 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Text-to-Music Evaluation with Human Preferences
Mar 20, 2025Despite significant recent advances in generative acoustic text-to-music (TTM) modeling, robust evaluation of these models lags behind, relying in particular on the popular Fr\'echet Audio Distance (FAD). In this work, we rigorously study the design space of reference-based divergence metrics for evaluating TTM models through (1) designing four synthetic meta-evaluations to measure sensitivity to particular musical desiderata, and (2) collecting and evaluating on MusicPrefs, the first open-source dataset of human preferences for TTM systems. We find that not only is the standard FAD setup inconsistent on both synthetic and human preference data, but that nearly all existing metrics fail to effectively capture desiderata, and are only weakly correlated with human perception. We propose a new metric, the MAUVE Audio Divergence (MAD), computed on representations from a self-supervised audio embedding model. We find that this metric effectively captures diverse musical desiderata (average rank correlation 0.84 for MAD vs. 0.49 for FAD and also correlates more strongly with MusicPrefs (0.62 vs. 0.14).
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024



In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
Efficient Task Grouping Through Samplewise Optimisation Landscape Analysis
Dec 05, 2024Shared training approaches, such as multi-task learning (MTL) and gradient-based meta-learning, are widely used in various machine learning applications, but they often suffer from negative transfer, leading to performance degradation in specific tasks. While several optimisation techniques have been developed to mitigate this issue for pre-selected task cohorts, identifying optimal task combinations for joint learning - known as task grouping - remains underexplored and computationally challenging due to the exponential growth in task combinations and the need for extensive training and evaluation cycles. This paper introduces an efficient task grouping framework designed to reduce these overwhelming computational demands of the existing methods. The proposed framework infers pairwise task similarities through a sample-wise optimisation landscape analysis, eliminating the need for the shared model training required to infer task similarities in existing methods. With task similarities acquired, a graph-based clustering algorithm is employed to pinpoint near-optimal task groups, providing an approximate yet efficient and effective solution to the originally NP-hard problem. Empirical assessments conducted on 8 different datasets highlight the effectiveness of the proposed framework, revealing a five-fold speed enhancement compared to previous state-of-the-art methods. Moreover, the framework consistently demonstrates comparable performance, confirming its remarkable efficiency and effectiveness in task grouping.
REFeREE: A REference-FREE Model-Based Metric for Text Simplification
Mar 26, 2024



Text simplification lacks a universal standard of quality, and annotated reference simplifications are scarce and costly. We propose to alleviate such limitations by introducing REFeREE, a reference-free model-based metric with a 3-stage curriculum. REFeREE leverages an arbitrarily scalable pretraining stage and can be applied to any quality standard as long as a small number of human annotations are available. Our experiments show that our metric outperforms existing reference-based metrics in predicting overall ratings and reaches competitive and consistent performance in predicting specific ratings while requiring no reference simplifications at inference time.
Robustness Tests for Automatic Machine Translation Metrics with Adversarial Attacks
Nov 01, 2023We investigate MT evaluation metric performance on adversarially-synthesized texts, to shed light on metric robustness. We experiment with word- and character-level attacks on three popular machine translation metrics: BERTScore, BLEURT, and COMET. Our human experiments validate that automatic metrics tend to overpenalize adversarially-degraded translations. We also identify inconsistencies in BERTScore ratings, where it judges the original sentence and the adversarially-degraded one as similar, while judging the degraded translation as notably worse than the original with respect to the reference. We identify patterns of brittleness that motivate more robust metric development.
