 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGene Function Prediction with Gene Interaction Networks: A Context Graph Kernel Approach
Apr 22, 2022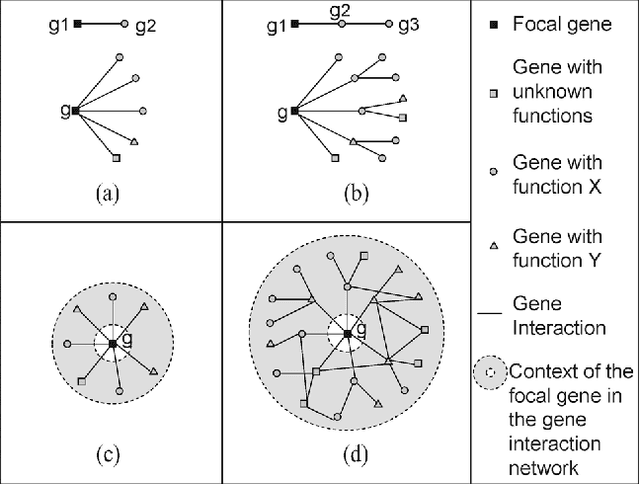
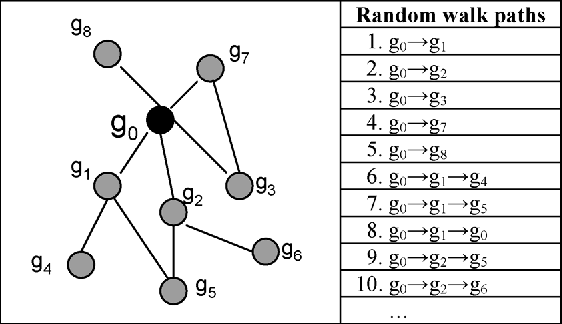
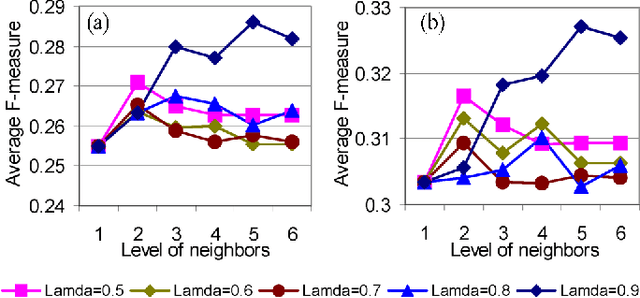
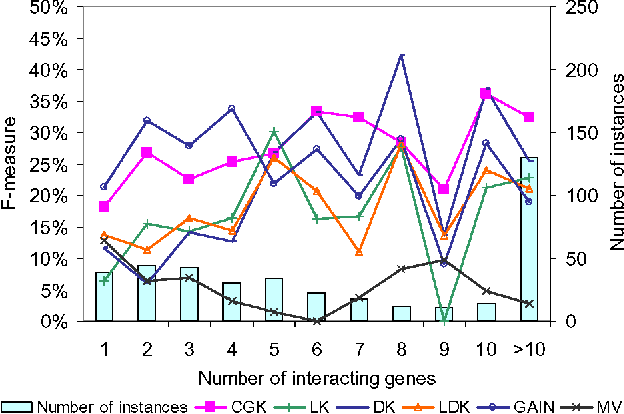
Predicting gene functions is a challenge for biologists in the post genomic era. Interactions among genes and their products compose networks that can be used to infer gene functions. Most previous studies adopt a linkage assumption, i.e., they assume that gene interactions indicate functional similarities between connected genes. In this study, we propose to use a gene's context graph, i.e., the gene interaction network associated with the focal gene, to infer its functions. In a kernel-based machine-learning framework, we design a context graph kernel to capture the information in context graphs. Our experimental study on a testbed of p53-related genes demonstrates the advantage of using indirect gene interactions and shows the empirical superiority of the proposed approach over linkage-assumption-based methods, such as the algorithm to minimize inconsistent connected genes and diffusion kernels.
