 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidLaDA: Bidirectional Diffusion Large Language Models for Efficient Video Understanding
Jan 25, 2026Standard Autoregressive Video LLMs inevitably suffer from causal masking biases that hinder global spatiotemporal modeling, leading to suboptimal understanding efficiency. We propose VidLaDA, a Video LLM based on Diffusion Language Model utilizing bidirectional attention to capture bidirectional dependencies. To further tackle the inference bottleneck of diffusion decoding on massive video tokens, we introduce MARS-Cache. This framework accelerates inference by combining asynchronous visual cache refreshing with frame-wise chunk attention, effectively pruning redundancy while preserving global connectivity via anchor tokens. Extensive experiments show VidLaDA outperforms diffusion baselines and rivals state-of-the-art autoregressive models (e.g., Qwen2.5-VL and LLaVA-Video), with MARS-Cache delivering over 12x speedup without compromising reasoning accuracy. Code and checkpoints are open-sourced at https://github.com/ziHoHe/VidLaDA.
FRoM-W1: Towards General Humanoid Whole-Body Control with Language Instructions
Jan 19, 2026Humanoid robots are capable of performing various actions such as greeting, dancing and even backflipping. However, these motions are often hard-coded or specifically trained, which limits their versatility. In this work, we present FRoM-W1, an open-source framework designed to achieve general humanoid whole-body motion control using natural language. To universally understand natural language and generate corresponding motions, as well as enable various humanoid robots to stably execute these motions in the physical world under gravity, FRoM-W1 operates in two stages: (a) H-GPT: utilizing massive human data, a large-scale language-driven human whole-body motion generation model is trained to generate diverse natural behaviors. We further leverage the Chain-of-Thought technique to improve the model's generalization in instruction understanding. (b) H-ACT: After retargeting generated human whole-body motions into robot-specific actions, a motion controller that is pretrained and further fine-tuned through reinforcement learning in physical simulation enables humanoid robots to accurately and stably perform corresponding actions. It is then deployed on real robots via a modular simulation-to-reality module. We extensively evaluate FRoM-W1 on Unitree H1 and G1 robots. Results demonstrate superior performance on the HumanML3D-X benchmark for human whole-body motion generation, and our introduced reinforcement learning fine-tuning consistently improves both motion tracking accuracy and task success rates of these humanoid robots. We open-source the entire FRoM-W1 framework and hope it will advance the development of humanoid intelligence.
A Safety Report on GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5
Jan 16, 2026The rapid evolution of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has driven major gains in reasoning, perception, and generation across language and vision, yet whether these advances translate into comparable improvements in safety remains unclear, partly due to fragmented evaluations that focus on isolated modalities or threat models. In this report, we present an integrated safety evaluation of six frontier models--GPT-5.2, Gemini 3 Pro, Qwen3-VL, Grok 4.1 Fast, Nano Banana Pro, and Seedream 4.5--assessing each across language, vision-language, and image generation using a unified protocol that combines benchmark, adversarial, multilingual, and compliance evaluations. By aggregating results into safety leaderboards and model profiles, we reveal a highly uneven safety landscape: while GPT-5.2 demonstrates consistently strong and balanced performance, other models exhibit clear trade-offs across benchmark safety, adversarial robustness, multilingual generalization, and regulatory compliance. Despite strong results under standard benchmarks, all models remain highly vulnerable under adversarial testing, with worst-case safety rates dropping below 6%. Text-to-image models show slightly stronger alignment in regulated visual risk categories, yet remain fragile when faced with adversarial or semantically ambiguous prompts. Overall, these findings highlight that safety in frontier models is inherently multidimensional--shaped by modality, language, and evaluation design--underscoring the need for standardized, holistic safety assessments to better reflect real-world risk and guide responsible deployment.
VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding
Jan 12, 2026This paper presents VideoLoom, a unified Video Large Language Model (Video LLM) for joint spatial-temporal understanding. To facilitate the development of fine-grained spatial and temporal localization capabilities, we curate LoomData-8.7k, a human-centric video dataset with temporally grounded and spatially localized captions. With this, VideoLoom achieves state-of-the-art or highly competitive performance across a variety of spatial and temporal benchmarks (e.g., 63.1 J&F on ReVOS for referring video object segmentation, and 48.3 R1@0.7 on Charades-STA for temporal grounding). In addition, we introduce LoomBench, a novel benchmark consisting of temporal, spatial, and compositional video-question pairs, enabling a comprehensive evaluation of Video LLMs from diverse aspects. Collectively, these contributions offer a universal and effective suite for joint spatial-temporal video understanding, setting a new standard in multimodal intelligence.
