 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Depth Completion with Multiple Balanced Bases and Confidence for Dense Monocular SLAM
Sep 20, 2023
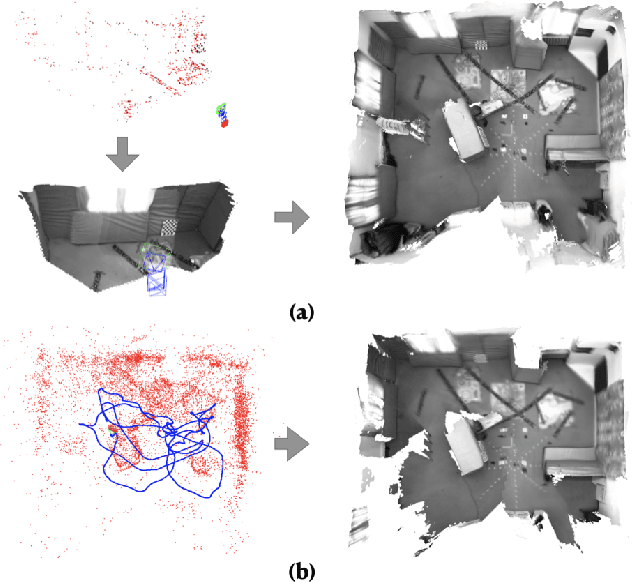



Dense SLAM based on monocular cameras does indeed have immense application value in the field of AR/VR, especially when it is performed on a mobile device. In this paper, we propose a novel method that integrates a light-weight depth completion network into a sparse SLAM system using a multi-basis depth representation, so that dense mapping can be performed online even on a mobile phone. Specifically, we present a specifically optimized multi-basis depth completion network, called BBC-Net, tailored to the characteristics of traditional sparse SLAM systems. BBC-Net can predict multiple balanced bases and a confidence map from a monocular image with sparse points generated by off-the-shelf keypoint-based SLAM systems. The final depth is a linear combination of predicted depth bases that can be optimized by tuning the corresponding weights. To seamlessly incorporate the weights into traditional SLAM optimization and ensure efficiency and robustness, we design a set of depth weight factors, which makes our network a versatile plug-in module, facilitating easy integration into various existing sparse SLAM systems and significantly enhancing global depth consistency through bundle adjustment. To verify the portability of our method, we integrate BBC-Net into two representative SLAM systems. The experimental results on various datasets show that the proposed method achieves better performance in monocular dense mapping than the state-of-the-art methods. We provide an online demo running on a mobile phone, which verifies the efficiency and mapping quality of the proposed method in real-world scenarios.