SYNERGY: Building Task Bots at Scale Using Symbolic Knowledge and Machine Teaching
Oct 21, 2021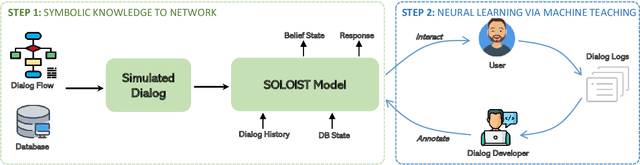

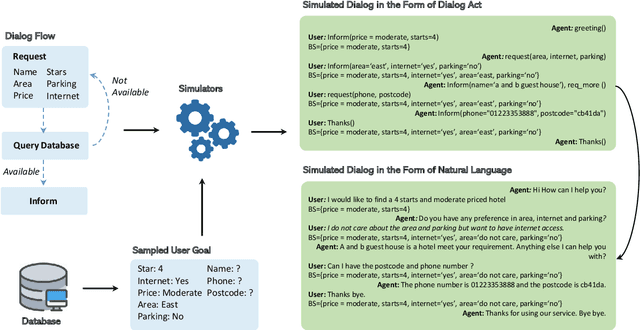
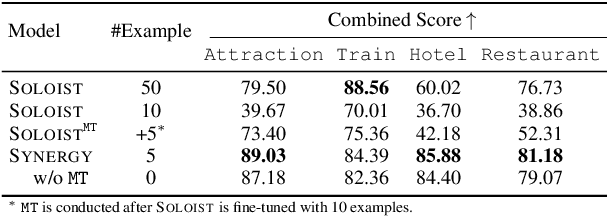
In this paper we explore the use of symbolic knowledge and machine teaching to reduce human data labeling efforts in building neural task bots. We propose SYNERGY, a hybrid learning framework where a task bot is developed in two steps: (i) Symbolic knowledge to neural networks: Large amounts of simulated dialog sessions are generated based on task-specific symbolic knowledge which is represented as a task schema consisting of dialog flows and task-oriented databases. Then a pre-trained neural dialog model, SOLOIST, is fine-tuned on the simulated dialogs to build a bot for the task. (ii) Neural learning: The fine-tuned neural dialog model is continually refined with a handful of real task-specific dialogs via machine teaching, where training samples are generated by human teachers interacting with the task bot. We validate SYNERGY on four dialog tasks. Experimental results show that SYNERGY maps task-specific knowledge into neural dialog models achieving greater diversity and coverage of dialog flows, and continually improves model performance with machine teaching, thus demonstrating strong synergistic effects of symbolic knowledge and machine teaching.
Learning to Rehearse in Long Sequence Memorization
Jun 02, 2021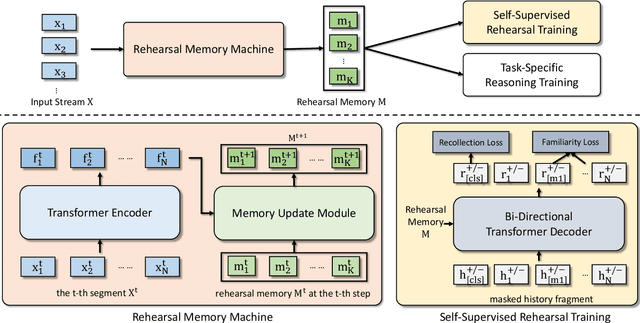
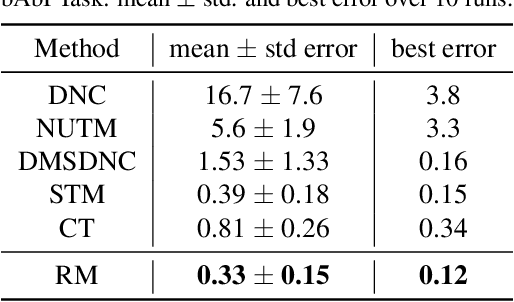
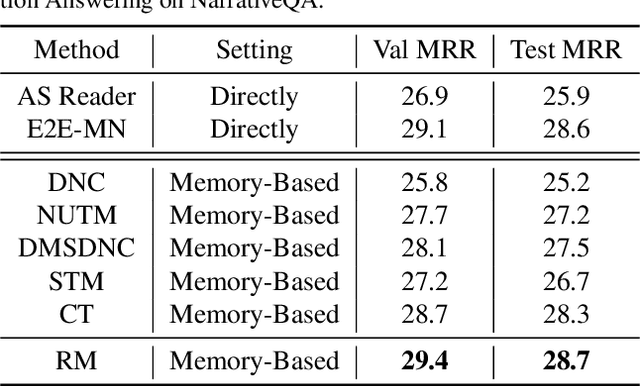
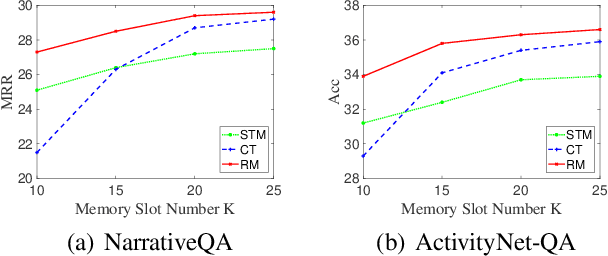
Existing reasoning tasks often have an important assumption that the input contents can be always accessed while reasoning, requiring unlimited storage resources and suffering from severe time delay on long sequences. To achieve efficient reasoning on long sequences with limited storage resources, memory augmented neural networks introduce a human-like write-read memory to compress and memorize the long input sequence in one pass, trying to answer subsequent queries only based on the memory. But they have two serious drawbacks: 1) they continually update the memory from current information and inevitably forget the early contents; 2) they