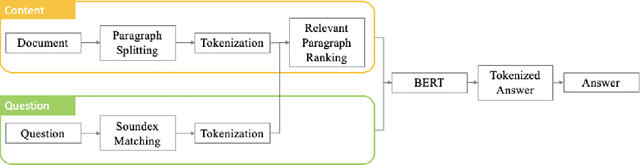
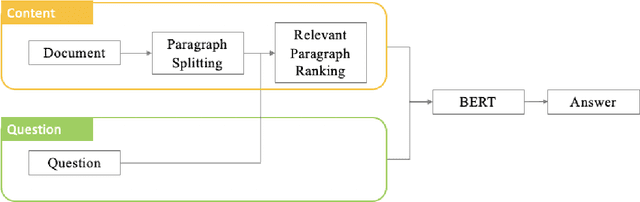
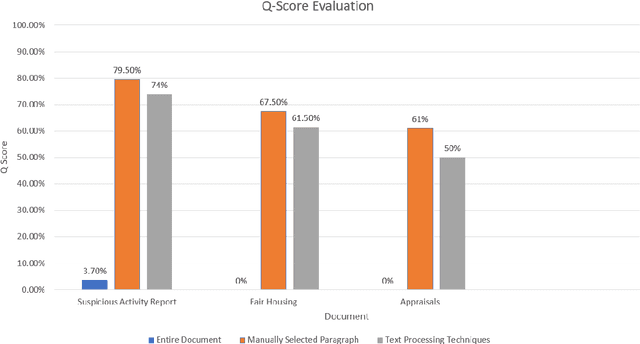
This paper discusses the effectiveness of various text processing techniques, their combinations, and encodings to achieve a reduction of complexity and size in a given text corpus. The simplified text corpus is sent to BERT (or similar transformer based models) for question and answering and can produce more relevant responses to user queries. This paper takes a scientific approach to determine the benefits and effectiveness of various techniques and concludes a best-fit combination that produces a statistically significant improvement in accuracy.
Classification of descriptions and summary using multiple passes of statistical and natural language toolkits
Sep 10, 2020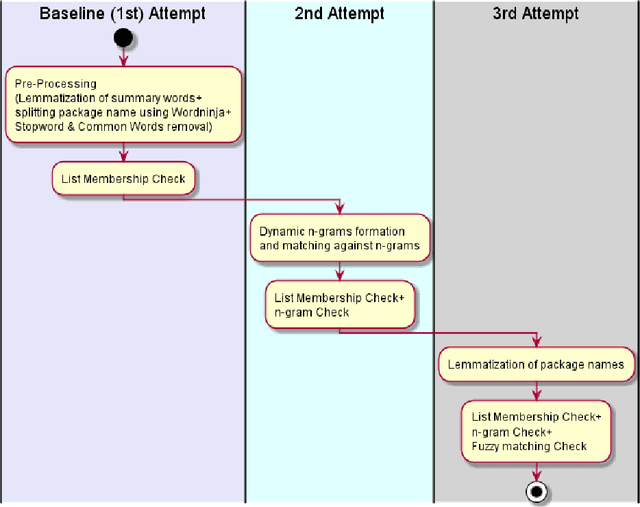
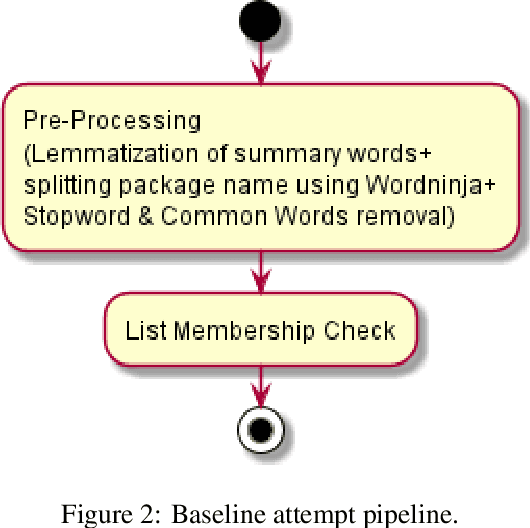
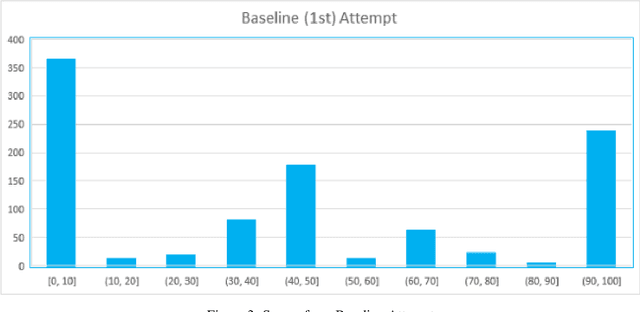
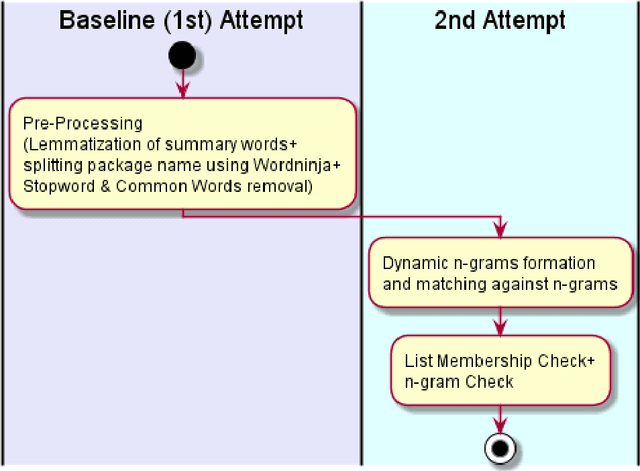
This document describes a possible approach that can be used to check the relevance of a summary / definition of an entity with respect to its name. This classifier focuses on the relevancy of an entity's name to its summary / definition, in other words, it is a name relevance check. The percentage score obtained from this approach can be used either on its own or used to supplement scores obtained from other metrics to arrive upon a final classification; at the end of the document, potential improvements have also been outlined. The dataset that this document focuses on achieving an objective score is a list of package names and their respective summaries (sourced from pypi.org).