Learning Interpretable Low-dimensional Representation via Physical Symmetry
Feb 24, 2023



Interpretable representation learning has been playing a key role in creative intelligent systems. In the music domain, current learning algorithms can successfully learn various features such as pitch, timbre, chord, texture, etc. However, most methods rely heavily on music domain knowledge. It remains an open question what general computational principles give rise to interpretable representations, especially low-dim factors that agree with human perception. In this study, we take inspiration from modern physics and use physical symmetry as a self-consistency constraint for the latent space. Specifically, it requires the prior model that characterises the dynamics of the latent states to be equivariant with respect to certain group transformations. We show that physical symmetry leads the model to learn a linear pitch factor from unlabelled monophonic music audio in a self-supervised fashion. In addition, the same methodology can be applied to computer vision, learning a 3D Cartesian space from videos of a simple moving object without labels. Furthermore, physical symmetry naturally leads to representation augmentation, a new technique which improves sample efficiency.
UNITER-Based Situated Coreference Resolution with Rich Multimodal Input
Dec 07, 2021
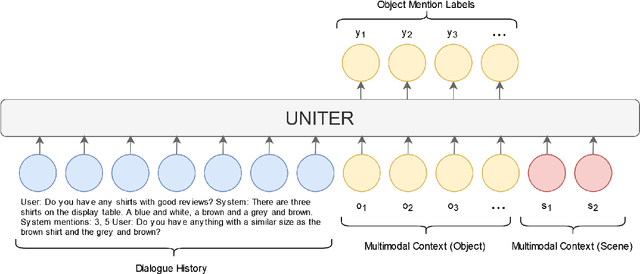
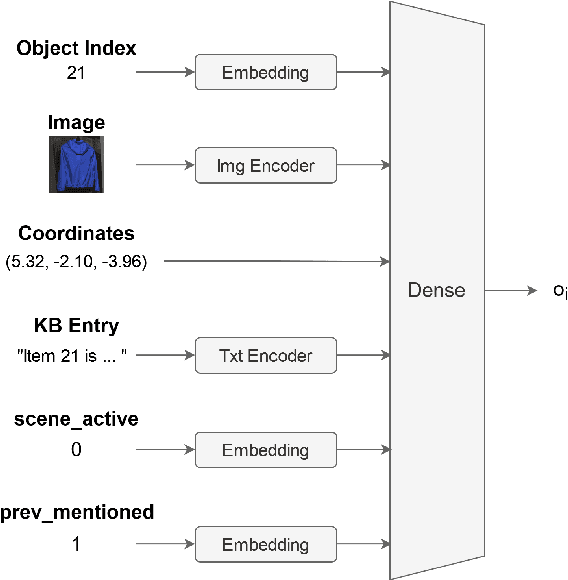
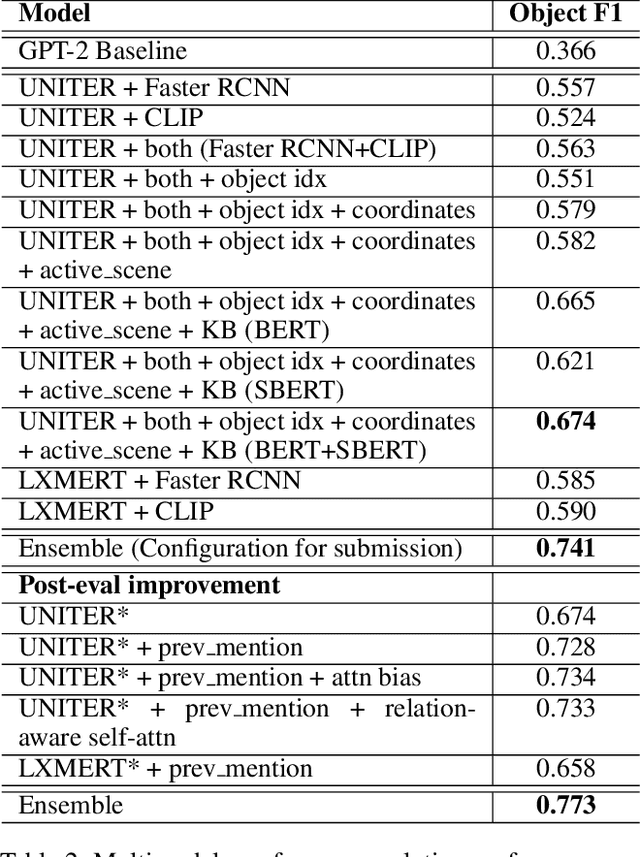
We present our work on the multimodal coreference resolution task of the Situated and Interactive Multimodal Conversation 2.0 (SIMMC 2.0) dataset as a part of the tenth Dialog System Technology Challenge (DSTC10). We propose a UNITER-based model utilizing rich multimodal context such as textual dialog history, object knowledge base and visual dialog scenes to determine whether each object in the current scene is mentioned in the current dialog turn. Results show that the proposed approach outperforms the official DSTC10 baseline substantially, with the object F1 score boosted from 36.6% to 77.3% on the development set, demonstrating the effectiveness of the proposed object representations from rich multimodal input. Our model ranks second in the official evaluation on the object coreference resolution task with an F1 score of 73.3% after model ensembling.
