 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaineCoon: Pursuing A Real-Time Audio-Visual Social World Model
Jun 16, 2026As an increasing majority of global video content is consumed on social platforms for interactive social purposes, video generation models built for social worlds are important but largely overlooked by previous studies. In this work, we define the position of social world models and build a prototype model as the first step towards this goal. While previous world models successfully simulate physical environments or gaming world exploration, they remain fundamentally detached from human-centric social dynamics. To bridge this gap as the first step to social world models, we present MaineCoon, the first real-time audio-visual autoregressive model that has 22B parameters and is capable of real-time streaming generation and sub-second interaction, with a record-breaking frame rate of up to 47.5 FPS, on a single GPU. To the best of our knowledge, MaineCoon is also the first real-time audio-visual generation model specifically optimized for social-interactive applications. To enable efficient and stable training, we introduce several novel techniques into MaineCoon, including self-resampling, cross-modal representation alignment, domain-aware preference optimization, and reinforced online-policy distillation (ROPD). We also design the first agentic streaming inference framework that supports thousand-second-scale or even longer generation while mitigating drift with agentic cache management and prompt planing. These innovations significantly accelerate training while optimizing real-time inference performance. We believe this work not only sets a new state-of-the-art (SOTA) performance benchmark for high-quality, low-latency, and long-horizon audio-visual autoregressive models, but also points out the paradigm shift desired for next-generation AI-native social platforms.
Lightning Unified Video Editing via In-Context Sparse Attention
May 06, 2026Video editing has evolved toward In-Context Learning (ICL) paradigms, yet the resulting quadratic attention costs create a critical computational bottleneck. In this work, we propose In-context Sparse Attention (ISA), the first near-lossless empirical sparse framework tailored for ICL video editing. Our design is grounded in two key insights: first, context tokens exhibit significantly lower saliency than source tokens; second, we theoretically prove and empirically validate that Query sharpness correlates with approximation error. Motivated by these findings, ISA implements an efficient pre-selection strategy to prune redundant context, followed by a dynamic query grouping mechanism that routes high-error queries to full attention and low-error ones to a computationally efficient 0-th order Taylor sparse attention. Furthermore, we build \textbf{\texttt{LIVEditor}} , a novel lightning video editing model via ISA and a proposed video-editing data pipeline that curated a 1.7M high-quality dataset. Extensive experiments demonstrate that LIVEditor achieves a $\sim$60% reduction in attention-module latency while surpassing state-of-the-art methods across EditVerseBench, IVE-Bench, and VIE-Bench, delivering near-lossless acceleration without compromising visual fidelity.
Exploring Data-Free LoRA Transferability for Video Diffusion Models
May 03, 2026Video diffusion models leveraging step distillation or causal distillation have achieved remarkable performance. However, adapting existing LoRAs to these variants remains a critical challenge due to weight space mismatches. We observe that direct application leads to style degradation and structural collapse, yet the underlying mechanisms remain poorly understood. To fill this gap, we delve into the weight space and identify that the incompatibility stems from spectral interference within shared functional clusters defined over singular subspaces. Specifically, our analysis reveals that while both paradigms respect spectral rigidity, they establish conflicting routing pathways that clash through constructive overload or destructive cancellation. To address this issue, we propose Cluster-Aware Spectral Arbitration (CASA), a data-free framework that dynamically arbitrates between safeguarding the target's manifold and restoring LoRA alignment based on spectral density. Extensive experiments demonstrate that CASA effectively mitigates artifacts and revives LoRA functionality. Our code is available at https://github.com/Noahwangyuchen/CASA
CRAFT: Aligning Diffusion Models with Fine-Tuning Is Easier Than You Think
Mar 19, 2026Aligning Diffusion models has achieved remarkable breakthroughs in generating high-quality, human preference-aligned images. Existing techniques, such as supervised fine-tuning (SFT) and DPO-style preference optimization, have become principled tools for fine-tuning diffusion models. However, SFT relies on high-quality images that are costly to obtain, while DPO-style methods depend on large-scale preference datasets, which are often inconsistent in quality. Beyond data dependency, these methods are further constrained by computational inefficiency. To address these two challenges, we propose Composite Reward Assisted Fine-Tuning (CRAFT), a lightweight yet powerful fine-tuning paradigm that requires significantly reduced training data while maintaining computational efficiency. It first leverages a Composite Reward Filtering (CRF) technique to construct a high-quality and consistent training dataset and then perform an enhanced variant of SFT. We also theoretically prove that CRAFT actually optimizes the lower bound of group-based reinforcement learning, establishing a principled connection between SFT with selected data and reinforcement learning. Our extensive empirical results demonstrate that CRAFT with only 100 samples can easily outperform recent SOTA preference optimization methods with thousands of preference-paired samples. Moreover, CRAFT can even achieve 11-220$\times$ faster convergences than the baseline preference optimization methods, highlighting its extremely high efficiency.
