 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeautonomous cars
Autonomous cars are self-driving vehicles that use artificial intelligence (AI) and sensors to navigate and operate without human intervention, using high-resolution cameras and lidars that detect what happens in the car's immediate surroundings. They have the potential to revolutionize transportation by improving safety, efficiency, and accessibility.
Papers and Code
Model-Structured Neural Networks to Control the Steering Dynamics of Autonomous Race Cars
Jul 27, 2025Autonomous racing has gained increasing attention in recent years, as a safe environment to accelerate the development of motion planning and control methods for autonomous driving. Deep learning models, predominantly based on neural networks (NNs), have demonstrated significant potential in modeling the vehicle dynamics and in performing various tasks in autonomous driving. However, their black-box nature is critical in the context of autonomous racing, where safety and robustness demand a thorough understanding of the decision-making algorithms. To address this challenge, this paper proposes MS-NN-steer, a new Model-Structured Neural Network for vehicle steering control, integrating the prior knowledge of the nonlinear vehicle dynamics into the neural architecture. The proposed controller is validated using real-world data from the Abu Dhabi Autonomous Racing League (A2RL) competition, with full-scale autonomous race cars. In comparison with general-purpose NNs, MS-NN-steer is shown to achieve better accuracy and generalization with small training datasets, while being less sensitive to the weights' initialization. Also, MS-NN-steer outperforms the steering controller used by the A2RL winning team. Our implementation is available open-source in a GitHub repository.
MonoCLUE : Object-Aware Clustering Enhances Monocular 3D Object Detection
Nov 11, 2025Monocular 3D object detection offers a cost-effective solution for autonomous driving but suffers from ill-posed depth and limited field of view. These constraints cause a lack of geometric cues and reduced accuracy in occluded or truncated scenes. While recent approaches incorporate additional depth information to address geometric ambiguity, they overlook the visual cues crucial for robust recognition. We propose MonoCLUE, which enhances monocular 3D detection by leveraging both local clustering and generalized scene memory of visual features. First, we perform K-means clustering on visual features to capture distinct object-level appearance parts (e.g., bonnet, car roof), improving detection of partially visible objects. The clustered features are propagated across regions to capture objects with similar appearances. Second, we construct a generalized scene memory by aggregating clustered features across images, providing consistent representations that generalize across scenes. This improves object-level feature consistency, enabling stable detection across varying environments. Lastly, we integrate both local cluster features and generalized scene memory into object queries, guiding attention toward informative regions. Exploiting a unified local clustering and generalized scene memory strategy, MonoCLUE enables robust monocular 3D detection under occlusion and limited visibility, achieving state-of-the-art performance on the KITTI benchmark.
ROAR: Robust Accident Recognition and Anticipation for Autonomous Driving
Nov 09, 2025
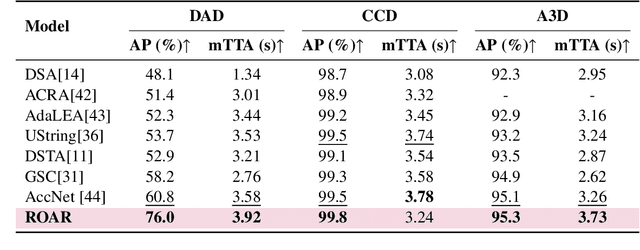
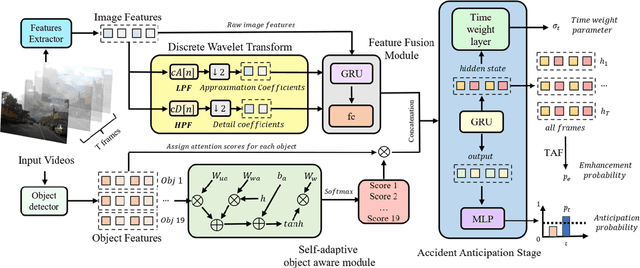
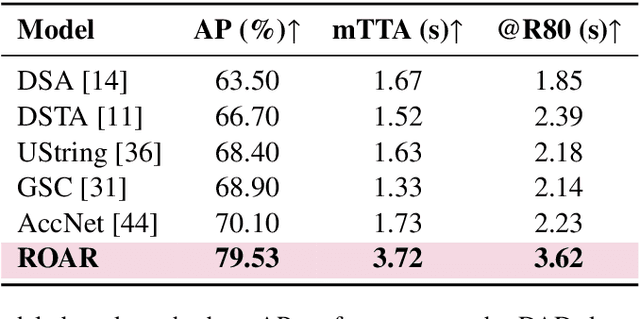
Accurate accident anticipation is essential for enhancing the safety of autonomous vehicles (AVs). However, existing methods often assume ideal conditions, overlooking challenges such as sensor failures, environmental disturbances, and data imperfections, which can significantly degrade prediction accuracy. Additionally, previous models have not adequately addressed the considerable variability in driver behavior and accident rates across different vehicle types. To overcome these limitations, this study introduces ROAR, a novel approach for accident detection and prediction. ROAR combines Discrete Wavelet Transform (DWT), a self adaptive object aware module, and dynamic focal loss to tackle these challenges. The DWT effectively extracts features from noisy and incomplete data, while the object aware module improves accident prediction by focusing on high-risk vehicles and modeling the spatial temporal relationships among traffic agents. Moreover, dynamic focal loss mitigates the impact of class imbalance between positive and negative samples. Evaluated on three widely used datasets, Dashcam Accident Dataset (DAD), Car Crash Dataset (CCD), and AnAn Accident Detection (A3D), our model consistently outperforms existing baselines in key metrics such as Average Precision (AP) and mean Time to Accident (mTTA). These results demonstrate the model's robustness in real-world conditions, particularly in handling sensor degradation, environmental noise, and imbalanced data distributions. This work offers a promising solution for reliable and accurate accident anticipation in complex traffic environments.
