 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACQUIRED: A Dataset for Answering Counterfactual Questions In Real-Life Videos
Nov 02, 2023



Multimodal counterfactual reasoning is a vital yet challenging ability for AI systems. It involves predicting the outcomes of hypothetical circumstances based on vision and language inputs, which enables AI models to learn from failures and explore hypothetical scenarios. Despite its importance, there are only a few datasets targeting the counterfactual reasoning abilities of multimodal models. Among them, they only cover reasoning over synthetic environments or specific types of events (e.g. traffic collisions), making them hard to reliably benchmark the model generalization ability in diverse real-world scenarios and reasoning dimensions. To overcome these limitations, we develop a video question answering dataset, ACQUIRED: it consists of 3.9K annotated videos, encompassing a wide range of event types and incorporating both first and third-person viewpoints, which ensures a focus on real-world diversity. In addition, each video is annotated with questions that span three distinct dimensions of reasoning, including physical, social, and temporal, which can comprehensively evaluate the model counterfactual abilities along multiple aspects. We benchmark our dataset against several state-of-the-art language-only and multimodal models and experimental results demonstrate a significant performance gap (>13%) between models and humans. The findings suggest that multimodal counterfactual reasoning remains an open challenge and ACQUIRED is a comprehensive and reliable benchmark for inspiring future research in this direction.
DesCo: Learning Object Recognition with Rich Language Descriptions
Jun 24, 2023



Recent development in vision-language approaches has instigated a paradigm shift in learning visual recognition models from language supervision. These approaches align objects with language queries (e.g. "a photo of a cat") and improve the models' adaptability to identify novel objects and domains. Recently, several studies have attempted to query these models with complex language expressions that include specifications of fine-grained semantic details, such as attributes, shapes, textures, and relations. However, simply incorporating language descriptions as queries does not guarantee accurate interpretation by the models. In fact, our experiments show that GLIP, the state-of-the-art vision-language model for object detection, often disregards contextual information in the language descriptions and instead relies heavily on detecting objects solely by their names. To tackle the challenges, we propose a new description-conditioned (DesCo) paradigm of learning object recognition models with rich language descriptions consisting of two major innovations: 1) we employ a large language model as a commonsense knowledge engine to generate rich language descriptions of objects based on object names and the raw image-text caption; 2) we design context-sensitive queries to improve the model's ability in deciphering intricate nuances embedded within descriptions and enforce the model to focus on context rather than object names alone. On two novel object detection benchmarks, LVIS and OminiLabel, under the zero-shot detection setting, our approach achieves 34.8 APr minival (+9.1) and 29.3 AP (+3.6), respectively, surpassing the prior state-of-the-art models, GLIP and FIBER, by a large margin.
Gender Biases in Automatic Evaluation Metrics: A Case Study on Image Captioning
May 24, 2023



Pretrained model-based evaluation metrics have demonstrated strong performance with high correlations with human judgments in various natural language generation tasks such as image captioning. Despite the impressive results, their impact on fairness is under-explored -- it is widely acknowledged that pretrained models can encode societal biases, and utilizing them for evaluation purposes may inadvertently manifest and potentially amplify biases. In this paper, we conduct a systematic study in gender biases of model-based evaluation metrics with a focus on image captioning tasks. Specifically, we first identify and quantify gender biases in different evaluation metrics regarding profession, activity, and object concepts. Then, we demonstrate the negative consequences of using these biased metrics, such as favoring biased generation models in deployment and propagating the biases to generation models through reinforcement learning. We also present a simple but effective alternative to reduce gender biases by combining n-gram matching-based and pretrained model-based evaluation metrics.
Masked Path Modeling for Vision-and-Language Navigation
May 23, 2023



Vision-and-language navigation (VLN) agents are trained to navigate in real-world environments by following natural language instructions. A major challenge in VLN is the limited availability of training data, which hinders the models' ability to generalize effectively. Previous approaches have attempted to address this issue by introducing additional supervision during training, often requiring costly human-annotated data that restricts scalability. In this paper, we introduce a masked path modeling (MPM) objective, which pretrains an agent using self-collected data for downstream navigation tasks. Our proposed method involves allowing the agent to actively explore navigation environments without a specific goal and collect the paths it traverses. Subsequently, we train the agent on this collected data to reconstruct the original path given a randomly masked subpath. This way, the agent can actively accumulate a diverse and substantial amount of data while learning conditional action generation. To evaluate the effectiveness of our technique, we conduct experiments on various VLN datasets and demonstrate the versatility of MPM across different levels of instruction complexity. Our results exhibit significant improvements in success rates, with enhancements of 1.32\%, 1.05\%, and 1.19\% on the val-unseen split of the Room-to-Room, Room-for-Room, and Room-across-Room datasets, respectively. Furthermore, we conduct an analysis that highlights the potential for additional improvements when the agent is allowed to explore unseen environments prior to testing.
Generalized Decoding for Pixel, Image, and Language
Dec 21, 2022



