 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantiCache: Efficient KV Cache Compression via Semantic Chunking and Clustered Merging
Mar 15, 2026Existing KV cache compression methods generally operate on discrete tokens or non-semantic chunks. However, such approaches often lead to semantic fragmentation, where linguistically coherent units are disrupted, causing irreversible information loss and degradation in model performance. To address this, we introduce SemantiCache, a novel compression framework that preserves semantic integrity by aligning the compression process with the semantic hierarchical nature of language. Specifically, we first partition the cache into semantically coherent chunks by delimiters, which are natural semantic boundaries. Within each chunk, we introduce a computationally efficient Greedy Seed-Based Clustering (GSC) algorithm to group tokens into semantic clusters. These clusters are further merged into semantic cores, enhanced by a Proportional Attention mechanism that rebalances the reduced attention contributions of the merged tokens. Extensive experiments across diverse benchmarks and models demonstrate that SemantiCache accelerates the decoding stage of inference by up to 2.61 times and substantially reduces memory footprint, while maintaining performance comparable to the original model.
LexSemBridge: Fine-Grained Dense Representation Enhancement through Token-Aware Embedding Augmentation
Aug 25, 2025As queries in retrieval-augmented generation (RAG) pipelines powered by large language models (LLMs) become increasingly complex and diverse, dense retrieval models have demonstrated strong performance in semantic matching. Nevertheless, they often struggle with fine-grained retrieval tasks, where precise keyword alignment and span-level localization are required, even in cases with high lexical overlap that would intuitively suggest easier retrieval. To systematically evaluate this limitation, we introduce two targeted tasks, keyword retrieval and part-of-passage retrieval, designed to simulate practical fine-grained scenarios. Motivated by these observations, we propose LexSemBridge, a unified framework that enhances dense query representations through fine-grained, input-aware vector modulation. LexSemBridge constructs latent enhancement vectors from input tokens using three paradigms: Statistical (SLR), Learned (LLR), and Contextual (CLR), and integrates them with dense embeddings via element-wise interaction. Theoretically, we show that this modulation preserves the semantic direction while selectively amplifying discriminative dimensions. LexSemBridge operates as a plug-in without modifying the backbone encoder and naturally extends to both text and vision modalities. Extensive experiments across semantic and fine-grained retrieval tasks validate the effectiveness and generality of our approach. All code and models are publicly available at https://github.com/Jasaxion/LexSemBridge/
GMSA: Enhancing Context Compression via Group Merging and Layer Semantic Alignment
May 18, 2025



Large language models (LLMs) have achieved impressive performance in a variety of natural language processing (NLP) tasks. However, when applied to long-context scenarios, they face two challenges, i.e., low computational efficiency and much redundant information. This paper introduces GMSA, a context compression framework based on the encoder-decoder architecture, which addresses these challenges by reducing input sequence length and redundant information. Structurally, GMSA has two key components: Group Merging and Layer Semantic Alignment (LSA). Group merging is used to effectively and efficiently extract summary vectors from the original context. Layer semantic alignment, on the other hand, aligns the high-level summary vectors with the low-level primary input semantics, thus bridging the semantic gap between different layers. In the training process, GMSA first learns soft tokens that contain complete semantics through autoencoder training. To furtherly adapt GMSA to downstream tasks, we propose Knowledge Extraction Fine-tuning (KEFT) to extract knowledge from the soft tokens for downstream tasks. We train GMSA by randomly sampling the compression rate for each sample in the dataset. Under this condition, GMSA not only significantly outperforms the traditional compression paradigm in context restoration but also achieves stable and significantly faster convergence with only a few encoder layers. In downstream question-answering (QA) tasks, GMSA can achieve approximately a 2x speedup in end-to-end inference while outperforming both the original input prompts and various state-of-the-art (SOTA) methods by a large margin.
