 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLdv
Papers and Code
Compression-Realized Deep Structural Network for Video Quality Enhancement
May 10, 2024



This paper focuses on the task of quality enhancement for compressed videos. Although deep network-based video restorers achieve impressive progress, most of the existing methods lack a structured design to optimally leverage the priors within compression codecs. Since the quality degradation of the video is primarily induced by the compression algorithm, a new paradigm is urgently needed for a more "conscious" process of quality enhancement. As a result, we propose the Compression-Realize Deep Structural Network (CRDS), introducing three inductive biases aligned with the three primary processes in the classic compression codec, merging the strengths of classical encoder architecture with deep network capabilities. Inspired by the residual extraction and domain transformation process in the codec, a pre-trained Latent Degradation Residual Auto-Encoder is proposed to transform video frames into a latent feature space, and the mutual neighborhood attention mechanism is integrated for precise motion estimation and residual extraction. Furthermore, drawing inspiration from the quantization noise distribution of the codec, CRDS proposes a novel Progressive Denoising framework with intermediate supervision that decomposes the quality enhancement into a series of simpler denoising sub-tasks. Experimental results on datasets like LDV 2.0 and MFQE 2.0 indicate our approach surpasses state-of-the-art models.
Non-contact photoacoustic imaging with a silicon photonics-based Laser Doppler Vibrometer
Feb 14, 2024Photoacoustic imaging has emerged as a powerful, non-invasive modality for various biomedical applications. Conventional photoacoustic systems require contact-based ultrasound detection and expensive and bulky high-power lasers for the excitation. The use of contact-based detectors involves the risk of contamination, which is undesirable for most biomedical applications. While other non-contact detection methods can be bulky, in this paper, we demonstrate compact and contactless detection of photoacoustic signals on silicone samples embedded with ink-filled channels, mimicking tissue with blood-carrying veins. A silicon photonics-based Laser Doppler Vibrometer (LDV) detects the acoustic waves excited by a compact pulsed laser diode. By scanning the LDV beam over the surface of the sample, 2D photoacoustic images were reconstructed of the sample. Photoacoustic signals with absorption coefficients within the physiological range were detected by this setup.
Laser Doppler vibrometer and accelerometer for vibrational analysis of the automotive components during Simulink simulation for validation
Apr 16, 2023In current research, laser Doppler vibrometer (LDV) as a new diagnostic tool is utilized for non-destructive testing of the automotive equipment. LDV technique is working based on measurement of the Doppler shift of a moving object in an interference set-up. The effects of different noises are considered and eliminated from data analysis. Here, the performance of LDV technique is compared with a reference accelerometer device. Furthermore, a simulation by Matlab Simulink is added to the analysis which confirms the results of the experimental data. Results demonstrated that the laser Doppler vibrometer can measure excellently the frequencies of different automotive components for employing in industry. Therefore, it is proposed that LDV technique can be substituted with other traditional non-destructive testing methods.