We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.
Coarse-to-Fine Vision-Language Pre-training with Fusion in the Backbone
Jun 15, 2022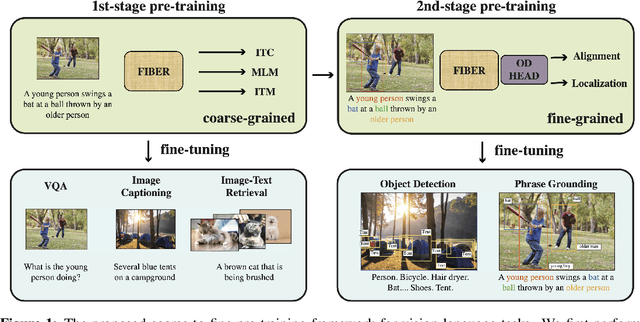

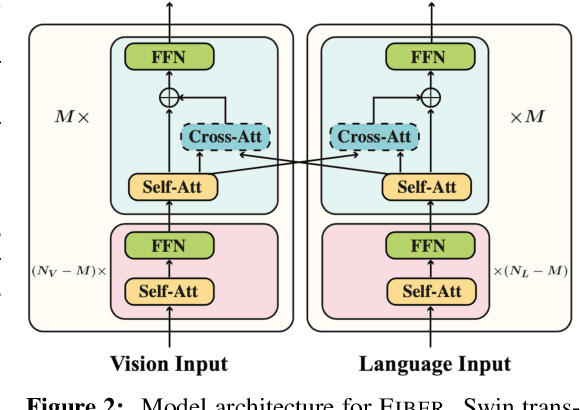
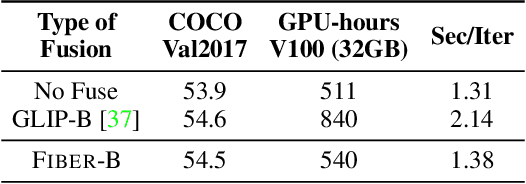
Vision-language (VL) pre-training has recently received considerable attention. However, most existing end-to-end pre-training approaches either only aim to tackle VL tasks such as image-text retrieval, visual question answering (VQA) and image captioning that test high-level understanding of images, or only target region-level understanding for tasks such as phrase grounding and object detection. We present FIBER (Fusion-In-the-Backbone-based transformER), a new VL model architecture that can seamlessly handle both these types of tasks. Instead of having dedicated transformer layers for fusion after the uni-modal backbones, FIBER pushes multimodal fusion deep into the model by inserting cross-attention into the image and text backbones, bringing gains in terms of memory and performance. In addition, unlike previous work that is either only pre-trained on image-text data or on fine-grained data with box-level annotations, we present a two-stage pre-training strategy that uses both these kinds of data efficiently: (i) coarse-grained pre-training based on image-text data; followed by (ii) fine-grained pre-training based on image-text-box data. We conduct comprehensive experiments on a wide range of VL tasks, ranging from VQA, image captioning, and retrieval, to phrase grounding, referring expression comprehension, and object detection. Using deep multimodal fusion coupled with the two-stage pre-training, FIBER provides consistent performance improvements over strong baselines across all tasks, often outperforming methods using magnitudes more data. Code is available at https://github.com/microsoft/FIBER.
FOAM: A Follower-aware Speaker Model For Vision-and-Language Navigation
Jun 09, 2022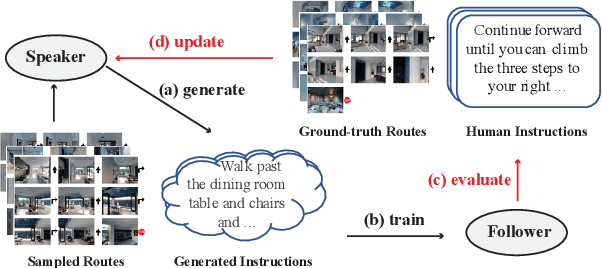
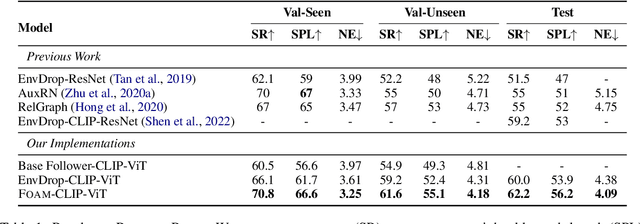