Exploring the Implicit Semantic Ability of Multimodal Large Language Models: A Pilot Study on Entity Set Expansion
Dec 31, 2024


The rapid development of multimodal large language models (MLLMs) has brought significant improvements to a wide range of tasks in real-world applications. However, LLMs still exhibit certain limitations in extracting implicit semantic information. In this paper, we apply MLLMs to the Multi-modal Entity Set Expansion (MESE) task, which aims to expand a handful of seed entities with new entities belonging to the same semantic class, and multi-modal information is provided with each entity. We explore the capabilities of MLLMs to understand implicit semantic information at the entity-level granularity through the MESE task, introducing a listwise ranking method LUSAR that maps local scores to global rankings. Our LUSAR demonstrates significant improvements in MLLM's performance on the MESE task, marking the first use of generative MLLM for ESE tasks and extending the applicability of listwise ranking.
Active Relation Discovery: Towards General and Label-aware Open Relation Extraction
Nov 08, 2022



Open Relation Extraction (OpenRE) aims to discover novel relations from open domains. Previous OpenRE methods mainly suffer from two problems: (1) Insufficient capacity to discriminate between known and novel relations. When extending conventional test settings to a more general setting where test data might also come from seen classes, existing approaches have a significant performance decline. (2) Secondary labeling must be performed before practical application. Existing methods cannot label human-readable and meaningful types for novel relations, which is urgently required by the downstream tasks. To address these issues, we propose the Active Relation Discovery (ARD) framework, which utilizes relational outlier detection for discriminating known and novel relations and involves active learning for labeling novel relations. Extensive experiments on three real-world datasets show that ARD significantly outperforms previous state-of-the-art methods on both conventional and our proposed general OpenRE settings. The source code and datasets will be available for reproducibility.
Prompt-Learning for Fine-Grained Entity Typing
Aug 24, 2021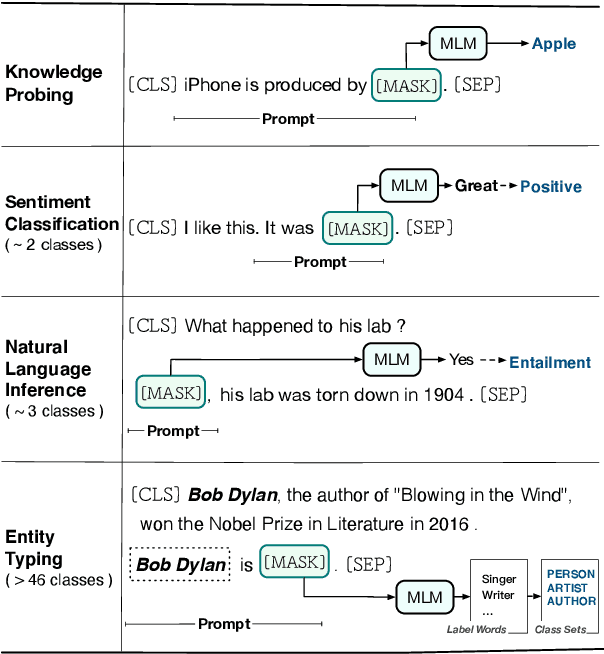


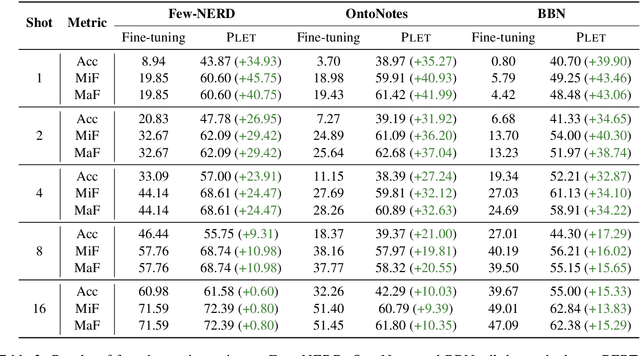
As an effective approach to tune pre-trained language models (PLMs) for specific tasks, prompt-learning has recently attracted much attention from researchers. By using \textit{cloze}-style language prompts to stimulate the versatile knowledge of PLMs, prompt-learning can achieve promising results on a series of NLP tasks, such as natural language inference, sentiment classification, and knowledge probing. In this work, we investigate the application of prompt-learning on fine-grained entity typing in fully supervised, few-shot and zero-shot scenarios. We first develop a simple and effective prompt-learning pipeline by constructing entity-oriented verbalizers and templates and conducting masked language modeling. Further, to tackle the zero-shot regime, we propose a self-supervised strategy that carries out distribution-level optimization in prompt-learning to automatically summarize the information of entity types. Extensive experiments on three fine-grained entity typing benchmarks (with up to 86 classes) under fully supervised, few-shot and zero-shot settings show that prompt-learning methods significantly outperform fine-tuning baselines, especially when the training data is insufficient.