Online Video Streaming Super-Resolution with Adaptive Look-Up Table Fusion
Mar 01, 2023This paper focuses on Super-resolution for online video streaming data. Applying existing super-resolution methods to video streaming data is non-trivial for two reasons. First, to support application with constant interactions, video streaming has a high requirement for latency that most existing methods are less applicable, especially on low-end devices. Second, existing video streaming protocols (e.g., WebRTC) dynamically adapt the video quality to the network condition, thus video streaming in the wild varies greatly under different network bandwidths, which leads to diverse and dynamic degradations. To tackle the above two challenges, we proposed a novel video super-resolution method for online video streaming. First, we incorporate Look-Up Table (LUT) to lightweight convolution modules to achieve real-time latency. Second, for variant degradations, we propose a pixel-level LUT fusion strategy, where a set of LUT bases are built upon state-of-the-art SR networks pre-trained on different degraded data, and those LUT bases are combined with extracted weights from lightweight convolution modules to adaptively handle dynamic degradations. Extensive experiments are conducted on a newly proposed online video streaming dataset named LDV-WebRTC. All the results show that our method significantly outperforms existing LUT-based methods and offers competitive SR performance with faster speed compared to efficient CNN-based methods. Accelerated with our parallel LUT inference, our proposed method can even support online 720P video SR around 100 FPS.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022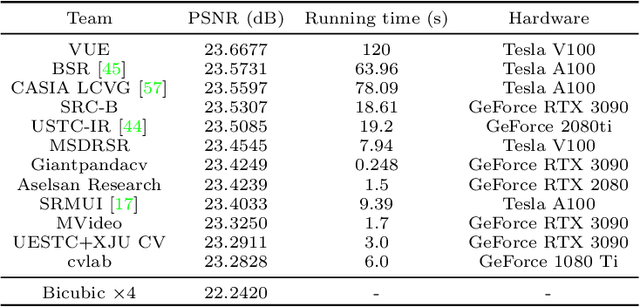
