 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Operations-Oriented Inference Optimization Techniques for Large Models
Jun 18, 2026Large model inference optimization serves as a key foundation for supporting the scalable, low-cost, and highly stable operation of large model services. Centered on token-oriented inference optimization technology, this paper proposes for the first time a four-layer technical architecture consisting of Multi-model Fusion, Model Optimization, Compute-Model Fusion, and Compute-Network-Model Fusion. It systematically reviews the key technologies and current industry status across these four levels and analyzes the application value of related technologies in real-world business scenarios. This paper provides a practical technical path for reducing token production costs, improving token service efficiency, ensuring the stability of token supply, and driving the transition of large model services from being merely callable to being operable.
HiMPO: Hindsight-Informed Memory Policy Optimization for Less-Entangled Credit in Long-Horizon Agents
Jun 15, 2026Long-horizon agents rely on memory mechanisms to compress interaction history, but optimizing memory writing faces a distinct credit assignment challenge: a memory update may be rewarded or penalized due to downstream tool failures, noisy observations, or reasoning errors rather than its own contribution. This causally entangled credit can lead agents to discard useful evidence or preserve irrelevant information. We propose HiMPO, a Hindsight-Informed Memory Policy Optimization framework for assigning less-entangled credit to memory-writing actions in long-horizon agents. HiMPO first estimates the local utility of a memory update by comparing the task-relevant information recoverable from the previous and updated memories under the same pre-write state. It then uses hindsight relevance as a bounded retrospective filter that attenuates memory credit when local utility is not supported by the target outcome. The resulting memory-specific advantage is applied only to memory tokens, while trajectory-level rewards optimize the rest of the agent behavior. Across judge-based open-domain tasks and objective compressive-memory QA, HiMPO improves over strong memory-based and RL-based baselines while preserving compressed-context efficiency. Controlled interventions further show that HiMPO reduces blame leakage from tool-induced errors and improves attribution fidelity of memory updates.
HEAL: Hindsight Entropy-Assisted Learning for Reasoning Distillation
Mar 11, 2026Distilling reasoning capabilities from Large Reasoning Models (LRMs) into smaller models is typically constrained by the limitation of rejection sampling. Standard methods treat the teacher as a static filter, discarding complex "corner-case" problems where the teacher fails to explore valid solutions independently, thereby creating an artificial "Teacher Ceiling" for the student. In this work, we propose Hindsight Entropy-Assisted Learning (HEAL), an RL-free framework designed to bridge this reasoning gap. Drawing on the educational theory of the Zone of Proximal Development(ZPD), HEAL synergizes three core modules: (1) Guided Entropy-Assisted Repair (GEAR), an active intervention mechanism that detects critical reasoning breakpoints via entropy dynamics and injects targeted hindsight hints to repair broken trajectories; (2) Perplexity-Uncertainty Ratio Estimator (PURE), a rigorous filtering protocol that decouples genuine cognitive breakthroughs from spurious shortcuts; and (3) Progressive Answer-guided Curriculum Evolution (PACE), a three-stage distillation strategy that organizes training from foundational alignment to frontier breakthrough. Extensive experiments on multiple benchmarks demonstrate that HEAL significantly outperforms traditional SFT distillation and other baselines.
Quantitative Analysis of Performance Drop in DeepSeek Model Quantization
May 05, 2025Recently, there is a high demand for deploying DeepSeek-R1 and V3 locally, possibly because the official service often suffers from being busy and some organizations have data privacy concerns. While single-machine deployment offers infrastructure simplicity, the models' 671B FP8 parameter configuration exceeds the practical memory limits of a standard 8-GPU machine. Quantization is a widely used technique that helps reduce model memory consumption. However, it is unclear what the performance of DeepSeek-R1 and V3 will be after being quantized. This technical report presents the first quantitative evaluation of multi-bitwidth quantization across the complete DeepSeek model spectrum. Key findings reveal that 4-bit quantization maintains little performance degradation versus FP8 while enabling single-machine deployment on standard NVIDIA GPU devices. We further propose DQ3_K_M, a dynamic 3-bit quantization method that significantly outperforms traditional Q3_K_M variant on various benchmarks, which is also comparable with 4-bit quantization (Q4_K_M) approach in most tasks. Moreover, DQ3_K_M supports single-machine deployment configurations for both NVIDIA H100/A100 and Huawei 910B. Our implementation of DQ3\_K\_M is released at https://github.com/UnicomAI/DeepSeek-Eval, containing optimized 3-bit quantized variants of both DeepSeek-R1 and DeepSeek-V3.
