 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyriSign: A Parallel Corpus for Arabic Text to Syrian Arabic Sign Language Translation
Mar 31, 2026Sign language is the primary approach of communication for the Deaf and Hard-of-Hearing (DHH) community. While there are numerous benchmarks for high-resource sign languages, low-resource languages like Arabic remain underrepresented. Currently, there is no publicly available dataset for Syrian Arabic Sign Language (SyArSL). To overcome this gap, we introduce SyriSign, a dataset comprising 1500 video samples across 150 unique lexical signs, designed for text-to-SyArSL translation tasks. This work aims to reduce communication barriers in Syria, as most news are delivered in spoken or written Arabic, which is often inaccessible to the deaf community. We evaluated SyriSign using three deep learning architectures: MotionCLIP for semantic motion generation, T2M-GPT for text-conditioned motion synthesis, and SignCLIP for bilingual embedding alignment. Experimental results indicate that while generative approaches show strong potential for sign representation, the limited dataset size constrains generalization performance. We will release SyriSign publicly, hoping it serves as an initial benchmark.
ArEEG_Words: Dataset for Envisioned Speech Recognition using EEG for Arabic Words
Nov 28, 2024



Brain-Computer-Interface (BCI) aims to support communication-impaired patients by translating neural signals into speech. A notable research topic in BCI involves Electroencephalography (EEG) signals that measure the electrical activity in the brain. While significant advancements have been made in BCI EEG research, a major limitation still exists: the scarcity of publicly available EEG datasets for non-English languages, such as Arabic. To address this gap, we introduce in this paper ArEEG_Words dataset, a novel EEG dataset recorded from 22 participants with mean age of 22 years (5 female, 17 male) using a 14-channel Emotiv Epoc X device. The participants were asked to be free from any effects on their nervous system, such as coffee, alcohol, cigarettes, and so 8 hours before recording. They were asked to stay calm in a clam room during imagining one of the 16 Arabic Words for 10 seconds. The words include 16 commonly used words such as up, down, left, and right. A total of 352 EEG recordings were collected, then each recording was divided into multiple 250ms signals, resulting in a total of 15,360 EEG signals. To the best of our knowledge, ArEEG_Words data is the first of its kind in Arabic EEG domain. Moreover, it is publicly available for researchers as we hope that will fill the gap in Arabic EEG research.
ArEEG_Chars: Dataset for Envisioned Speech Recognition using EEG for Arabic Characters
Feb 24, 2024



Brain-Computer-Interface (BCI) has been a hot research topic in the last few years that could help paralyzed people in their lives. Several researches were done to classify electroencephalography (EEG) signals automatically into English characters and words. Arabic language is one of the most used languages around the world. However, to the best of our knowledge, there is no dataset for Arabic characters EEG signals. In this paper, we have created an EEG dataset for Arabic characters and named it ArEEG_Chars. Moreover, several experiments were done on ArEEG_Chars using deep learning. Best results were achieved using LSTM and reached an accuracy of 97%. ArEEG_Chars dataset will be public for researchers.
Voting-based Multimodal Automatic Deception Detection
Jun 30, 2023



Automatic Deception Detection has been a hot research topic for a long time, using machine learning and deep learning to automatically detect deception, brings new light to this old field. In this paper, we proposed a voting-based method for automatic deception detection from videos using audio, visual and lexical features. Experiments were done on two datasets, the Real-life trial dataset by Michigan University and the Miami University deception detection dataset. Video samples were split into frames of images, audio, and manuscripts. Our Voting-based Multimodal proposed solution consists of three models. The first model is CNN for detecting deception from images, the second model is Support Vector Machine (SVM) on Mel spectrograms for detecting deception from audio and the third model is Word2Vec on Support Vector Machine (SVM) for detecting deception from manuscripts. Our proposed solution outperforms state of the art. Best results achieved on images, audio and text were 97%, 96%, 92% respectively on Real-Life Trial Dataset, and 97%, 82%, 73% on video, audio and text respectively on Miami University Deception Detection.
Mispronunciation Detection of Basic Quranic Recitation Rules using Deep Learning
May 10, 2023In Islam, readers must apply a set of pronunciation rules called Tajweed rules to recite the Quran in the same way that the angel Jibrael taught the Prophet, Muhammad. The traditional process of learning the correct application of these rules requires a human who must have a license and great experience to detect mispronunciation. Due to the increasing number of Muslims around the world, the number of Tajweed teachers is not enough nowadays for daily recitation practice for every Muslim. Therefore, lots of work has been done for automatic Tajweed rules' mispronunciation detection to help readers recite Quran correctly in an easier way and shorter time than traditional learning ways. All previous works have three common problems. First, most of them focused on machine learning algorithms only. Second, they used private datasets with no benchmark to compare with. Third, they did not take into consideration the sequence of input data optimally, although the speech signal is time series. To overcome these problems, we proposed a solution that consists of Mel-Frequency Cepstral Coefficient (MFCC) features with Long Short-Term Memory (LSTM) neural networks which use the time series, to detect mispronunciation in Tajweed rules. In addition, our experiments were performed on a public dataset, the QDAT dataset, which contains more than 1500 voices of the correct and incorrect recitation of three Tajweed rules (Separate stretching , Tight Noon , and Hide ). To the best of our knowledge, the QDAT dataset has not been used by any research paper yet. We compared the performance of the proposed LSTM model with traditional machine learning algorithms used in SoTA. The LSTM model with time series showed clear superiority over traditional machine learning. The accuracy achieved by LSTM on the QDAT dataset was 96%, 95%, and 96% for the three rules (Separate stretching, Tight Noon, and Hide), respectively.
Quran Recitation Recognition using End-to-End Deep Learning
May 10, 2023