Reference-based Motion Blur Removal: Learning to Utilize Sharpness in the Reference Image
Jul 06, 2023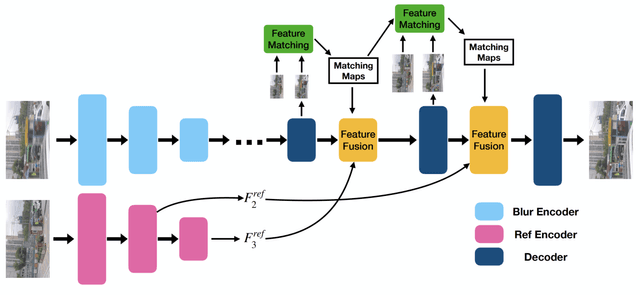
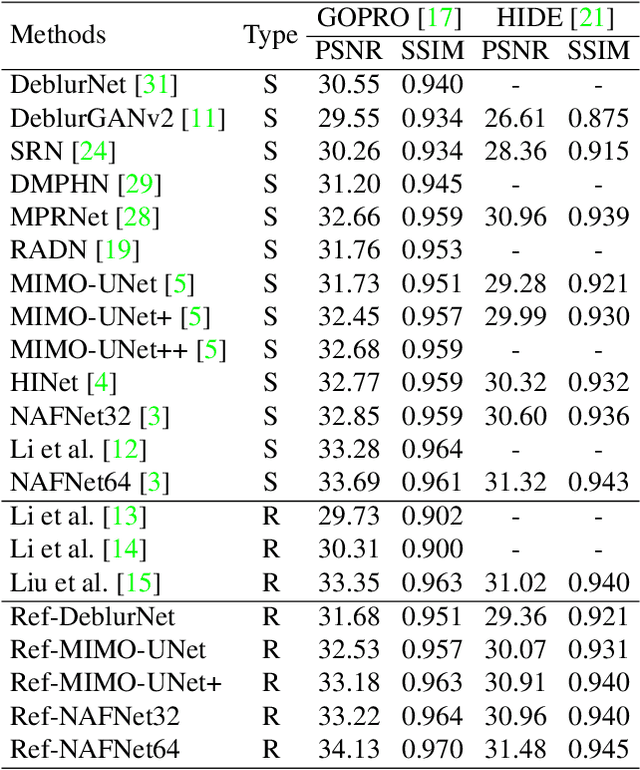
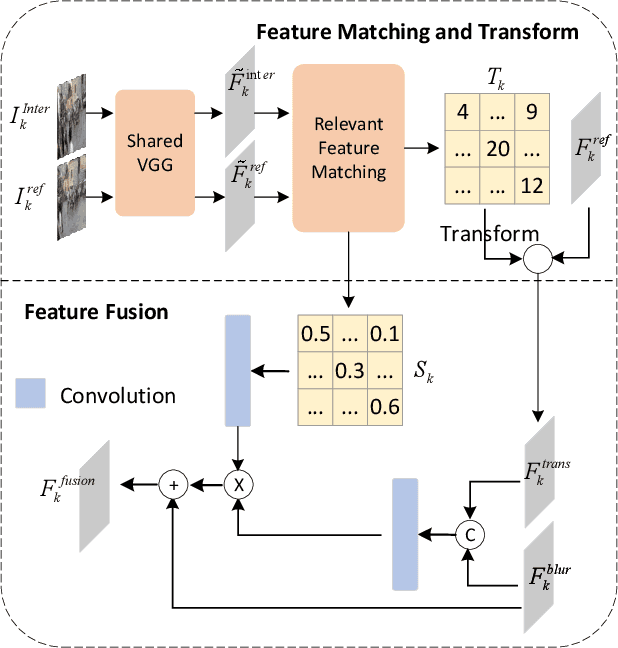
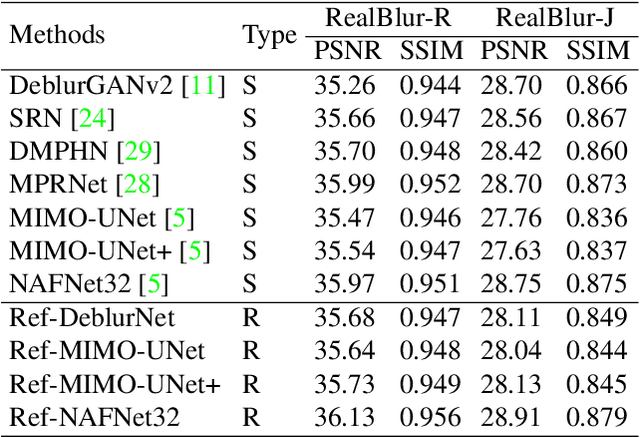
Despite the recent advancement in the study of removing motion blur in an image, it is still hard to deal with strong blurs. While there are limits in removing blurs from a single image, it has more potential to use multiple images, e.g., using an additional image as a reference to deblur a blurry image. A typical setting is deburring an image using a nearby sharp image(s) in a video sequence, as in the studies of video deblurring. This paper proposes a better method to use the information present in a reference image. The method does not need a strong assumption on the reference image. We can utilize an alternative shot of the identical scene, just like in video deblurring, or we can even employ a distinct image from another scene. Our method first matches local patches of the target and reference images and then fuses their features to estimate a sharp image. We employ a patch-based feature matching strategy to solve the difficult problem of matching the blurry image with the sharp reference. Our method can be integrated into pre-existing networks designed for single image deblurring. The experimental results show the effectiveness of the proposed method.
