 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Reasoning Breaks: Logic-Aware Path Selection by Controlling Logical Connectives in LLMs Reasoning Chains
Apr 22, 2026While LLMs demonstrate impressive reasoning capabilities, they remain fragile in multi-step logical deduction, where a single transition error can propagate through the entire reasoning chain, leading to unstable performance. In this work, we identify logical connectives as primary points of this structural fragility. Through empirical analysis, we show that connective tokens function as high entropy forking points, at which models frequently struggle to determine the correct logical direction. Motivated by this observation, we hypothesize that intervening in logical connective selection can guide LLMs toward more correct logical direction, thereby improving the overall reasoning chain. To validate this hypothesis, we propose a multi-layered framework that intervenes specifically at these logic-critical junctions in the reasoning process. Our framework includes (1) Gradient-based Logical Steering to guide LLMs internal representations towards valid reasoning subspaces, (2) Localized Branching to resolve ambiguity via targeted look-ahead search, and (3) Targeted Transition Preference Optimization, a surgical reinforcement learning objective that selectively optimizes single-token preferences at logical pivots. Crucially, by concentrating intervention solely on logic-critical transitions, our framework achieves a favorable accuracy--efficiency trade-off compared to global inference time scaling methods like beam search and self-consistency.
Focus, Don't Prune: Identifying Instruction-Relevant Regions for Information-Rich Image Understanding
Mar 24, 2026Large Vision-Language Models (LVLMs) have shown strong performance across various multimodal tasks by leveraging the reasoning capabilities of Large Language Models (LLMs). However, processing visually complex and information-rich images, such as infographics or document layouts, requires these models to generate a large number of visual tokens, leading to significant computational overhead. To address this, we propose PinPoint, a novel two-stage framework that first identifies instruction-relevant image regions and then refines them to extract fine-grained visual features for improved reasoning and efficiency. Central to our approach is the Instruction-Region Alignment, which localizes relevant regions using both visual input and textual instructions. We further introduce new annotations that provide richer ground-truth supervision for instruction-relevant regions across challenging VQA benchmarks: InfographicVQA, MultiPageDocVQA, and SinglePageDocVQA. Experimental results show that PinPoint not only achieves superior accuracy compared to existing methods but also reduces computational overhead by minimizing irrelevant visual tokens.
Watermarking for Factuality: Guiding Vision-Language Models Toward Truth via Tri-layer Contrastive Decoding
Oct 16, 2025Large Vision-Language Models (LVLMs) have recently shown promising results on various multimodal tasks, even achieving human-comparable performance in certain cases. Nevertheless, LVLMs remain prone to hallucinations -- they often rely heavily on a single modality or memorize training data without properly grounding their outputs. To address this, we propose a training-free, tri-layer contrastive decoding with watermarking, which proceeds in three steps: (1) select a mature layer and an amateur layer among the decoding layers, (2) identify a pivot layer using a watermark-related question to assess whether the layer is visually well-grounded, and (3) apply tri-layer contrastive decoding to generate the final output. Experiments on public benchmarks such as POPE, MME and AMBER demonstrate that our method achieves state-of-the-art performance in reducing hallucinations in LVLMs and generates more visually grounded responses.
