 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVOLT: Vision and Language Trajectory Segmentation for Faster-than-Demonstration Policies
Jun 04, 2026Humans often take longer to demonstrate a task than a robot would need to execute it. Rather than learning to replicate the demonstration at the same pace, many industrial and practical applications require robots to perform tasks as quickly as possible. In this paper, we investigate several hypotheses for learning policies that operate faster-than-demonstrations. Our experiments show that the most effective strategy is to downsample recorded demonstrations and train the robot's policy on this accelerated data. However, uniformly downsampling an entire trajectory can be problematic. Some parts of a task can be safely sped up (e.g., unconstrained motion), while others demand slower, more precise motion (e.g., object interactions or fine manipulation). To address this challenge, we introduce VOLT, a vision-and-language trajectory segmentation method that reasons over video demonstrations, and leverages contextual cues to determine when acceleration is appropriate and when careful precision is required. VOLT identifies segments where slow, deliberate motion is necessary, then selectively downsamples the remaining segments. The resulting reformatted trajectories can be used with standard imitation learning approaches, such as diffusion policies. Our results highlight that segmentation quality is critical -- baseline methods often misidentify when acceleration is possible, leading to overly cautious or unreliable policies. Compared to state-of-the-art alternatives, VOLT allows robots to execute tasks faster while maintaining strong performance.
From Local Corrections to Generalized Skills: Improving Neuro-Symbolic Policies with MEMO
Mar 04, 2026Recent works use a neuro-symbolic framework for general manipulation policies. The advantage of this framework is that -- by applying off-the-shelf vision and language models -- the robot can break complex tasks down into semantic subtasks. However, the fundamental bottleneck is that the robot needs skills to ground these subtasks into embodied motions. Skills can take many forms (e.g., trajectory snippets, motion primitives, coded functions), but regardless of their form skills act as a constraint. The high-level policy can only ground its language reasoning through the available skills; if the robot cannot generate the right skill for the current task, its policy will fail. We propose to address this limitation -- and dynamically expand the robot's skills -- by leveraging user feedback. When a robot fails, humans can intuitively explain what went wrong (e.g., ``no, go higher''). While a simple approach is to recall this exact text the next time the robot faces a similar situation, we hypothesize that by collecting, clustering, and re-phrasing natural language corrections across multiple users and tasks, we can synthesize more general text guidance and coded skill templates. Applying this hypothesis we develop Memory Enhanced Manipulation (MEMO). MEMO builds and maintains a retrieval-augmented skillbook gathered from human feedback and task successes. At run time, MEMO retrieves relevant text and code from this skillbook, enabling the robot's policy to generate new skills while reasoning over multi-task human feedback. Our experiments demonstrate that using MEMO to aggregate local feedback into general skill templates enables generalization to novel tasks where existing baselines fall short. See supplemental material here: https://collab.me.vt.edu/memo