do not distinguish what information is important and treat all contents equally. In this paper, we propose the Rehearsal Memory (RM) to enhance long-sequence memorization by self-supervised rehearsal with a history sampler. To alleviate the gradual forgetting of early information, we design self-supervised rehearsal training with recollection and familiarity tasks. Further, we design a history sampler to select informative fragments for rehearsal training, making the memory focus on the crucial information. We evaluate the performance of our rehearsal memory by the synthetic bAbI task and several downstream tasks, including text/video question answering and recommendation on long sequences.
Connecting Language and Vision for Natural Language-Based Vehicle Retrieval
May 31, 2021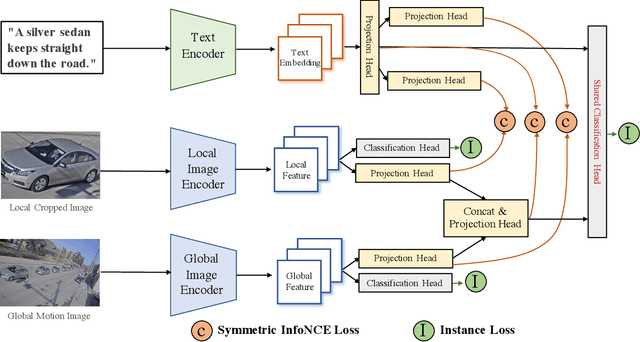
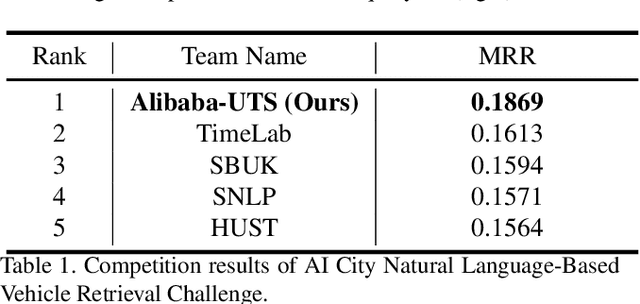
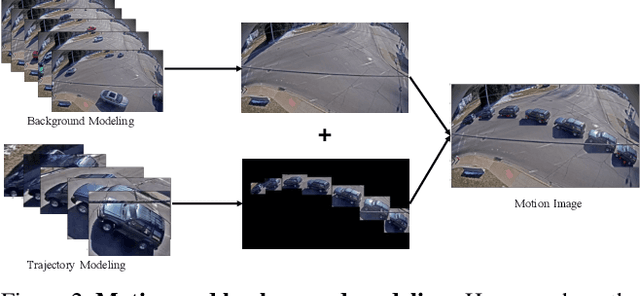
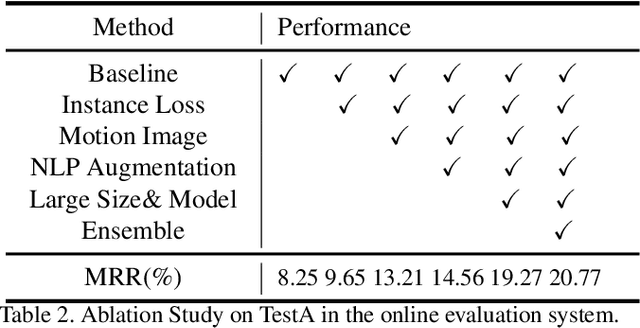
Vehicle search is one basic task for the efficient traffic management in terms of the AI City. Most existing practices focus on the image-based vehicle matching, including vehicle re-identification and vehicle tracking. In this paper, we apply one new modality, i.e., the language description, to search the vehicle of interest and explore the potential of this task in the real-world scenario. The natural language-based vehicle search poses one new challenge of fine-grained understanding of both vision and language modalities. To connect language and vision, we propose to jointly train the state-of-the-art vision models with the transformer-based language model in an end-to-end manner. Except for the network structure design and the training strategy, several optimization objectives are also re-visited in this work. The qualitative and quantitative experiments verify the effectiveness of the proposed method. Our proposed method has achieved the 1st place on the 5th AI City Challenge, yielding competitive performance 18.69% MRR accuracy on the private test set. We hope this work can pave the way for the future study on using language description effectively and efficiently for real-world vehicle retrieval systems. The code will be available at https://github.com/ShuaiBai623/AIC2021-T5-CLV.