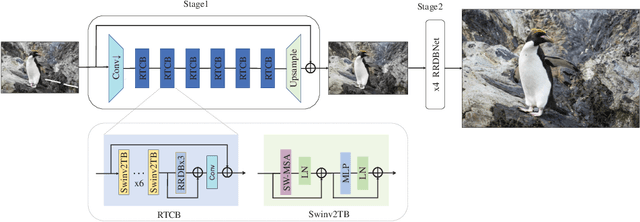

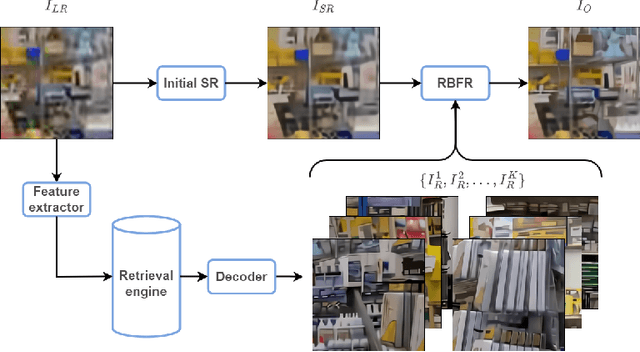
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Accelerated RRT* By Local Directional Visibility
Jul 17, 2022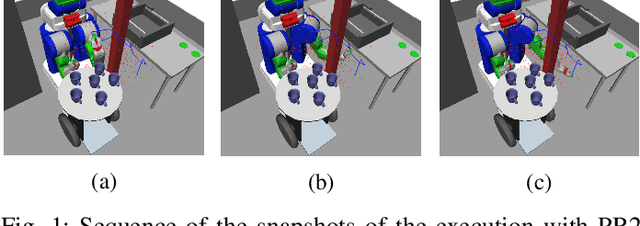
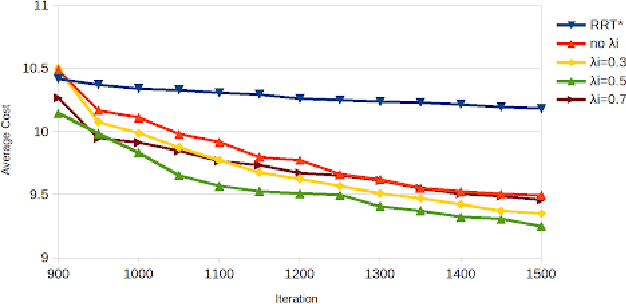
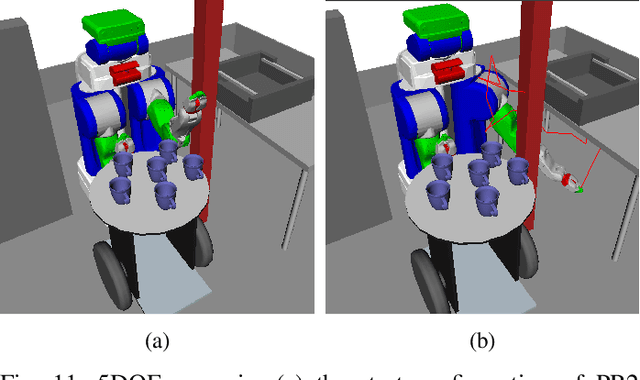
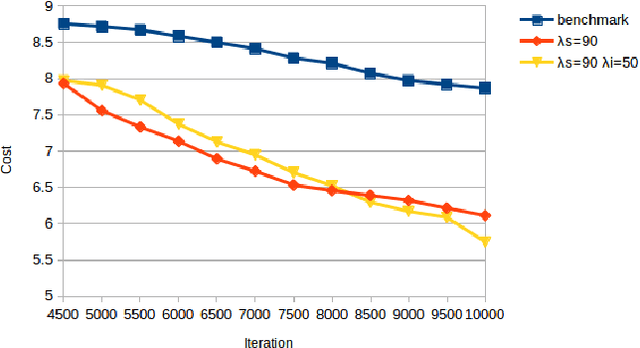
RRT* is an efficient sampling-based motion planning algorithm. However, without taking advantages of accessible environment information, sampling-based algorithms usually result in sampling failures, generate useless nodes, and/or fail in exploring narrow passages. For this paper, in order to better utilize environment information and further improve searching efficiency, we proposed a novel approach to improve RRT* by 1) quantifying local knowledge of the obstacle configurations during neighbour rewiring in terms of directional visibility, 2) collecting environment information during searching, and 3) changing the sampling strategy biasing toward near-obstacle nodes after the first solution found. The proposed algorithm RRT* by Local Directional Visibility (RRT*-LDV) better utilizes local known information and innovates a weighted sampling strategy. The accelerated RRT*-LDV outperforms RRT* in convergence rate and success rate of finding narrow passages. A high Degree-Of-Freedom scenario is also experimented.
NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video: Dataset, Methods and Results
Apr 25, 2022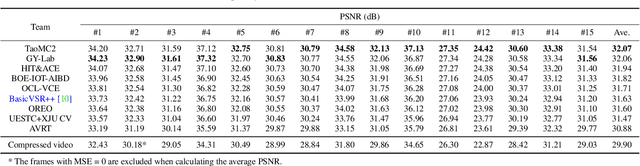
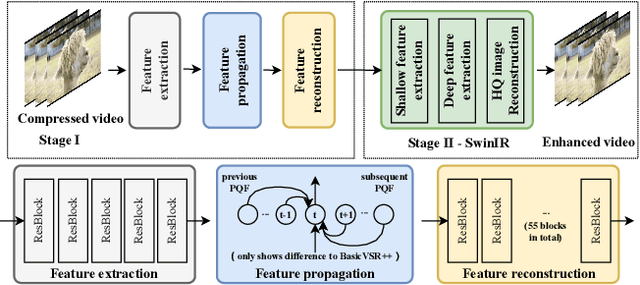
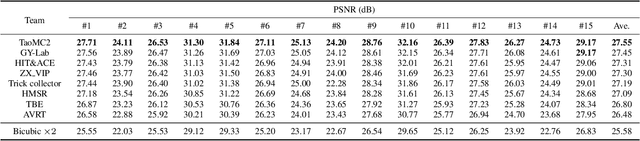

