 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveGesture Streamable Co-Speech Gesture Generation Model
Apr 13, 2026We propose LiveGesture, the first fully streamable, speech-driven full-body gesture generation framework that operates with zero look-ahead and supports arbitrary sequence length. Unlike existing co-speech gesture methods, which are designed for offline generation and either treat body regions independently or entangle all joints within a single model, LiveGesture is built from the ground up for causal, region-coordinated motion generation. LiveGesture consists of two main modules: the Streamable Vector Quantized Motion Tokenizer (SVQ) and the Hierarchical Autoregressive Transformer (HAR). The SVQ tokenizer converts the motion sequence of each body region into causal, discrete motion tokens, enabling real-time, streamable token decoding. On top of SVQ, HAR employs region-expert autoregressive (xAR) transformers to model expressive, fine-grained motion dynamics for each body region. A causal spatio-temporal fusion module (xAR Fusion) then captures and integrates correlated motion dynamics across regions. Both xAR and xAR Fusion are conditioned on live, continuously arriving audio signals encoded by a streamable causal audio encoder. To enhance robustness under streaming noise and prediction errors, we introduce autoregressive masking training, which leverages uncertainty-guided token masking and random region masking to expose the model to imperfect, partially erroneous histories during training. Experiments on the BEAT2 dataset demonstrate that LiveGesture produces coherent, diverse, and beat-synchronous full-body gestures in real time, matching or surpassing state-of-the-art offline methods under true zero look-ahead conditions.
Monocular Models are Strong Learners for Multi-View Human Mesh Recovery
Mar 20, 2026Multi-view human mesh recovery (HMR) is broadly deployed in diverse domains where high accuracy and strong generalization are essential. Existing approaches can be broadly grouped into geometry-based and learning-based methods. However, geometry-based methods (e.g., triangulation) rely on cumbersome camera calibration, while learning-based approaches often generalize poorly to unseen camera configurations due to the lack of multi-view training data, limiting their performance in real-world scenarios. To enable calibration-free reconstruction that generalizes to arbitrary camera setups, we propose a training-free framework that leverages pretrained single-view HMR models as strong priors, eliminating the need for multi-view training data. Our method first constructs a robust and consistent multi-view initialization from single-view predictions, and then refines it via test-time optimization guided by multi-view consistency and anatomical constraints. Extensive experiments demonstrate state-of-the-art performance on standard benchmarks, surpassing multi-view models trained with explicit multi-view supervision.
DanceMosaic: High-Fidelity Dance Generation with Multimodal Editability
Apr 06, 2025Recent advances in dance generation have enabled automatic synthesis of 3D dance motions. However, existing methods still struggle to produce high-fidelity dance sequences that simultaneously deliver exceptional realism, precise dance-music synchronization, high motion diversity, and physical plausibility. Moreover, existing methods lack the flexibility to edit dance sequences according to diverse guidance signals, such as musical prompts, pose constraints, action labels, and genre descriptions, significantly restricting their creative utility and adaptability. Unlike the existing approaches, DanceMosaic enables fast and high-fidelity dance generation, while allowing multimodal motion editing. Specifically, we propose a multimodal masked motion model that fuses the text-to-motion model with music and pose adapters to learn probabilistic mapping from diverse guidance signals to high-quality dance motion sequences via progressive generative masking training. To further enhance the motion generation quality, we propose multimodal classifier-free guidance and inference-time optimization mechanism that further enforce the alignment between the generated motions and the multimodal guidance. Extensive experiments demonstrate that our method establishes a new state-of-the-art performance in dance generation, significantly advancing the quality and editability achieved by existing approaches.
BioPose: Biomechanically-accurate 3D Pose Estimation from Monocular Videos
Jan 14, 2025Recent advancements in 3D human pose estimation from single-camera images and videos have relied on parametric models, like SMPL. However, these models oversimplify anatomical structures, limiting their accuracy in capturing true joint locations and movements, which reduces their applicability in biomechanics, healthcare, and robotics. Biomechanically accurate pose estimation, on the other hand, typically requires costly marker-based motion capture systems and optimization techniques in specialized labs. To bridge this gap, we propose BioPose, a novel learning-based framework for predicting biomechanically accurate 3D human pose directly from monocular videos. BioPose includes three key components: a Multi-Query Human Mesh Recovery model (MQ-HMR), a Neural Inverse Kinematics (NeurIK) model, and a 2D-informed pose refinement technique. MQ-HMR leverages a multi-query deformable transformer to extract multi-scale fine-grained image features, enabling precise human mesh recovery. NeurIK treats the mesh vertices as virtual markers, applying a spatial-temporal network to regress biomechanically accurate 3D poses under anatomical constraints. To further improve 3D pose estimations, a 2D-informed refinement step optimizes the query tokens during inference by aligning the 3D structure with 2D pose observations. Experiments on benchmark datasets demonstrate that BioPose significantly outperforms state-of-the-art methods. Project website: \url{https://m-usamasaleem.github.io/publication/BioPose/BioPose.html}.
