 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Image Retrieval
Face image retrieval is the task of retrieving faces similar to a query, according to the given criteria (e.g., identity) and ranking them using their distances to the query.
Papers and Code
LP-LLM: End-to-End Real-World Degraded License Plate Text Recognition via Large Multimodal Models
Jan 14, 2026Real-world License Plate Recognition (LPR) faces significant challenges from severe degradations such as motion blur, low resolution, and complex illumination. The prevailing "restoration-then-recognition" two-stage paradigm suffers from a fundamental flaw: the pixel-level optimization objectives of image restoration models are misaligned with the semantic goals of character recognition, leading to artifact interference and error accumulation. While Vision-Language Models (VLMs) have demonstrated powerful general capabilities, they lack explicit structural modeling for license plate character sequences (e.g., fixed length, specific order). To address this, we propose an end-to-end structure-aware multimodal reasoning framework based on Qwen3-VL. The core innovation lies in the Character-Aware Multimodal Reasoning Module (CMRM), which introduces a set of learnable Character Slot Queries. Through a cross-attention mechanism, these queries actively retrieve fine-grained evidence corresponding to character positions from visual features. Subsequently, we inject these character-aware representations back into the visual tokens via residual modulation, enabling the language model to perform autoregressive generation based on explicit structural priors. Furthermore, combined with the LoRA parameter-efficient fine-tuning strategy, the model achieves domain adaptation while retaining the generalization capabilities of the large model. Extensive experiments on both synthetic and real-world severely degraded datasets demonstrate that our method significantly outperforms existing restoration-recognition combinations and general VLMs, validating the superiority of incorporating structured reasoning into large models for low-quality text recognition tasks.
Vclip: Face-based Speaker Generation by Face-voice Association Learning
Jan 06, 2026This paper discusses the task of face-based speech synthesis, a kind of personalized speech synthesis where the synthesized voices are constrained to perceptually match with a reference face image. Due to the lack of TTS-quality audio-visual corpora, previous approaches suffer from either low synthesis quality or domain mismatch induced by a knowledge transfer scheme. This paper proposes a new approach called Vclip that utilizes the facial-semantic knowledge of the CLIP encoder on noisy audio-visual data to learn the association between face and voice efficiently, achieving 89.63% cross-modal verification AUC score on Voxceleb testset. The proposed method then uses a retrieval-based strategy, combined with GMM-based speaker generation module for a downstream TTS system, to produce probable target speakers given reference images. Experimental results demonstrate that the proposed Vclip system in conjunction with the retrieval step can bridge the gap between face and voice features for face-based speech synthesis. And using the feedback information distilled from downstream TTS helps to synthesize voices that match closely with reference faces. Demos available at sos1sos2sixteen.github.io/vclip.
Low-Resource Heuristics for Bahnaric Optical Character Recognition Improvement
Jan 06, 2026Bahnar, a minority language spoken across Vietnam, Cambodia, and Laos, faces significant preservation challenges due to limited research and data availability. This study addresses the critical need for accurate digitization of Bahnar language documents through optical character recognition (OCR) technology. Digitizing scanned paper documents poses significant challenges, as degraded image quality from broken or blurred areas introduces considerable OCR errors that compromise information retrieval systems. We propose a comprehensive approach combining advanced table and non-table detection techniques with probability-based post-processing heuristics to enhance recognition accuracy. Our method first applies detection algorithms to improve input data quality, then employs probabilistic error correction on OCR output. Experimental results indicate a substantial improvement, with recognition accuracy increasing from 72.86% to 79.26%. This work contributes valuable resources for Bahnar language preservation and provides a framework applicable to other minority language digitization efforts.
PMPGuard: Catching Pseudo-Matched Pairs in Remote Sensing Image-Text Retrieval
Dec 21, 2025Remote sensing (RS) image-text retrieval faces significant challenges in real-world datasets due to the presence of Pseudo-Matched Pairs (PMPs), semantically mismatched or weakly aligned image-text pairs, which hinder the learning of reliable cross-modal alignments. To address this issue, we propose a novel retrieval framework that leverages Cross-Modal Gated Attention and a Positive-Negative Awareness Attention mechanism to mitigate the impact of such noisy associations. The gated module dynamically regulates cross-modal information flow, while the awareness mechanism explicitly distinguishes informative (positive) cues from misleading (negative) ones during alignment learning. Extensive experiments on three benchmark RS datasets, i.e., RSICD, RSITMD, and RS5M, demonstrate that our method consistently achieves state-of-the-art performance, highlighting its robustness and effectiveness in handling real-world mismatches and PMPs in RS image-text retrieval tasks.
Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views
Dec 15, 2025



Vector Similarity Search (VSS) in high-dimensional spaces is rapidly emerging as core functionality in next-generation database systems for numerous data-intensive services -- from embedding lookups in large language models (LLMs), to semantic information retrieval and recommendation engines. Current benchmarks, however, evaluate VSS primarily on the recall-latency trade-off against a ground truth defined solely by distance metrics, neglecting how retrieval quality ultimately impacts downstream tasks. This disconnect can mislead both academic research and industrial practice. We present Iceberg, a holistic benchmark suite for end-to-end evaluation of VSS methods in realistic application contexts. From a task-centric view, Iceberg uncovers the Information Loss Funnel, which identifies three principal sources of end-to-end performance degradation: (1) Embedding Loss during feature extraction; (2) Metric Misuse, where distances poorly reflect task relevance; (3) Data Distribution Sensitivity, highlighting index robustness across skews and modalities. For a more comprehensive assessment, Iceberg spans eight diverse datasets across key domains such as image classification, face recognition, text retrieval, and recommendation systems. Each dataset, ranging from 1M to 100M vectors, includes rich, task-specific labels and evaluation metrics, enabling assessment of retrieval algorithms within the full application pipeline rather than in isolation. Iceberg benchmarks 13 state-of-the-art VSS methods and re-ranks them based on application-level metrics, revealing substantial deviations from traditional rankings derived purely from recall-latency evaluations. Building on these insights, we define a set of task-centric meta-features and derive an interpretable decision tree to guide practitioners in selecting and tuning VSS methods for their specific workloads.
Depth-Copy-Paste: Multimodal and Depth-Aware Compositing for Robust Face Detection
Dec 12, 2025Data augmentation is crucial for improving the robustness of face detection systems, especially under challenging conditions such as occlusion, illumination variation, and complex environments. Traditional copy paste augmentation often produces unrealistic composites due to inaccurate foreground extraction, inconsistent scene geometry, and mismatched background semantics. To address these limitations, we propose Depth Copy Paste, a multimodal and depth aware augmentation framework that generates diverse and physically consistent face detection training samples by copying full body person instances and pasting them into semantically compatible scenes. Our approach first employs BLIP and CLIP to jointly assess semantic and visual coherence, enabling automatic retrieval of the most suitable background images for the given foreground person. To ensure high quality foreground masks that preserve facial details, we integrate SAM3 for precise segmentation and Depth-Anything to extract only the non occluded visible person regions, preventing corrupted facial textures from being used in augmentation. For geometric realism, we introduce a depth guided sliding window placement mechanism that searches over the background depth map to identify paste locations with optimal depth continuity and scale alignment. The resulting composites exhibit natural depth relationships and improved visual plausibility. Extensive experiments show that Depth Copy Paste provides more diverse and realistic training data, leading to significant performance improvements in downstream face detection tasks compared with traditional copy paste and depth free augmentation methods.
A Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
DAFM: Dynamic Adaptive Fusion for Multi-Model Collaboration in Composed Image Retrieval
Nov 07, 2025Composed Image Retrieval (CIR) is a cross-modal task that aims to retrieve target images from large-scale databases using a reference image and a modification text. Most existing methods rely on a single model to perform feature fusion and similarity matching. However, this paradigm faces two major challenges. First, one model alone can't see the whole picture and the tiny details at the same time; it has to handle different tasks with the same weights, so it often misses the small but important links between image and text. Second, the absence of dynamic weight allocation prevents adaptive leveraging of complementary model strengths, so the resulting embedding drifts away from the target and misleads the nearest-neighbor search in CIR. To address these limitations, we propose Dynamic Adaptive Fusion (DAFM) for multi-model collaboration in CIR. Rather than optimizing a single method in isolation, DAFM exploits the complementary strengths of heterogeneous models and adaptively rebalances their contributions. This not only maximizes retrieval accuracy but also ensures that the performance gains are independent of the fusion order, highlighting the robustness of our approach. Experiments on the CIRR and FashionIQ benchmarks demonstrate consistent improvements. Our method achieves a Recall@10 of 93.21 and an Rmean of 84.43 on CIRR, and an average Rmean of 67.48 on FashionIQ, surpassing recent strong baselines by up to 4.5%. These results confirm that dynamic multi-model collaboration provides an effective and general solution for CIR.