Comparative study of Deep Learning Models for Binary Classification on Combined Pulmonary Chest X-ray Dataset
Sep 16, 2023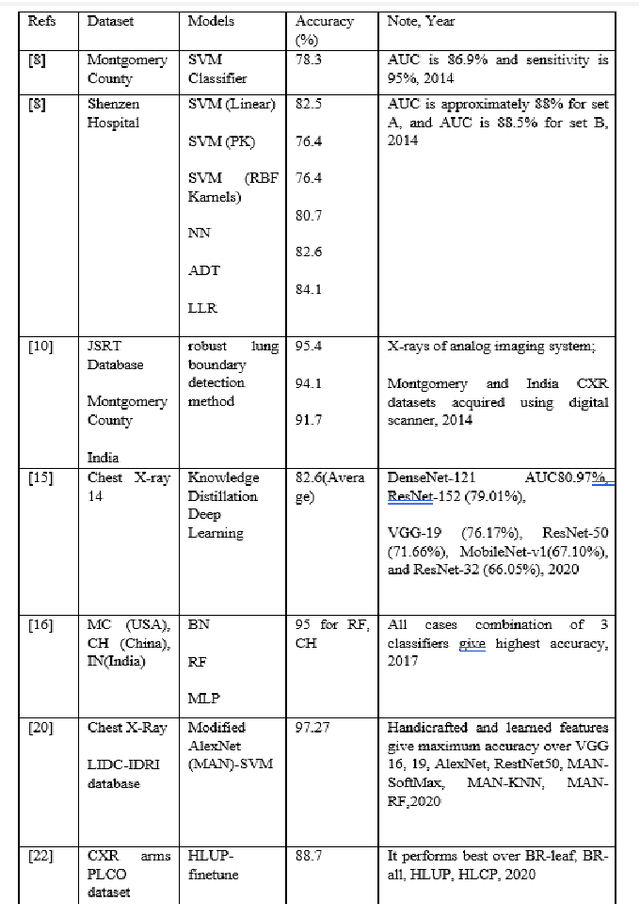
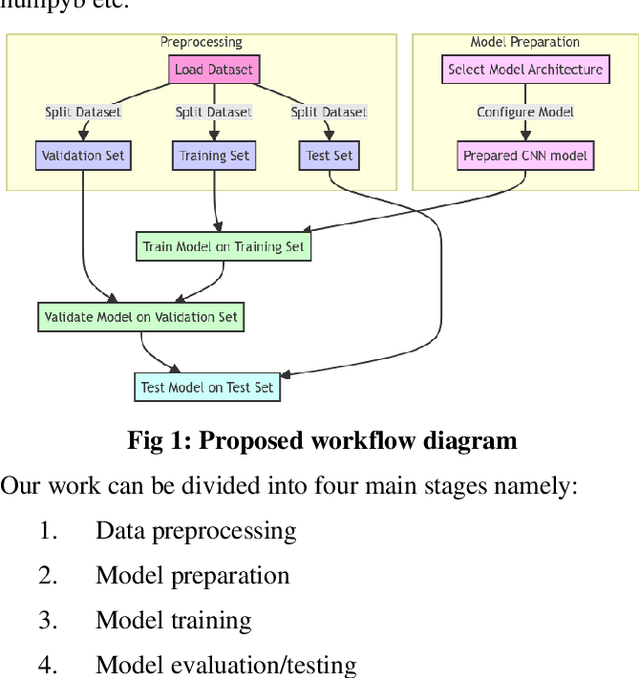
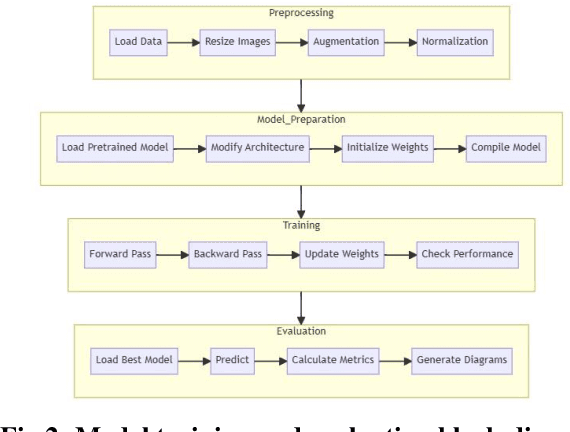
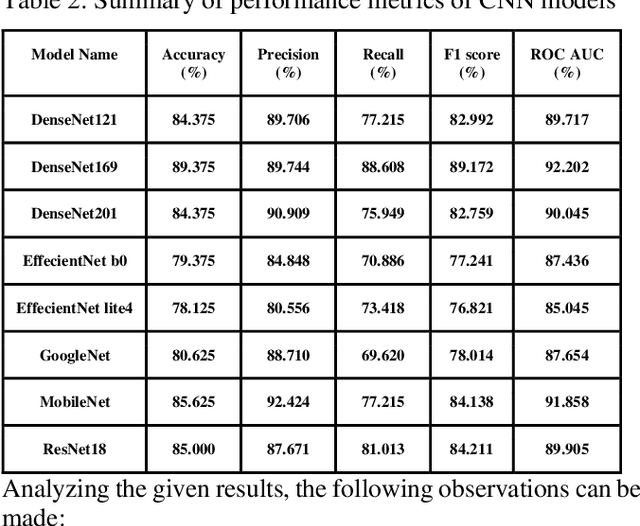
CNN-based deep learning models for disease detection have become popular recently. We compared the binary classification performance of eight prominent deep learning models: DenseNet 121, DenseNet 169, DenseNet 201, EffecientNet b0, EffecientNet lite4, GoogleNet, MobileNet, and ResNet18 for their binary classification performance on combined Pulmonary Chest Xrays dataset. Despite the widespread application in different fields in medical images, there remains a knowledge gap in determining their relative performance when applied to the same dataset, a gap this study aimed to address. The dataset combined Shenzhen, China (CH) and Montgomery, USA (MC) data. We trained our model for binary classification, calculated different parameters of the mentioned models, and compared them. The models were trained to keep in mind all following the same training parameters to maintain a controlled comparison environment. End of the study, we found a distinct difference in performance among the other models when applied to the pulmonary chest Xray image dataset, where DenseNet169 performed with 89.38 percent and MobileNet with 92.2 percent precision. Keywords: Pulmonary, Deep Learning, Tuberculosis, Disease detection, Xray
Leveraging the Power of Data Augmentation for Transformer-based Tracking
Sep 15, 2023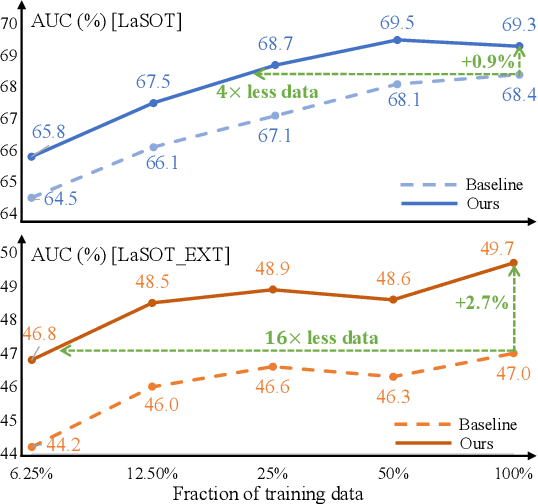



Due to long-distance correlation and powerful pretrained models, transformer-based methods have initiated a breakthrough in visual object tracking performance. Previous works focus on designing effective architectures suited for tracking, but ignore that data augmentation is equally crucial for training a well-performing model. In this paper, we first