This paper reviews the NTIRE 2022 Challenge on Super-Resolution and Quality Enhancement of Compressed Video. In this challenge, we proposed the LDV 2.0 dataset, which includes the LDV dataset (240 videos) and 95 additional videos. This challenge includes three tracks. Track 1 aims at enhancing the videos compressed by HEVC at a fixed QP. Track 2 and Track 3 target both the super-resolution and quality enhancement of HEVC compressed video. They require x2 and x4 super-resolution, respectively. The three tracks totally attract more than 600 registrations. In the test phase, 8 teams, 8 teams and 12 teams submitted the final results to Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution and quality enhancement of compressed video. The proposed LDV 2.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge (including open-sourced codes) is at https://github.com/RenYang-home/NTIRE22_VEnh_SR.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021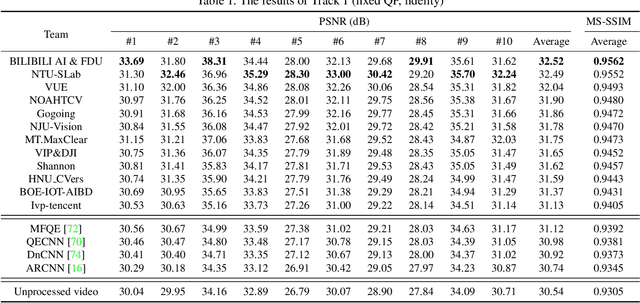
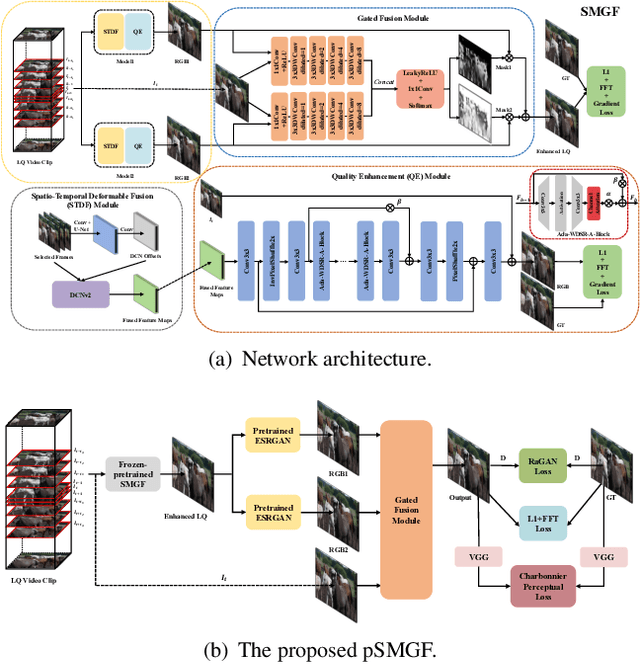
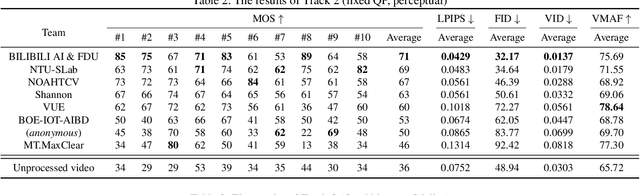
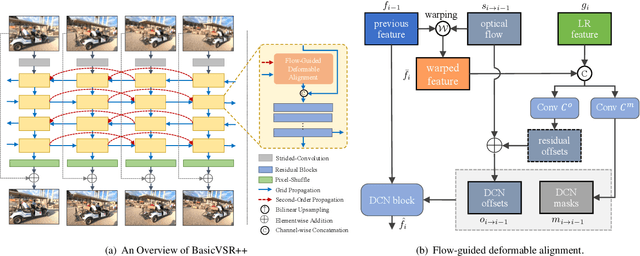
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Dataset and Study
May 02, 2021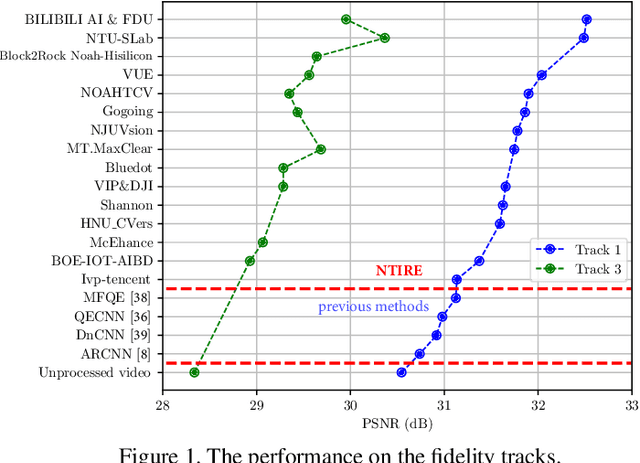
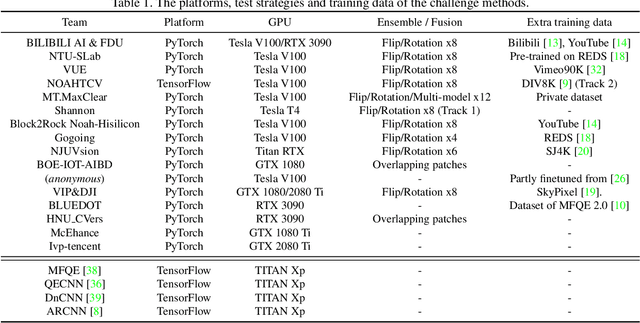
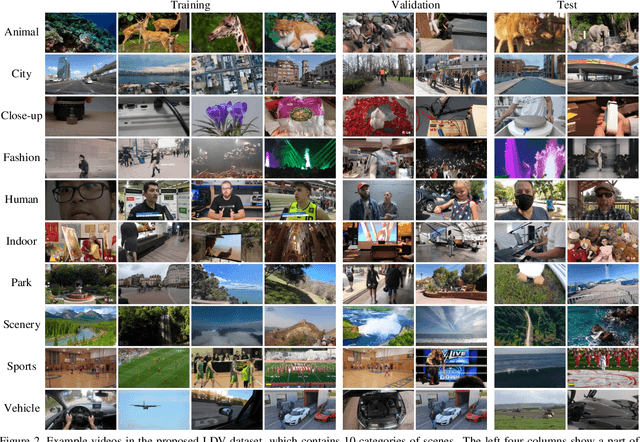
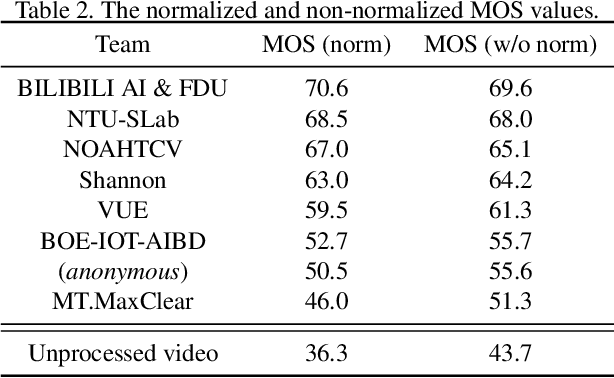
This paper introduces a novel dataset for video enhancement and studies the state-of-the-art methods of the NTIRE 2021 challenge on quality enhancement of compressed video. The challenge is the first NTIRE challenge in this direction, with three competitions, hundreds of participants and tens of proposed solutions. Our newly collected Large-scale Diverse Video (LDV) dataset is employed in the challenge. In our study, we analyze the proposed methods of the challenge and several methods in previous works on the proposed LDV dataset. We find that the NTIRE 2021 challenge advances the state-of-the-art of quality enhancement on compressed video. The proposed LDV dataset is publicly available at the homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
