 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
The Sample Complexity of Online Strategic Decision Making with Information Asymmetry and Knowledge Transportability
Jun 11, 2025Information asymmetry is a pervasive feature of multi-agent systems, especially evident in economics and social sciences. In these settings, agents tailor their actions based on private information to maximize their rewards. These strategic behaviors often introduce complexities due to confounding variables. Simultaneously, knowledge transportability poses another significant challenge, arising from the difficulties of conducting experiments in target environments. It requires transferring knowledge from environments where empirical data is more readily available. Against these backdrops, this paper explores a fundamental question in online learning: Can we employ non-i.i.d. actions to learn about confounders even when requiring knowledge transfer? We present a sample-efficient algorithm designed to accurately identify system dynamics under information asymmetry and to navigate the challenges of knowledge transfer effectively in reinforcement learning, framed within an online strategic interaction model. Our method provably achieves learning of an $\epsilon$-optimal policy with a tight sample complexity of $O(1/\epsilon^2)$.
Learning to Lead: Incentivizing Strategic Agents in the Dark
Jun 10, 2025We study an online learning version of the generalized principal-agent model, where a principal interacts repeatedly with a strategic agent possessing private types, private rewards, and taking unobservable actions. The agent is non-myopic, optimizing a discounted sum of future rewards and may strategically misreport types to manipulate the principal's learning. The principal, observing only her own realized rewards and the agent's reported types, aims to learn an optimal coordination mechanism that minimizes strategic regret. We develop the first provably sample-efficient algorithm for this challenging setting. Our approach features a novel pipeline that combines (i) a delaying mechanism to incentivize approximately myopic agent behavior, (ii) an innovative reward angle estimation framework that uses sector tests and a matching procedure to recover type-dependent reward functions, and (iii) a pessimistic-optimistic LinUCB algorithm that enables the principal to explore efficiently while respecting the agent's incentive constraints. We establish a near optimal $\tilde{O}(\sqrt{T}) $ regret bound for learning the principal's optimal policy, where $\tilde{O}(\cdot) $ omits logarithmic factors. Our results open up new avenues for designing robust online learning algorithms for a wide range of game-theoretic settings involving private types and strategic agents.
Quantile-Optimal Policy Learning under Unmeasured Confounding
Jun 08, 2025We study quantile-optimal policy learning where the goal is to find a policy whose reward distribution has the largest $\alpha$-quantile for some $\alpha \in (0, 1)$. We focus on the offline setting whose generating process involves unobserved confounders. Such a problem suffers from three main challenges: (i) nonlinearity of the quantile objective as a functional of the reward distribution, (ii) unobserved confounding issue, and (iii) insufficient coverage of the offline dataset. To address these challenges, we propose a suite of causal-assisted policy learning methods that provably enjoy strong theoretical guarantees under mild conditions. In particular, to address (i) and (ii), using causal inference tools such as instrumental variables and negative controls, we propose to estimate the quantile objectives by solving nonlinear functional integral equations. Then we adopt a minimax estimation approach with nonparametric models to solve these integral equations, and propose to construct conservative policy estimates that address (iii). The final policy is the one that maximizes these pessimistic estimates. In addition, we propose a novel regularized policy learning method that is more amenable to computation. Finally, we prove that the policies learned by these methods are $\tilde{\mathscr{O}}(n^{-1/2})$ quantile-optimal under a mild coverage assumption on the offline dataset. Here, $\tilde{\mathscr{O}}(\cdot)$ omits poly-logarithmic factors. To the best of our knowledge, we propose the first sample-efficient policy learning algorithms for estimating the quantile-optimal policy when there exist unmeasured confounding.
BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms
May 21, 2025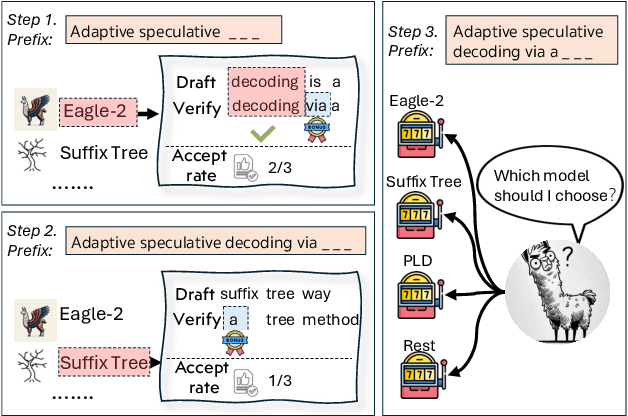
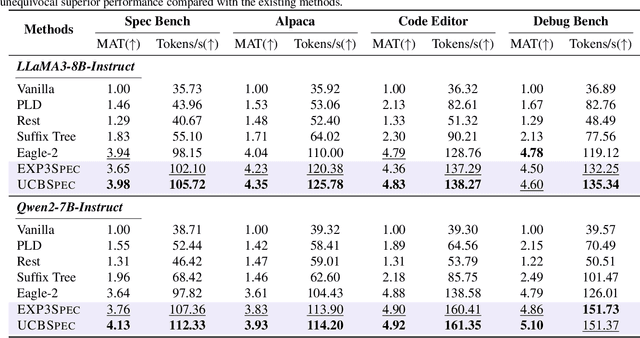
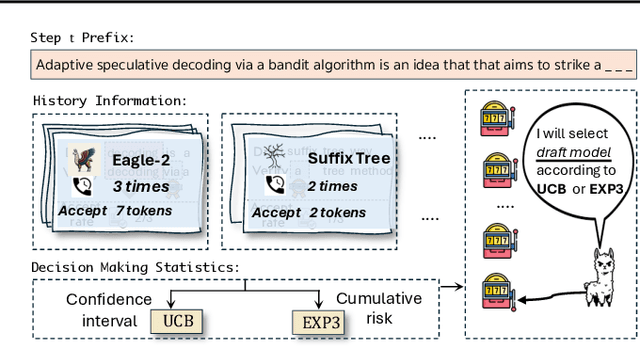
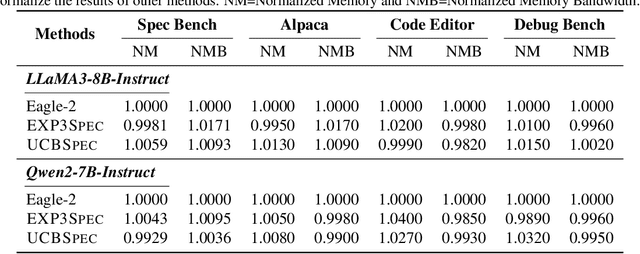
Speculative decoding has emerged as a popular method to accelerate the inference of Large Language Models (LLMs) while retaining their superior text generation performance. Previous methods either adopt a fixed speculative decoding configuration regardless of the prefix tokens, or train draft models in an offline or online manner to align them with the context. This paper proposes a training-free online learning framework to adaptively choose the configuration of the hyperparameters for speculative decoding as text is being generated. We first formulate this hyperparameter selection problem as a Multi-Armed Bandit problem and provide a general speculative decoding framework BanditSpec. Furthermore, two bandit-based hyperparameter selection algorithms, UCBSpec and EXP3Spec, are designed and analyzed in terms of a novel quantity, the stopping time regret. We upper bound this regret under both stochastic and adversarial reward settings. By deriving an information-theoretic impossibility result, it is shown that the regret performance of UCBSpec is optimal up to universal constants. Finally, extensive empirical experiments with LLaMA3 and Qwen2 demonstrate that our algorithms are effective compared to existing methods, and the throughput is close to the oracle best hyperparameter in simulated real-life LLM serving scenarios with diverse input prompts.
Self-Supervised Pre-training with Combined Datasets for 3D Perception in Autonomous Driving
Apr 17, 2025



The significant achievements of pre-trained models leveraging large volumes of data in the field of NLP and 2D vision inspire us to explore the potential of extensive data pre-training for 3D perception in autonomous driving. Toward this goal, this paper proposes to utilize massive unlabeled data from heterogeneous datasets to pre-train 3D perception models. We introduce a self-supervised pre-training framework that learns effective 3D representations from scratch on unlabeled data, combined with a prompt adapter based domain adaptation strategy to reduce dataset bias. The approach significantly improves model performance on downstream tasks such as 3D object detection, BEV segmentation, 3D object tracking, and occupancy prediction, and shows steady performance increase as the training data volume scales up, demonstrating the potential of continually benefit 3D perception models for autonomous driving. We will release the source code to inspire further investigations in the community.