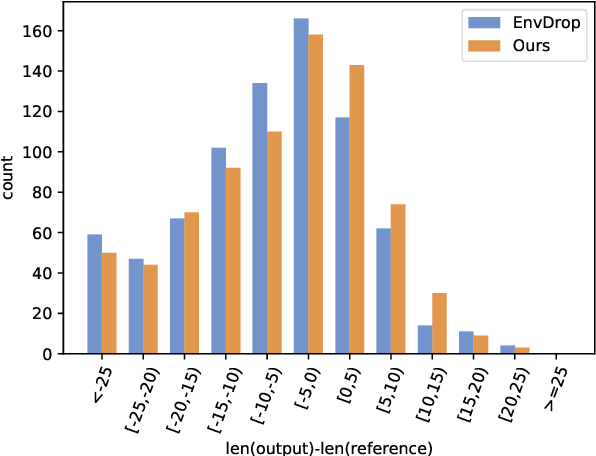
The speaker-follower models have proven to be effective in vision-and-language navigation, where a speaker model is used to synthesize new instructions to augment the training data for a follower navigation model. However, in many of the previous methods, the generated instructions are not directly trained to optimize the performance of the follower. In this paper, we present \textsc{foam}, a \textsc{Fo}llower-\textsc{a}ware speaker \textsc{M}odel that is constantly updated given the follower feedback, so that the generated instructions can be more suitable to the current learning state of the follower. Specifically, we optimize the speaker using a bi-level optimization framework and obtain its training signals by evaluating the follower on labeled data. Experimental results on the Room-to-Room and Room-across-Room datasets demonstrate that our methods can outperform strong baseline models across settings. Analyses also reveal that our generated instructions are of higher quality than the baselines.
Zero-shot Commonsense Question Answering with Cloze Translation and Consistency Optimization
Jan 01, 2022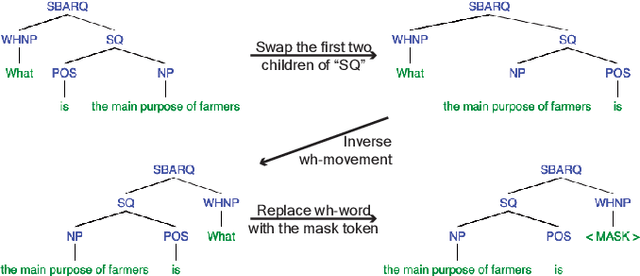


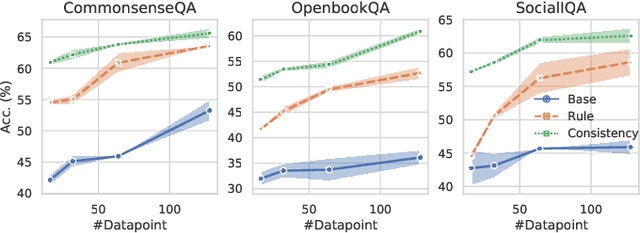
Commonsense question answering (CQA) aims to test if models can answer questions regarding commonsense knowledge that everyone knows. Prior works that incorporate external knowledge bases have shown promising results, but knowledge bases are expensive to construct and are often limited to a fixed set of relations. In this paper, we instead focus on better utilizing the \textit{implicit knowledge} stored in pre-trained language models. While researchers have found that the knowledge embedded in pre-trained language models can be extracted by having them fill in the blanks of carefully designed prompts for relation extraction and text classification, it remains unclear if we can adopt this paradigm in CQA where the inputs and outputs take much more flexible forms. To this end, we investigate four translation methods that can translate natural questions into cloze-style sentences to better solicit commonsense knowledge from language models, including a syntactic-based model, an unsupervised neural model, and two supervised neural models. In addition, to combine the different translation methods, we propose to encourage consistency among model predictions on different translated questions with unlabeled data. We demonstrate the effectiveness of our methods on three CQA datasets in zero-shot settings. We show that our methods are complementary to a knowledge base improved model, and combining them can lead to state-of-the-art zero-shot performance. Analyses also reveal distinct characteristics of the different cloze translation methods and provide insights on why combining them can lead to great improvements.
An Empirical Study of Training End-to-End Vision-and-Language Transformers
Nov 25, 2021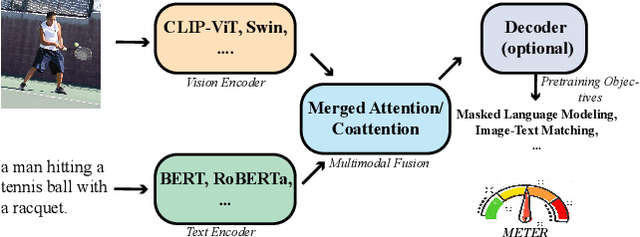