Guidance Matters: Rethinking the Evaluation Pitfall for Text-to-Image Generation
Feb 26, 2026Classifier-free guidance (CFG) has helped diffusion models achieve great conditional generation in various fields. Recently, more diffusion guidance methods have emerged with improved generation quality and human preference. However, can these emerging diffusion guidance methods really achieve solid and significant improvements? In this paper, we rethink recent progress on diffusion guidance. Our work mainly consists of four contributions. First, we reveal a critical evaluation pitfall that common human preference models exhibit a strong bias towards large guidance scales. Simply increasing the CFG scale can easily improve quantitative evaluation scores due to strong semantic alignment, even if image quality is severely damaged (e.g., oversaturation and artifacts). Second, we introduce a novel guidance-aware evaluation (GA-Eval) framework that employs effective guidance scale calibration to enable fair comparison between current guidance methods and CFG by identifying the effects orthogonal and parallel to CFG effects. Third, motivated by the evaluation pitfall, we design Transcendent Diffusion Guidance (TDG) method that can significantly improve human preference scores in the conventional evaluation framework but actually does not work in practice. Fourth, in extensive experiments, we empirically evaluate recent eight diffusion guidance methods within the conventional evaluation framework and the proposed GA-Eval framework. Notably, simply increasing the CFG scales can compete with most studied diffusion guidance methods, while all methods suffer severely from winning rate degradation over standard CFG. Our work would strongly motivate the community to rethink the evaluation paradigm and future directions of this field.
Optimizing Few-Step Generation with Adaptive Matching Distillation
Feb 07, 2026Distribution Matching Distillation (DMD) is a powerful acceleration paradigm, yet its stability is often compromised in Forbidden Zone, regions where the real teacher provides unreliable guidance while the fake teacher exerts insufficient repulsive force. In this work, we propose a unified optimization framework that reinterprets prior art as implicit strategies to avoid these corrupted regions. Based on this insight, we introduce Adaptive Matching Distillation (AMD), a self-correcting mechanism that utilizes reward proxies to explicitly detect and escape Forbidden Zones. AMD dynamically prioritizes corrective gradients via structural signal decomposition and introduces Repulsive Landscape Sharpening to enforce steep energy barriers against failure mode collapse. Extensive experiments across image and video generation tasks (e.g., SDXL, Wan2.1) and rigorous benchmarks (e.g., VBench, GenEval) demonstrate that AMD significantly enhances sample fidelity and training robustness. For instance, AMD improves the HPSv2 score on SDXL from 30.64 to 31.25, outperforming state-of-the-art baselines. These findings validate that explicitly rectifying optimization trajectories within Forbidden Zones is essential for pushing the performance ceiling of few-step generative models.
PISA: Piecewise Sparse Attention Is Wiser for Efficient Diffusion Transformers
Feb 03, 2026Diffusion Transformers are fundamental for video and image generation, but their efficiency is bottlenecked by the quadratic complexity of attention. While block sparse attention accelerates computation by attending only critical key-value blocks, it suffers from degradation at high sparsity by discarding context. In this work, we discover that attention scores of non-critical blocks exhibit distributional stability, allowing them to be approximated accurately and efficiently rather than discarded, which is essentially important for sparse attention design. Motivated by this key insight, we propose PISA, a training-free Piecewise Sparse Attention that covers the full attention span with sub-quadratic complexity. Unlike the conventional keep-or-drop paradigm that directly drop the non-critical block information, PISA introduces a novel exact-or-approximate strategy: it maintains exact computation for critical blocks while efficiently approximating the remainder through block-wise Taylor expansion. This design allows PISA to serve as a faithful proxy to full attention, effectively bridging the gap between speed and quality. Experimental results demonstrate that PISA achieves 1.91 times and 2.57 times speedups on Wan2.1-14B and Hunyuan-Video, respectively, while consistently maintaining the highest quality among sparse attention methods. Notably, even for image generation on FLUX, PISA achieves a 1.2 times acceleration without compromising visual quality. Code is available at: https://github.com/xie-lab-ml/piecewise-sparse-attention.