Thinking with Deltas: Incentivizing Reinforcement Learning via Differential Visual Reasoning Policy
Jan 11, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced reasoning capabilities in Large Language Models. However, adapting RLVR to multimodal domains suffers from a critical \textit{perception-reasoning decoupling}. Existing paradigms, driven by text-centric outcome rewards, reasoning in language medium, inadvertently encourage models to bypass visual perception. We empirically validate this through blind experiments: state-of-the-art policies maintain or surprisingly improve performance even when visual inputs are entirely removed. This reveals that these models degenerate into \textit{blind reasoners}, exploiting linguistic priors to generate plausible answers instead of attending to visual evidence. In response, we propose \textbf{Thinking with Deltas}, a framework driven by a \textbf{Differential Visual Reasoning Policy (DVRP)}. DVRP introduces intrinsic supervision via visual triplets, comprising original, masked, and perturbed inputs. It optimizes the model to maximize reasoning divergence from masked inputs (enforcing \textit{visual sensitivity}) while minimizing divergence from perturbed inputs (ensuring \textit{visual robustness}). By aligning reasoning variations strictly with the \textit{Delta} of visual information, DVRP inherently bolsters visual understanding capabilities and significantly outperforms state-of-the-art methods on both general and medical benchmarks, without requiring external annotations or auxiliary tools.
FlashPortrait: 6x Faster Infinite Portrait Animation with Adaptive Latent Prediction
Dec 18, 2025Current diffusion-based acceleration methods for long-portrait animation struggle to ensure identity (ID) consistency. This paper presents FlashPortrait, an end-to-end video diffusion transformer capable of synthesizing ID-preserving, infinite-length videos while achieving up to 6x acceleration in inference speed. In particular, FlashPortrait begins by computing the identity-agnostic facial expression features with an off-the-shelf extractor. It then introduces a Normalized Facial Expression Block to align facial features with diffusion latents by normalizing them with their respective means and variances, thereby improving identity stability in facial modeling. During inference, FlashPortrait adopts a dynamic sliding-window scheme with weighted blending in overlapping areas, ensuring smooth transitions and ID consistency in long animations. In each context window, based on the latent variation rate at particular timesteps and the derivative magnitude ratio among diffusion layers, FlashPortrait utilizes higher-order latent derivatives at the current timestep to directly predict latents at future timesteps, thereby skipping several denoising steps and achieving 6x speed acceleration. Experiments on benchmarks show the effectiveness of FlashPortrait both qualitatively and quantitatively.
UniGen-1.5: Enhancing Image Generation and Editing through Reward Unification in Reinforcement Learning
Nov 18, 2025We present UniGen-1.5, a unified multimodal large language model (MLLM) for advanced image understanding, generation and editing. Building upon UniGen, we comprehensively enhance the model architecture and training pipeline to strengthen the image understanding and generation capabilities while unlocking strong image editing ability. Especially, we propose a unified Reinforcement Learning (RL) strategy that improves both image generation and image editing jointly via shared reward models. To further enhance image editing performance, we propose a light Edit Instruction Alignment stage that significantly improves the editing instruction comprehension that is essential for the success of the RL training. Experimental results show that UniGen-1.5 demonstrates competitive understanding and generation performance. Specifically, UniGen-1.5 achieves 0.89 and 4.31 overall scores on GenEval and ImgEdit that surpass the state-of-the-art models such as BAGEL and reaching performance comparable to proprietary models such as GPT-Image-1.