Language Movement Primitives: Grounding Language Models in Robot Motion
Feb 02, 2026Enabling robots to perform novel manipulation tasks from natural language instructions remains a fundamental challenge in robotics, despite significant progress in generalized problem solving with foundational models. Large vision and language models (VLMs) are capable of processing high-dimensional input data for visual scene and language understanding, as well as decomposing tasks into a sequence of logical steps; however, they struggle to ground those steps in embodied robot motion. On the other hand, robotics foundation models output action commands, but require in-domain fine-tuning or experience before they are able to perform novel tasks successfully. At its core, there still remains the fundamental challenge of connecting abstract task reasoning with low-level motion control. To address this disconnect, we propose Language Movement Primitives (LMPs), a framework that grounds VLM reasoning in Dynamic Movement Primitive (DMP) parameterization. Our key insight is that DMPs provide a small number of interpretable parameters, and VLMs can set these parameters to specify diverse, continuous, and stable trajectories. Put another way: VLMs can reason over free-form natural language task descriptions, and semantically ground their desired motions into DMPs -- bridging the gap between high-level task reasoning and low-level position and velocity control. Building on this combination of VLMs and DMPs, we formulate our LMP pipeline for zero-shot robot manipulation that effectively completes tabletop manipulation problems by generating a sequence of DMP motions. Across 20 real-world manipulation tasks, we show that LMP achieves 80% task success as compared to 31% for the best-performing baseline. See videos at our website: https://collab.me.vt.edu/lmp
Curvature-Aware Calibration of Tactile Sensors for Accurate Force Estimation on Non-Planar Surfaces
Oct 29, 2025
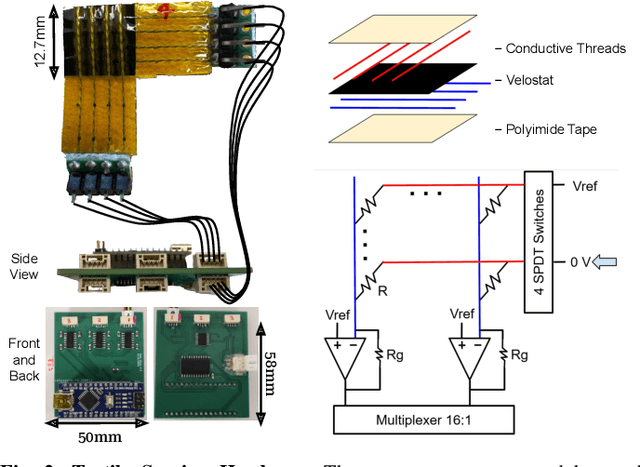
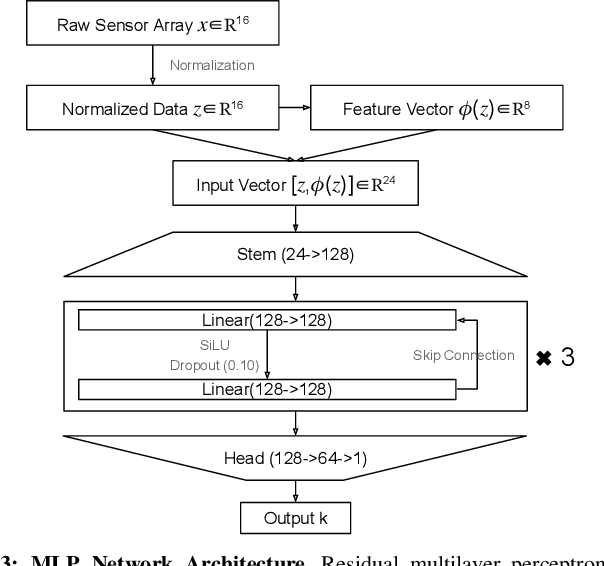
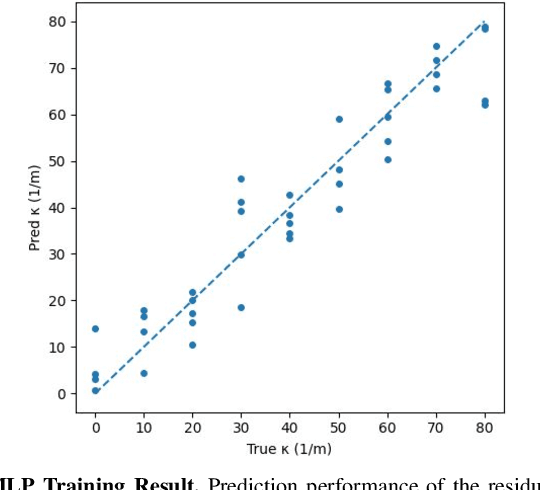
Flexible tactile sensors are increasingly used in real-world applications such as robotic grippers, prosthetic hands, wearable gloves, and assistive devices, where they need to conform to curved and irregular surfaces. However, most existing tactile sensors are calibrated only on flat substrates, and their accuracy and consistency degrade once mounted on curved geometries. This limitation restricts their reliability in practical use. To address this challenge, we develop a calibration model for a widely used resistive tactile sensor design that enables accurate force estimation on one-dimensional curved surfaces. We then train a neural network (a multilayer perceptron) to predict local curvature from baseline sensor outputs recorded under no applied load, achieving an R2 score of 0.91. The proposed approach is validated on five daily objects with varying curvatures under forces from 2 N to 8 N. Results show that the curvature-aware calibration maintains consistent force accuracy across all surfaces, while flat-surface calibration underestimates force as curvature increases. Our results demonstrate that curvature-aware modeling improves the accuracy, consistency, and reliability of flexible tactile sensors, enabling dependable performance across real-world applications.
