 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDast
Papers and Code
A Disease-Aware Dual-Stage Framework for Chest X-ray Report Generation
Nov 15, 2025Radiology report generation from chest X-rays is an important task in artificial intelligence with the potential to greatly reduce radiologists' workload and shorten patient wait times. Despite recent advances, existing approaches often lack sufficient disease-awareness in visual representations and adequate vision-language alignment to meet the specialized requirements of medical image analysis. As a result, these models usually overlook critical pathological features on chest X-rays and struggle to generate clinically accurate reports. To address these limitations, we propose a novel dual-stage disease-aware framework for chest X-ray report generation. In Stage~1, our model learns Disease-Aware Semantic Tokens (DASTs) corresponding to specific pathology categories through cross-attention mechanisms and multi-label classification, while simultaneously aligning vision and language representations via contrastive learning. In Stage~2, we introduce a Disease-Visual Attention Fusion (DVAF) module to integrate disease-aware representations with visual features, along with a Dual-Modal Similarity Retrieval (DMSR) mechanism that combines visual and disease-specific similarities to retrieve relevant exemplars, providing contextual guidance during report generation. Extensive experiments on benchmark datasets (i.e., CheXpert Plus, IU X-ray, and MIMIC-CXR) demonstrate that our disease-aware framework achieves state-of-the-art performance in chest X-ray report generation, with significant improvements in clinical accuracy and linguistic quality.
Collaborative penetration testing suite for emerging generative AI algorithms
Oct 22, 2025Problem Space: AI Vulnerabilities and Quantum Threats Generative AI vulnerabilities: model inversion, data poisoning, adversarial inputs. Quantum threats Shor Algorithm breaking RSA ECC encryption. Challenge Secure generative AI models against classical and quantum cyberattacks. Proposed Solution Collaborative Penetration Testing Suite Five Integrated Components: DAST SAST OWASP ZAP, Burp Suite, SonarQube, Fortify. IAST Contrast Assess integrated with CI CD pipeline. Blockchain Logging Hyperledger Fabric for tamper-proof logs. Quantum Cryptography Lattice based RLWE protocols. AI Red Team Simulations Adversarial ML & Quantum-assisted attacks. Integration Layer: Unified workflow for AI, cybersecurity, and quantum experts. Key Results 300+ vulnerabilities identified across test environments. 70% reduction in high-severity issues within 2 weeks. 90% resolution efficiency for blockchain-logged vulnerabilities. Quantum-resistant cryptography maintained 100% integrity in tests. Outcome: Quantum AI Security Protocol integrating Blockchain Quantum Cryptography AI Red Teaming.
DAST: Difficulty-Aware Self-Training on Large Language Models
Mar 12, 2025Present Large Language Models (LLM) self-training methods always under-sample on challenging queries, leading to inadequate learning on difficult problems which limits LLMs' ability. Therefore, this work proposes a difficulty-aware self-training (DAST) framework that focuses on improving both the quantity and quality of self-generated responses on challenging queries during self-training. DAST is specified in three components: 1) sampling-based difficulty level estimation, 2) difficulty-aware data augmentation, and 3) the self-training algorithm using SFT and DPO respectively. Experiments on mathematical tasks demonstrate the effectiveness and generalization of DAST, highlighting the critical role of difficulty-aware strategies in advancing LLM self-training.
DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models
Mar 06, 2025Recent advancements in slow-thinking reasoning models have shown exceptional performance in complex reasoning tasks. However, these models often exhibit overthinking-generating redundant reasoning steps for simple problems, leading to excessive computational resource usage. While current mitigation strategies uniformly reduce reasoning tokens, they risk degrading performance on challenging tasks that require extended reasoning. This paper introduces Difficulty-Adaptive Slow-Thinking (DAST), a novel framework that enables models to autonomously adjust the length of Chain-of-Thought(CoT) based on problem difficulty. We first propose a Token Length Budget (TLB) metric to quantify difficulty, then leveraging length-aware reward shaping and length preference optimization to implement DAST. DAST penalizes overlong responses for simple tasks while incentivizing sufficient reasoning for complex problems. Experiments on diverse datasets and model scales demonstrate that DAST effectively mitigates overthinking (reducing token usage by over 30\% on average) while preserving reasoning accuracy on complex problems.