Safe Planning in Interactive Environments via Iterative Policy Updates and Adversarially Robust Conformal Prediction
Nov 13, 2025Safe planning of an autonomous agent in interactive environments -- such as the control of a self-driving vehicle among pedestrians and human-controlled vehicles -- poses a major challenge as the behavior of the environment is unknown and reactive to the behavior of the autonomous agent. This coupling gives rise to interaction-driven distribution shifts where the autonomous agent's control policy may change the environment's behavior, thereby invalidating safety guarantees in existing work. Indeed, recent works have used conformal prediction (CP) to generate distribution-free safety guarantees using observed data of the environment. However, CP's assumption on data exchangeability is violated in interactive settings due to a circular dependency where a control policy update changes the environment's behavior, and vice versa. To address this gap, we propose an iterative framework that robustly maintains safety guarantees across policy updates by quantifying the potential impact of a planned policy update on the environment's behavior. We realize this via adversarially robust CP where we perform a regular CP step in each episode using observed data under the current policy, but then transfer safety guarantees across policy updates by analytically adjusting the CP result to account for distribution shifts. This adjustment is performed based on a policy-to-trajectory sensitivity analysis, resulting in a safe, episodic open-loop planner. We further conduct a contraction analysis of the system providing conditions under which both the CP results and the policy updates are guaranteed to converge. We empirically demonstrate these safety and convergence guarantees on a two-dimensional car-pedestrian case study. To the best of our knowledge, these are the first results that provide valid safety guarantees in such interactive settings.
UruBots Autonomous Cars Challenge Pro Team Description Paper for FIRA 2025
Jun 09, 2025



This paper describes the development of an autonomous car by the UruBots team for the 2025 FIRA Autonomous Cars Challenge (Pro). The project involves constructing a compact electric vehicle, approximately the size of an RC car, capable of autonomous navigation through different tracks. The design incorporates mechanical and electronic components and machine learning algorithms that enable the vehicle to make real-time navigation decisions based on visual input from a camera. We use deep learning models to process camera images and control vehicle movements. Using a dataset of over ten thousand images, we trained a Convolutional Neural Network (CNN) to drive the vehicle effectively, through two outputs, steering and throttle. The car completed the track in under 30 seconds, achieving a pace of approximately 0.4 meters per second while avoiding obstacles.
CAMNet: Leveraging Cooperative Awareness Messages for Vehicle Trajectory Prediction
Oct 14, 2025
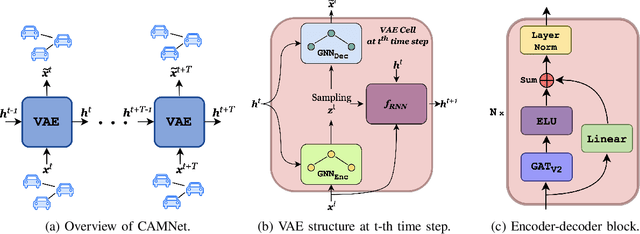
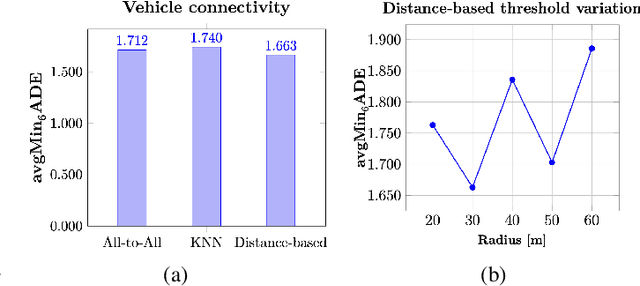
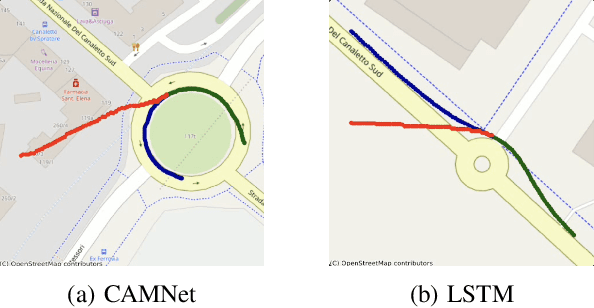
Autonomous driving remains a challenging task, particularly due to safety concerns. Modern vehicles are typically equipped with expensive sensors such as LiDAR, cameras, and radars to reduce the risk of accidents. However, these sensors face inherent limitations: their field of view and line of sight can be obstructed by other vehicles, thereby reducing situational awareness. In this context, vehicle-to-vehicle communication plays a crucial role, as it enables cars to share information and remain aware of each other even when sensors are occluded. One way to achieve this is through the use of Cooperative Awareness Messages (CAMs). In this paper, we investigate the use of CAM data for vehicle trajectory prediction. Specifically, we design and train a neural network, Cooperative Awareness Message-based Graph Neural Network (CAMNet), on a widely used motion forecasting dataset. We then evaluate the model on a second dataset that we created from scratch using Cooperative Awareness Messages, in order to assess whether this type of data can be effectively exploited. Our approach demonstrates promising results, showing that CAMs can indeed support vehicle trajectory prediction. At the same time, we discuss several limitations of the approach, which highlight opportunities for future research.