explore the impact of general data augmentations on transformer-based trackers via systematic experiments, and reveal the limited effectiveness of these common strategies. Motivated by experimental observations, we then propose two data augmentation methods customized for tracking. First, we optimize existing random cropping via a dynamic search radius mechanism and simulation for boundary samples. Second, we propose a token-level feature mixing augmentation strategy, which enables the model against challenges like background interference. Extensive experiments on two transformer-based trackers and six benchmarks demonstrate the effectiveness and data efficiency of our methods, especially under challenging settings, like one-shot tracking and small image resolutions.
HINT: Healthy Influential-Noise based Training to Defend against Data Poisoning Attacks
Sep 15, 2023While numerous defense methods have been proposed to prohibit potential poisoning attacks from untrusted data sources, most research works only defend against specific attacks, which leaves many avenues for an adversary to exploit. In this work, we propose an efficient and robust training approach to defend against data poisoning attacks based on influence functions, named Healthy Influential-Noise based Training. Using influence functions, we craft healthy noise that helps to harden the classification model against poisoning attacks without significantly affecting the generalization ability on test data. In addition, our method can perform effectively when only a subset of the training data is modified, instead of the current method of adding noise to all examples that has been used in several previous works. We conduct comprehensive evaluations over two image datasets with state-of-the-art poisoning attacks under different realistic attack scenarios. Our empirical results show that HINT can efficiently protect deep learning models against the effect of both untargeted and targeted poisoning attacks.