DAST: Context-Aware Compression in LLMs via Dynamic Allocation of Soft Tokens
Feb 17, 2025



Large Language Models (LLMs) face computational inefficiencies and redundant processing when handling long context inputs, prompting a focus on compression techniques. While existing semantic vector-based compression methods achieve promising performance, these methods fail to account for the intrinsic information density variations between context chunks, instead allocating soft tokens uniformly across context chunks. This uniform distribution inevitably diminishes allocation to information-critical regions. To address this, we propose Dynamic Allocation of Soft Tokens (DAST), a simple yet effective method that leverages the LLM's intrinsic understanding of contextual relevance to guide compression. DAST combines perplexity-based local information with attention-driven global information to dynamically allocate soft tokens to the informative-rich chunks, enabling effective, context-aware compression. Experimental results across multiple benchmarks demonstrate that DAST surpasses state-of-the-art methods.
Domain Generalized Recaptured Screen Image Identification Using SWIN Transformer
Jul 25, 2024An increasing number of classification approaches have been developed to address the issue of image rebroadcast and recapturing, a standard attack strategy in insurance frauds, face spoofing, and video piracy. However, most of them neglected scale variations and domain generalization scenarios, performing poorly in instances involving domain shifts, typically made worse by inter-domain and cross-domain scale variances. To overcome these issues, we propose a cascaded data augmentation and SWIN transformer domain generalization framework (DAST-DG) in the current research work Initially, we examine the disparity in dataset representation. A feature generator is trained to make authentic images from various domains indistinguishable. This process is then applied to recaptured images, creating a dual adversarial learning setup. Extensive experiments demonstrate that our approach is practical and surpasses state-of-the-art methods across different databases. Our model achieves an accuracy of approximately 82\% with a precision of 95\% on high-variance datasets.
One model to rule them all ? Towards End-to-End Joint Speaker Diarization and Speech Recognition
Oct 02, 2023This paper presents a novel framework for joint speaker diarization (SD) and automatic speech recognition (ASR), named SLIDAR (sliding-window diarization-augmented recognition). SLIDAR can process arbitrary length inputs and can handle any number of speakers, effectively solving ``who spoke what, when'' concurrently. SLIDAR leverages a sliding window approach and consists of an end-to-end diarization-augmented speech transcription (E2E DAST) model which provides, locally, for each window: transcripts, diarization and speaker embeddings. The E2E DAST model is based on an encoder-decoder architecture and leverages recent techniques such as serialized output training and ``Whisper-style" prompting. The local outputs are then combined to get the final SD+ASR result by clustering the speaker embeddings to get global speaker identities. Experiments performed on monaural recordings from the AMI corpus confirm the effectiveness of the method in both close-talk and far-field speech scenarios.
FDINet: Protecting against DNN Model Extraction via Feature Distortion Index
Jun 22, 2023Machine Learning as a Service (MLaaS) platforms have gained popularity due to their accessibility, cost-efficiency, scalability, and rapid development capabilities. However, recent research has highlighted the vulnerability of cloud-based models in MLaaS to model extraction attacks. In this paper, we introduce FDINET, a novel defense mechanism that leverages the feature distribution of deep neural network (DNN) models. Concretely, by analyzing the feature distribution from the adversary's queries, we reveal that the feature distribution of these queries deviates from that of the model's training set. Based on this key observation, we propose Feature Distortion Index (FDI), a metric designed to quantitatively measure the feature distribution deviation of received queries. The proposed FDINET utilizes FDI to train a binary detector and exploits FDI similarity to identify colluding adversaries from distributed extraction attacks. We conduct extensive experiments to evaluate FDINET against six state-of-the-art extraction attacks on four benchmark datasets and four popular model architectures. Empirical results demonstrate the following findings FDINET proves to be highly effective in detecting model extraction, achieving a 100% detection accuracy on DFME and DaST. FDINET is highly efficient, using just 50 queries to raise an extraction alarm with an average confidence of 96.08% for GTSRB. FDINET exhibits the capability to identify colluding adversaries with an accuracy exceeding 91%. Additionally, it demonstrates the ability to detect two types of adaptive attacks.