Sequential Routing Framework: Fully Capsule Network-based Speech Recognition
Jul 23, 2020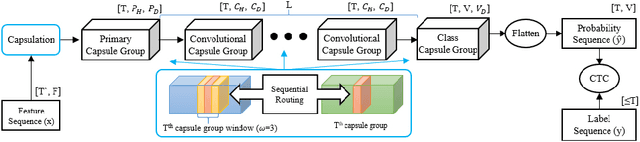
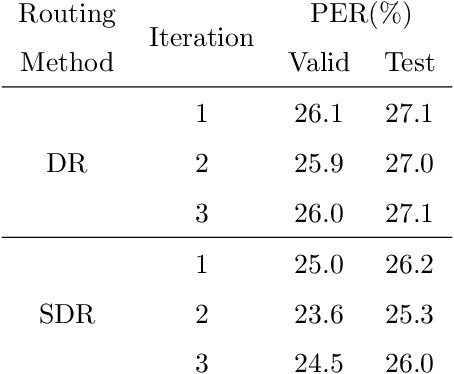
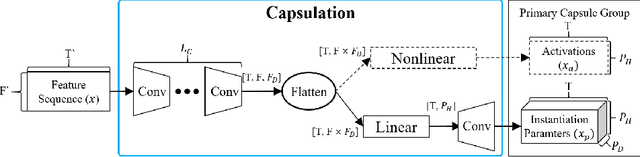
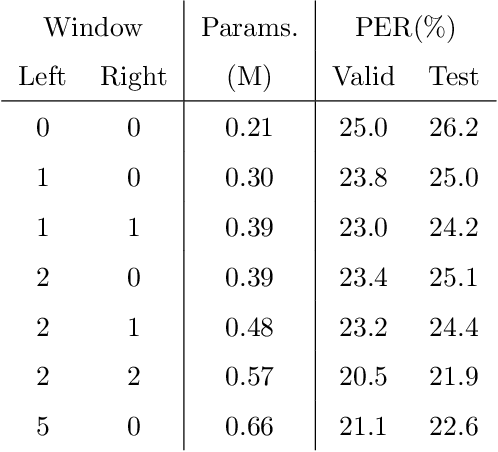
Capsule networks (CapsNets) have recently gotten attention as alternatives for convolutional neural networks (CNNs) with their greater hierarchical representation capabilities. In this paper, we introduce the sequential routing framework (SRF) which we believe is the first method to adapt a CapsNet-only structure to sequence-to-sequence recognition. In SRF, input sequences are capsulized then sliced by the window size. Each sliced window is classified to a label at the corresponding time through iterative routing mechanisms. Afterwards, training losses are computed using connectionist temporal classification (CTC). During routing, two kinds of information, learnable weights and iteration outputs are shared across the slices. By sharing the information, the required parameter numbers can be controlled by the given window size regardless of the length of sequences. Moreover, the method can minimize decoding speed degradation caused by the routing iterations since it can operate in a non-iterative manner at inference time without dropping accuracy. We empirically proved the validity of our method by performing phoneme sequence recognition tasks on the TIMIT corpus. The proposed method attains an 82.6% phoneme recognition rate. It is 0.8% more accurate than that of CNN-based CTC networks and on par with that of recurrent neural network transducers (RNN-Ts). Even more, the method requires less than half the parameters compared to the two architectures.