 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
The Rhythm In Anything: Audio-Prompted Drums Generation with Masked Language Modeling
Sep 19, 2025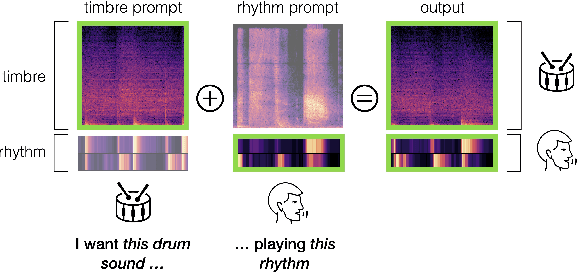
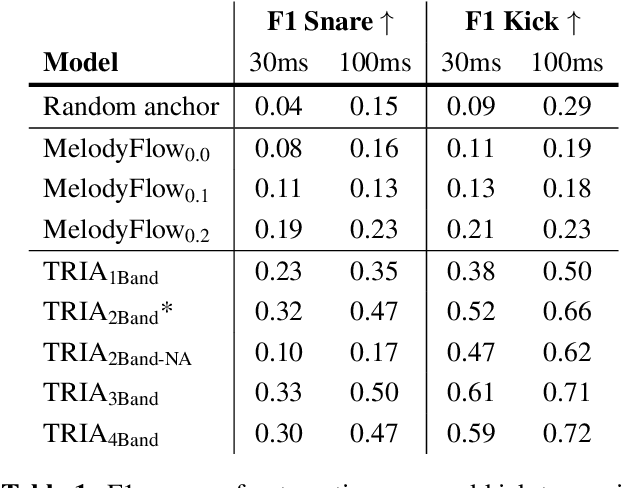
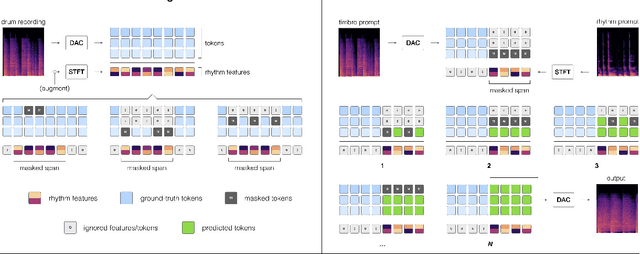
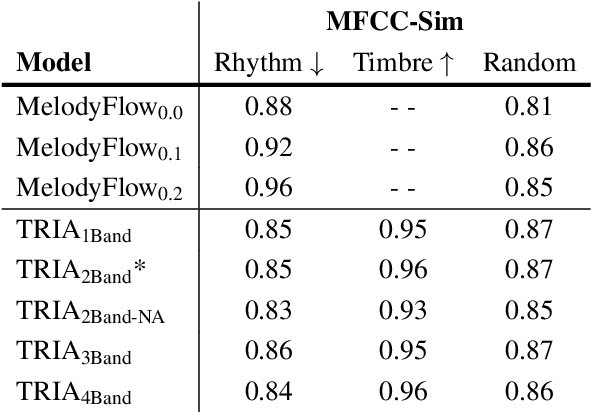
Musicians and nonmusicians alike use rhythmic sound gestures, such as tapping and beatboxing, to express drum patterns. While these gestures effectively communicate musical ideas, realizing these ideas as fully-produced drum recordings can be time-consuming, potentially disrupting many creative workflows. To bridge this gap, we present TRIA (The Rhythm In Anything), a masked transformer model for mapping rhythmic sound gestures to high-fidelity drum recordings. Given an audio prompt of the desired rhythmic pattern and a second prompt to represent drumkit timbre, TRIA produces audio of a drumkit playing the desired rhythm (with appropriate elaborations) in the desired timbre. Subjective and objective evaluations show that a TRIA model trained on less than 10 hours of publicly-available drum data can generate high-quality, faithful realizations of sound gestures across a wide range of timbres in a zero-shot manner.