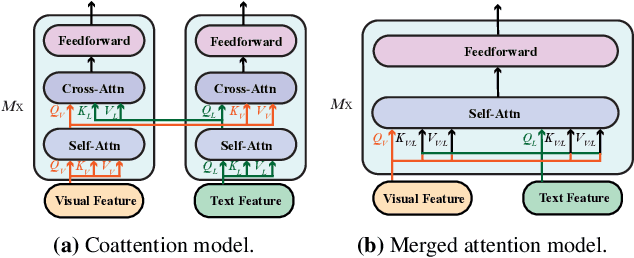

Vision-and-language (VL) pre-training has proven to be highly effective on various VL downstream tasks. While recent work has shown that fully transformer-based VL models can be more efficient than previous region-feature-based methods, their performance on downstream tasks often degrades significantly. In this paper, we present METER, a Multimodal End-to-end TransformER framework, through which we investigate how to design and pre-train a fully transformer-based VL model in an end-to-end manner. Specifically, we dissect the model designs along multiple dimensions: vision encoders (e.g., CLIPViT, Swin transformer), text encoders (e.g., RoBERTa, DeBERTa), multimodal fusion module (e.g., merged attention vs. co-attention), architectural design (e.g., encoder-only vs. encoder-decoder), and pre-training objectives (e.g., masked image modeling). We conduct comprehensive experiments and provide insights on how to train a performant VL transformer while maintaining fast inference speed. Notably, our best model achieves an accuracy of 77.64% on the VQAv2 test-std set using only 4M images for pre-training, surpassing the state-of-the-art region-feature-based model by 1.04%, and outperforming the previous best fully transformer-based model by 1.6%. Code and models are released at https://github.com/zdou0830/METER.
RefSum: Refactoring Neural Summarization
Apr 15, 2021
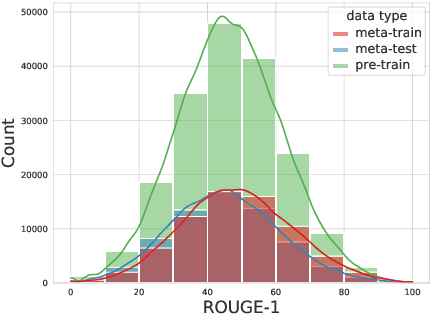
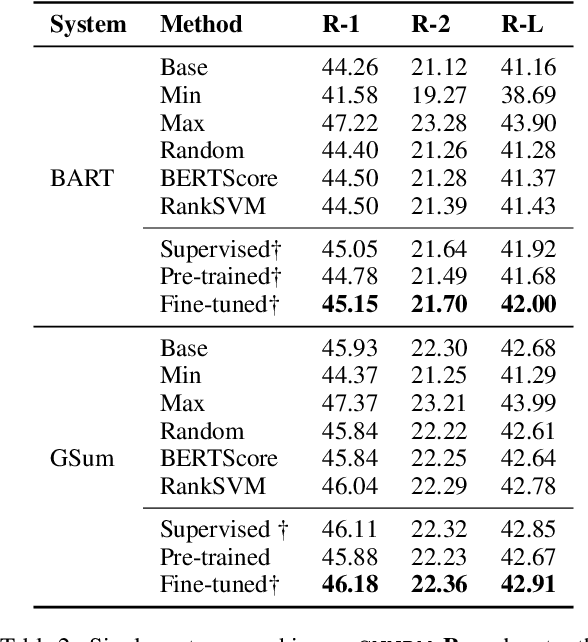
Although some recent works show potential complementarity among different state-of-the-art systems, few works try to investigate this problem in text summarization. Researchers in other areas commonly refer to the techniques of reranking or stacking to approach this problem. In this work, we highlight several limitations of previous methods, which motivates us to present a new framework Refactor that provides a unified view of text summarization and summaries combination. Experimentally, we perform a comprehensive evaluation that involves twenty-two base systems, four datasets, and three different application scenarios. Besides new state-of-the-art results on CNN/DailyMail dataset (46.18 ROUGE-1), we also elaborate on how our proposed method addresses the limitations of the traditional methods and the effectiveness of the Refactor model sheds light on insight for performance improvement. Our system can be directly used by other researchers as an off-the-shelf tool to achieve further performance improvements. We open-source all the code and provide a convenient interface to use it: https://github.com/yixinL7/Refactoring-Summarization. We have also made the demo of this work available at: http://explainaboard.nlpedia.ai/leaderboard/task-summ/index.php.