The Quran is the holy scripture of Islam, and its recitation is an important aspect of the religion. Recognizing the recitation of the Holy Quran automatically is a challenging task due to its unique rules that are not applied in normal speaking speeches. A lot of research has been done in this domain, but previous works have detected recitation errors as a classification task or used traditional automatic speech recognition (ASR). In this paper, we proposed a novel end-to-end deep learning model for recognizing the recitation of the Holy Quran. The proposed model is a CNN-Bidirectional GRU encoder that uses CTC as an objective function, and a character-based decoder which is a beam search decoder. Moreover, all previous works were done on small private datasets consisting of short verses and a few chapters of the Holy Quran. As a result of using private datasets, no comparisons were done. To overcome this issue, we used a public dataset that has recently been published (Ar-DAD) and contains about 37 chapters that were recited by 30 reciters, with different recitation speeds and different types of pronunciation rules. The proposed model performance was evaluated using the most common evaluation metrics in speech recognition, word error rate (WER), and character error rate (CER). The results were 8.34% WER and 2.42% CER. We hope this research will be a baseline for comparisons with future research on this public new dataset (Ar-DAD).
Vulnerability Detection Using Two-Stage Deep Learning Models
May 08, 2023



Application security is an essential part of developing modern software, as lots of attacks depend on vulnerabilities in software. The number of attacks is increasing globally due to technological advancements. Companies must include security in every stage of developing, testing, and deploying their software in order to prevent data breaches. There are several methods to detect software vulnerability Non-AI-based such as Static Application Security Testing (SAST) and Dynamic Application Security Testing (DAST). However, these approaches have substantial false-positive and false-negative rates. On the other side, researchers have been interested in developing an AI-based vulnerability detection system employing deep learning models like BERT, BLSTM, etc. In this paper, we proposed a two-stage solution, two deep learning models were proposed for vulnerability detection in C/C++ source codes, the first stage is CNN which detects if the source code contains any vulnerability (binary classification model) and the second stage is CNN-LTSM that classifies this vulnerability into a class of 50 different types of vulnerabilities (multiclass classification model). Experiments were done on SySeVR dataset. Results show an accuracy of 99% for the first and 98% for the second stage.
An experimental study in Real-time Facial Emotion Recognition on new 3RL dataset
Apr 06, 2023Although real-time facial emotion recognition is a hot topic research domain in the field of human-computer interaction, state-of the-art available datasets still suffer from various problems, such as some unrelated photos such as document photos, unbalanced numbers of photos in each class, and misleading images that can negatively affect correct classification. The 3RL dataset was created, which contains approximately 24K images and will be publicly available, to overcome previously available dataset problems. The 3RL dataset is labelled with five basic emotions: happiness, fear, sadness, disgust, and anger. Moreover, we compared the 3RL dataset with other famous state-of-the-art datasets (FER dataset, CK+ dataset), and we applied the most commonly used algorithms in previous works, SVM and CNN. The results show a noticeable improvement in generalization on the 3RL dataset. Experiments have shown an accuracy of up to 91.4% on 3RL dataset using CNN where results on FER2013, CK+ are, respectively (approximately from 60% to 85%).