Modeling Electrical Daily Demand in Presence of PHEVs in Smart Grids with Supervised Learning
Apr 14, 2016



Replacing a portion of current light duty vehicles (LDV) with plug-in hybrid electric vehicles (PHEVs) offers the possibility to reduce the dependence on petroleum fuels together with environmental and economic benefits. The charging activity of PHEVs will certainly introduce new load to the power grid. In the framework of the development of a smarter grid, the primary focus of the present study is to propose a model for the electrical daily demand in presence of PHEVs charging. Expected PHEV demand is modeled by the PHEV charging time and the starting time of charge according to real world data. A normal distribution for starting time of charge is assumed. Several distributions for charging time are considered: uniform distribution, Gaussian with positive support, Rician distribution and a non-uniform distribution coming from driving patterns in real-world data. We generate daily demand profiles by using real-world residential profiles throughout 2014 in the presence of different expected PHEV demand models. Support vector machines (SVMs), a set of supervised machine learning models, are employed in order to find the best model to fit the data. SVMs with radial basis function (RBF) and polynomial kernels were tested. Model performances are evaluated by means of mean squared error (MSE) and mean absolute percentage error (MAPE). Best results are obtained with RBF kernel: maximum (worst) values for MSE and MAPE were about 2.89 10-8 and 0.023, respectively.