Safe and Transparent Robots for Human-in-the-Loop Meat Processing
Aug 20, 2025Labor shortages have severely affected the meat processing sector. Automated technology has the potential to support the meat industry, assist workers, and enhance job quality. However, existing automation in meat processing is highly specialized, inflexible, and cost intensive. Instead of forcing manufacturers to buy a separate device for each step of the process, our objective is to develop general-purpose robotic systems that work alongside humans to perform multiple meat processing tasks. Through a recently conducted survey of industry experts, we identified two main challenges associated with integrating these collaborative robots alongside human workers. First, there must be measures to ensure the safety of human coworkers; second, the coworkers need to understand what the robot is doing. This paper addresses both challenges by introducing a safety and transparency framework for general-purpose meat processing robots. For safety, we implement a hand-detection system that continuously monitors nearby humans. This system can halt the robot in situations where the human comes into close proximity of the operating robot. We also develop an instrumented knife equipped with a force sensor that can differentiate contact between objects such as meat, bone, or fixtures. For transparency, we introduce a method that detects the robot's uncertainty about its performance and uses an LED interface to communicate that uncertainty to the human. Additionally, we design a graphical interface that displays the robot's plans and allows the human to provide feedback on the planned cut. Overall, our framework can ensure safe operation while keeping human workers in-the-loop about the robot's actions which we validate through a user study.
Towards Balanced Behavior Cloning from Imbalanced Datasets
Aug 08, 2025Robots should be able to learn complex behaviors from human demonstrations. In practice, these human-provided datasets are inevitably imbalanced: i.e., the human demonstrates some subtasks more frequently than others. State-of-the-art methods default to treating each element of the human's dataset as equally important. So if -- for instance -- the majority of the human's data focuses on reaching a goal, and only a few state-action pairs move to avoid an obstacle, the learning algorithm will place greater emphasis on goal reaching. More generally, misalignment between the relative amounts of data and the importance of that data causes fundamental problems for imitation learning approaches. In this paper we analyze and develop learning methods that automatically account for mixed datasets. We formally prove that imbalanced data leads to imbalanced policies when each state-action pair is weighted equally; these policies emulate the most represented behaviors, and not the human's complex, multi-task demonstrations. We next explore algorithms that rebalance offline datasets (i.e., reweight the importance of different state-action pairs) without human oversight. Reweighting the dataset can enhance the overall policy performance. However, there is no free lunch: each method for autonomously rebalancing brings its own pros and cons. We formulate these advantages and disadvantages, helping other researchers identify when each type of approach is most appropriate. We conclude by introducing a novel meta-gradient rebalancing algorithm that addresses the primary limitations behind existing approaches. Our experiments show that dataset rebalancing leads to better downstream learning, improving the performance of general imitation learning algorithms without requiring additional data collection. See our project website: https://collab.me.vt.edu/data_curation/.
A Modular Haptic Display with Reconfigurable Signals for Personalized Information Transfer
Jun 06, 2025We present a customizable soft haptic system that integrates modular hardware with an information-theoretic algorithm to personalize feedback for different users and tasks. Our platform features modular, multi-degree-of-freedom pneumatic displays, where different signal types, such as pressure, frequency, and contact area, can be activated or combined using fluidic logic circuits. These circuits simplify control by reducing reliance on specialized electronics and enabling coordinated actuation of multiple haptic elements through a compact set of inputs. Our approach allows rapid reconfiguration of haptic signal rendering through hardware-level logic switching without rewriting code. Personalization of the haptic interface is achieved through the combination of modular hardware and software-driven signal selection. To determine which display configurations will be most effective, we model haptic communication as a signal transmission problem, where an agent must convey latent information to the user. We formulate the optimization problem to identify the haptic hardware setup that maximizes the information transfer between the intended message and the user's interpretation, accounting for individual differences in sensitivity, preferences, and perceptual salience. We evaluate this framework through user studies where participants interact with reconfigurable displays under different signal combinations. Our findings support the role of modularity and personalization in creating multimodal haptic interfaces and advance the development of reconfigurable systems that adapt with users in dynamic human-machine interaction contexts.