Coherent Online Road Topology Estimation and Reasoning with Standard-Definition Maps
Jul 02, 2025



Most autonomous cars rely on the availability of high-definition (HD) maps. Current research aims to address this constraint by directly predicting HD map elements from onboard sensors and reasoning about the relationships between the predicted map and traffic elements. Despite recent advancements, the coherent online construction of HD maps remains a challenging endeavor, as it necessitates modeling the high complexity of road topologies in a unified and consistent manner. To address this challenge, we propose a coherent approach to predict lane segments and their corresponding topology, as well as road boundaries, all by leveraging prior map information represented by commonly available standard-definition (SD) maps. We propose a network architecture, which leverages hybrid lane segment encodings comprising prior information and denoising techniques to enhance training stability and performance. Furthermore, we facilitate past frames for temporal consistency. Our experimental evaluation demonstrates that our approach outperforms previous methods by a large margin, highlighting the benefits of our modeling scheme.
Confidence Boosts Trust-Based Resilience in Cooperative Multi-Robot Systems
Jun 10, 2025Wireless communication-based multi-robot systems open the door to cyberattacks that can disrupt safety and performance of collaborative robots. The physical channel supporting inter-robot communication offers an attractive opportunity to decouple the detection of malicious robots from task-relevant data exchange between legitimate robots. Yet, trustworthiness indications coming from physical channels are uncertain and must be handled with this in mind. In this paper, we propose a resilient protocol for multi-robot operation wherein a parameter {\lambda}t accounts for how confident a robot is about the legitimacy of nearby robots that the physical channel indicates. Analytical results prove that our protocol achieves resilient coordination with arbitrarily many malicious robots under mild assumptions. Tuning {\lambda}t allows a designer to trade between near-optimal inter-robot coordination and quick task execution; see Fig. 1. This is a fundamental performance tradeoff and must be carefully evaluated based on the task at hand. The effectiveness of our approach is numerically verified with experiments involving platoons of autonomous cars where some vehicles are maliciously spoofed.
DisorientLiDAR: Physical Attacks on LiDAR-based Localization
Sep 16, 2025



Deep learning models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Even this poses a serious security challenge for the localization of self-driving cars, there has been very little exploration of attack on it, as most of adversarial attacks have been applied to 3D perception. In this work, we propose a novel adversarial attack framework called DisorientLiDAR targeting LiDAR-based localization. By reverse-engineering localization models (e.g., feature extraction networks), adversaries can identify critical keypoints and strategically remove them, thereby disrupting LiDAR-based localization. Our proposal is first evaluated on three state-of-the-art point-cloud registration models (HRegNet, D3Feat, and GeoTransformer) using the KITTI dataset. Experimental results demonstrate that removing regions containing Top-K keypoints significantly degrades their registration accuracy. We further validate the attack's impact on the Autoware autonomous driving platform, where hiding merely a few critical regions induces noticeable localization drift. Finally, we extended our attacks to the physical world by hiding critical regions with near-infrared absorptive materials, thereby successfully replicate the attack effects observed in KITTI data. This step has been closer toward the realistic physical-world attack that demonstrate the veracity and generality of our proposal.
A Workflow for Map Creation in Autonomous Vehicle Simulations
Aug 23, 2025The fast development of technology and artificial intelligence has significantly advanced Autonomous Vehicle (AV) research, emphasizing the need for extensive simulation testing. Accurate and adaptable maps are critical in AV development, serving as the foundation for localization, path planning, and scenario testing. However, creating simulation-ready maps is often difficult and resource-intensive, especially with simulators like CARLA (CAR Learning to Act). Many existing workflows require significant computational resources or rely on specific simulators, limiting flexibility for developers. This paper presents a custom workflow to streamline map creation for AV development, demonstrated through the generation of a 3D map of a parking lot at Ontario Tech University. Future work will focus on incorporating SLAM technologies, optimizing the workflow for broader simulator compatibility, and exploring more flexible handling of latitude and longitude values to enhance map generation accuracy.
* 6 pages, 12 figures. Published in the Proceedings of GEOProcessing 2025: The Seventeenth International Conference on Advanced Geographic Information Systems, Applications, and Services (IARIA)