In-Context Linear Regression Demystified: Training Dynamics and Mechanistic Interpretability of Multi-Head Softmax Attention
Mar 17, 2025



We study how multi-head softmax attention models are trained to perform in-context learning on linear data. Through extensive empirical experiments and rigorous theoretical analysis, we demystify the emergence of elegant attention patterns: a diagonal and homogeneous pattern in the key-query (KQ) weights, and a last-entry-only and zero-sum pattern in the output-value (OV) weights. Remarkably, these patterns consistently appear from gradient-based training starting from random initialization. Our analysis reveals that such emergent structures enable multi-head attention to approximately implement a debiased gradient descent predictor -- one that outperforms single-head attention and nearly achieves Bayesian optimality up to proportional factor. Furthermore, compared to linear transformers, the softmax attention readily generalizes to sequences longer than those seen during training. We also extend our study to scenarios with non-isotropic covariates and multi-task linear regression. In the former, multi-head attention learns to implement a form of pre-conditioned gradient descent. In the latter, we uncover an intriguing regime where the interplay between head number and task number triggers a superposition phenomenon that efficiently resolves multi-task in-context learning. Our results reveal that in-context learning ability emerges from the trained transformer as an aggregated effect of its architecture and the underlying data distribution, paving the way for deeper understanding and broader applications of in-context learning.
Nash Equilibrium Constrained Auto-bidding With Bi-level Reinforcement Learning
Mar 13, 2025



Many online advertising platforms provide advertisers with auto-bidding services to enhance their advertising performance. However, most existing auto-bidding algorithms fail to accurately capture the auto-bidding problem formulation that the platform truly faces, let alone solve it. Actually, we argue that the platform should try to help optimize each advertiser's performance to the greatest extent -- which makes $\epsilon$-Nash Equilibrium ($\epsilon$-NE) a necessary solution concept -- while maximizing the social welfare of all the advertisers for the platform's long-term value. Based on this, we introduce the \emph{Nash-Equilibrium Constrained Bidding} (NCB), a new formulation of the auto-bidding problem from the platform's perspective. Specifically, it aims to maximize the social welfare of all advertisers under the $\epsilon$-NE constraint. However, the NCB problem presents significant challenges due to its constrained bi-level structure and the typically large number of advertisers involved. To address these challenges, we propose a \emph{Bi-level Policy Gradient} (BPG) framework with theoretical guarantees. Notably, its computational complexity is independent of the number of advertisers, and the associated gradients are straightforward to compute. Extensive simulated and real-world experiments validate the effectiveness of the BPG framework.
Reflective Planning: Vision-Language Models for Multi-Stage Long-Horizon Robotic Manipulation
Feb 23, 2025



Solving complex long-horizon robotic manipulation problems requires sophisticated high-level planning capabilities, the ability to reason about the physical world, and reactively choose appropriate motor skills. Vision-language models (VLMs) pretrained on Internet data could in principle offer a framework for tackling such problems. However, in their current form, VLMs lack both the nuanced understanding of intricate physics required for robotic manipulation and the ability to reason over long horizons to address error compounding issues. In this paper, we introduce a novel test-time computation framework that enhances VLMs' physical reasoning capabilities for multi-stage manipulation tasks. At its core, our approach iteratively improves a pretrained VLM with a "reflection" mechanism - it uses a generative model to imagine future world states, leverages these predictions to guide action selection, and critically reflects on potential suboptimalities to refine its reasoning. Experimental results demonstrate that our method significantly outperforms several state-of-the-art commercial VLMs as well as other post-training approaches such as Monte Carlo Tree Search (MCTS). Videos are available at https://reflect-vlm.github.io.
Active Advantage-Aligned Online Reinforcement Learning with Offline Data
Feb 11, 2025Online reinforcement learning (RL) enhances policies through direct interactions with the environment, but faces challenges related to sample efficiency. In contrast, offline RL leverages extensive pre-collected data to learn policies, but often produces suboptimal results due to limited data coverage. Recent efforts have sought to integrate offline and online RL in order to harness the advantages of both approaches. However, effectively combining online and offline RL remains challenging due to issues that include catastrophic forgetting, lack of robustness and sample efficiency. In an effort to address these challenges, we introduce A3 RL , a novel method that actively selects data from combined online and offline sources to optimize policy improvement. We provide theoretical guarantee that validates the effectiveness our active sampling strategy and conduct thorough empirical experiments showing that our method outperforms existing state-of-the-art online RL techniques that utilize offline data. Our code will be publicly available at: https://github.com/xuefeng-cs/A3RL.