UFC-BERT: Unifying Multi-Modal Controls for Conditional Image Synthesis
May 29, 2021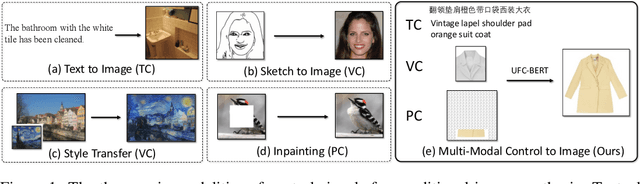

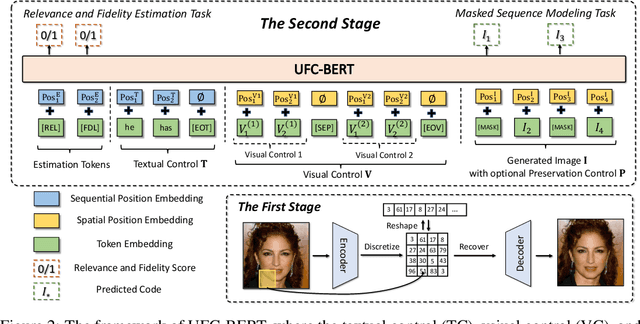
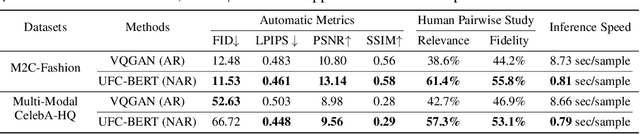
Conditional image synthesis aims to create an image according to some multi-modal guidance in the forms of textual descriptions, reference images, and image blocks to preserve, as well as their combinations. In this paper, instead of investigating these control signals separately, we propose a new two-stage architecture, UFC-BERT, to unify any number of multi-modal controls. In UFC-BERT, both the diverse control signals and the synthesized image are uniformly represented as a sequence of discrete tokens to be processed by Transformer. Different from existing two-stage autoregressive approaches such as DALL-E and VQGAN, UFC-BERT adopts non-autoregressive generation (NAR) at the second stage to enhance the holistic consistency of the synthesized image, to support preserving specified image blocks, and to improve the synthesis speed. Further, we design a progressive algorithm that iteratively improves the non-autoregressively generated image, with the help of two estimators developed for evaluating the compliance with the controls and evaluating the fidelity of the synthesized image, respectively. Extensive experiments on a newly collected large-scale clothing dataset M2C-Fashion and a facial dataset Multi-Modal CelebA-HQ verify that UFC-BERT can synthesize high-fidelity images that comply with flexible multi-modal controls.