L2D2: Robot Learning from 2D Drawings
May 17, 2025Robots should learn new tasks from humans. But how do humans convey what they want the robot to do? Existing methods largely rely on humans physically guiding the robot arm throughout their intended task. Unfortunately -- as we scale up the amount of data -- physical guidance becomes prohibitively burdensome. Not only do humans need to operate robot hardware but also modify the environment (e.g., moving and resetting objects) to provide multiple task examples. In this work we propose L2D2, a sketching interface and imitation learning algorithm where humans can provide demonstrations by drawing the task. L2D2 starts with a single image of the robot arm and its workspace. Using a tablet, users draw and label trajectories on this image to illustrate how the robot should act. To collect new and diverse demonstrations, we no longer need the human to physically reset the workspace; instead, L2D2 leverages vision-language segmentation to autonomously vary object locations and generate synthetic images for the human to draw upon. We recognize that drawing trajectories is not as information-rich as physically demonstrating the task. Drawings are 2-dimensional and do not capture how the robot's actions affect its environment. To address these fundamental challenges the next stage of L2D2 grounds the human's static, 2D drawings in our dynamic, 3D world by leveraging a small set of physical demonstrations. Our experiments and user study suggest that L2D2 enables humans to provide more demonstrations with less time and effort than traditional approaches, and users prefer drawings over physical manipulation. When compared to other drawing-based approaches, we find that L2D2 learns more performant robot policies, requires a smaller dataset, and can generalize to longer-horizon tasks. See our project website: https://collab.me.vt.edu/L2D2/
Counterfactual Behavior Cloning: Offline Imitation Learning from Imperfect Human Demonstrations
May 16, 2025Learning from humans is challenging because people are imperfect teachers. When everyday humans show the robot a new task they want it to perform, humans inevitably make errors (e.g., inputting noisy actions) and provide suboptimal examples (e.g., overshooting the goal). Existing methods learn by mimicking the exact behaviors the human teacher provides -- but this approach is fundamentally limited because the demonstrations themselves are imperfect. In this work we advance offline imitation learning by enabling robots to extrapolate what the human teacher meant, instead of only considering what the human actually showed. We achieve this by hypothesizing that all of the human's demonstrations are trying to convey a single, consistent policy, while the noise and sub-optimality within their behaviors obfuscates the data and introduces unintentional complexity. To recover the underlying policy and learn what the human teacher meant, we introduce Counter-BC, a generalized version of behavior cloning. Counter-BC expands the given dataset to include actions close to behaviors the human demonstrated (i.e., counterfactual actions that the human teacher could have intended, but did not actually show). During training Counter-BC autonomously modifies the human's demonstrations within this expanded region to reach a simple and consistent policy that explains the underlying trends in the human's dataset. Theoretically, we prove that Counter-BC can extract the desired policy from imperfect data, multiple users, and teachers of varying skill levels. Empirically, we compare Counter-BC to state-of-the-art alternatives in simulated and real-world settings with noisy demonstrations, standardized datasets, and real human teachers. See videos of our work here: https://youtu.be/XaeOZWhTt68
CIVIL: Causal and Intuitive Visual Imitation Learning
Apr 24, 2025



Today's robots learn new tasks by imitating human examples. However, this standard approach to visual imitation learning is fundamentally limited: the robot observes what the human does, but not why the human chooses those behaviors. Without understanding the features that factor into the human's decisions, robot learners often misinterpret the data and fail to perform the task when the environment changes. We therefore propose a shift in perspective: instead of asking human teachers just to show what actions the robot should take, we also enable humans to indicate task-relevant features using markers and language prompts. Our proposed algorithm, CIVIL, leverages this augmented data to filter the robot's visual observations and extract a feature representation that causally informs human actions. CIVIL then applies these causal features to train a transformer-based policy that emulates human behaviors without being confused by visual distractors. Our simulations, real-world experiments, and user study demonstrate that robots trained with CIVIL can learn from fewer human demonstrations and perform better than state-of-the-art baselines, especially in previously unseen scenarios. See videos at our project website: https://civil2025.github.io