 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
The More You See in 2D, the More You Perceive in 3D
Apr 04, 2024
Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
DPMesh: Exploiting Diffusion Prior for Occluded Human Mesh Recovery
Apr 01, 2024The recovery of occluded human meshes presents challenges for current methods due to the difficulty in extracting effective image features under severe occlusion. In this paper, we introduce DPMesh, an innovative framework for occluded human mesh recovery that capitalizes on the profound diffusion prior about object structure and spatial relationships embedded in a pre-trained text-to-image diffusion model. Unlike previous methods reliant on conventional backbones for vanilla feature extraction, DPMesh seamlessly integrates the pre-trained denoising U-Net with potent knowledge as its image backbone and performs a single-step inference to provide occlusion-aware information. To enhance the perception capability for occluded poses, DPMesh incorporates well-designed guidance via condition injection, which produces effective controls from 2D observations for the denoising U-Net. Furthermore, we explore a dedicated noisy key-point reasoning approach to mitigate disturbances arising from occlusion and crowded scenarios. This strategy fully unleashes the perceptual capability of the diffusion prior, thereby enhancing accuracy. Extensive experiments affirm the efficacy of our framework, as we outperform state-of-the-art methods on both occlusion-specific and standard datasets. The persuasive results underscore its ability to achieve precise and robust 3D human mesh recovery, particularly in challenging scenarios involving occlusion and crowded scenes.
Strong and Controllable Blind Image Decomposition
Mar 15, 2024
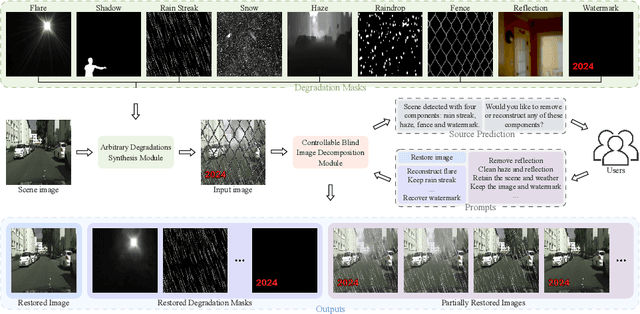

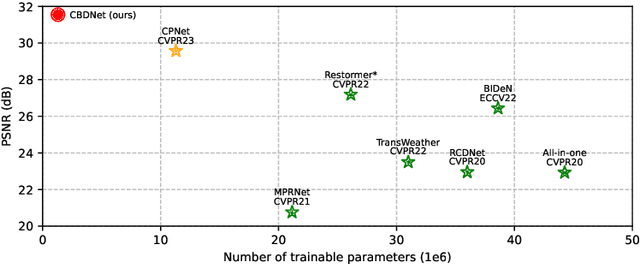
Blind image decomposition aims to decompose all components present in an image, typically used to restore a multi-degraded input image. While fully recovering the clean image is appealing, in some scenarios, users might want to retain certain degradations, such as watermarks, for copyright protection. To address this need, we add controllability to the blind image decomposition process, allowing users to enter which types of degradation to remove or retain. We design an architecture named controllable blind image decomposition network. Inserted in the middle of U-Net structure, our method first decomposes the input feature maps and then recombines them according to user instructions. Advantageously, this functionality is implemented at minimal computational cost: decomposition and recombination are all parameter-free. Experimentally, our system excels in blind image decomposition tasks and can outputs partially or fully restored images that well reflect user intentions. Furthermore, we evaluate and configure different options for the network structure and loss functions. This, combined with the proposed decomposition-and-recombination method, yields an efficient and competitive system for blind image decomposition, compared with current state-of-the-art methods.