Class Attention to Regions of Lesion for Imbalanced Medical Image Recognition
Jul 20, 2023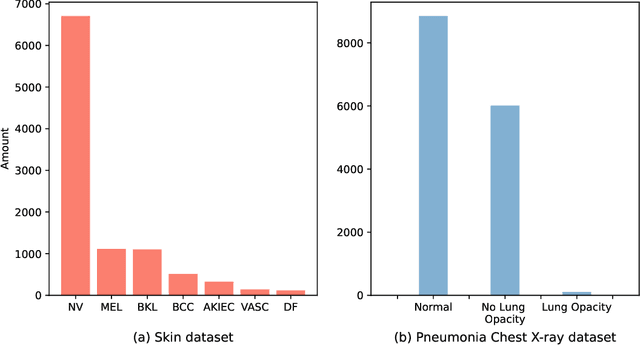

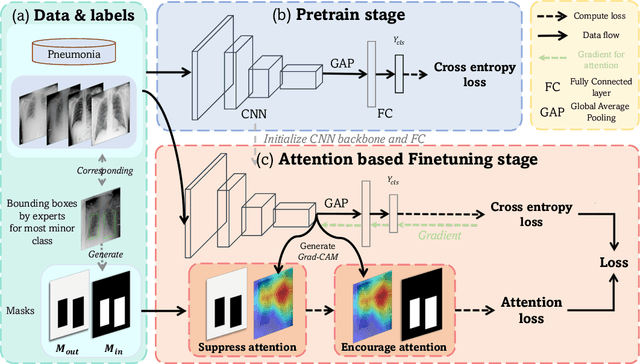
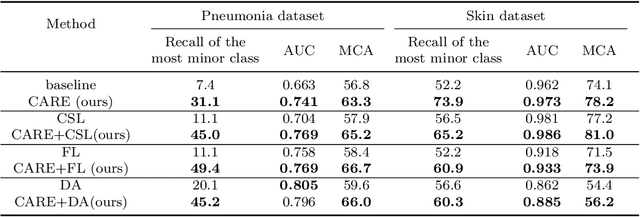
Automated medical image classification is the key component in intelligent diagnosis systems. However, most medical image datasets contain plenty of samples of common diseases and just a handful of rare ones, leading to major class imbalances. Currently, it is an open problem in intelligent diagnosis to effectively learn from imbalanced training data. In this paper, we propose a simple yet effective framework, named \textbf{C}lass \textbf{A}ttention to \textbf{RE}gions of the lesion (CARE), to handle data imbalance issues by embedding attention into the training process of \textbf{C}onvolutional \textbf{N}eural \textbf{N}etworks (CNNs). The proposed attention module helps CNNs attend to lesion regions of rare diseases, therefore helping CNNs to learn their characteristics more effectively. In addition, this attention module works only during the training phase and does not change the architecture of the original network, so it can be directly combined with any existing CNN architecture. The CARE framework needs bounding boxes to represent the lesion regions of rare diseases. To alleviate the need for manual annotation, we further developed variants of CARE by leveraging the traditional saliency methods or a pretrained segmentation model for bounding box generation. Results show that the CARE variants with automated bounding box generation are comparable to the original CARE framework with \textit{manual} bounding box annotations. A series of experiments on an imbalanced skin image dataset and a pneumonia dataset indicates that our method can effectively help the network focus on the lesion regions of rare diseases and remarkably improves the classification performance of rare diseases.
Stage-by-stage Wavelet Optimization Refinement Diffusion Model for Sparse-View CT Reconstruction
Sep 03, 2023Diffusion models have emerged as potential tools to tackle the challenge of sparse-view CT reconstruction, displaying superior performance compared to conventional methods. Nevertheless, these prevailing diffusion models predominantly focus on the sinogram or image domains, which can lead to instability during model training, potentially culminating in convergence towards local minimal solutions. The wavelet trans-form serves to disentangle image contents and features into distinct frequency-component bands at varying scales, adeptly capturing diverse directional structures. Employing the Wavelet transform as a guiding sparsity prior significantly enhances the robustness of diffusion models. In this study, we present an innovative approach named the Stage-by-stage Wavelet Optimization Refinement Diffusion (SWORD) model for sparse-view CT reconstruction. Specifically, we establish a unified mathematical model integrating low-frequency and high-frequency generative models, achieving the solution with optimization procedure. Furthermore, we perform the low-frequency and high-frequency generative models on wavelet's decomposed components rather than sinogram or image domains, ensuring the stability of model training. Our method rooted in established optimization theory, comprising three distinct stages, including low-frequency generation, high-frequency refinement and domain transform. Our experimental results demonstrate that the proposed method outperforms existing state-of-the-art methods both quantitatively and qualitatively.