Narrative Incoherence Detection
Dec 21, 2020

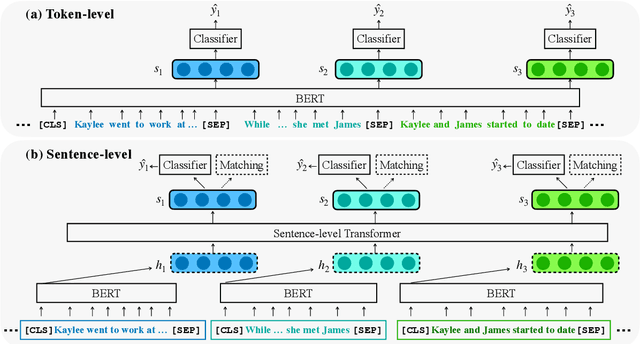
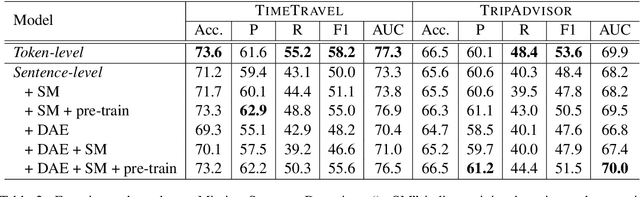
Motivated by the increasing popularity of intelligent editing assistant, we introduce and investigate the task of narrative incoherence detection: Given a (corrupted) long-form narrative, decide whether there exists some semantic discrepancy in the narrative flow. Specifically, we focus on the missing sentence and incoherent sentence detection. Despite its simple setup, this task is challenging as the model needs to understand and analyze a multi-sentence narrative text, and make decisions at the sentence level. As an initial step towards this task, we implement several baselines either directly analyzing the raw text (\textit{token-level}) or analyzing learned sentence representations (\textit{sentence-level}). We observe that while token-level modeling enjoys greater expressive power and hence better performance, sentence-level modeling possesses an advantage in efficiency and flexibility. With pre-training on large-scale data and cycle-consistent sentence embedding, our extended sentence-level model can achieve comparable detection accuracy to the token-level model. As a by-product, such a strategy enables simultaneous incoherence detection and infilling/modification suggestions.