Vulnerability Detection Using Two-Stage Deep Learning Models
May 08, 2023



Application security is an essential part of developing modern software, as lots of attacks depend on vulnerabilities in software. The number of attacks is increasing globally due to technological advancements. Companies must include security in every stage of developing, testing, and deploying their software in order to prevent data breaches. There are several methods to detect software vulnerability Non-AI-based such as Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST). However, these approaches have substantial false-positive and false-negative rates. On the other side, researchers have been interested in developing an AI-based vulnerability detection system employing deep learning models like BERT, BLSTM, etc. In this paper, we proposed a two-stage solution, two deep learning models were proposed for vulnerability detection in C/C++ source codes, the first stage is CNN which detects if the source code contains any vulnerability (binary classification model) and the second stage is CNN-LTSM that classifies this vulnerability into a class of 50 different types of vulnerabilities (multiclass classification model). Experiments were done on SySeVR dataset. Results show an accuracy of 99% for the first and 98% for the second stage.
Dynamic Adaptive Spatio-temporal Graph Convolution for fMRI Modelling
Sep 26, 2021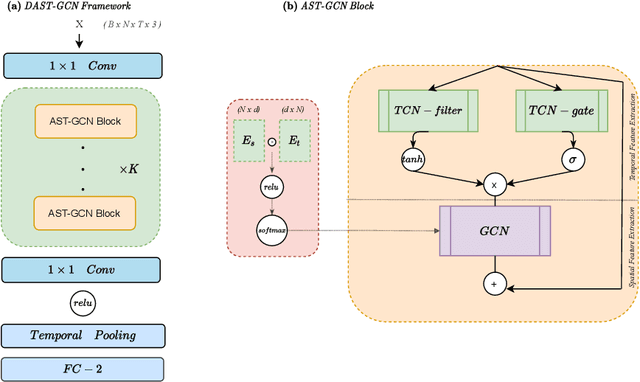
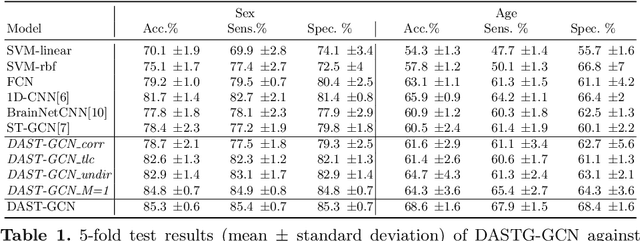
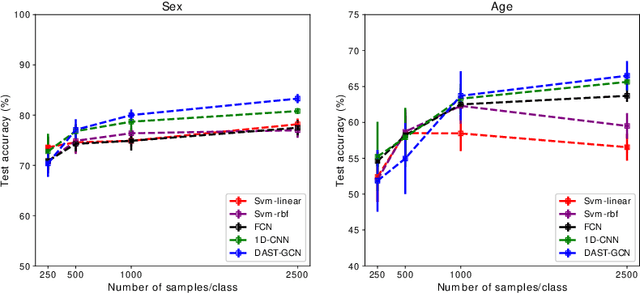
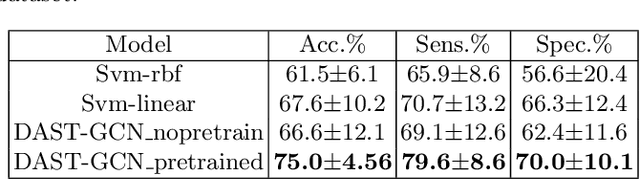
The characterisation of the brain as a functional network in which the connections between brain regions are represented by correlation values across time series has been very popular in the last years. Although this representation has advanced our understanding of brain function, it represents a simplified model of brain connectivity that has a complex dynamic spatio-temporal nature. Oversimplification of the data may hinder the merits of applying advanced non-linear feature extraction algorithms. To this end, we propose a dynamic adaptive spatio-temporal graph convolution (DAST-GCN) model to overcome the shortcomings of pre-defined static correlation-based graph structures. The proposed approach allows end-to-end inference of dynamic connections between brain regions via layer-wise graph structure learning module while mapping brain connectivity to a phenotype in a supervised learning framework. This leverages the computational power of the model, data and targets to represent brain connectivity, and could enable the identification of potential biomarkers for the supervised target in question. We evaluate our pipeline on the UKBiobank dataset for age and gender classification tasks from resting-state functional scans and show that it outperforms currently adapted linear and non-linear methods in neuroimaging. Further, we assess the generalizability of the inferred graph structure by transferring the pre-trained graph to an independent dataset for the same task. Our results demonstrate the task-robustness of the graph against different scanning parameters and demographics.
* Accepted at International Workshop on Machine Learning in Clinical Neuroimaging (MLCN2021)