FastPacket: Towards Pre-trained Packets Embedding based on FastText for next-generation NIDS
Sep 29, 2022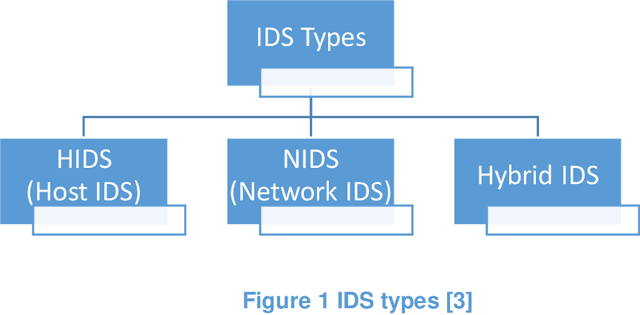
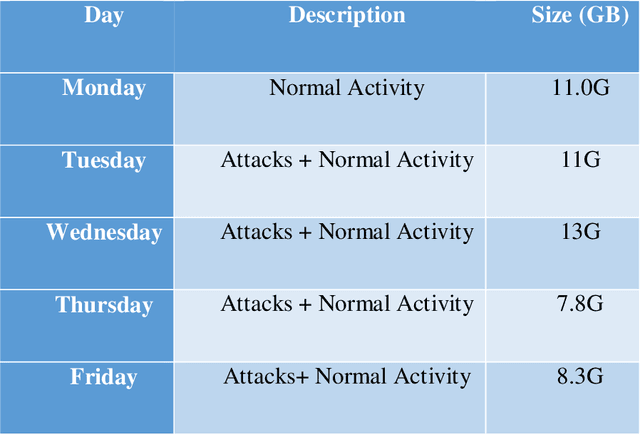
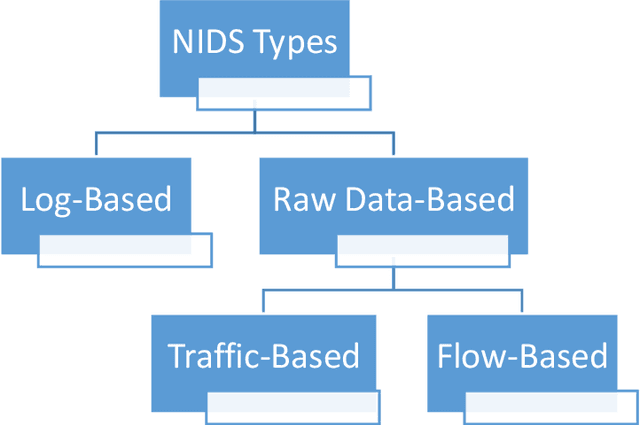
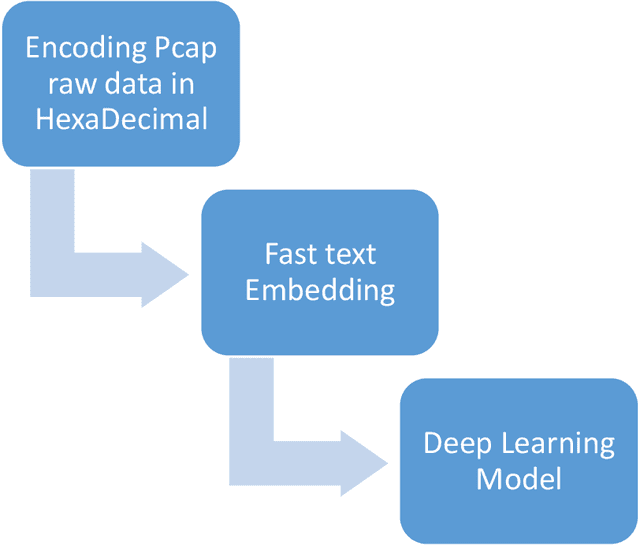
New Attacks are increasingly used by attackers everyday but many of them are not detected by Intrusion Detection Systems as most IDS ignore raw packet information and only care about some basic statistical information extracted from PCAP files. Using networking programs to extract fixed statistical features from packets is good, but may not enough to detect nowadays challenges. We think that it is time to utilize big data and deep learning for automatic dynamic feature extraction from packets. It is time to get inspired by deep learning pre-trained models in computer vision and natural language processing, so security deep learning solutions will have its pre-trained models on big datasets to be used in future researches. In this paper, we proposed a new approach for embedding packets based on character-level embeddings, inspired by FastText success on text data. We called this approach FastPacket. Results are measured on subsets of CIC-IDS-2017 dataset, but we expect promising results on big data pre-trained models. We suggest building pre-trained FastPacket on MAWI big dataset and make it available to community, similar to FastText. To be able to outperform currently used NIDS, to start a new era of packet-level NIDS that can better detect complex attacks.
Anomaly detection optimization using big data and deep learning to reduce false-positive
Sep 28, 2022Anomaly-based Intrusion Detection System (IDS) has been a hot research topic because of its ability to detect new threats rather than only memorized signatures threats of signature-based IDS. Especially after the availability of advanced technologies that increase the number of hacking tools and increase the risk impact of an attack. The problem of any anomaly-based model is its high false-positive rate. The high false-positive rate is the reason why anomaly IDS is not commonly applied in practice. Because anomaly-based models classify an unseen pattern as a threat where it may be normal but not included in the training dataset. This type of problem is called overfitting where the model is not able to generalize. Optimizing Anomaly-based models by having a big training dataset that includes all possible normal cases may be an optimal solution but could not be applied in practice. Although we can increase the number of training samples to include much more normal cases, still we need a model that has more ability to generalize. In this research paper, we propose applying deep model instead of traditional models because it has more ability to generalize. Thus, we will obtain less false-positive by using big data and deep model. We made a comparison between machine learning and deep learning algorithms in the optimization of anomaly-based IDS by decreasing the false-positive rate. We did an experiment on the NSL-KDD benchmark and compared our results with one of the best used classifiers in traditional learning in IDS optimization. The experiment shows 10% lower false-positive by using deep learning instead of traditional learning.