Sparse Sampling Transformer with Uncertainty-Driven Ranking for Unified Removal of Raindrops and Rain Streaks
Aug 27, 2023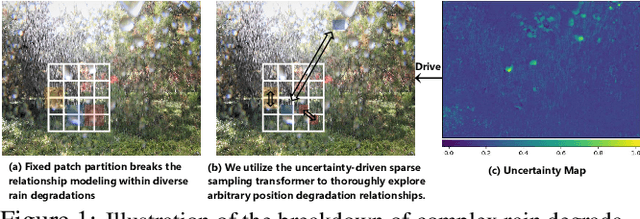
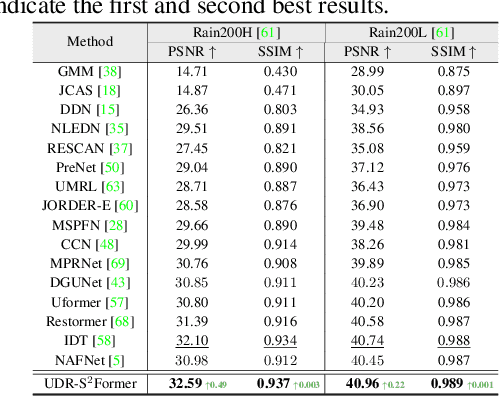
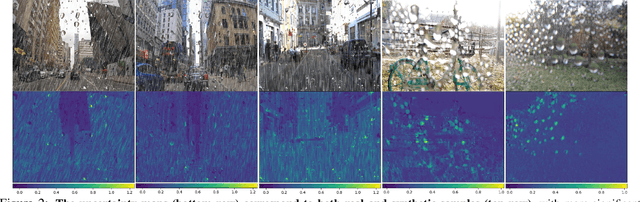
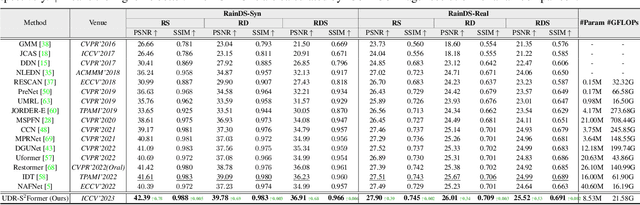
In the real world, image degradations caused by rain often exhibit a combination of rain streaks and raindrops, thereby increasing the challenges of recovering the underlying clean image. Note that the rain streaks and raindrops have diverse shapes, sizes, and locations in the captured image, and thus modeling the correlation relationship between irregular degradations caused by rain artifacts is a necessary prerequisite for image deraining. This paper aims to present an efficient and flexible mechanism to learn and model degradation relationships in a global view, thereby achieving a unified removal of intricate rain scenes. To do so, we propose a Sparse Sampling Transformer based on Uncertainty-Driven Ranking, dubbed UDR-S2Former. Compared to previous methods, our UDR-S2Former has three merits. First, it can adaptively sample relevant image degradation information to model underlying degradation relationships. Second, explicit application of the uncertainty-driven ranking strategy can facilitate the network to attend to degradation features and understand the reconstruction process. Finally, experimental results show that our UDR-S2Former clearly outperforms state-of-the-art methods for all benchmarks.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 05, 2023