DAST: Difficulty-Adaptive Slow-Thinking for Large Reasoning Models
Mar 06, 2025Recent advancements in slow-thinking reasoning models have shown exceptional performance in complex reasoning tasks. However, these models often exhibit overthinking-generating redundant reasoning steps for simple problems, leading to excessive computational resource usage. While current mitigation strategies uniformly reduce reasoning tokens, they risk degrading performance on challenging tasks that require extended reasoning. This paper introduces Difficulty-Adaptive Slow-Thinking (DAST), a novel framework that enables models to autonomously adjust the length of Chain-of-Thought(CoT) based on problem difficulty. We first propose a Token Length Budget (TLB) metric to quantify difficulty, then leveraging length-aware reward shaping and length preference optimization to implement DAST. DAST penalizes overlong responses for simple tasks while incentivizing sufficient reasoning for complex problems. Experiments on diverse datasets and model scales demonstrate that DAST effectively mitigates overthinking (reducing token usage by over 30\% on average) while preserving reasoning accuracy on complex problems.
A Tensor-Based Sub-Mode Coordinate Algorithm for Stock Prediction
May 21, 2018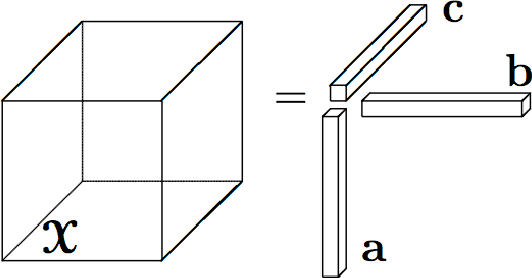
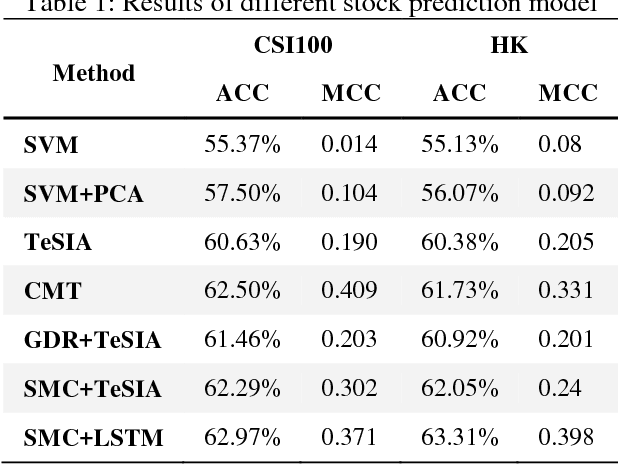
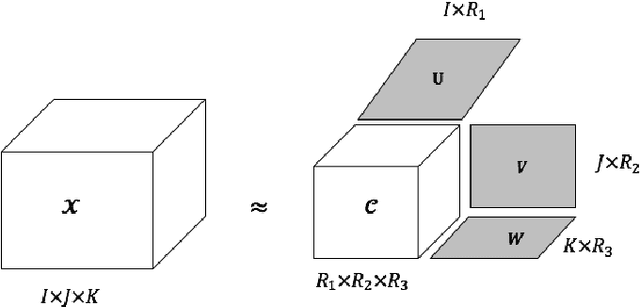
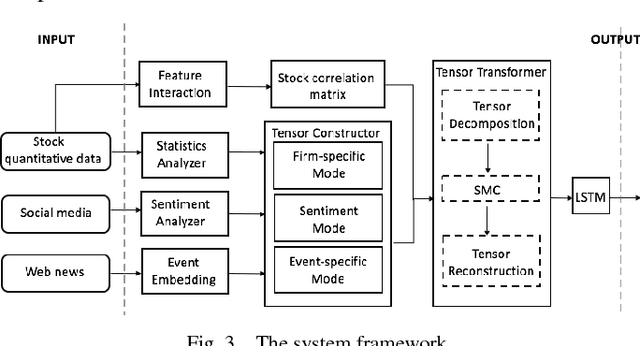
The investment on the stock market is prone to be affected by the Internet. For the purpose of improving the prediction accuracy, we propose a multi-task stock prediction model that not only considers the stock correlations but also supports multi-source data fusion. Our proposed model first utilizes tensor to integrate the multi-sourced data, including financial Web news, investors' sentiments extracted from the social network and some quantitative data on stocks. In this way, the intrinsic relationships among different information sources can be captured, and meanwhile, multi-sourced information can be complemented to solve the data sparsity problem. Secondly, we propose an improved sub-mode coordinate algorithm (SMC). SMC is based on the stock similarity, aiming to reduce the variance of their subspace in each dimension produced by the tensor decomposition. The algorithm is able to improve the quality of the input features, and thus improves the prediction accuracy. And the paper utilizes the Long Short-Term Memory (LSTM) neural network model to predict the stock fluctuation trends. Finally, the experiments on 78 A-share stocks in CSI 100 and thirteen popular HK stocks in the year 2015 and 2016 are conducted. The results demonstrate the improvement on the prediction accuracy and the effectiveness of the proposed model.