CREPE: Coordinate-Aware End-to-End Document Parser
May 01, 2024



In this study, we formulate an OCR-free sequence generation model for visual document understanding (VDU). Our model not only parses text from document images but also extracts the spatial coordinates of the text based on the multi-head architecture. Named as Coordinate-aware End-to-end Document Parser (CREPE), our method uniquely integrates these capabilities by introducing a special token for OCR text, and token-triggered coordinate decoding. We also proposed a weakly-supervised framework for cost-efficient training, requiring only parsing annotations without high-cost coordinate annotations. Our experimental evaluations demonstrate CREPE's state-of-the-art performances on document parsing tasks. Beyond that, CREPE's adaptability is further highlighted by its successful usage in other document understanding tasks such as layout analysis, document visual question answering, and so one. CREPE's abilities including OCR and semantic parsing not only mitigate error propagation issues in existing OCR-dependent methods, it also significantly enhance the functionality of sequence generation models, ushering in a new era for document understanding studies.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
EGTR: Extracting Graph from Transformer for Scene Graph Generation
Apr 05, 2024



Scene Graph Generation (SGG) is a challenging task of detecting objects and predicting relationships between objects. After DETR was developed, one-stage SGG models based on a one-stage object detector have been actively studied. However, complex modeling is used to predict the relationship between objects, and the inherent relationship between object queries learned in the multi-head self-attention of the object detector has been neglected. We propose a lightweight one-stage SGG model that extracts the relation graph from the various relationships learned in the multi-head self-attention layers of the DETR decoder. By fully utilizing the self-attention by-products, the relation graph can be extracted effectively with a shallow relation extraction head. Considering the dependency of the relation extraction task on the object detection task, we propose a novel relation smoothing technique that adjusts the relation label adaptively according to the quality of the detected objects. By the relation smoothing, the model is trained according to the continuous curriculum that focuses on object detection task at the beginning of training and performs multi-task learning as the object detection performance gradually improves. Furthermore, we propose a connectivity prediction task that predicts whether a relation exists between object pairs as an auxiliary task of the relation extraction. We demonstrate the effectiveness and efficiency of our method for the Visual Genome and Open Image V6 datasets. Our code is publicly available at https://github.com/naver-ai/egtr.
Cream: Visually-Situated Natural Language Understanding with Contrastive Reading Model and Frozen Large Language Models
May 24, 2023



Advances in Large Language Models (LLMs) have inspired a surge of research exploring their expansion into the visual domain. While recent models exhibit promise in generating abstract captions for images and conducting natural conversations, their performance on text-rich images leaves room for improvement. In this paper, we propose the Contrastive Reading Model (Cream), a novel neural architecture designed to enhance the language-image understanding capability of LLMs by capturing intricate details typically overlooked by existing methods. Cream integrates vision and auxiliary encoders, complemented by a contrastive feature alignment technique, resulting in a more effective understanding of textual information within document images. Our approach, thus, seeks to bridge the gap between vision and language understanding, paving the way for more sophisticated Document Intelligence Assistants. Rigorous evaluations across diverse tasks, such as visual question answering on document images, demonstrate the efficacy of Cream as a state-of-the-art model in the field of visual document understanding. We provide our codebase and newly-generated datasets at https://github.com/naver-ai/cream