RADDLE: An Evaluation Benchmark and Analysis Platform for Robust Task-oriented Dialog Systems
Dec 29, 2020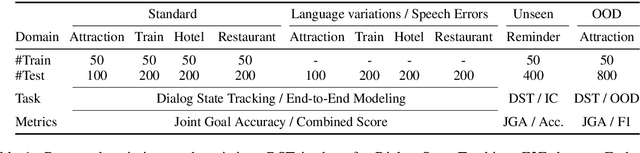
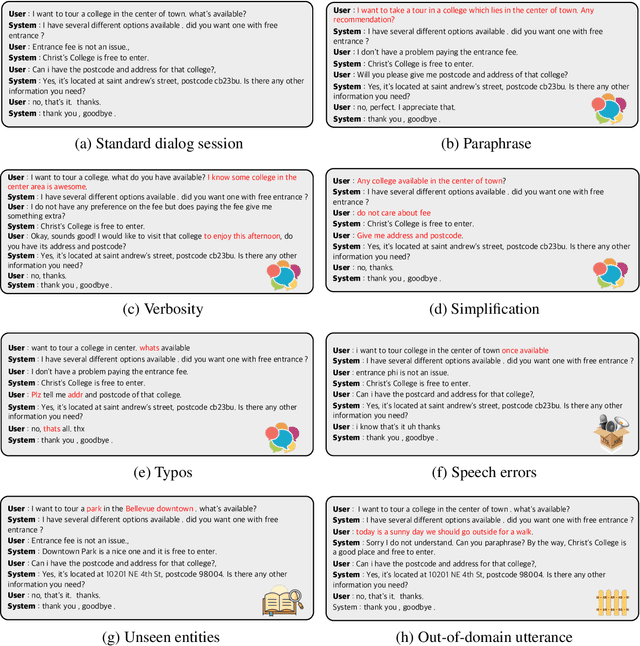

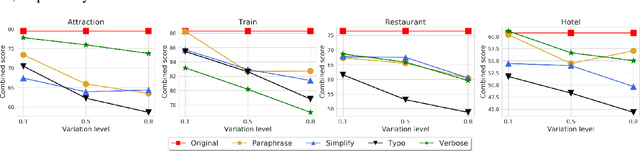
For task-oriented dialog systems to be maximally useful, it must be able to process conversations in a way that is (1) generalizable with a small number of training examples for new task domains, and (2) robust to user input in various styles, modalities or domains. In pursuit of these goals, we introduce the RADDLE benchmark, a collection of corpora and tools for evaluating the performance of models across a diverse set of domains. By including tasks with limited training data, RADDLE is designed to favor and encourage models with a strong generalization ability. RADDLE also includes a diagnostic checklist that facilitates detailed robustness analysis in aspects such as language variations, speech errors, unseen entities, and out-of-domain utterances. We evaluate recent state-of-the-art systems based on pre-training and fine-tuning, and find that grounded pre-training on heterogeneous dialog corpora performs better than training a separate model per domain. Overall, existing models are less than satisfactory in robustness evaluation, which suggests opportunities for future improvement.
Object-Aware Multi-Branch Relation Networks for Spatio-Temporal Video Grounding
Aug 22, 2020
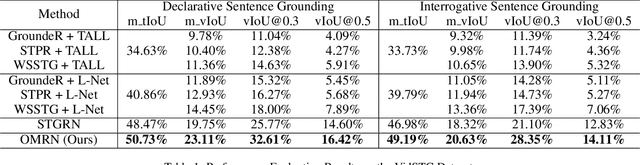
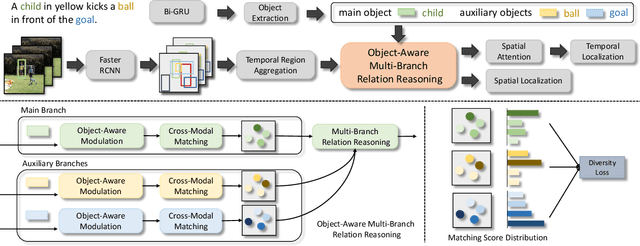
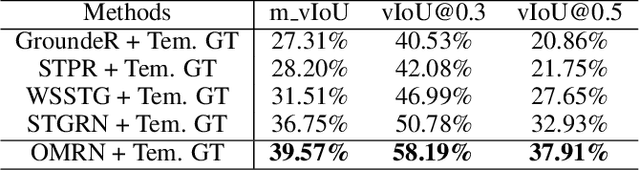
Spatio-temporal video grounding aims to retrieve the spatio-temporal tube of a queried object according to the given sentence. Currently, most existing grounding methods are restricted to well-aligned segment-sentence pairs. In this paper, we explore spatio-temporal video grounding on unaligned data and multi-form sentences. This challenging task requires to capture critical object relations to identify the queried target. However, existing approaches cannot distinguish notable objects and remain in ineffective relation modeling between unnecessary objects. Thus, we propose a novel object-aware multi-branch relation network for object-aware relation discovery. Concretely, we first devise multiple branches to develop object-aware region modeling, where each branch focuses on a crucial object mentioned in the sentence. We then propose multi-branch relation reasoning to capture critical object relationships between the main branch and auxiliary branches. Moreover, we apply a diversity loss to make each branch only pay attention to its corresponding object and boost multi-branch learning. The extensive experiments show the effectiveness of our proposed method.