TempoMaster: Efficient Long Video Generation via Next-Frame-Rate Prediction
Nov 16, 2025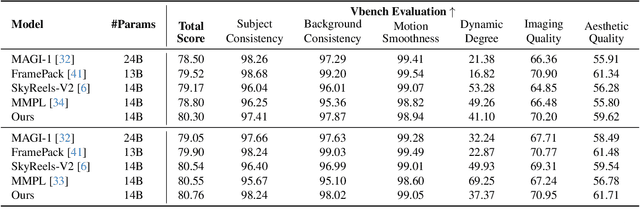
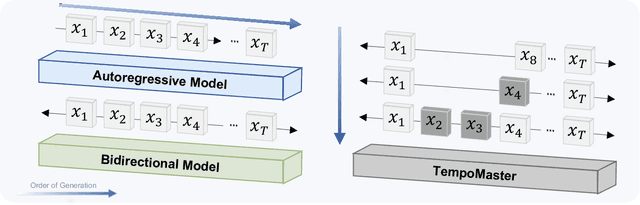
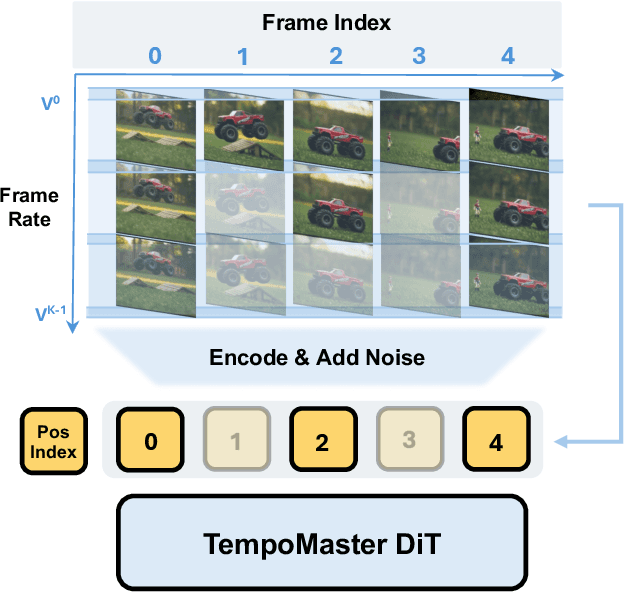
We present TempoMaster, a novel framework that formulates long video generation as next-frame-rate prediction. Specifically, we first generate a low-frame-rate clip that serves as a coarse blueprint of the entire video sequence, and then progressively increase the frame rate to refine visual details and motion continuity. During generation, TempoMaster employs bidirectional attention within each frame-rate level while performing autoregression across frame rates, thus achieving long-range temporal coherence while enabling efficient and parallel synthesis. Extensive experiments demonstrate that TempoMaster establishes a new state-of-the-art in long video generation, excelling in both visual and temporal quality.
Preserving Cross-Modal Consistency for CLIP-based Class-Incremental Learning
Nov 14, 2025



Class-incremental learning (CIL) enables models to continuously learn new categories from sequential tasks without forgetting previously acquired knowledge. While recent advances in vision-language models such as CLIP have demonstrated strong generalization across domains, extending them to continual settings remains challenging. In particular, learning task-specific soft prompts for newly introduced classes often leads to severe classifier bias, as the text prototypes overfit to recent categories when prior data are unavailable. In this paper, we propose DMC, a simple yet effective two-stage framework for CLIP-based CIL that decouples the adaptation of the vision encoder and the optimization of textual soft prompts. Each stage is trained with the other frozen, allowing one modality to act as a stable semantic anchor for the other to preserve cross-modal alignment. Furthermore, current CLIP-based CIL approaches typically store class-wise Gaussian statistics for generative replay, yet they overlook the distributional drift that arises when the vision encoder is updated over time. To address this issue, we introduce DMC-OT, an enhanced version of DMC that incorporates an optimal-transport guided calibration strategy to align memory statistics across evolving encoders, along with a task-specific prompting design that enhances inter-task separability. Extensive experiments on CIFAR-100, Imagenet-R, CUB-200, and UCF-101 demonstrate that both DMC and DMC-OT achieve state-of-the-art performance, with DMC-OT further improving accuracy by an average of 1.80%.
LRANet++: Low-Rank Approximation Network for Accurate and Efficient Text Spotting
Nov 08, 2025End-to-end text spotting aims to jointly optimize text detection and recognition within a unified framework. Despite significant progress, designing an accurate and efficient end-to-end text spotter for arbitrary-shaped text remains largely unsolved. We identify the primary bottleneck as the lack of a reliable and efficient text detection method. To address this, we propose a novel parameterized text shape method based on low-rank approximation for precise detection and a triple assignment detection head to enable fast inference. Specifically, unlike other shape representation methods that employ data-irrelevant parameterization, our data-driven approach derives a low-rank subspace directly from labeled text boundaries. To ensure this process is robust against the inherent annotation noise in this data, we utilize a specialized recovery method based on an $\ell_1$-norm formulation, which accurately reconstructs the text shape with only a few key orthogonal vectors. By exploiting the inherent shape correlation among different text contours, our method achieves consistency and compactness in shape representation. Next, the triple assignment scheme introduces a novel architecture where a deep sparse branch (for stabilized training) is used to guide the learning of an ultra-lightweight sparse branch (for accelerated inference), while a dense branch provides rich parallel supervision. Building upon these advancements, we integrate the enhanced detection module with a lightweight recognition branch to form an end-to-end text spotting framework, termed LRANet++, capable of accurately and efficiently spotting arbitrary-shaped text. Extensive experiments on several challenging benchmarks demonstrate the superiority of LRANet++ compared to state-of-the-art methods. Code will be available at: https://github.com/ychensu/LRANet-PP.git