Neuro-Symbolic Visual Reasoning: Disentangling "Visual" from "Reasoning"
Jun 30, 2020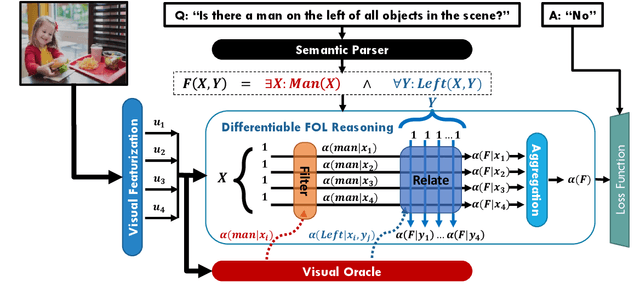
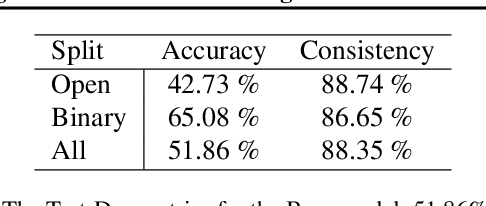
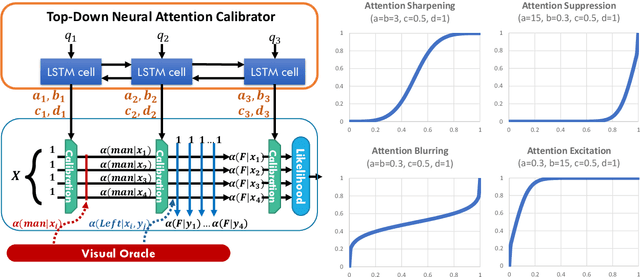
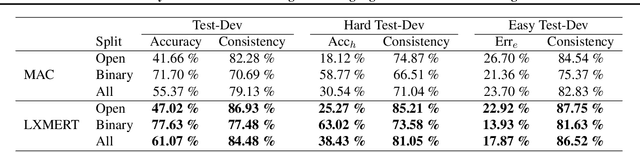
Visual reasoning tasks such as visual question answering (VQA) require an interplay of visual perception with reasoning about the question semantics grounded in perception. Various benchmarks for reasoning across language and vision like VQA, VCR and more recently GQA for compositional question answering facilitate scientific progress from perception models to visual reasoning. However, recent advances are still primarily driven by perception improvements (e.g. scene graph generation) rather than reasoning. Neuro-symbolic models such as Neural Module Networks bring the benefits of compositional reasoning to VQA, but they are still entangled with visual representation learning, and thus neural reasoning is hard to improve and assess on its own. To address this, we propose (1) a framework to isolate and evaluate the reasoning aspect of VQA separately from its perception, and (2) a novel top-down calibration technique that allows the model to answer reasoning questions even with imperfect perception. To this end, we introduce a differentiable first-order logic formalism for VQA that explicitly decouples question answering from visual perception. On the challenging GQA dataset, this framework is used to perform in-depth, disentangled comparisons between well-known VQA models leading to informative insights regarding the participating models as well as the task.
INSET: Sentence Infilling with Inter-sentential Generative Pre-training
Nov 10, 2019

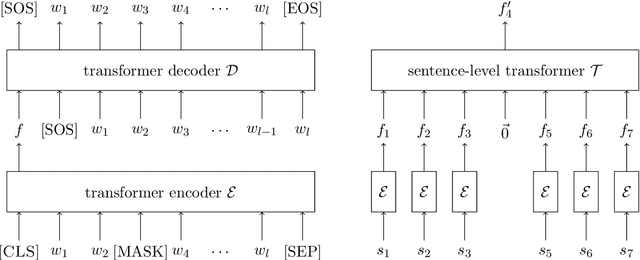
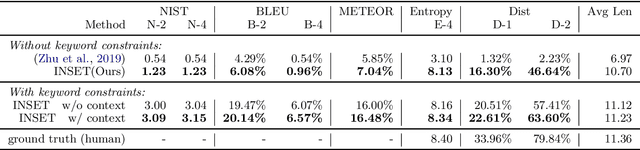
Missing sentence generation (or sentence infilling) fosters a wide range of applications in natural language generation, such as document auto-completion and meeting note expansion. Such a task asks the model to generate intermediate missing sentence that can semantically and syntactically bridge the surrounding context. Solving the sentence infilling task requires techniques in NLP ranging from natural language understanding, discourse-level planning and natural language generation. In this paper, we present a framework to decouple this challenge and address these three aspects respectively, leveraging the power of existing large-scale pre-trained models such as BERT and GPT-2. Our empirical results demonstrate the effectiveness of our proposed model in learning a sentence representation for generation, and further generating a missing sentence that bridges the context.