Regularized Two-Branch Proposal Networks for Weakly-Supervised Moment Retrieval in Videos
Aug 19, 2020
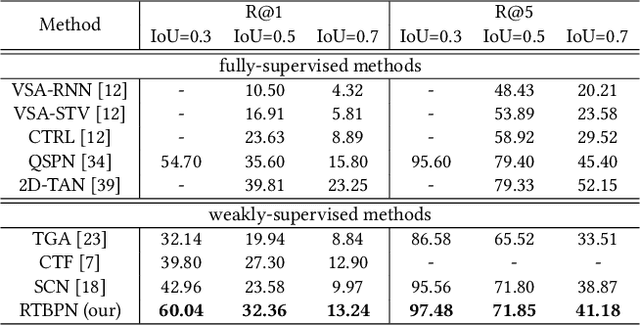
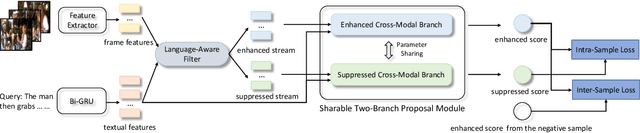
Video moment retrieval aims to localize the target moment in an video according to the given sentence. The weak-supervised setting only provides the video-level sentence annotations during training. Most existing weak-supervised methods apply a MIL-based framework to develop inter-sample confrontment, but ignore the intra-sample confrontment between moments with semantically similar contents. Thus, these methods fail to distinguish the target moment from plausible negative moments. In this paper, we propose a novel Regularized Two-Branch Proposal Network to simultaneously consider the inter-sample and intra-sample confrontments. Concretely, we first devise a language-aware filter to generate an enhanced video stream and a suppressed video stream. We then design the sharable two-branch proposal module to generate positive proposals from the enhanced stream and plausible negative proposals from the suppressed one for sufficient confrontment. Further, we apply the proposal regularization to stabilize the training process and improve model performance. The extensive experiments show the effectiveness of our method. Our code is released at here.
Where Does It Exist: Spatio-Temporal Video Grounding for Multi-Form Sentences
Feb 25, 2020
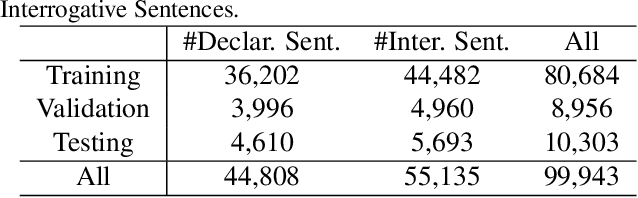
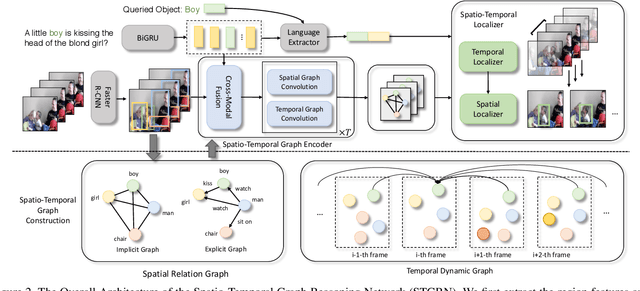
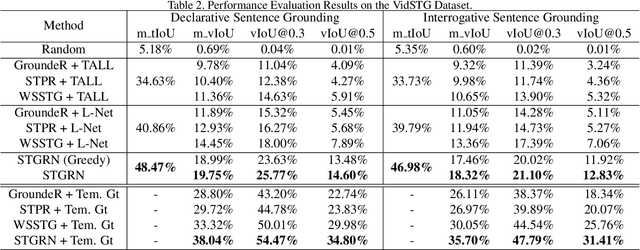
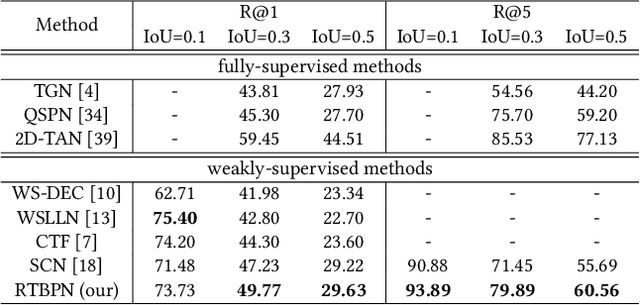
In this paper, we consider a novel task, Spatio-Temporal Video Grounding for Multi-Form Sentences (STVG). Given an untrimmed video and a declarative/interrogative sentence depicting an object, STVG aims to localize the spatiotemporal tube of the queried object. STVG has two challenging settings: (1) We need to localize spatio-temporal object tubes from untrimmed videos, where the object may only exist in a very small segment of the video; (2) We deal with multi-form sentences, including the declarative sentences with explicit objects and interrogative sentences with unknown