TISDiSS: A Training-Time and Inference-Time Scalable Framework for Discriminative Source Separation
Sep 19, 2025Source separation is a fundamental task in speech, music, and audio processing, and it also provides cleaner and larger data for training generative models. However, improving separation performance in practice often depends on increasingly large networks, inflating training and deployment costs. Motivated by recent advances in inference-time scaling for generative modeling, we propose Training-Time and Inference-Time Scalable Discriminative Source Separation (TISDiSS), a unified framework that integrates early-split multi-loss supervision, shared-parameter design, and dynamic inference repetitions. TISDiSS enables flexible speed-performance trade-offs by adjusting inference depth without retraining additional models. We further provide systematic analyses of architectural and training choices and show that training with more inference repetitions improves shallow-inference performance, benefiting low-latency applications. Experiments on standard speech separation benchmarks demonstrate state-of-the-art performance with a reduced parameter count, establishing TISDiSS as a scalable and practical framework for adaptive source separation.
ACMID: Automatic Curation of Musical Instrument Dataset for 7-Stem Music Source Separation
Oct 09, 2025Most current music source separation (MSS) methods rely on supervised learning, limited by training data quan- tity and quality. Though web-crawling can bring abundant data, platform-level track labeling often causes metadata mismatches, impeding accurate "audio-label" pair acquisi- tion. To address this, we present ACMID: a dataset for MSS generated through web crawling of extensive raw data, fol- lowed by automatic cleaning via an instrument classifier built on a pre-trained audio encoder that filters and aggregates clean segments of target instruments from the crawled tracks, resulting in the refined ACMID-Cleaned dataset. Leverag- ing abundant data, we expand the conventional classifica- tion from 4-stem (Vocal/Bass/Drums/Others) to 7-stem (Pi- ano/Drums/Bass/Acoustic Guitar/Electric Guitar/Strings/Wind- Brass), enabling high granularity MSS systems. Experiments on SOTA MSS model demonstrates two key results: (i) MSS model trained with ACMID-Cleaned achieved a 2.39dB improvement in SDR performance compared to that with ACMID-Uncleaned, demostrating the effectiveness of our data cleaning procedure; (ii) incorporating ACMID-Cleaned to training enhances MSS model's average performance by 1.16dB, confirming the value of our dataset. Our data crawl- ing code, cleaning model code and weights are available at: https://github.com/scottishfold0621/ACMID.
Biases in LLM-Generated Musical Taste Profiles for Recommendation
Jul 22, 2025One particularly promising use case of Large Language Models (LLMs) for recommendation is the automatic generation of Natural Language (NL) user taste profiles from consumption data. These profiles offer interpretable and editable alternatives to opaque collaborative filtering representations, enabling greater transparency and user control. However, it remains unclear whether users consider these profiles to be an accurate representation of their taste, which is crucial for trust and usability. Moreover, because LLMs inherit societal and data-driven biases, profile quality may systematically vary across user and item characteristics. In this paper, we study this issue in the context of music streaming, where personalization is challenged by a large and culturally diverse catalog. We conduct a user study in which participants rate NL profiles generated from their own listening histories. We analyze whether identification with the profiles is biased by user attributes (e.g., mainstreamness, taste diversity) and item features (e.g., genre, country of origin). We also compare these patterns to those observed when using the profiles in a downstream recommendation task. Our findings highlight both the potential and limitations of scrutable, LLM-based profiling in personalized systems.
Exploring State-Space-Model based Language Model in Music Generation
Jul 09, 2025


The recent surge in State Space Models (SSMs), particularly the emergence of Mamba, has established them as strong alternatives or complementary modules to Transformers across diverse domains. In this work, we aim to explore the potential of Mamba-based architectures for text-to-music generation. We adopt discrete tokens of Residual Vector Quantization (RVQ) as the modeling representation and empirically find that a single-layer codebook can capture semantic information in music. Motivated by this observation, we focus on modeling a single-codebook representation and adapt SiMBA, originally designed as a Mamba-based encoder, to function as a decoder for sequence modeling. We compare its performance against a standard Transformer-based decoder. Our results suggest that, under limited-resource settings, SiMBA achieves much faster convergence and generates outputs closer to the ground truth. This demonstrates the promise of SSMs for efficient and expressive text-to-music generation. We put audio examples on Github.