Grounding Visual Representations with Texts for Domain Generalization
Jul 21, 2022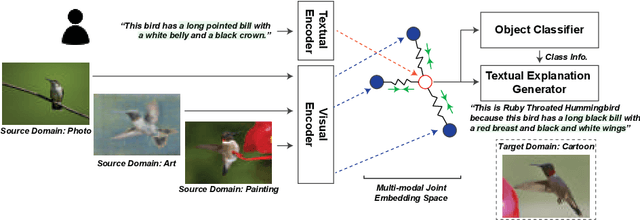
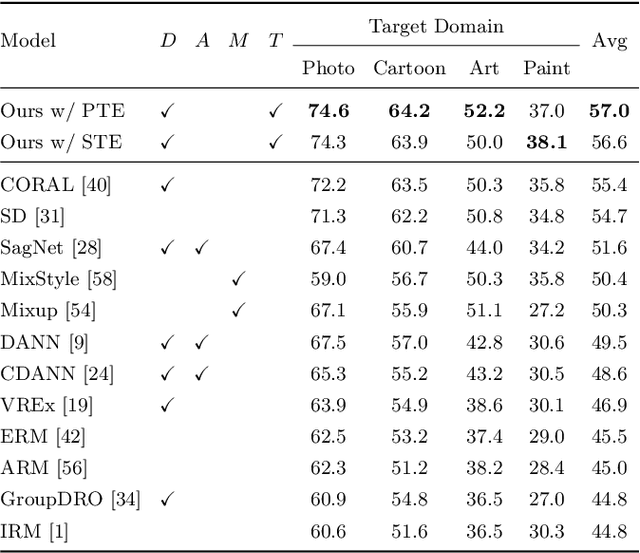
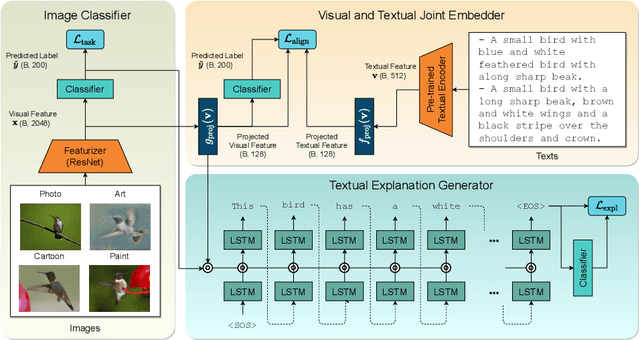
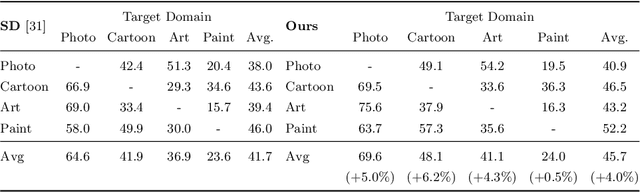
Reducing the representational discrepancy between source and target domains is a key component to maximize the model generalization. In this work, we advocate for leveraging natural language supervision for the domain generalization task. We introduce two modules to ground visual representations with texts containing typical reasoning of humans: (1) Visual and Textual Joint Embedder and (2) Textual Explanation Generator. The former learns the image-text joint embedding space where we can ground high-level class-discriminative information into the model. The latter leverages an explainable model and generates explanations justifying the rationale behind its decision. To the best of our knowledge, this is the first work to leverage the vision-and-language cross-modality approach for the domain generalization task. Our experiments with a newly created CUB-DG benchmark dataset demonstrate that cross-modality supervision can be successfully used to ground domain-invariant visual representations and improve the model generalization. Furthermore, in the large-scale DomainBed benchmark, our proposed method achieves state-of-the-art results and ranks 1st in average performance for five multi-domain datasets. The dataset and codes are available at https://github.com/mswzeus/GVRT.
An Embedding-Dynamic Approach to Self-supervised Learning
Jul 07, 2022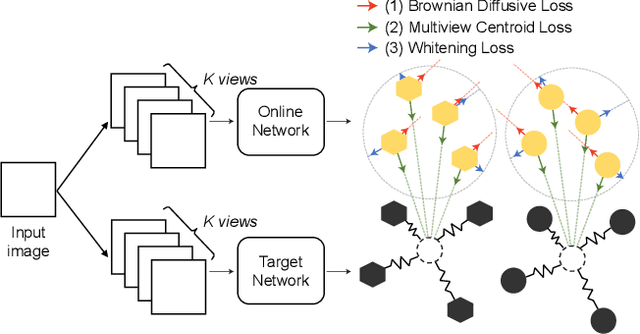
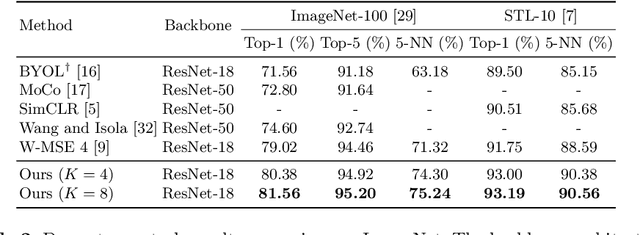
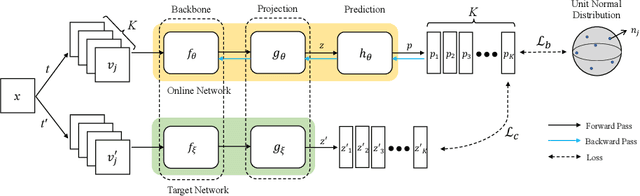
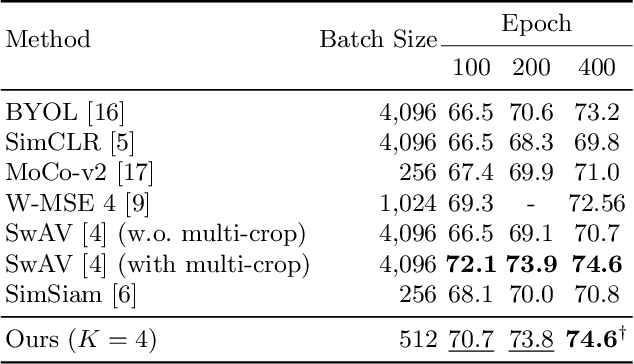
A number of recent self-supervised learning methods have shown impressive performance on image classification and other tasks. A somewhat bewildering variety of techniques have been used, not always with a clear understanding of the reasons for their benefits, especially when used in combination. Here we treat the embeddings of images as point particles and consider model optimization as a dynamic process on this system of particles. Our dynamic model combines an attractive force for similar images, a locally dispersive force to avoid local collapse, and a global dispersive force to achieve a globally-homogeneous distribution of particles. The dynamic perspective highlights the advantage of using a delayed-parameter image embedding (a la BYOL) together with multiple views of the same image. It also uses a purely-dynamic local dispersive force (Brownian motion) that shows improved performance over other methods and does not require knowledge of other particle coordinates. The method is called MSBReg which stands for (i) a Multiview centroid loss, which applies an attractive force to pull different image view embeddings toward their centroid, (ii) a Singular value loss, which pushes the particle system toward spatially homogeneous density, (iii) a Brownian diffusive loss. We evaluate downstream classification performance of MSBReg on ImageNet as well as transfer learning tasks including fine-grained classification, multi-class object classification, object detection, and instance segmentation. In addition, we also show that applying our regularization term to other methods further improves their performance and stabilize the training by preventing a mode collapse.