Compress3D: a Compressed Latent Space for 3D Generation from a Single Image
Mar 20, 2024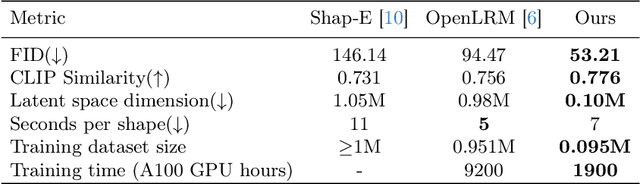
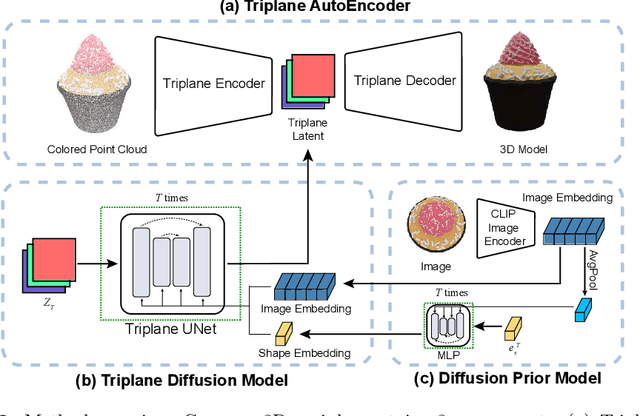

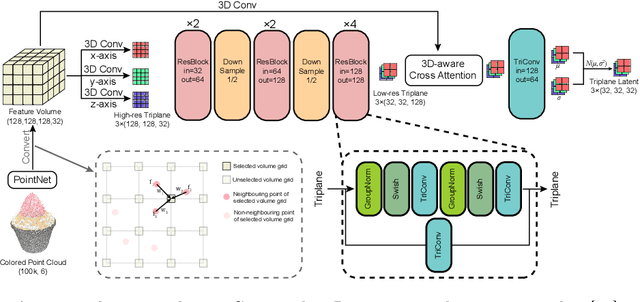
3D generation has witnessed significant advancements, yet efficiently producing high-quality 3D assets from a single image remains challenging. In this paper, we present a triplane autoencoder, which encodes 3D models into a compact triplane latent space to effectively compress both the 3D geometry and texture information. Within the autoencoder framework, we introduce a 3D-aware cross-attention mechanism, which utilizes low-resolution latent representations to query features from a high-resolution 3D feature volume, thereby enhancing the representation capacity of the latent space. Subsequently, we train a diffusion model on this refined latent space. In contrast to solely relying on image embedding for 3D generation, our proposed method advocates for the simultaneous utilization of both image embedding and shape embedding as conditions. Specifically, the shape embedding is estimated via a diffusion prior model conditioned on the image embedding. Through comprehensive experiments, we demonstrate that our method outperforms state-of-the-art algorithms, achieving superior performance while requiring less training data and time. Our approach enables the generation of high-quality 3D assets in merely 7 seconds on a single A100 GPU.
AGFSync: Leveraging AI-Generated Feedback for Preference Optimization in Text-to-Image Generation
Mar 20, 2024
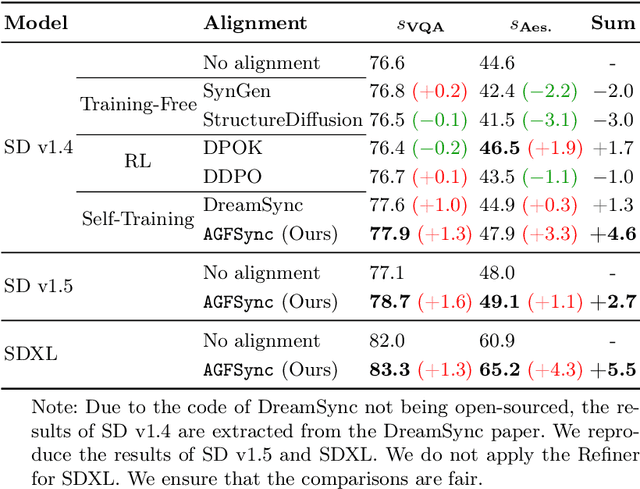
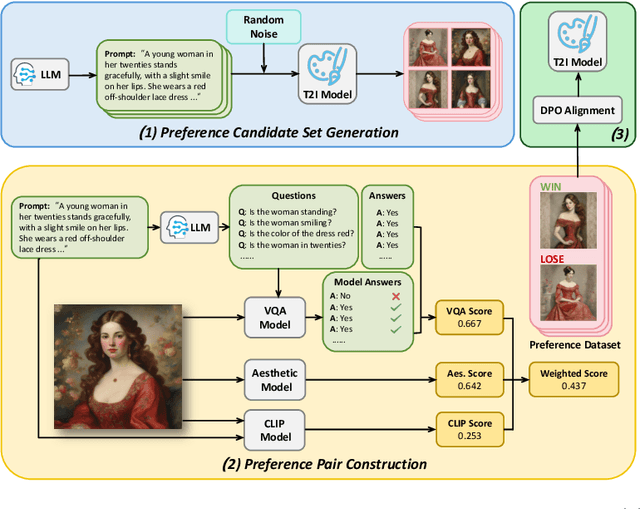
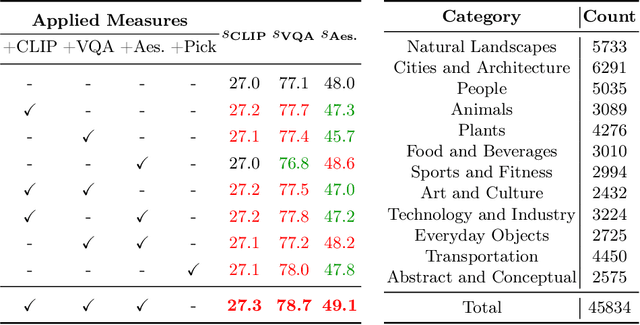
Text-to-Image (T2I) diffusion models have achieved remarkable success in image generation. Despite their progress, challenges remain in both prompt-following ability, image quality and lack of high-quality datasets, which are essential for refining these models. As acquiring labeled data is costly, we introduce AGFSync, a framework that enhances T2I diffusion models through Direct Preference Optimization (DPO) in a fully AI-driven approach. AGFSync utilizes Vision-Language Models (VLM) to assess image quality across style, coherence, and aesthetics, generating feedback data within an AI-driven loop. By applying AGFSync to leading T2I models such as SD v1.4, v1.5, and SDXL, our extensive experiments on the TIFA dataset demonstrate notable improvements in VQA scores, aesthetic evaluations, and performance on the HPSv2 benchmark, consistently outperforming the base models. AGFSync's method of refining T2I diffusion models paves the way for scalable alignment techniques.