ERMoE: Eigen-Reparameterized Mixture-of-Experts for Stable Routing and Interpretable Specialization
Nov 14, 2025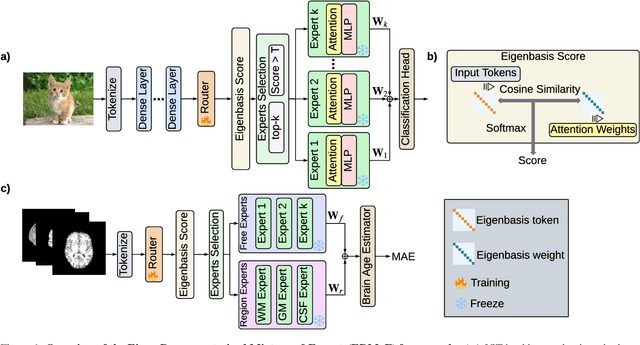



Mixture-of-Experts (MoE) architectures expand model capacity by sparsely activating experts but face two core challenges: misalignment between router logits and each expert's internal structure leads to unstable routing and expert underutilization, and load imbalances create straggler bottlenecks. Standard solutions, such as auxiliary load-balancing losses, can reduce load disparities but often weaken expert specialization and hurt downstream performance. To address these issues, we propose ERMoE, a sparse MoE transformer that reparameterizes each expert in a learned orthonormal eigenbasis and replaces learned gating logits with an "Eigenbasis Score", defined as the cosine similarity between input features and an expert's basis. This content-aware routing ties token assignments directly to experts' representation spaces, stabilizing utilization and promoting interpretable specialization without sacrificing sparsity. Crucially, ERMoE removes the need for explicit balancing losses and avoids the interfering gradients they introduce. We show that ERMoE achieves state-of-the-art accuracy on ImageNet classification and cross-modal image-text retrieval benchmarks (e.g., COCO, Flickr30K), while naturally producing flatter expert load distributions. Moreover, a 3D MRI variant (ERMoE-ba) improves brain age prediction accuracy by more than 7\% and yields anatomically interpretable expert specializations. ERMoE thus introduces a new architectural principle for sparse expert models that directly addresses routing instabilities and enables improved performance with scalable, interpretable specialization.
OracleAgent: A Multimodal Reasoning Agent for Oracle Bone Script Research
Oct 30, 2025As one of the earliest writing systems, Oracle Bone Script (OBS) preserves the cultural and intellectual heritage of ancient civilizations. However, current OBS research faces two major challenges: (1) the interpretation of OBS involves a complex workflow comprising multiple serial and parallel sub-tasks, and (2) the efficiency of OBS information organization and retrieval remains a critical bottleneck, as scholars often spend substantial effort searching for, compiling, and managing relevant resources. To address these challenges, we present OracleAgent, the first agent system designed for the structured management and retrieval of OBS-related information. OracleAgent seamlessly integrates multiple OBS analysis tools, empowered by large language models (LLMs), and can flexibly orchestrate these components. Additionally, we construct a comprehensive domain-specific multimodal knowledge base for OBS, which is built through a rigorous multi-year process of data collection, cleaning, and expert annotation. The knowledge base comprises over 1.4M single-character rubbing images and 80K interpretation texts. OracleAgent leverages this resource through its multimodal tools to assist experts in retrieval tasks of character, document, interpretation text, and rubbing image. Extensive experiments demonstrate that OracleAgent achieves superior performance across a range of multimodal reasoning and generation tasks, surpassing leading mainstream multimodal large language models (MLLMs) (e.g., GPT-4o). Furthermore, our case study illustrates that OracleAgent can effectively assist domain experts, significantly reducing the time cost of OBS research. These results highlight OracleAgent as a significant step toward the practical deployment of OBS-assisted research and automated interpretation systems.