Multiphysics Bench: Benchmarking and Investigating Scientific Machine Learning for Multiphysics PDEs
May 23, 2025


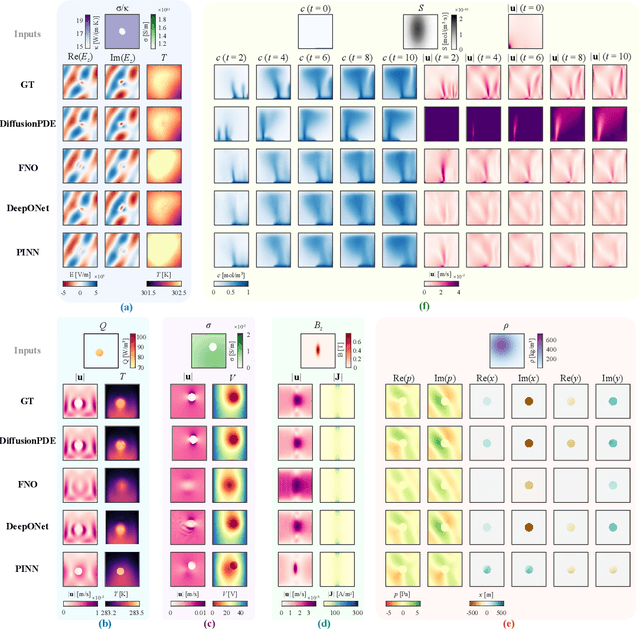
Solving partial differential equations (PDEs) with machine learning has recently attracted great attention, as PDEs are fundamental tools for modeling real-world systems that range from fundamental physical science to advanced engineering disciplines. Most real-world physical systems across various disciplines are actually involved in multiple coupled physical fields rather than a single field. However, previous machine learning studies mainly focused on solving single-field problems, but overlooked the importance and characteristics of multiphysics problems in real world. Multiphysics PDEs typically entail multiple strongly coupled variables, thereby introducing additional complexity and challenges, such as inter-field coupling. Both benchmarking and solving multiphysics problems with machine learning remain largely unexamined. To identify and address the emerging challenges in multiphysics problems, we mainly made three contributions in this work. First, we collect the first general multiphysics dataset, the Multiphysics Bench, that focuses on multiphysics PDE solving with machine learning. Multiphysics Bench is also the most comprehensive PDE dataset to date, featuring the broadest range of coupling types, the greatest diversity of PDE formulations, and the largest dataset scale. Second, we conduct the first systematic investigation on multiple representative learning-based PDE solvers, such as PINNs, FNO, DeepONet, and DiffusionPDE solvers, on multiphysics problems. Unfortunately, naively applying these existing solvers usually show very poor performance for solving multiphysics. Third, through extensive experiments and discussions, we report multiple insights and a bag of useful tricks for solving multiphysics with machine learning, motivating future directions in the study and simulation of complex, coupled physical systems.
GMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025



Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
CoRe^2: Collect, Reflect and Refine to Generate Better and Faster
Mar 12, 2025Making text-to-image (T2I) generative model sample both fast and well represents a promising research direction. Previous studies have typically focused on either enhancing the visual quality of synthesized images at the expense of sampling efficiency or dramatically accelerating sampling without improving the base model's generative capacity. Moreover, nearly all inference methods have not been able to ensure stable performance simultaneously on both diffusion models (DMs) and visual autoregressive models (ARMs). In this paper, we introduce a novel plug-and-play inference paradigm, CoRe^2, which comprises three subprocesses: Collect, Reflect, and Refine. CoRe^2 first collects classifier-free guidance (CFG) trajectories, and then use collected data to train a weak model that reflects the easy-to-learn contents while reducing number of function evaluations during inference by half. Subsequently, CoRe^2 employs weak-to-strong guidance to refine the conditional output, thereby improving the model's capacity to generate high-frequency and realistic content, which is difficult for the base model to capture. To the best of our knowledge, CoRe^2 is the first to demonstrate both efficiency and effectiveness across a wide range of DMs, including SDXL, SD3.5, and FLUX, as well as ARMs like LlamaGen. It has exhibited significant performance improvements on HPD v2, Pick-of-Pic, Drawbench, GenEval, and T2I-Compbench. Furthermore, CoRe^2 can be seamlessly integrated with the state-of-the-art Z-Sampling, outperforming it by 0.3 and 0.16 on PickScore and AES, while achieving 5.64s time saving using SD3.5.Code is released at https://github.com/xie-lab-ml/CoRe/tree/main.