Grid Diffusion Models for Text-to-Video Generation
Mar 30, 2024Recent advances in the diffusion models have significantly improved text-to-image generation. However, generating videos from text is a more challenging task than generating images from text, due to the much larger dataset and higher computational cost required. Most existing video generation methods use either a 3D U-Net architecture that considers the temporal dimension or autoregressive generation. These methods require large datasets and are limited in terms of computational costs compared to text-to-image generation. To tackle these challenges, we propose a simple but effective novel grid diffusion for text-to-video generation without temporal dimension in architecture and a large text-video paired dataset. We can generate a high-quality video using a fixed amount of GPU memory regardless of the number of frames by representing the video as a grid image. Additionally, since our method reduces the dimensions of the video to the dimensions of the image, various image-based methods can be applied to videos, such as text-guided video manipulation from image manipulation. Our proposed method outperforms the existing methods in both quantitative and qualitative evaluations, demonstrating the suitability of our model for real-world video generation.
Fast Personalized Text-to-Image Syntheses With Attention Injection
Mar 17, 2024
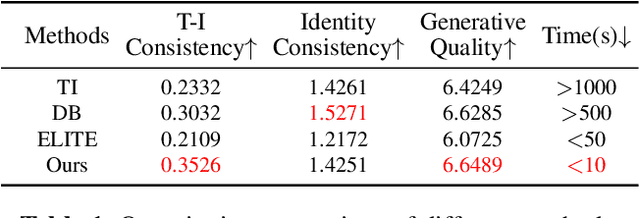
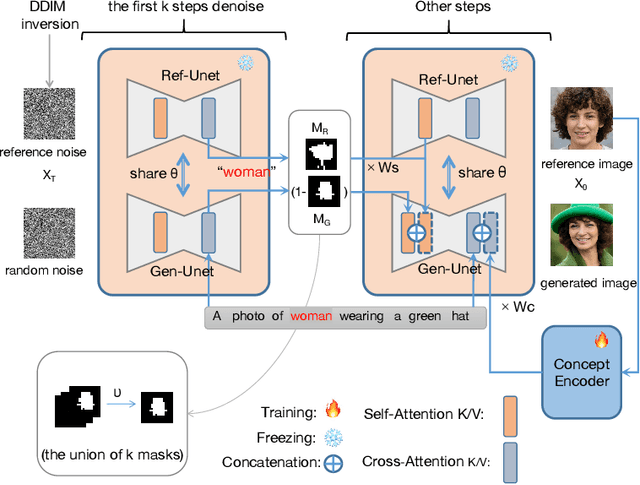
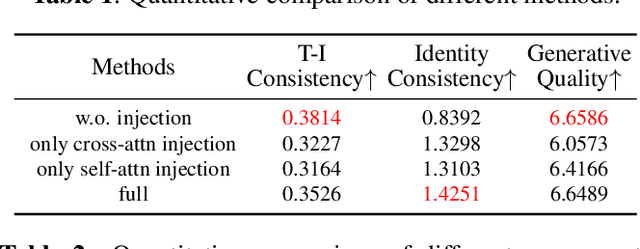
Currently, personalized image generation methods mostly require considerable time to finetune and often overfit the concept resulting in generated images that are similar to custom concepts but difficult to edit by prompts. We propose an effective and fast approach that could balance the text-image consistency and identity consistency of the generated image and reference image. Our method can generate personalized images without any fine-tuning while maintaining the inherent text-to-image generation ability of diffusion models. Given a prompt and a reference image, we merge the custom concept into generated images by manipulating cross-attention and self-attention layers of the original diffusion model to generate personalized images that match the text description. Comprehensive experiments highlight the superiority of our method.