DEER: Detection-agnostic End-to-End Recognizer for Scene Text Spotting
Mar 10, 2022
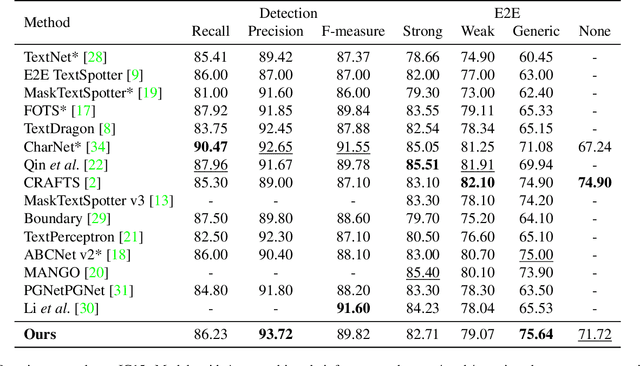
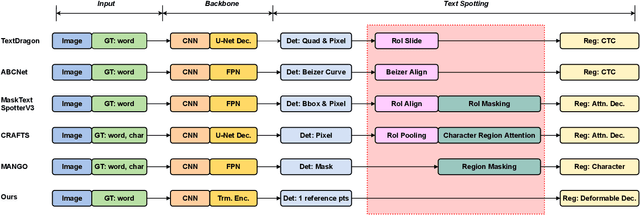
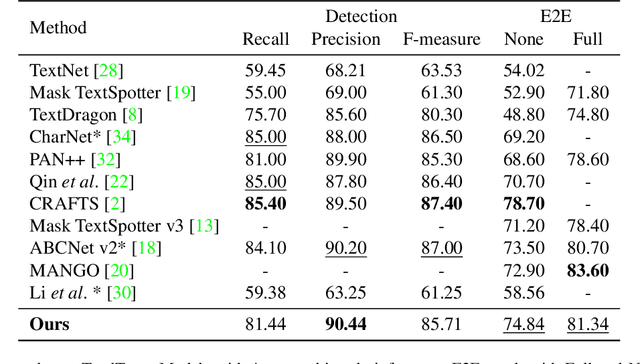
Recent end-to-end scene text spotters have achieved great improvement in recognizing arbitrary-shaped text instances. Common approaches for text spotting use region of interest pooling or segmentation masks to restrict features to single text instances. However, this makes it hard for the recognizer to decode correct sequences when the detection is not accurate i.e. one or more characters are cropped out. Considering that it is hard to accurately decide word boundaries with only the detector, we propose a novel Detection-agnostic End-to-End Recognizer, DEER, framework. The proposed method reduces the tight dependency between detection and recognition modules by bridging them with a single reference point for each text instance, instead of using detected regions. The proposed method allows the decoder to recognize the texts that are indicated by the reference point, with features from the whole image. Since only a single point is required to recognize the text, the proposed method enables text spotting without an arbitrarily-shaped detector or bounding polygon annotations. Experimental results present that the proposed method achieves competitive results on regular and arbitrarily-shaped text spotting benchmarks. Further analysis shows that DEER is robust to the detection errors. The code and dataset will be publicly available.