DeformTune: A Deformable XAI Music Prototype for Non-Musicians
Jul 31, 2025

Many existing AI music generation tools rely on text prompts, complex interfaces, or instrument-like controls, which may require musical or technical knowledge that non-musicians do not possess. This paper introduces DeformTune, a prototype system that combines a tactile deformable interface with the MeasureVAE model to explore more intuitive, embodied, and explainable AI interaction. We conducted a preliminary study with 11 adult participants without formal musical training to investigate their experience with AI-assisted music creation. Thematic analysis of their feedback revealed recurring challenge--including unclear control mappings, limited expressive range, and the need for guidance throughout use. We discuss several design opportunities for enhancing explainability of AI, including multimodal feedback and progressive interaction support. These findings contribute early insights toward making AI music systems more explainable and empowering for novice users.
MelCap: A Unified Single-Codebook Neural Codec for High-Fidelity Audio Compression
Oct 02, 2025Neural audio codecs have recently emerged as powerful tools for high-quality and low-bitrate audio compression, leveraging deep generative models to learn latent representations of audio signals. However, existing approaches either rely on a single quantizer that only processes speech domain, or on multiple quantizers that are not well suited for downstream tasks. To address this issue, we propose MelCap, a unified "one-codebook-for-all" neural codec that effectively handles speech, music, and general sound. By decomposing audio reconstruction into two stages, our method preserves more acoustic details than previous single-codebook approaches, while achieving performance comparable to mainstream multi-codebook methods. In the first stage, audio is transformed into mel-spectrograms, which are compressed and quantized into compact single tokens using a 2D tokenizer. A perceptual loss is further applied to mitigate the over-smoothing artifacts observed in spectrogram reconstruction. In the second stage, a Vocoder recovers waveforms from the mel discrete tokens in a single forward pass, enabling real-time decoding. Both objective and subjective evaluations demonstrate that MelCap achieves quality on comparable to state-of-the-art multi-codebook codecs, while retaining the computational simplicity of a single-codebook design, thereby providing an effective representation for downstream tasks.
Benchmarking Music Generation Models and Metrics via Human Preference Studies
Jun 23, 2025Recent advancements have brought generated music closer to human-created compositions, yet evaluating these models remains challenging. While human preference is the gold standard for assessing quality, translating these subjective judgments into objective metrics, particularly for text-audio alignment and music quality, has proven difficult. In this work, we generate 6k songs using 12 state-of-the-art models and conduct a survey of 15k pairwise audio comparisons with 2.5k human participants to evaluate the correlation between human preferences and widely used metrics. To the best of our knowledge, this work is the first to rank current state-of-the-art music generation models and metrics based on human preference. To further the field of subjective metric evaluation, we provide open access to our dataset of generated music and human evaluations.
* Accepted at ICASSP 2025
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
Exploring Procedural Data Generation for Automatic Acoustic Guitar Fingerpicking Transcription
Aug 11, 2025Automatic transcription of acoustic guitar fingerpicking performances remains a challenging task due to the scarcity of labeled training data and legal constraints connected with musical recordings. This work investigates a procedural data generation pipeline as an alternative to real audio recordings for training transcription models. Our approach synthesizes training data through four stages: knowledge-based fingerpicking tablature composition, MIDI performance rendering, physical modeling using an extended Karplus-Strong algorithm, and audio augmentation including reverb and distortion. We train and evaluate a CRNN-based note-tracking model on both real and synthetic datasets, demonstrating that procedural data can be used to achieve reasonable note-tracking results. Finetuning with a small amount of real data further enhances transcription accuracy, improving over models trained exclusively on real recordings. These results highlight the potential of procedurally generated audio for data-scarce music information retrieval tasks.