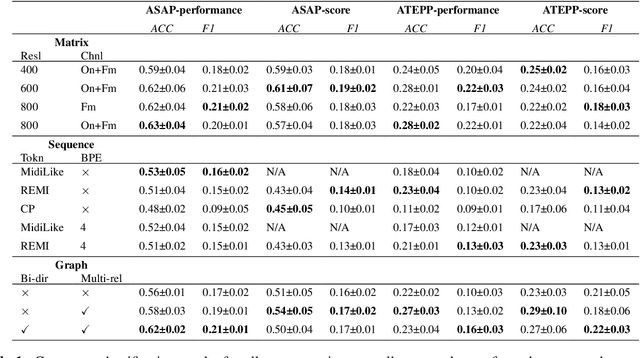
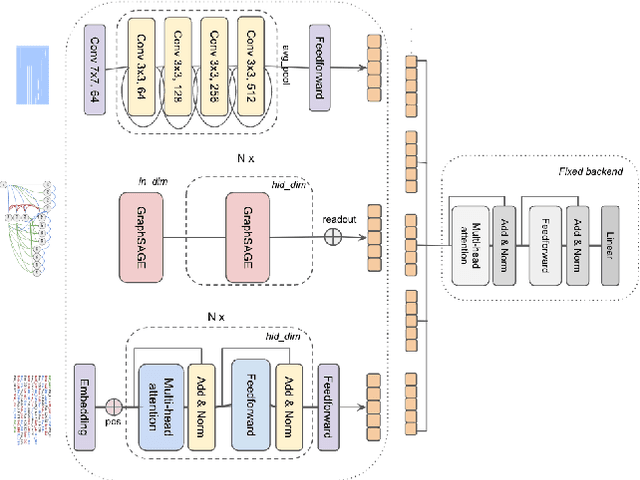
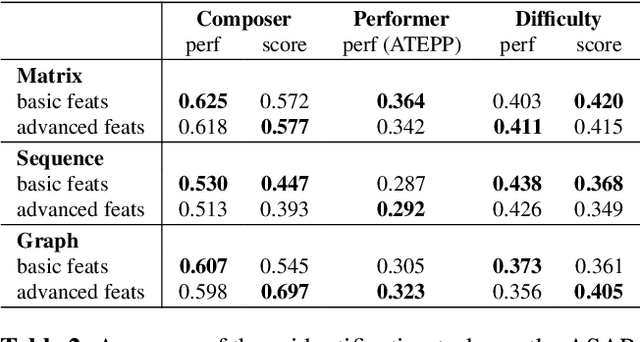
Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
Unsupervised Skin Lesion Segmentation via Structural Entropy Minimization on Multi-Scale Superpixel Graphs
Sep 05, 2023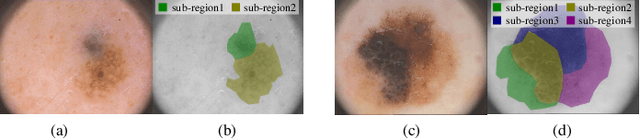
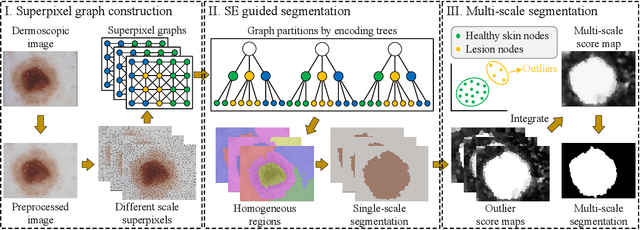
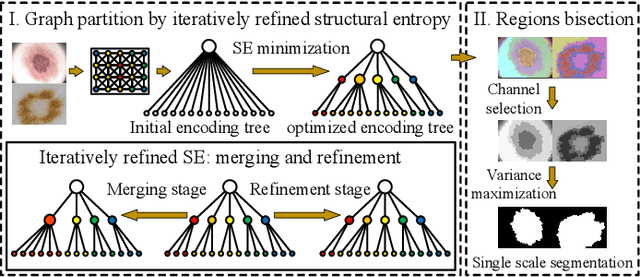

Skin lesion segmentation is a fundamental task in dermoscopic image analysis. The complex features of pixels in the lesion region impede the lesion segmentation accuracy, and existing deep learning-based methods often lack interpretability to this problem. In this work, we propose a novel unsupervised Skin Lesion sEgmentation framework based on structural entropy and isolation forest outlier Detection, namely SLED. Specifically, skin lesions are segmented by minimizing the structural entropy of a superpixel graph constructed from the dermoscopic image. Then, we characterize the consistency of healthy skin features and devise a novel multi-scale segmentation mechanism by outlier detection, which enhances the segmentation accuracy by leveraging the superpixel features from multiple scales. We conduct experiments on four skin lesion benchmarks and compare SLED with nine representative unsupervised segmentation methods. Experimental results demonstrate the superiority of the proposed framework. Additionally, some case studies are analyzed to demonstrate the effectiveness of SLED.