objects. Existing methods cannot tackle the STVG task due to the ineffective tube pre-generation and the lack of object relationship modeling. Thus, we then propose a novel Spatio-Temporal Graph Reasoning Network (STGRN) for this task. First, we build a spatio-temporal region graph to capture the region relationships with temporal object dynamics, which involves the implicit and explicit spatial subgraphs in each frame and the temporal dynamic subgraph across frames. We then incorporate textual clues into the graph and develop the multi-step cross-modal graph reasoning. Next, we introduce a spatio-temporal localizer with a dynamic selection method to directly retrieve the spatiotemporal tubes without tube pre-generation. Moreover, we contribute a large-scale video grounding dataset VidSTG based on video relation dataset VidOR. The extensive experiments demonstrate the effectiveness of our method.
Weakly-Supervised Video Moment Retrieval via Semantic Completion Network
Nov 19, 2019
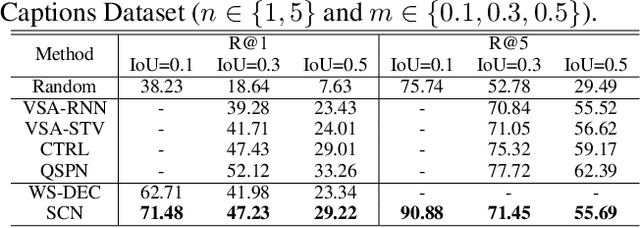
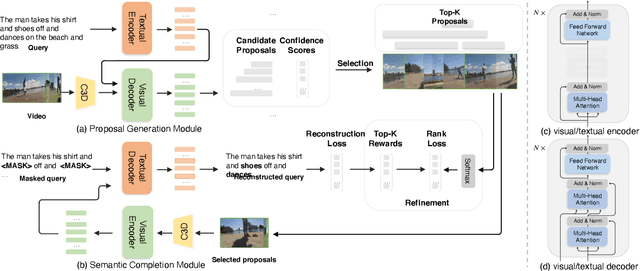
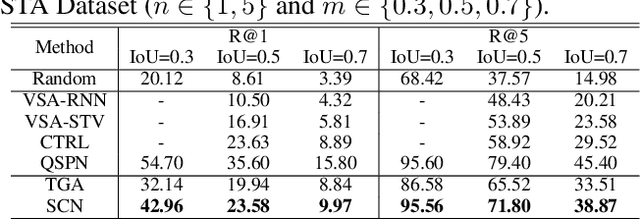
Video moment retrieval is to search the moment that is most relevant to the given natural language query. Existing methods are mostly trained in a fully-supervised setting, which requires the full annotations of temporal boundary for each query. However, manually labeling the annotations is actually time-consuming and expensive. In this paper, we propose a novel weakly-supervised moment retrieval framework requiring only coarse video-level annotations for training. Specifically, we devise a proposal generation module that aggregates the context information to generate and score all candidate proposals in one single pass. We then devise an algorithm that considers both exploitation and exploration to select top-K proposals. Next, we build a semantic completion module to measure the semantic similarity between the selected proposals and query, compute reward and provide feedbacks to the proposal generation module for scoring refinement. Experiments on the ActivityCaptions and Charades-STA demonstrate the effectiveness of our proposed method.