MS-Temba : Multi-Scale Temporal Mamba for Efficient Temporal Action Detection
Jan 10, 2025Action detection in real-world scenarios is particularly challenging due to densely distributed actions in hour-long untrimmed videos. It requires modeling both short- and long-term temporal relationships while handling significant intra-class temporal variations. Previous state-of-the-art (SOTA) Transformer-based architectures, though effective, are impractical for real-world deployment due to their high parameter count, GPU memory usage, and limited throughput, making them unsuitable for very long videos. In this work, we innovatively adapt the Mamba architecture for action detection and propose Multi-scale Temporal Mamba (MS-Temba), comprising two key components: Temporal Mamba (Temba) Blocks and the Temporal Mamba Fuser. Temba Blocks include the Temporal Local Module (TLM) for short-range temporal modeling and the Dilated Temporal SSM (DTS) for long-range dependencies. By introducing dilations, a novel concept for Mamba, TLM and DTS capture local and global features at multiple scales. The Temba Fuser aggregates these scale-specific features using Mamba to learn comprehensive multi-scale representations of untrimmed videos. MS-Temba is validated on three public datasets, outperforming SOTA methods on long videos and matching prior methods on short videos while using only one-eighth of the parameters.
MMHMR: Generative Masked Modeling for Hand Mesh Recovery
Dec 18, 2024



Reconstructing a 3D hand mesh from a single RGB image is challenging due to complex articulations, self-occlusions, and depth ambiguities. Traditional discriminative methods, which learn a deterministic mapping from a 2D image to a single 3D mesh, often struggle with the inherent ambiguities in 2D-to-3D mapping. To address this challenge, we propose MMHMR, a novel generative masked model for hand mesh recovery that synthesizes plausible 3D hand meshes by learning and sampling from the probabilistic distribution of the ambiguous 2D-to-3D mapping process. MMHMR consists of two key components: (1) a VQ-MANO, which encodes 3D hand articulations as discrete pose tokens in a latent space, and (2) a Context-Guided Masked Transformer that randomly masks out pose tokens and learns their joint distribution, conditioned on corrupted token sequences, image context, and 2D pose cues. This learned distribution facilitates confidence-guided sampling during inference, producing mesh reconstructions with low uncertainty and high precision. Extensive evaluations on benchmark and real-world datasets demonstrate that MMHMR achieves state-of-the-art accuracy, robustness, and realism in 3D hand mesh reconstruction. Project website: https://m-usamasaleem.github.io/publication/MMHMR/mmhmr.html
Comparing Background Subtraction Algorithms and Method of Car Counting
Jan 29, 2012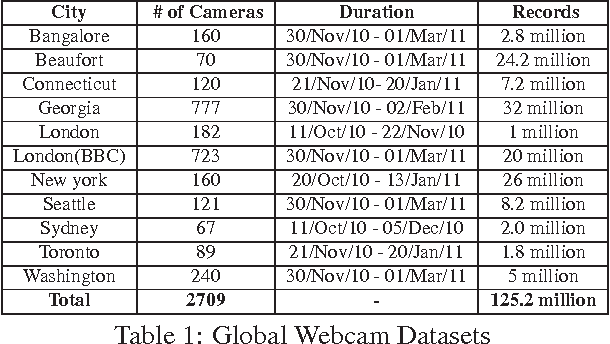
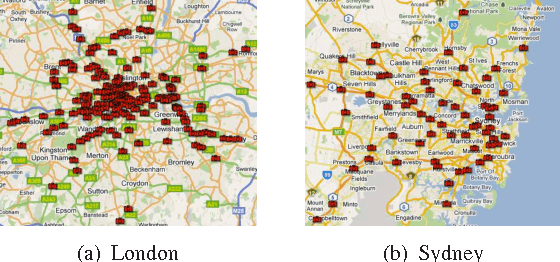
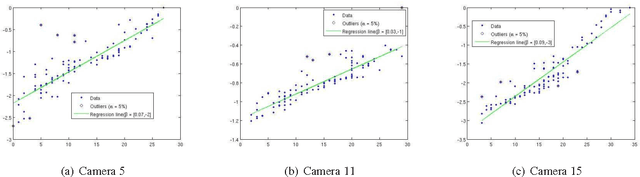
In this paper, we compare various image background subtraction algorithms with the ground truth of cars counted. We have given a sample of thousand images, which are the snap shots of current traffic as records at various intersections and highways. We have also counted an approximate number of cars that are visible in these images. In order to ascertain the accuracy of algorithms to be used for the processing of million images, we compare them on many metrics that includes (i) Scalability (ii) Accuracy (iii) Processing time.