Idea-2-3D: Collaborative LMM Agents Enable 3D Model Generation from Interleaved Multimodal Inputs
Apr 05, 2024In this paper, we pursue a novel 3D AIGC setting: generating 3D content from IDEAs. The definition of an IDEA is the composition of multimodal inputs including text, image, and 3D models. To our knowledge, this challenging and appealing 3D AIGC setting has not been studied before. We propose the novel framework called Idea-2-3D to achieve this goal, which consists of three agents based upon large multimodel models (LMMs) and several existing algorithmic tools for them to invoke. Specifically, these three LMM-based agents are prompted to do the jobs of prompt generation, model selection and feedback reflection. They work in a cycle that involves both mutual collaboration and criticism. Note that this cycle is done in a fully automatic manner, without any human intervention. The framework then outputs a text prompt to generate 3D models that well align with input IDEAs. We show impressive 3D AIGC results that are beyond any previous methods can achieve. For quantitative comparisons, we construct caption-based baselines using a whole bunch of state-of-the-art 3D AIGC models and demonstrate Idea-2-3D out-performs significantly. In 94.2% of cases, Idea-2-3D meets users' requirements, marking a degree of match between IDEA and 3D models that is 2.3 times higher than baselines. Moreover, in 93.5% of the cases, users agreed that Idea-2-3D was better than baselines. Codes, data and models will made publicly available.
EGTR: Extracting Graph from Transformer for Scene Graph Generation
Apr 05, 2024Scene Graph Generation (SGG) is a challenging task of detecting objects and predicting relationships between objects. After DETR was developed, one-stage SGG models based on a one-stage object detector have been actively studied. However, complex modeling is used to predict the relationship between objects, and the inherent relationship between object queries learned in the multi-head self-attention of the object detector has been neglected. We propose a lightweight one-stage SGG model that extracts the relation graph from the various relationships learned in the multi-head self-attention layers of the DETR decoder. By fully utilizing the self-attention by-products, the relation graph can be extracted effectively with a shallow relation extraction head. Considering the dependency of the relation extraction task on the object detection task, we propose a novel relation smoothing technique that adjusts the relation label adaptively according to the quality of the detected objects. By the relation smoothing, the model is trained according to the continuous curriculum that focuses on object detection task at the beginning of training and performs multi-task learning as the object detection performance gradually improves. Furthermore, we propose a connectivity prediction task that predicts whether a relation exists between object pairs as an auxiliary task of the relation extraction. We demonstrate the effectiveness and efficiency of our method for the Visual Genome and Open Image V6 datasets. Our code is publicly available at https://github.com/naver-ai/egtr.
Heterogeneous Peridynamic Neural Operators: Discover Biotissue Constitutive Law and Microstructure From Digital Image Correlation Measurements
Mar 27, 2024Human tissues are highly organized structures with specific collagen fiber arrangements varying from point to point. The effects of such heterogeneity play an important role for tissue function, and hence it is of critical to discover and understand the distribution of such fiber orientations from experimental measurements, such as the digital image correlation data. To this end, we introduce the heterogeneous peridynamic neural operator (HeteroPNO) approach, for data-driven constitutive modeling of heterogeneous anisotropic materials. The goal is to learn both a nonlocal constitutive law together with the material microstructure, in the form of a heterogeneous fiber orientation field, from loading field-displacement field measurements. To this end, we propose a two-phase learning approach. Firstly, we learn a homogeneous constitutive law in the form of a neural network-based kernel function and a nonlocal bond force, to capture complex homogeneous material responses from data. Then, in the second phase we reinitialize the learnt bond force and the kernel function, and training them together with a fiber orientation field for each material point. Owing to the state-based peridynamic skeleton, our HeteroPNO-learned material models are objective and have the balance of linear and angular momentum guaranteed. Moreover, the effects from heterogeneity and nonlinear constitutive relationship are captured by the kernel function and the bond force respectively, enabling physical interpretability. As a result, our HeteroPNO architecture can learn a constitutive model for a biological tissue with anisotropic heterogeneous response undergoing large deformation regime. Moreover, the framework is capable to provide displacement and stress field predictions for new and unseen loading instances.