Mobile Testbeds with an Attitude
Sep 18, 2010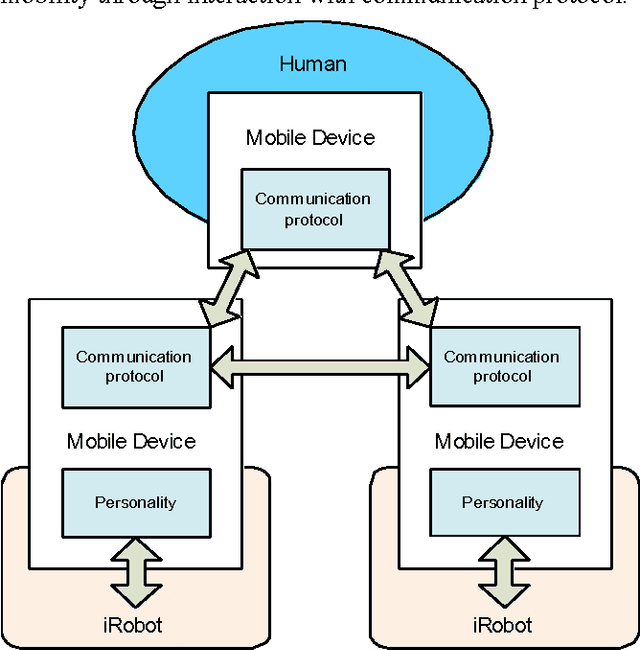

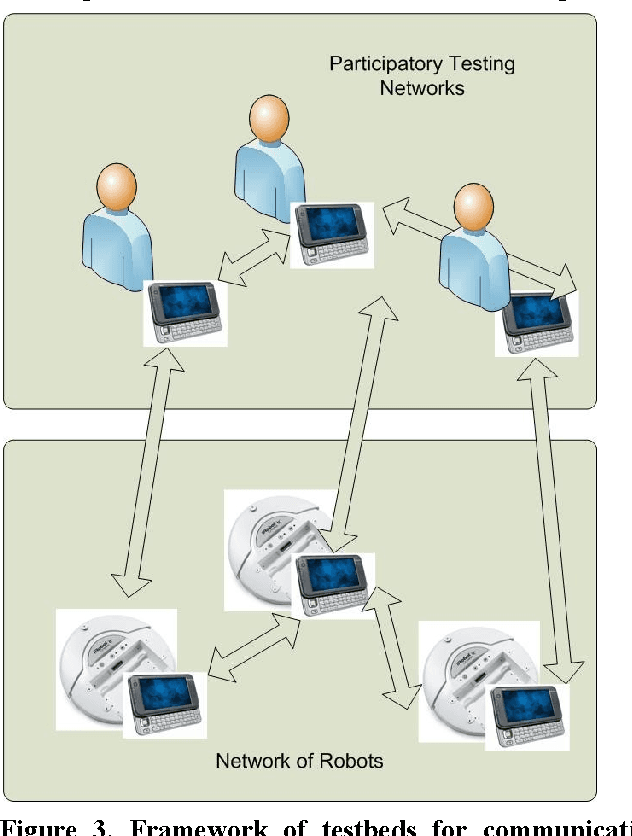
There have been significant recent advances in mobile networks, specifically in multi-hop wireless networks including DTNs and sensor networks. It is critical to have a testing environment to realistically evaluate such networks and their protocols and services. Towards this goal, we propose a novel, mobile testbed of two main components. The first consists of a network of robots with personality- mimicking, human-encounter behaviors, which will be the focus of this demo. The personality is build upon behavioral profiling of mobile users based on extensive wireless-network measurements and analysis. The second component combines the testbed with the human society using a new concept that we refer to as participatory testing utilizing crowd sourcing.